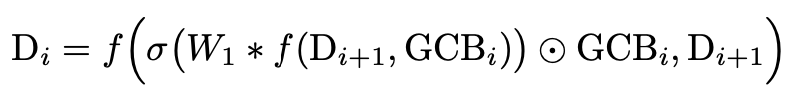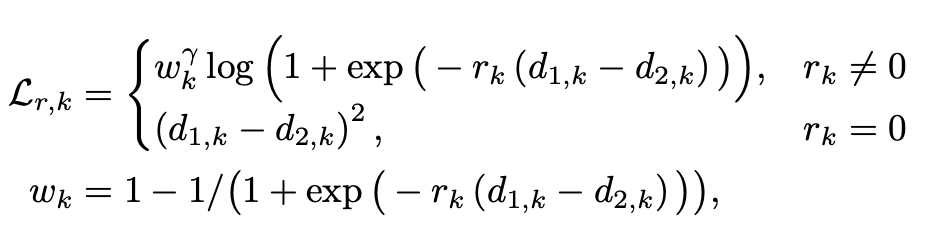深度是实现 3D 场景理解的重要信息,快手 Y-tech 利用自研的单目深度估计技术获得了高质量的深度信息,并将模型部署到移动端,结合 Y-tech 已有的多项技术研发了 3DPhoto、混合现实等多种新玩法。这些黑科技玩法不限机型,可让用户在手机上无门槛的实时体验,给用户带来全新的视觉体验和交互方式的同时,可帮助用户更好的进行创作。
这项研究主要探究了如何更好的利用三维空间的结构性信息提升单目深度估计精度,此外还针对复杂场景构建了一个新的深度数据集 HC Depth,包含六种挑战性场景,有针对性地提升模型的精度和泛化性。该论文已被 ECCV 2020 收录,论文代码和模型即将在 GitHub 上开源,作者也将在 8 月 23-28 日的 ECCV 大会线上展示他们的工作。
![]()
从 2D 图像恢复 3D 信息是计算机视觉的一个基础性问题,可以应用在视觉定位、场景理解和增强现实等领域。在无法通过深度传感器或者多视角获得有效的深度测量时,单目深度估计算法尤为重要。传统方法通常使用先验信息恢复图像的深度信息,例如纹理线索,物体尺寸和位置,遮挡和透视关系等。近年来深层卷积神经网络通过对大规模数据集的学习,能够隐式捕获这些先验信息,取得了重大的突破。
然而,自然场景的深度信息估计存在很多挑战,如光照不足或过曝,包含移动人像和天空区域,虚假边缘,相机的抖动和倾斜等(见图 1)。现有算法把单目深度估计转化为像素深度值的分类或回归问题,对于全局像素之间的结构性缺乏考量,导致遇到很多问题,如空间布局错误,边缘不清晰,平面估计错误等。针对这一缺陷,这篇论文从深度信息的结构性角度出发,从网络结构、损失函数、训练方式、数据扩充等方面入手,提高深度估计的质量。
![]()
![]()
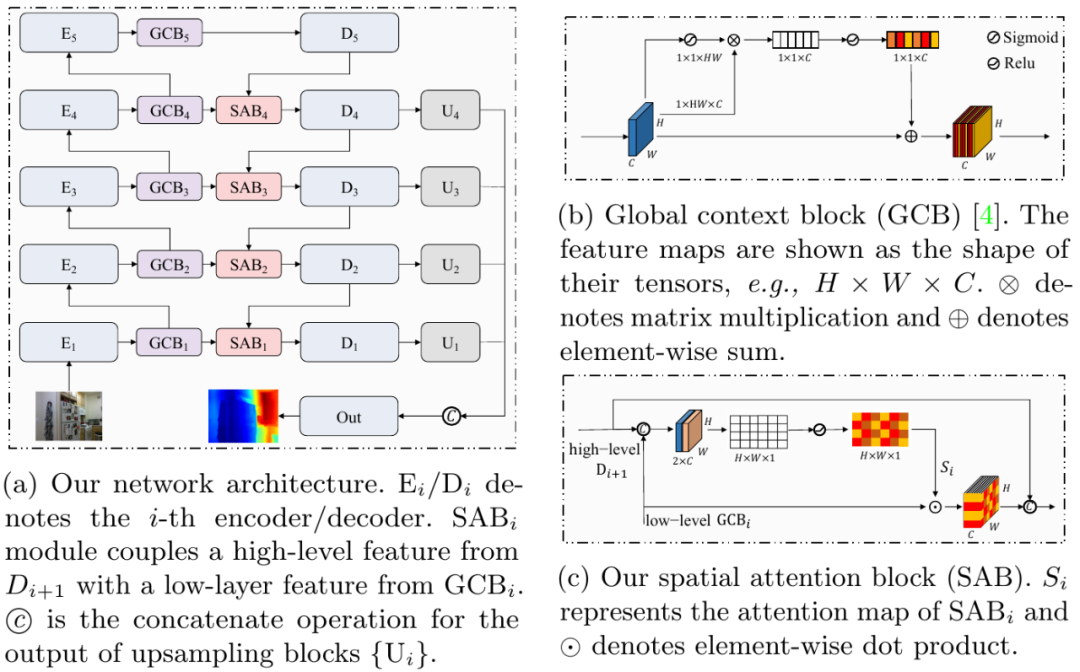
这篇论文基于编码 - 解码结构的 U 形网络进行设计,为多级特征图添加了从编码器到解码器的 skip 连接层。编码器主要提取语义特征,解码器则更加关注空间结构信息。包含全局上下文信息的 GCB 模块在编码阶段应用于每个残差模块,以重新校准通道特征。校准的特征与高级特征组合,作为空间注意力机制 SAB 模块的输入。
其中 SAB 是这篇论文提出的一种新颖的空间注意力机制模块。从空间角度来看,GCB 模块用于全局强调语义信息,而空间注意模块则侧重于图像局部区域模块的权重调节。
GCB 和 SAB 注意力模块可以构建三维注意机制以指导特征选择。如图 3 所示,其中低分辨率 SAB 特征图用于指导全局空间布局信息的选择,而高分辨率 SAB 特征图用于强调细节信息。经过选择后的多尺度特征图融合后经过上采样层输出最终深度图。
![]()
论文的 SAB 模块专为单目深度估计而设计,旨在优化像素级回归任务中的几何空间布局。SAB 模块通过 1×1 卷积层对串联特征进行挤压操作,以在其通道尺寸上聚合空间上下文。然后,激活局部特征以获取注意力特征图,该图对所有空间位置上的像素深度信息进行编码。低层特征与该特征图进行逐像素相乘,以进行后续融合,获取高层传递的空间上下文信息。因此,SAB 能生成具有空间信息的权重图,以重新校准 GCB 的语义特征。
![]()
SAB 的表达式如上,其中 f 是融合函数(例如按元素求和,按元素点积或串联),∗表示 1×1 或 3×3 卷积,⊙表示按元素点积。由于深度图的元素值呈长拖尾的正值分布,因此将 ReLU 用作激活函数σ(x)。如图 3 所示,使用 SAB 获得的注意力特征图有助于网络选择跨不同尺度的特定空间信息。其中,S4 能够描述语义层级关系,帮助网络捕获 3D 空间整体的远近结构。空间注意力特征图越接近 S1,能够使网络关注更加局部空间的信息,如物体边界。
这篇论文的损失函数由四种损失函数构成,包含已开源的 Berhu 损失,尺度不变性梯度损失,法向损失和这篇文章提出的 GFRL 相对损失,我们参考相关文献将这些 loss 进行合理的组合,从而使网络更好的收敛。
GFRL 损失(global focal relative loss)
为了更好地约束全局像素间的相对关系,这篇文章在相对损失函数(Relative Loss,RL)的基础上引入了焦点损失概念(focal loss),可以通过减少易判断空间远近点对的权重,使得模型在训练时更专注于难以区分远近的点对。为了确保点对的均匀选择,将图像细分为相同大小的 16×16 块,并从每个块中随机采样一个点,训练网络时,会将每个点与同一图像中的所有其他点进行比较,从而使网络表现出更好的全局结构约束性能。第 k 对点的相对损失函数如下式所示:
![]()
其中 rk 是真值的点对相对关系,如果第一个点的深度值比第二个点小时,rk 设置为 - 1,反之为 1。深度差值比率小于阈值 0.02 时,rk 设置为 0。与传统的相对损失不同,GFRL 引入一个调控因子来衡量点对的相对损失权重。当一对像素在预测中具有不正确的序数关系时,调控因子权重接近于 1,相当于传统的相对损失函数。当深度序数关系正确且深度差足够大时,则对该点对的调控因子将变为 0。因此 GFRL 能是网络在训练时专注于错误的像素对。参数γ调整点对的权重调节幅度。当γ= 0 时,GFRL 相当于传统相对损失函数。随着γ的增加,调制因子的影响变大,这篇论文在实验中将γ设置为 2。实验证明,在各种评估指标下,GFRL 都优于 RL。
边缘感知策略(Edge-aware consistency)
现有的大多数单目深度估计方法都无法准确地估计边缘区域,生成的深度边界有一定扭曲和模糊。为了使网络更好的区分前后景且保持平面的平滑,这篇论文在训练的过程中引入了边缘感知策略,从而在深度预测结果中保留前后景深度的断层。首先使用 Canny 边缘检测算子提取深度图的边缘,然后对这些边缘进行扩张以得到边界区域。在这些边界区域调大训练权重以显着增加边界区域中预测误差的损失。边缘感知一致性方案作为一种难例挖掘方法,在边界区域提升效果显著,如图 4 所示:
![]()
这篇论文在现有深度估计的方法上总结了六种挑战性场景,并尽可能在开源数据集上搜集这些场景。然而现有开源的深度数据集场景非常单一,难以提供足够的 hard case 数据。这篇论文针对这一现状,设计了数据采集方案,并整理了 HC Depth 数据集。论文作者使用 Microsoft Kinect 收集了 24660 张挑战场景图像,由于 Kinect 的有效距离范围有限,这些图像主要是包含移动人像的室内场景。为了扩充数据集的深度分布范围,论文作者同时使用了 Intel RealSense 收集了 95400 张室内和室外场景的图像,对于室外场景,使用天空分割模型分割出天空区域并赋予最大深度值。此外还对所有深度图进行了空洞补全及平滑处理,提升数据质量。HC depth 数据集示例如图 5 所示:
![]()
![]()
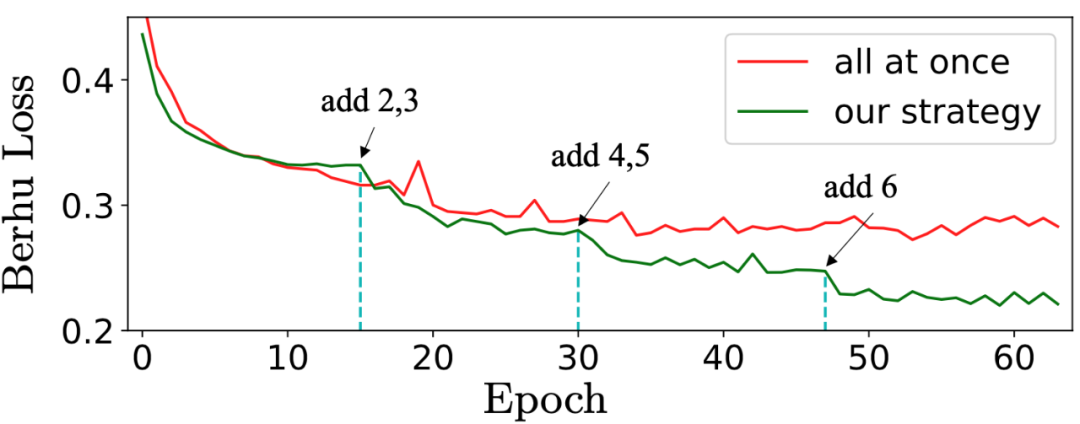
为了训练通用的单目深度估计模型,这篇论文在多个不同的数据集上进行训练。在非凸函数的全局优化中,深度数据在各种场景中的分布不同,导致训练时难以收敛。这篇论文受到课程学习的启发,提出了一种增量式数据集混合策略,以加速网络训练收敛并提高训练模型的泛化性能。首先,在具有相似分布的数据集上训练模型,直到收敛为止。然后逐一添加更难学习的不同深度分布的数据集,并为每个 batch 构建一个新的采样器,以确保从这些不平衡的数据集中进行均衡的采样。训练收敛过程如图 6 所示:
![]()
图 6:多数据集训练策略的 BerHu loss 收敛曲线
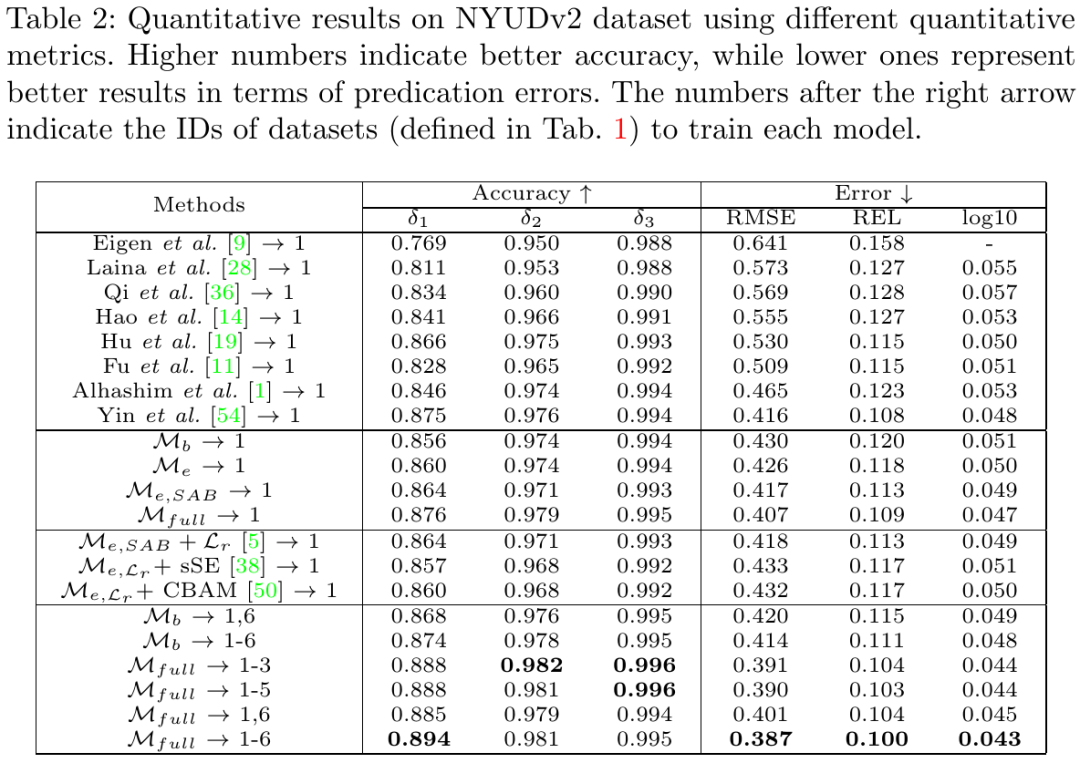
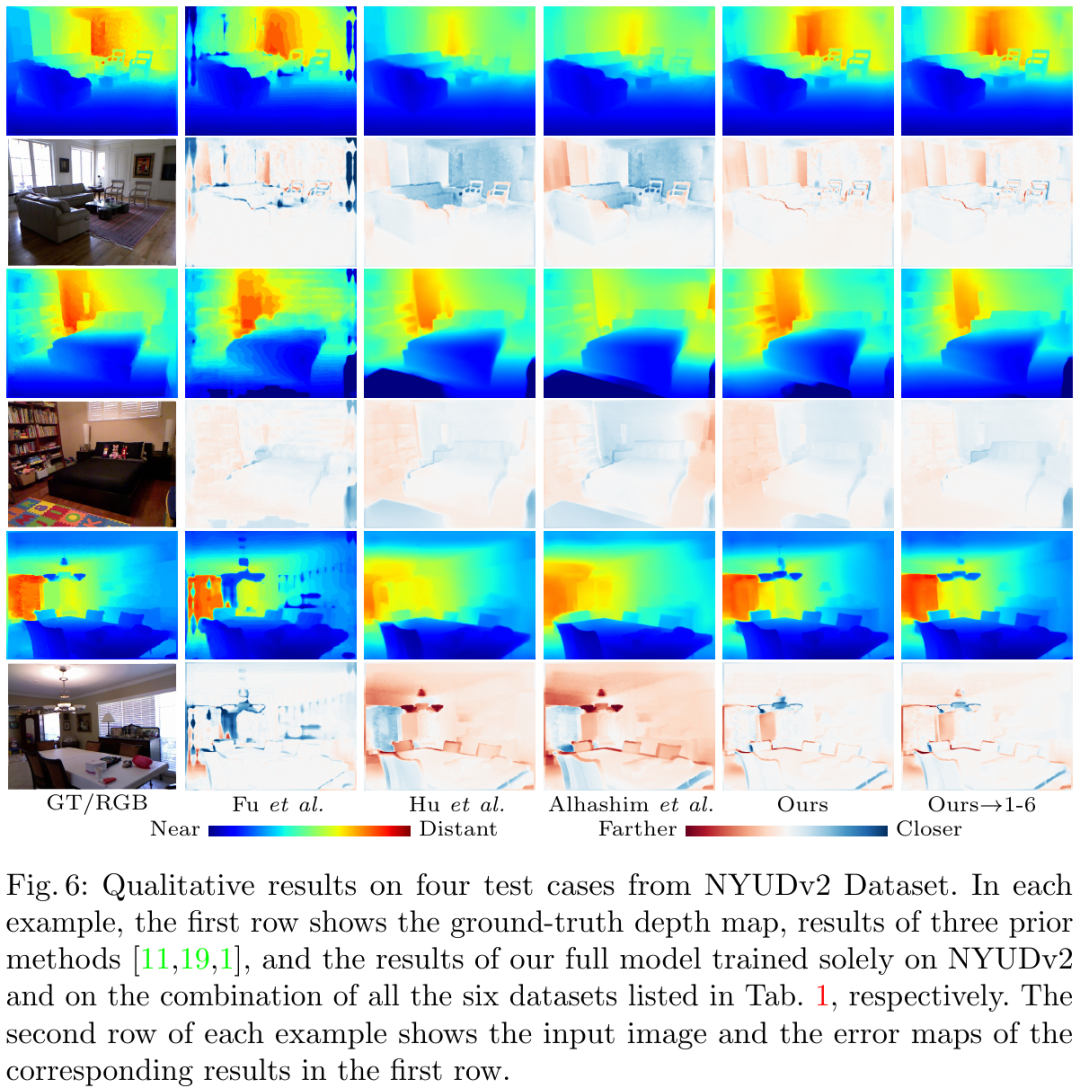
作者对比了当前最优的深度估计算法,在 NYUv2 开源数据集上的指标对比结果和视觉对比结果见下图,可以看出该论文方法在深度图整体及细节上均好于 SOTA。
![]()
![]()
![]()
图 9:在 NYUv2 数据集上的点云可视化实验对比
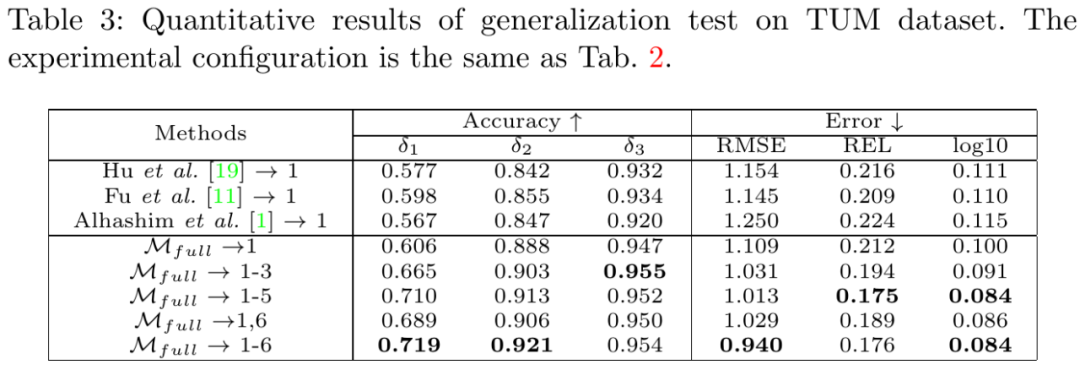
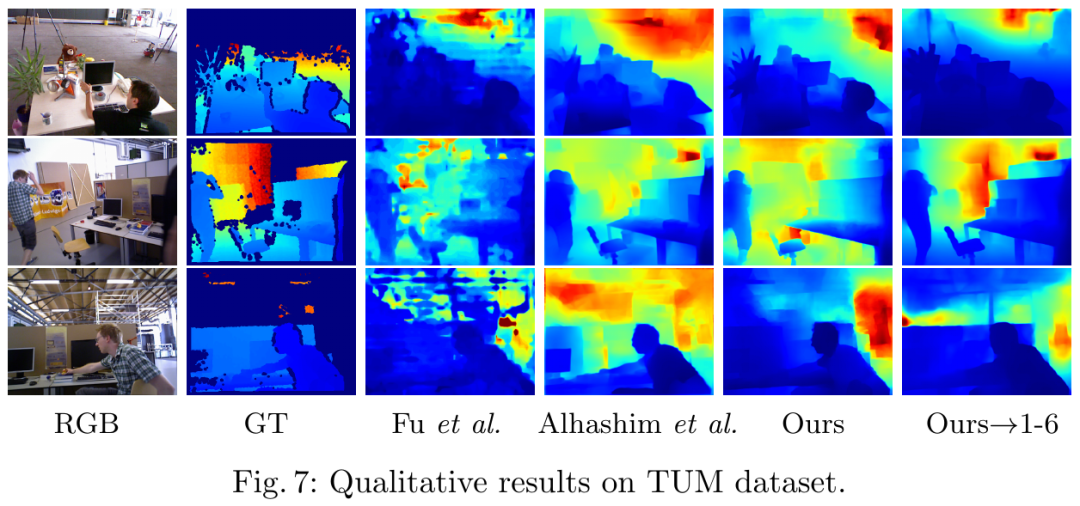
为了进一步验证模型的泛化性能,作者在 TUM 数据集上进行了方法对比测试如下图,在未见过的场景下,该论文方法预测效果也优于 SOTA。
![]()
![]()
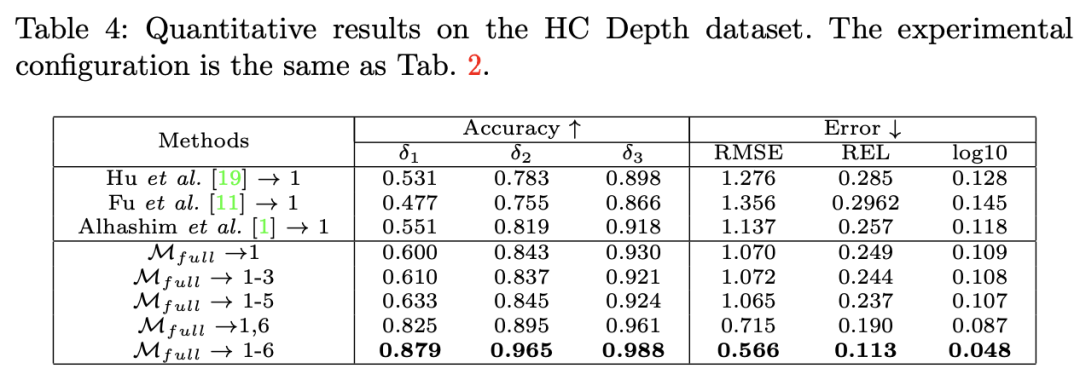
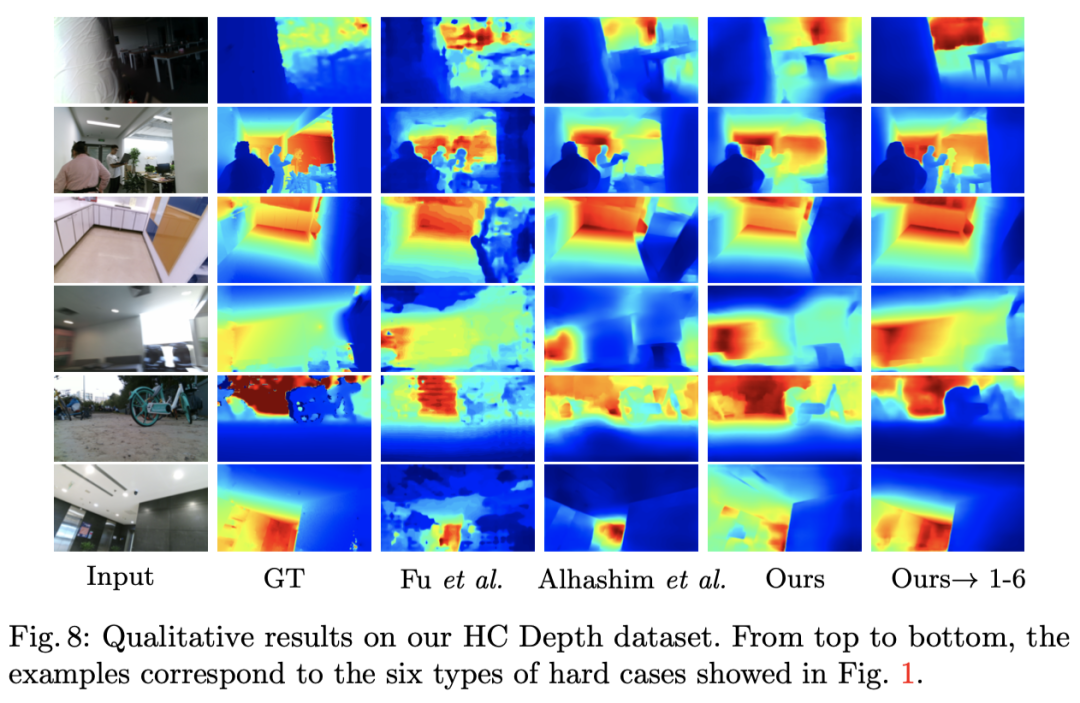
最后,为了说明该论文方法在各种具有挑战性场景下的有效性,作者在自采的 HC Depth 上进行了对比测试如下图,可以看出该论文的方法远好于 SOTA。
![]()
图 12:在 HC Depth 数据集上的 hard case 性能测试实验
![]()
图 13:在 HC Depth 数据集上的可视化测试实验
基于深度信息业界已经有了很多相关的落地应用,快手利用深度信息也支持了很多应用的上线落地,如混合现实、3DPhoto、景深虚化等。
传统的增强现实 (AR) 技术一般只有空间定位功能,缺少环境感知、深度测量、实时光照等高级能力,虚拟和现实难以真正的融合和交互。快手利用单目深度估计技术实时感知和理解场景的几何信息,并将其与传统的 SLAM/VIO 技术相结合,同时完成了空间计算和场景重建,结合自研的 3D 渲染引擎,打造了移动端的 MR 混合现实系统,给用户带来更逼真、沉浸、新奇的虚实交互新体验。该技术方向大大减少了对特殊硬件 (如深度传感器) 的依赖,可以只利用现有手机硬件实现,技术的普适性可帮助几乎所有用户无门槛使用 MR 技术。用户通过快手的 MR 混合现实系统可以实时体验虚实遮挡、体表运动、虚拟打光、物理碰撞等虚实交互特性。快手最近半年已上线了 “新春灯牌”、“辞旧迎新”、“蹦迪滤镜” 等多款 MR 魔表,是国内首家上线该技术的公司,激发了用户的创造力,提升了用户拍摄生产欲望。
3D 照片是近两年比较热的研究方向,通过对单张图片进行重建,可以让这张图片动起来,产生伪 3D 的交互效果。其产生的玩法是沉浸式的,可交互的,可以给用户带来新颖的体验。快手通过单目深度估计网络对静态图片进行稠密重建,结合人像分割、人脸三维重建、图像背景修复等技术,可产生生动逼真的 3D 立体照片效果。利用快手 Y-tech 自研的 YCNN 推理引擎,所有的模型都是在用户的移动设备上运行,没有设备机型和数据传输能力的限制,可让每位快手用户都能体验到这一新奇玩法。目前这项功能已在快手主 APP、一甜相机等多款 APP 上线。
用户在使用单反设备进行拍照时,可以拍出具有浅景深的大光圈照片,它突出了拍摄主体,让画面变得更富层次感,并将背景转化为柔美的光斑。这样的景深虚化功能能明确主次,增强画面美感,提升用户的拍摄质量。在手机上实现大光圈的效果需要有场景的深度信息,快手利用深度估计网络获取到的深度图后,结合人像分割实现了逼真的虚化效果。目前该功能已经在一甜相机完成上线,支持多种光斑形态的景深虚化以及动感和旋集等新效果。用户对该功能满意度很高,进入虚化功能到保存的渗透率高达 70%。
Y-tech 团队是快手公司在人工智能领域的探索者和先行者,致力于计算机视觉、计算机图形学、机器学习、AR/VR 等领域的技术创新和业务落地,不断探索新技术与新用户体验的最佳结合点。目前 Y-tech 在北京、深圳、杭州、Seattle、Palo Alto 有研发团队,大部分成员来自于国际知名公司和大学。
Amazon SageMaker 是一项完全托管的服务,可以帮助开发人员和数据科学家快速构建、训练和部署机器学习 模型。SageMaker完全消除了机器学习过程中每个步骤的繁重工作,让开发高质量模型变得更加轻松。
现在,企业开发者可以免费领取1000元服务抵扣券,轻松上手Amazon SageMaker,快速体验5个人工智能应用实例。
![]()
© THE END
转载请联系本公众号获得授权
投稿或寻求报道:content@jiqizhixin.com