【论文解读】基于Transformer增强架构的中文语法纠错
论文介绍
论文名称:基于Transformer增强架构的中文语法纠错
论文作者:王辰成,杨麟儿,王莹莹,杜永萍,杨尔弘
发表于:第十八届中国计算语言学大会(CCL 2019)
-ONE-
简介
语法纠错(Grammatical Error Correction, GEC)任务,旨在利用自然语言处理技术,自动识别并纠正非中文母语学习者书写的文本中所包含的语法错误,拼写错误,语序错误,标点错误等等,是自然语言处理的一项重要任务。下面这对语句就是语法纠错任务的一个示例,每个输入对应一个输出,左侧输入的是一句可能带有错误的文本,右侧输出的是纠正后的结果,句中红色的字是有修改的地方。
这个软件让我们什么有趣的事都记录。
↓
这个软件能让我们把有趣的事都记录下来。
本文采用基于多头注意力机制的Transformer序列生成模型作为我们的纠错模型,并且提出了一种动态残差结构,能够增强模型挖掘文本语义信息的能力。由于中文语法纠错的训练语料过少,无法充分训练序列生成模型,我们提出了一种腐化语料的单语数据增强方法,能够有效的扩大训练集的规模,并进一步提升模型的纠错效果。
-TWO-
基于动态残差结构的Transformer模型
Transformer模型
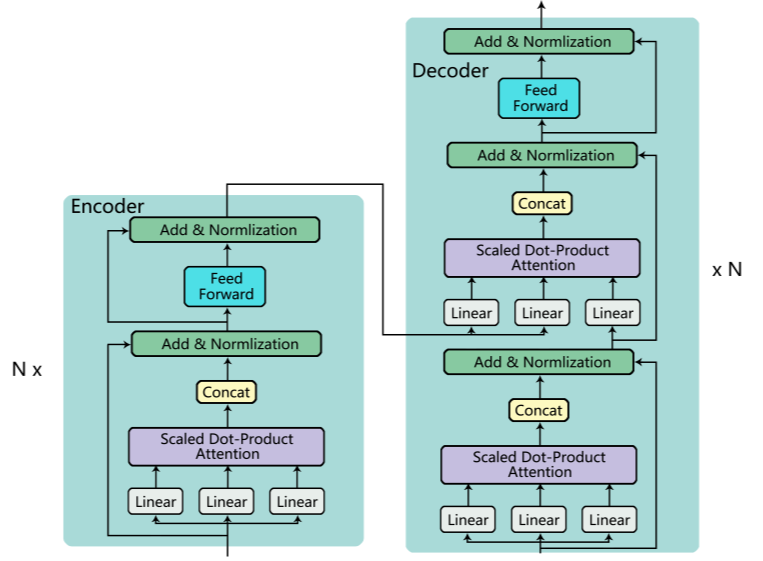
Transformer模型是一种基于多头注意力机制的序列生成模型,编码器(Encoder)负责将输入文本编码为高维隐含语义向量,解码器(Decoder)依据上一步解码的输出,解码隐含语义向量为当前步骤的输出向量,每个步骤的输出向量对应一个字,所有步骤输出的字拼在一起得到最终输出的句子。编码器与解码器中,每个独立的层后都有一个归一化层以及一个残差结构。归一化层用于将经过的向量值映射到0-1之间,加快模型的收敛速度;残差结构的作用是使得模型深度过深时,梯度不会为0。
动态残差结构
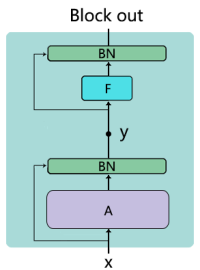
模型中的神经模块(Block)可以简化为上图的结构,所以,每个模块的输出可以表示为如下的公式:
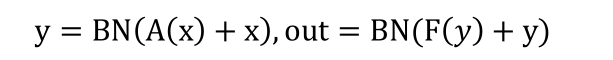
其中BN表示归一化函数,A表示注意力操作,F对应的是前馈层的线性变换,求导后得到:
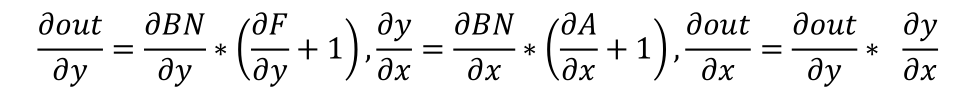
可以看到,虽然模块中有两个残差结构,但是求导后依旧存在乘法因子。随着模块的增多,这个因子会被连乘累积起来,导致模型仍旧存在梯度消失的可能。我们将所有神经模块的输出的累加作为最终的输出,如下图所示,这样模型损失误差,可以传递到任意深的模块。
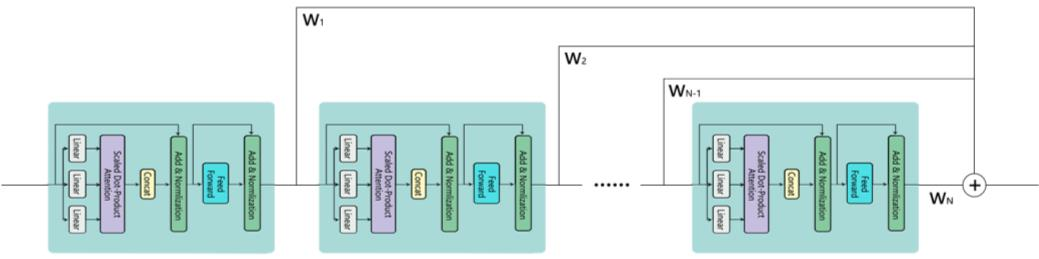
受到 ELMo工作启发,我们认为在不同的神经模块中学习到的知识可能有互补的作用,即高层的神经模块的状态可以捕捉到词语意义中和语境相关的特征,而低层的可以找到语法方面的特征,将所有模块的输出动态地结合到一起,可以表达更加丰富的语义信息。具体计算如下:
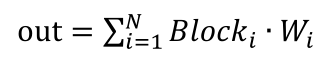
这种动态的残差结构,可以应用到Transformer模型的编码器或者解码器端,不仅能够帮助模型捕获更加丰富的语义信息,其中的残差结构还可以减少因为模型过深而带来的梯度消失的问题,帮助深度神经网络更好的训练。
-THREE-
基于腐化语料的单语数据增强方法
互联网中存在着大量的中文单语数据,即完全正确的中文语句。在这些容易获取且完全正确的单语语料中,合理地添加错误,即可得到大量的语法纠错并行语料。因此,我们认为可以将人们常犯的错误按照添加删除替换的规则简单区分为,多字错误,缺字错误以及替换错误。我们设计了一种腐化算法,可以根据所需的错误类型比例,对单语语料进行造错,具体实现如下:

腐化后的语料示例:

-FOUR-
实验结果
本文所采用的平行语料包括NLPCC官方提供的Lang-8汉语数据集以及HSK数据集,测试集选用的是NLPCC 2018年公开评测比赛的测试集。
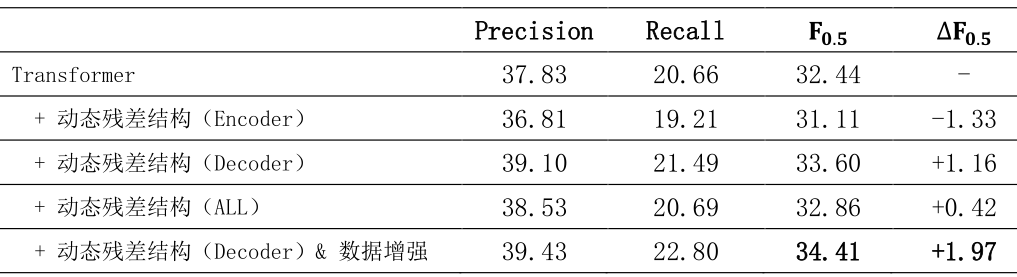
我们分别做了5组实验,来验证本文所提出的方法的有效性,实验结果如下所示。动态残差组的第三第四组实验相对于第一组结果都有明显的提升,但第二组的F值略有降低,对比这三组的结果,我们发现在解码器端添加动态残差结构可以很好地提升模型的表现,但是在编码器端却会损害模型的纠错能力。这也就说明了第四组实验中,F值的提升主要贡献都来自于解码器端而非编码器端。第五组实验是在第三组实验上又加入了数据增强的方法,使得模型的性能达到了最优。
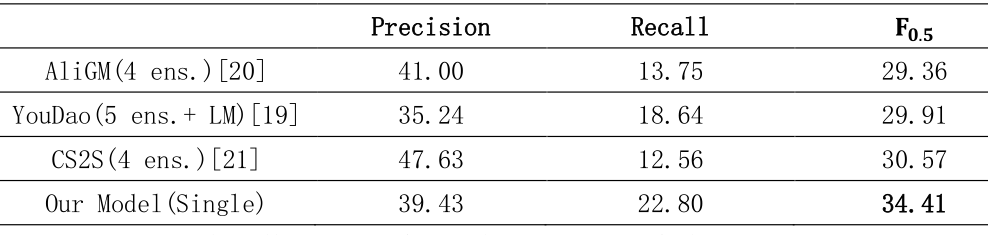
同时,我们与NLPCC2018中文语法纠错共享任务的前三名团队进行了结果的比较。'4 ens.'表示 4 个模型集成的结果,'LM'表示利用了额外的语言模型。从中可以看到,我们模型的F值优于所有队伍的表现,而且该结果是我们仅使用单一模型得到的,没有任何模型的集成和语言模型的使用。
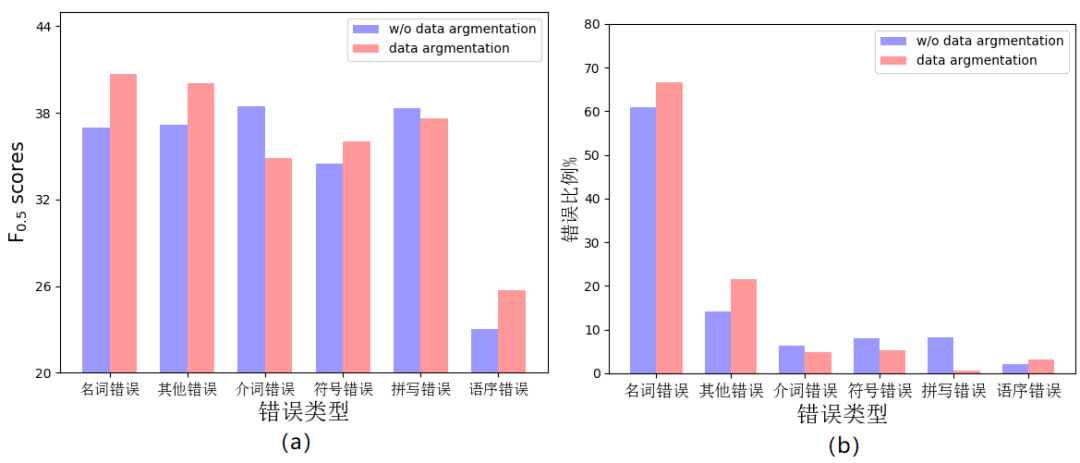
我们同时也分析了数据增强方法的影响,包括对测试集中六种具体的错误类型的F0.5值的影响。从图a中可以看出,使用数据增强方法之后,在名词、符号、语序和其他错误四种错误类型上有着显著提高,而在介词错误与拼写错误上却没有有效提升。图b显示,数据增强方法产生了更多的名词、语序与其他类型的错误,从而增加了这三种错误的比例,降低了介词与拼写错误的比例,比例上增减的变化与对应的F0.5的变化相吻合。因此,数据增强策略应该是能够同比增加不同错误类型的数量。
-FIVE-
结语
本文的工作将语法纠错任务看作是翻译任务,利用基于多头注意力机制的Transformer对错误文本进行改正,同时提出了一种动态残差结构,可以分别结合到Transformer的编码器与解码器端,用以增强模型捕获丰富语义信息的能力。受限于训练数据过少的情况,我们还提出了一种腐化语料的单语数据增强方法,扩充了训练集的规模。这种数据增强的方法可以在任何领域或者语言的单语语料上使用。通过实验进一步验证了我们提出的模型增强与数据增强方法的有效性,在NLPCC 2018中文语法纠错共享评测任务上达到了最优的性能。

编辑:王莹莹

扫码关注我们
BLCU-ICALL
语言监测与智能学习


