SCENE-一个可扩展两层级新闻推荐系统

-欢迎加入AI技术专家社群>>
简介:目前推荐系统仍然具有挑战性的3个原因:1)推荐服务需要进行快速实时的计算;2)大多数场景中,推荐item相互间并不独立;3)对于不同类型的item,经过时间推移,item的流行性和时效性都会经历非常大的变化。在之前的研究中,很多问题还没有得到过探索:1)新闻选择;2)新闻表示的方式;3)新闻处理;4)构建用户画像。
在这篇论文中定位于以上提到的问题,SCENE,a SCalable two-stage pErsonalized News rEcommendation system with a two-level representation.第一层包含了和用户的偏好相关的多种主题,第二层包含了特定的item。我们探索用户和item、以及item推荐给用户时特殊属性(比如流行性和时效性)之间的内在联系。同样的,本系统具有有效地处理大量语料的能力。
SCENE包含三个主要的组件:新发布items聚类、用户画像构建、个性化推荐系统。对于新发布的items,使用LSH(Locality Sensitive Hashing)将其分成多个小组,然后使用概率语言模型(如PLSI及LDA)将这些小组归纳为中间堆。用户画像会构建为三个不同却相关的维度,items主题分布、相似访问模式、新闻实体偏好。根据生成的主题分布,我们依次选择和给定用户画像相似的中间堆,并转化为结果表达的第一层级。在每一中间堆中,隐藏于items中的不同维度中的子模式,激励我们将这种特性采纳于表示成第二层的解决方案中。在一个数据集上大量的实验论证了此方法的有效性。
概要来说,这篇paper的贡献有三个方面:1)新颖的两层结果表示方式;2)新闻选择原则框架;3)多因子高质量用户画像构建
相关工作
目前的推荐系统可以粗略地分为两类,基于内容的系统以及CF系统。
基于内容的系统是从新近发布的文章中找到和用户阅读历史相似的文章,通常使用向量空间模型、语言模型以及一些相似度量方法。
CF系统利用了用户对items的排序,与内容无关。许多CF系统建立于用户过往的排序行为,或者是用一组相似用户的行为预测用户的新闻排序情况,或者用概率的方式将用户行为建模。
SCENE系统和是一种混合的方法,将新闻推荐定义为一个给定预算最大覆盖问题。在新闻推荐新闻内容和命名实体的使用上来看,SCENE系统与EMM News Explorer算法、Newsjunike算法联系比较紧密。
推荐框架

图1简要描述了SCENE的框架。推荐需要由两级程序完成,第一级程序将新闻集分成小组,第二级则是推荐新闻。系统的主要的三大组件将在接下来进行介绍。
1.新闻文章聚类组件:新发布的新闻在LSH算法作用下依据新闻内容被分成小组。为快速定位到小组,采用了层次聚类的方式。然后采用概率语言模型应用于这些小组。
2.用户画像构建组件:用户画像主要用到访问过的新闻内容、相似访问模式以及偏好的命名实体这三类信息--来源于用户访问历史。新闻内容被定义为阅读历史的主题分布;相似的访问模式得自于分析不同用户的点击行为;偏好的命名实体通过NLP工具从访问历史中提取。
3.个性化新闻推荐系统:通过比较每个中间簇与用户访问的新闻内容的主题分布相似度,选择中间簇作为第一层的推荐结果。在每个中间簇内,再比较每个小组与用户访问过新闻内容的相似度,选择最相似的小组作为第二层推荐的基础。在选中的小组内部建立类似给定预算最大覆盖问题的模型,并且用贪婪算法去解决。
新闻文章聚类
给定文章集合N={n1,n2,···,nM}, |N|=M,我们的目标是在N上生成C={C1,C2,···,CK}, K预设,Ci由Gxi = {G1,G2,···}组成,Gj(|Gj| = tj)包含了tj篇文章。每一类及其Gi由主题分布T关联.聚类组件位于SCENE系统第一级。
由于文章之间相似度的计算量大,为了减少不必要的计算,采用LSH方法,将文章大致分类。在本系统中,采用一种基于Jaccard的哈希方法去寻找相同的新闻。这个处理过程可以分为三模块。
分解新闻文章为shingles(固定长度的词串):为克服传统词袋模型的缺点,使用"shingles"表示新闻文章。k-shingle指出现在文章中的长度为k的连续的词语组成的序列。在进行文章分解为shingles这步之前,还需要进行一系列的预操作,比如摘掉停止词,标记以及提取主干。因为典型的新闻文章篇幅适中,经验上我们选择k=10以保证任一shingle出现在任一文章中的低概率。通过shingling,原始的新闻语料可以被量化为矩阵M,行为shingles列为文章。
最小哈希:当语料数量很大时,M对内存来说是一个挑战,所以我们使用最小哈希技术去为M中每列即每篇文章产生一个简洁的签名,因此两篇文章有相同的签名等价于两篇文章的Jaccard相似性。在我们系统中,为每篇文章生成长度为100的最小哈希签名。由于最小哈希的随机性,因此需要对语料中可能存在的有相似性的文章对进行进一步的检查,以增大它们被发现的可能性,我们使用LSH(局部敏感哈希)方法增大这个概率。
局部敏感哈希:LSH方法是用来减少比较次数。将最小哈希产生的结果分解为多个段,对每一个段,我们采用标准的哈希算法将之哈希到一个大的哈希表中。在我们的实验中,选择了段中长度为5。我们将能哈希到同一个桶中至少一次的文章看作相似的,最后原始的文章语料被分为多个小组。
新闻组上的聚类
使用LSH处理过的新闻组数量依然庞大,可能有成千上百个。为了加速文章的选择,使用基于平均链接的层次聚类方法,给语料的潜在结构一个优雅的表示。给定一个组群G = {G1,G2,···}, 层次聚类将为G产生一个树状图H。根据预定义的数据K,将会分割H得到K个群。这些群将成为推荐结果第一级的基础。
讨论:我们使用"LSH+层次聚类“方法将原始语料分成多个群。有人也许会质疑这将导致准确率上的下降。另外的选择是直接在原始语料上使用标准的k-means方法以及直接的层次聚类方法。然后这两种方法在处理语料的数量极大时,无法一直保证效率,并且当数据集增大时,无法保证精度。并且在推荐新闻文章时,无法快速定位到用户感兴趣的小组。在实验中,我们会证明这些断言。
新闻主题探测
使用LDA去寻找潜在的主题,并将小组的主题分布使用主题向量表示出来,每一项代表了相应主题词的权重。
讨论:LDA方法与PLSI在数据集很大时功能等价,LDA假设有一个狄利克雷先验。LDA在数据量小时可以预防过拟合。第7部分探讨LDA与PLSI的等价。
用户画像构建
我们建议从用户阅读历史的文章内容、相似访问模式、喜爱的命名实体这三个维度构造用户画像,表示为U = <T, P, E>。
T:表示用户看过的文章历史,{<t1,w1>,<t2,w2>,...},t代表主题词,w代表相应的权重。
P:代表users<u1,u2,...>,与用户相似的用户集合
E:从用户浏览历史中提取的用户喜爱的命名实体<e1,e2,...>
新闻内容的概括
使用与4.3节中所述相同的表示方法表示用户消费历史。
访问模式分析
实际上,许多用户有着类似的阅读偏好。一个用户的画像信息可以通过研究其它用户的阅读偏好去丰富。通过计算用户阅读历史的Jaccard Sim,给定用户相似阈值,则可以离线地将与用户相似的用户添加到用户画像中。
命名实体
命名实体包括哪里、发生了什么、谁等等这些信息。有些读者可能对文章中的某些特殊实体有特别的偏好。为提取命名实体,我们采用NLP TOOLS-GATE,通过预定义一些规则,它可以自动地识别出来这些命名实体。
个性化推荐
这里我们有一个两级的推荐层次结构。第一级是简洁地对用户可能喜爱的主题分类的一个归纳,第二级给出与用户阅读历史相似的特定文章。这个组件位于系统第二层结构当中。
第一级表示的兴趣匹配
我们考虑用户阅读历史与每一个群的相似性,V是所有主题词组成的向量,TC为群主题分布,TU为用户主题分布,Sim(TC,TU)= TC ·TU /(||TC||*||TU||) (公式1)。|TC|=|TU|=|V|。通过给定一个阈值,可以选择到合适的群。进一步地,在群中通过相同方法选择合适的小组,作为第二级推荐的基础。
第二级表示的新闻选择
每一条候选新闻都有其文章的画像。我们将此级推荐问题看作给定预算最大覆盖问题,并且用贪婪算法解决它。
新闻画像构建
新闻画像既包含静态特征(如主题分布、命名实体),也有动态特征(访问用户)。持续地优化新闻画像有助于优化新闻语料的使用。比如流行度可以定义为访问此新闻的读者与读者池的总数。
在SCENE中,新闻画像有助于比较两篇新闻,评估为何这篇新闻会使用户满意。这两种类型的比较的计算在同一设置下。给定新闻画像Fn =<Tn,Pn,En>,以及用户画像Fu =<Tu,Pu,Eu>, 两者的相似度计算方法如图所示。 α, β 以及 γ是控制三个维度的参数。Sim(Tn,Tu)通过公式1进行计算,Sim(Pn,Pu)、Sim(En,Eu)通过Jaccard方法进行计算。
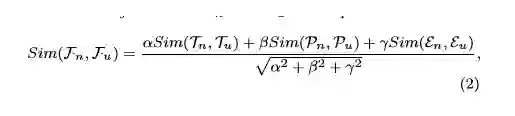
次模简介
E为有限集合,f为定义在E子集上的实值非减函数,并且满足f(T ∪{ ς})−f(T)<= f(S ∪{ ς})−f(S), (公式3) 。S ⊆ T,且S、T都为E子集,ς ∈ E\T。这样的函数称为次模函数。这样的减少的属性存在于许多领域中,如社会网络中,在大集群中增加一个人所产生的社会影响会小于在小集群中增加一个人产生的社会影响。
给定预算最大覆盖问题在这里描述为:给定一个集合E,包含了很多元素,这些元素都包含有一个影响以及开销,以及预算B。目标就是找到E的一个子集可以有最大的影响同时开销不超过B。这个问题是一个NP问题。文献【16】提出了一种贪婪算法可以顺序的通过纳入元素,使得在开销限制之内增大影响,并且保证结果的影响是(1-1/e)-近似。次模的思想存在于每一步纳入操作。
推荐中的次模模型
用户关注的东西很可能是相应主题上的微小差别,比如电影《盗梦空间》,有些人关注演员表,有些则关注其中的高端技术。因此基于某些直觉,我们新闻的选择策略描述如下:(N 代表最初的小组, S代表选择的新闻集, ς 是选择出的新闻)
S与N\S集合在一般话题上应该相似
S中的话题差异不应该过大
S应该提供在给定用户阅读偏好时提供较大满意度
给出公式:
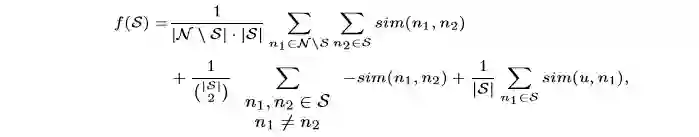
公式第一项说明S的代表性,第二项代表了选中S集合中新闻的差异性,第三项代表了可能的用户满意程度。注意到这三项其实都是次模函数。ς的增益可以表示为I(ς)=f(S∪{ ς})−f(S). (公式5) 。在推荐数目给定的条件下,得到最大的增益。在每个小组中均采用贪婪算法去取top N来组合成最终的结果集合,每个组中取的新闻数与用户对每个主题偏爱权重成正比。
排序调整
从各个小组中取来的新闻文章合成一个列表时需要重新排序。这里利用流行度与新近性特征来进行重排序。nP为流行度,nI为新近性。
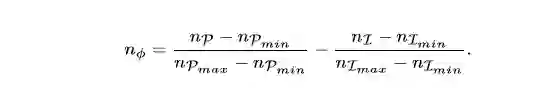
原文:http://x-algo.cn/index.php/2017/07/05/2009/

↓ 点击阅读原文,进入学院




