SPN 介绍2
https://arxiv.org/pdf/1202.3732.pdf
Sum-Product Networks: A New Deep Architecture
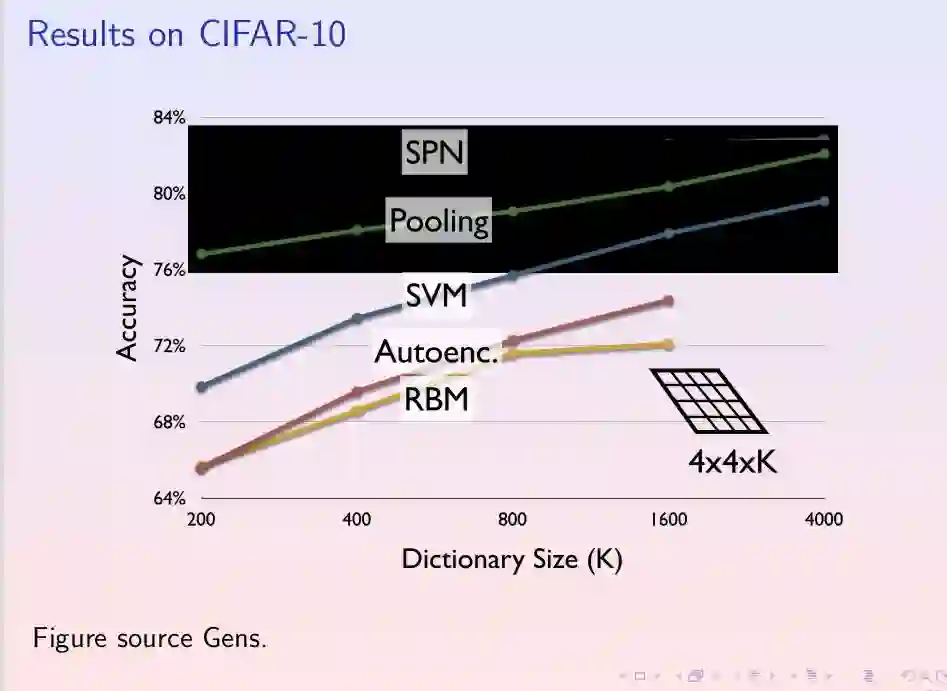
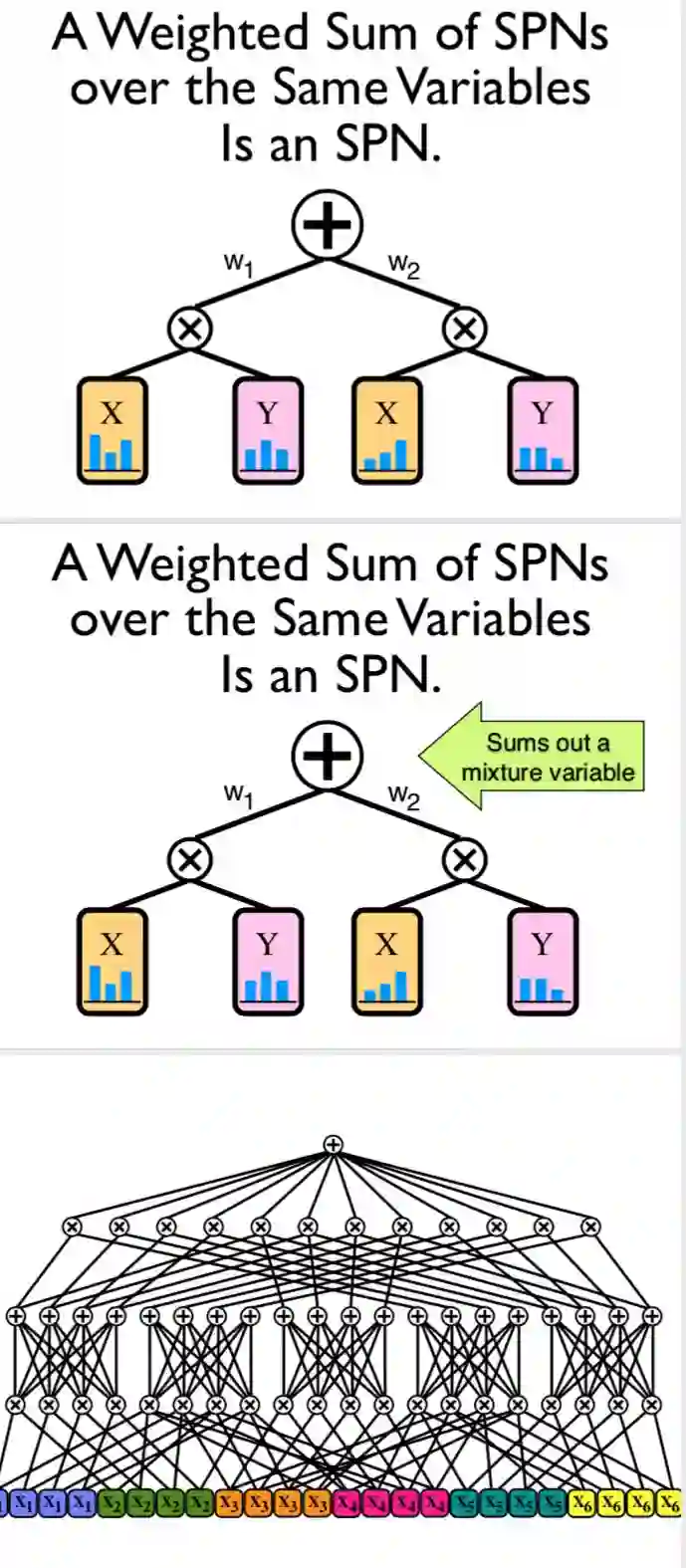
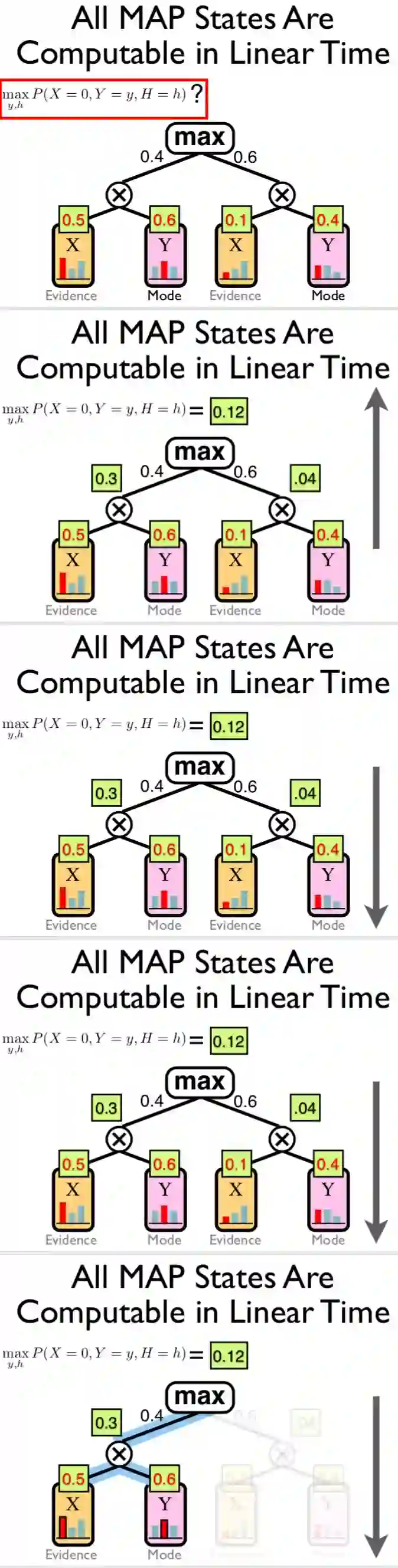
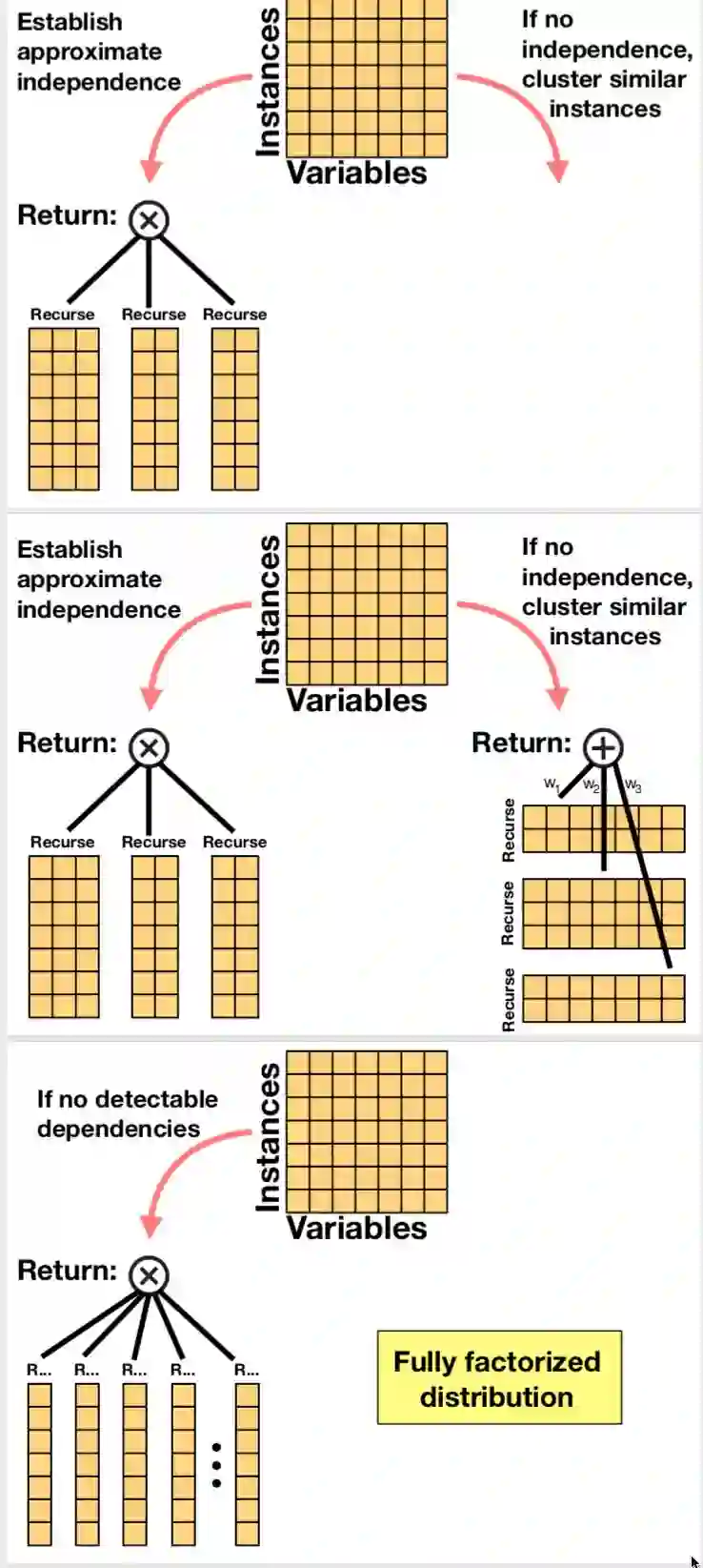
Abstract The key limiting factor in graphical model inference and learning is the complexity of the partition function. We thus ask the question: what are general conditions under which the partition function is tractable? The answer leads to a new kind of deep architecture, which we call sumproduct networks (SPNs). SPNs are directed acyclic graphs with variables as leaves, sums and products as internal nodes, and weighted edges. We show that if an SPN is complete and consistent it represents the partition function and all marginals of some graphical model, and give semantics to its nodes. Essentially all tractable graphical models can be cast as SPNs, but SPNs are also strictly more general. We then propose learning algorithms for SPNs, based on backpropagation and EM. Experiments show that inference and learning with SPNs can be both faster and more accurate than with standard deep networks. For example, SPNs perform image completion better than state-of-the-art deep networks for this task. SPNs also have intriguing potential connections to the architecture of the cortex.
1
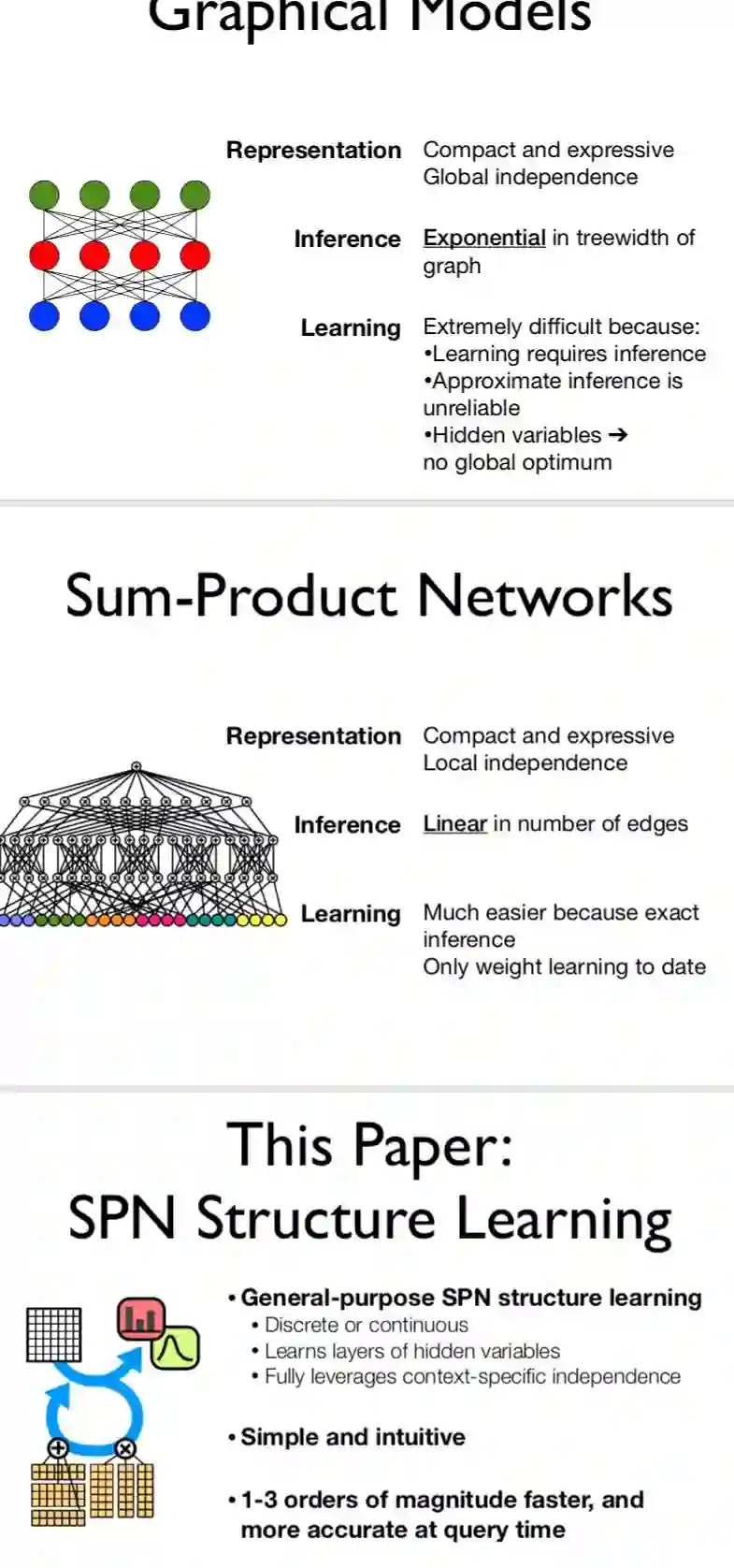
Graphical models have a number of important limitations.
First, there are many distributions that admit a compact representation, but not in the form above. (For example, the uniform distribution over vectors with an even number of 1’s.) Second, inference is still exponential in the worst case. Third, the sample size required for accurate learning is worst-case exponential in scope size. Fourth, because learning requires inference as a subroutine, it can take exponential time even with fixed scopes (unless the partition function is a known constant, which requires restricting the potentials to be conditional probabilities).
This paper starts from the observation that models with multiple layers of hidden variables allow for efficient inference in a much larger class of distributions. Surprisingly, current deep architectures do not take advantage of this, and typically solve a harder inference problem than models with one or no hidden layers
2


awesome https://github.com/arranger1044/awesome-spn#code

2016 ppt



11年ppt
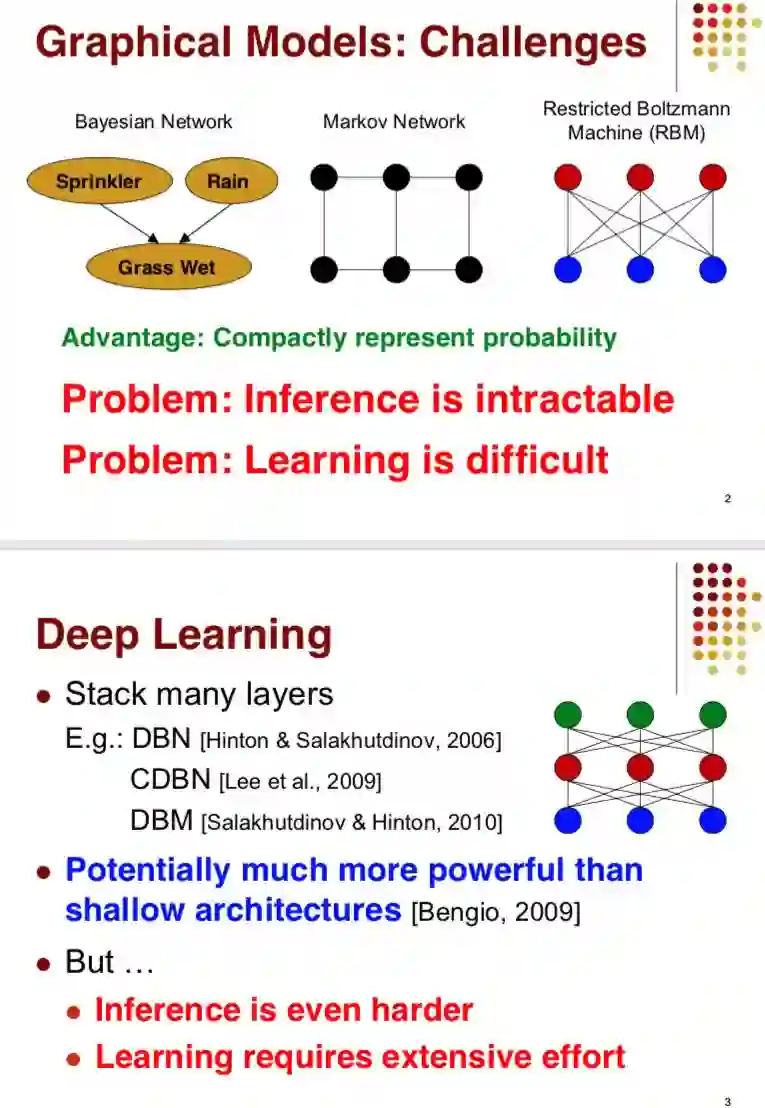





13年ppt



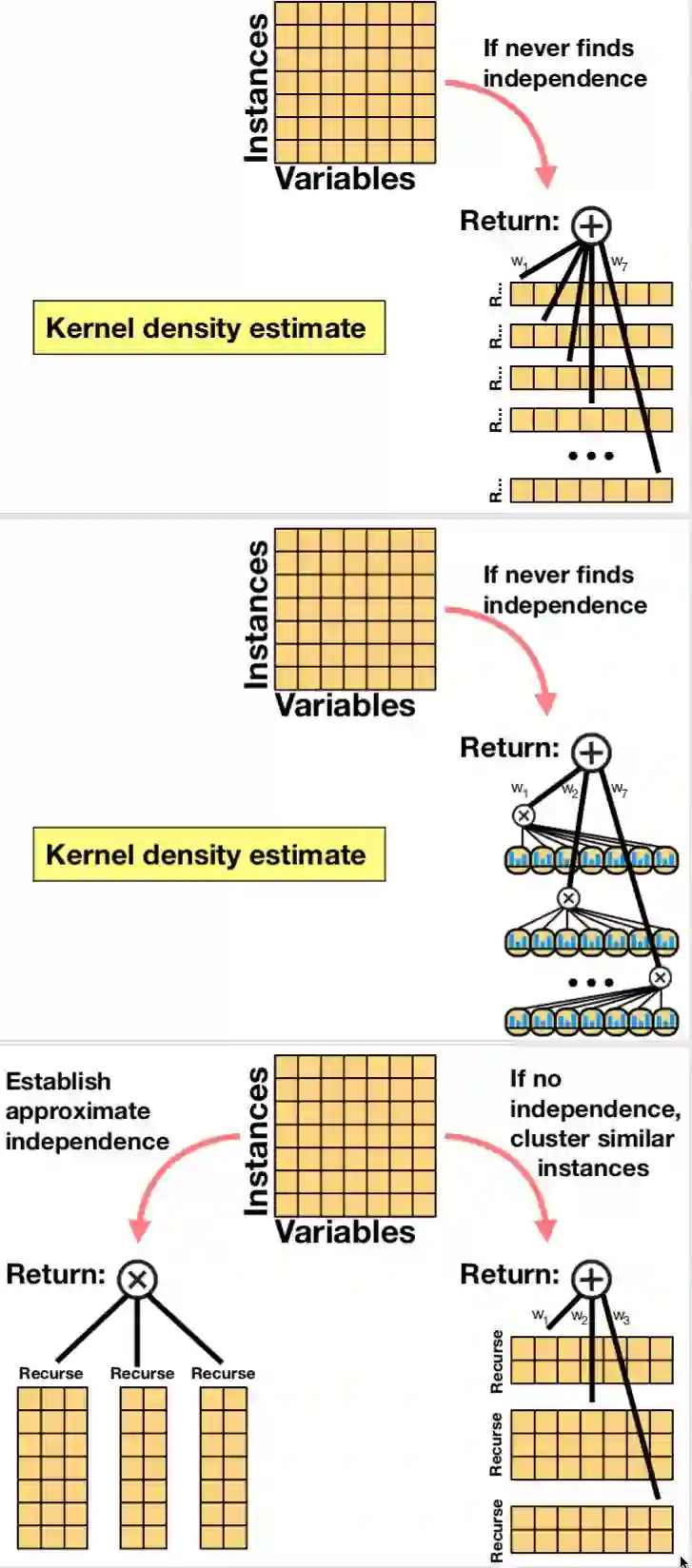
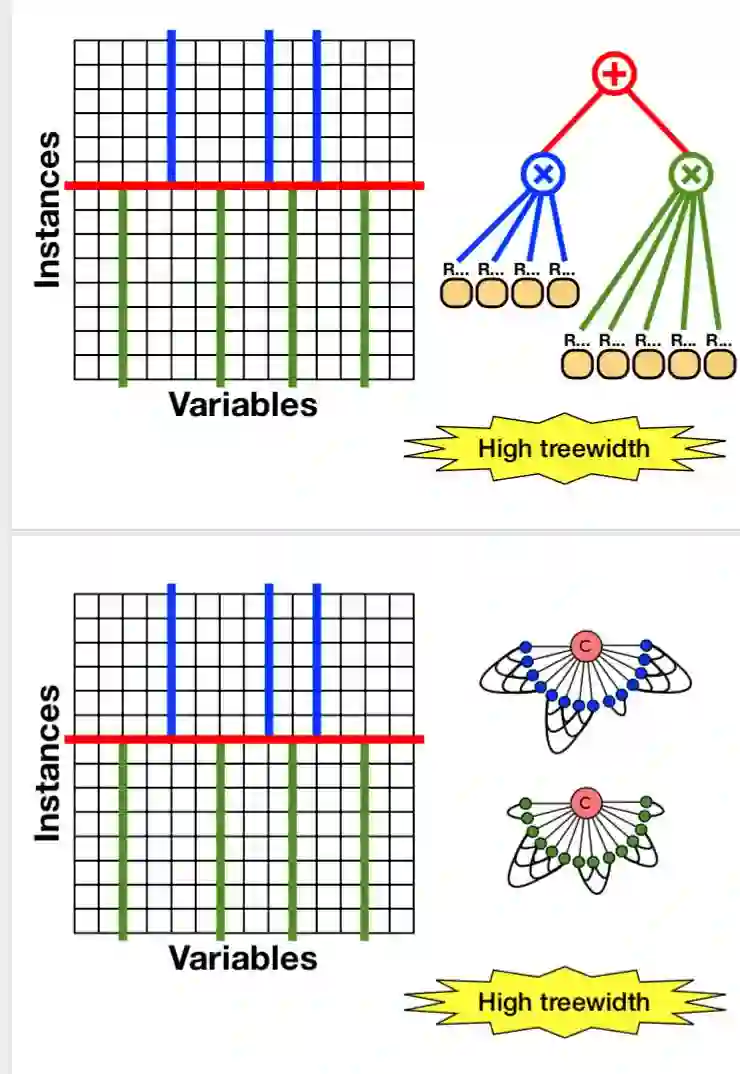
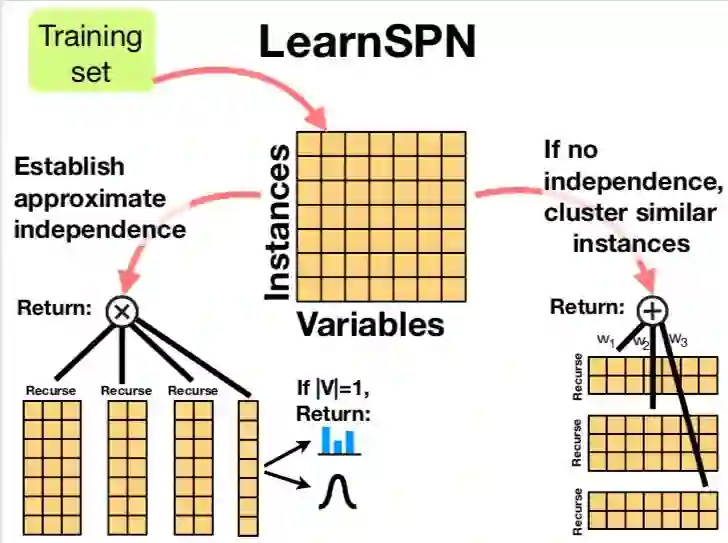
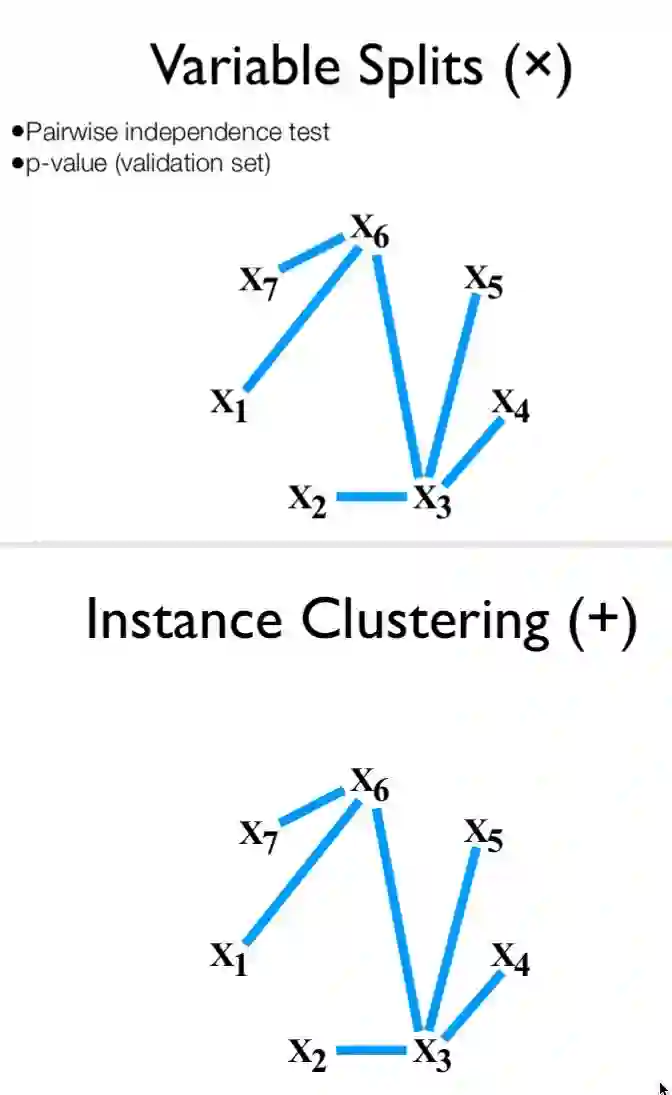
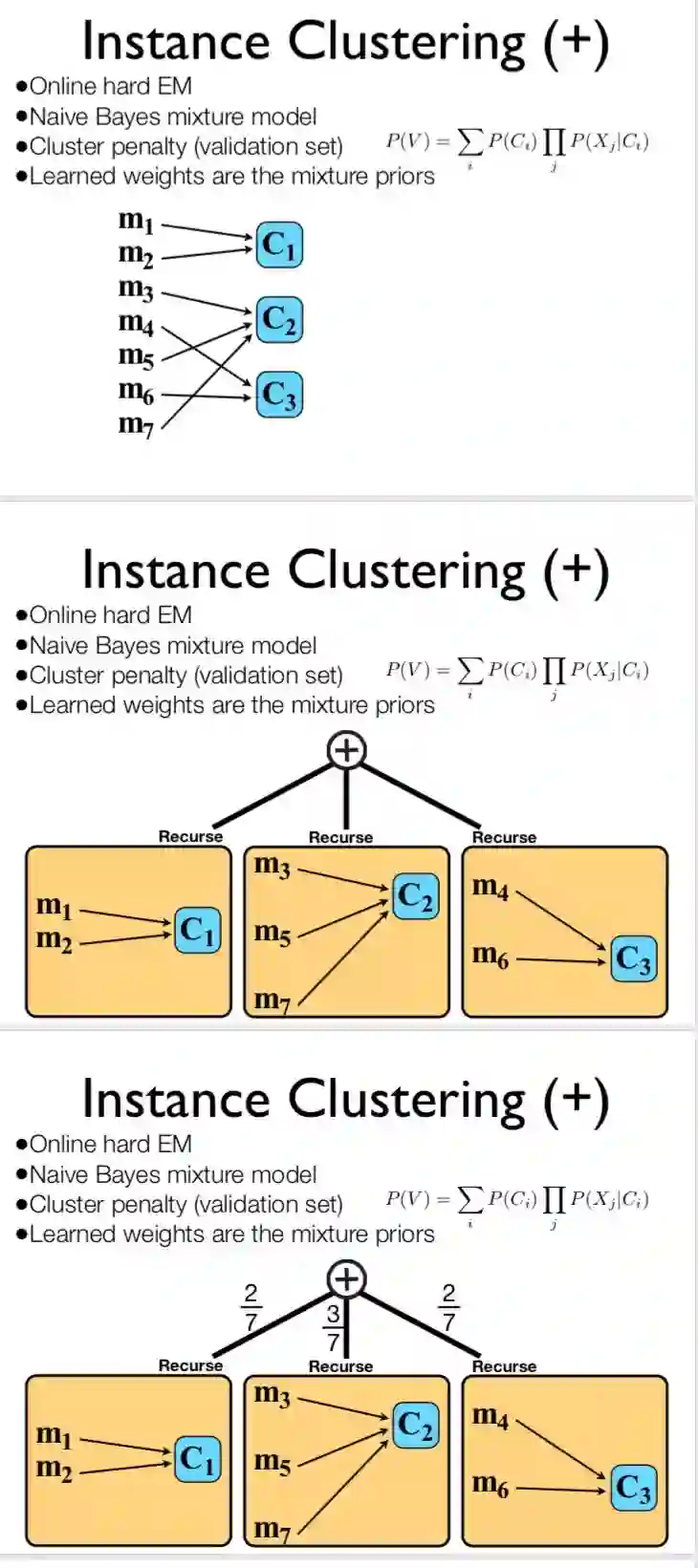
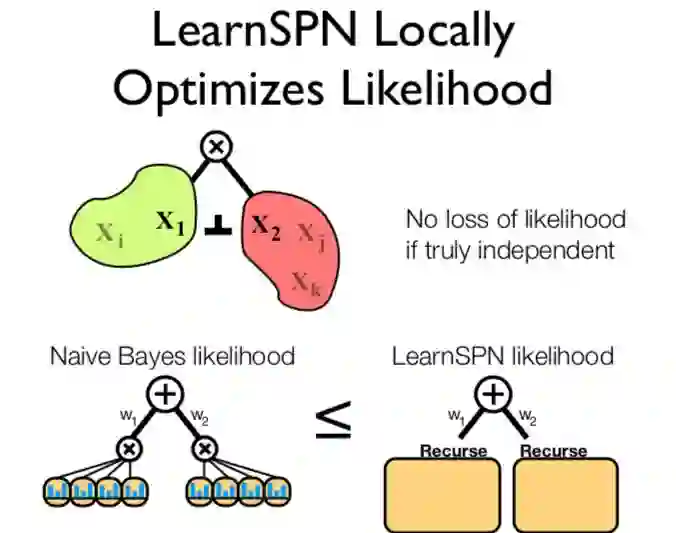
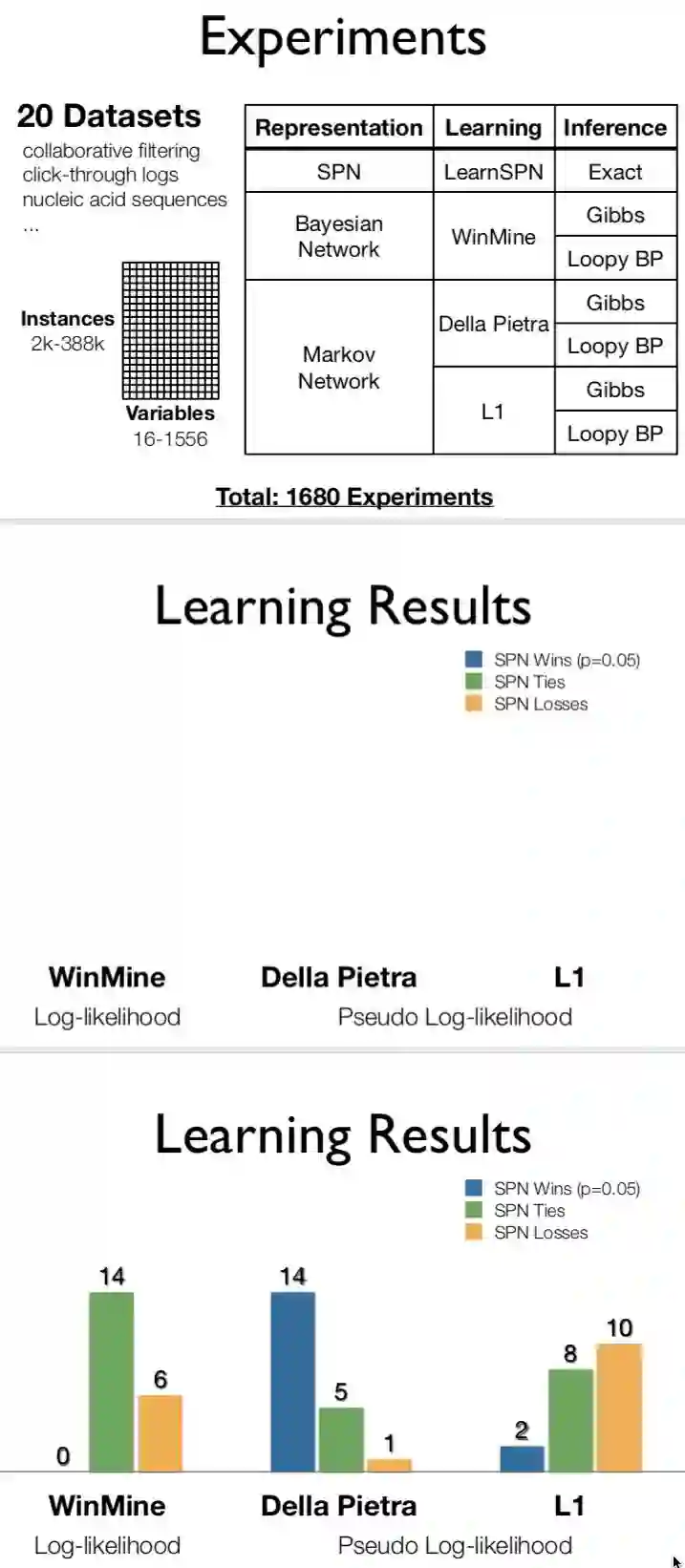
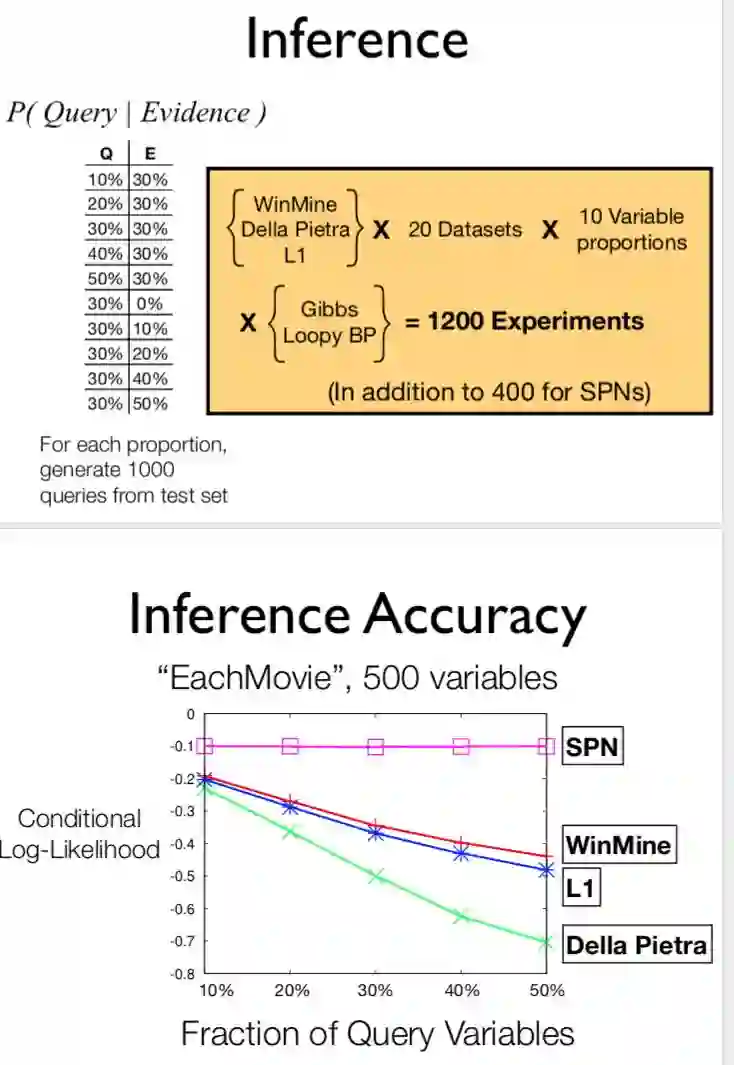

2013 ppt