【VALSE 前沿技术选介17-04期】利用对抗学习改进目标检测的结果
今天跟大家介绍的是近期的一个利用adversarial learning来训练object detector的工作:A-Fast-RCNN: Hard Positive Generation via Adversary forObject Detection. 和目前主流的GAN paper不同,这篇文章的目标是为了用GAN来提升recognition的performance,而不是生成好看的图片。在具体介绍这个工作之前,先给大家讲讲背景故事。
GAN 作为一个生成图像的工具,在近两年已经异常火爆,许多paper一遍遍的刷新了各种酷炫的visualization。最近和某同学讨论,他的评价我觉得很贴切“要评价现在的生成的结果有多差,要等下一篇paper出来后才知道”。当然我不否认GAN在graphics和low-level vision里面起到了很大的帮助,实际上用它来做出来的APP也产生不少的商业价值。但是从machinelearning的角度来看,现在的GAN主要问题有:(i) 作为一种self-supervisised/unsupervised learning的方法并没有体现出学习到low-level feature之上的semantic representation; (ii) 生成的图片结果大部分还是靠肉眼评价,现有的用inception score或者各种给图片“打分”的机制其实并没有很强的说服力。
为什么我说这些“打分”的方法并不十分“靠谱”呢?实际上在A-Fast-RCNN这个工作之前,我尝试将inception score比较高的生成的图片当成额外的负样本来训练imagenet-pretrained的Fast-RCNN。经过非常少数的finetunining, 分类器就能学会把生成的图片分成负样本。也就是说我只需要将“打分器”稍微finetune一下,所有方法生成的图片都会变得很低分。
为什么我说GAN并没有学习出low-level feature以上的representation呢?我尝试对训练图片用GAN做super-resolution /inpainting / adding adversarial noise 各种操作来生成额外的正样本,发现对训练imagenet-pretrained的Fast-RCNN并没有任何的帮助。这说明了用condtional GAN生成的新样本并没有对原图增加新的semantic information(具体的做法读者可以想象在训练GAN的时候把discriminator 替换成FRCNN,这里就不做具体描述)。
针对这些问题,A-Fast-RCNN提出的是与其依赖生成图片本身,不如尝试去改变图片的feature来产生新的training data。具体的做法是,我们在Fast-RCNN的pool5 / roi-pooling 的feature上增加了两个小网络:Adversarial SpatialDropout Network和Adversarial Spatial Transformer Network。根据不同输入样本的feature,这两个network会学习分别对feature进行dropout和rotation。目标是feature在进行dropout和rotation的变化后使得detector的loss 变大。
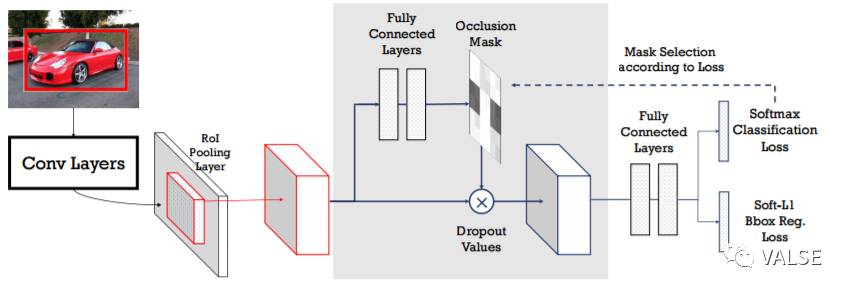
如上图所示,根据pool5 / roi-pooling 的feature生成的mask,最后也会被apply到pool5上对原来的feature进行修改。以下是用我们的adversarial network生成的occlusion mask的样例,黑色的部分表示的是对应的pool5 feature整个channel要被赋值0(spatial dropout)。

看到这个结果,我们其实可以把最近很火的Mask-RCNN也联系起来。Mask-RCNN是在mask branch 的network上额外提供了segmentation signal,直接去训练网络。而我们的mask branch是根据classification的结果来获取signal来训练。
我们在PASCAL和COCO上测试了A-Fast-RCNN证实其有效性,具体的数字可以参考原文。代码也release在:https://github.com/xiaolonw/adversarial-frcnn
Reference:
Xiaolong Wang, Abhinav Shrivastava, and Abhinav Gupta.A-Fast-RCNN: Hard Positive Generation via Adversary for Object Detection. CVPR2017.





