从洗袜子到hbase存储原理解析
来自:互联网侦察

小史是一个非科班的程序员,虽然学的是电子专业,但是通过自己的努力成功通过了面试,现在要开始迎接新生活了。
对小史面试情况感兴趣的同学可以观看面试现场系列。

今天,小史的姐姐和吕老师一起过来看小史,一进屋,就有一股难闻的气味。

可不,小史姐姐走进卫生间,发现地下一个盆子里全是没洗的袜子。


小史:当然不是,盆里的袜子满了,就先放到这个桶里,然后再继续装,等到桶里的袜子满了,然后才放到洗衣机里一次洗完,这样不仅效率高,而且节省水电费。
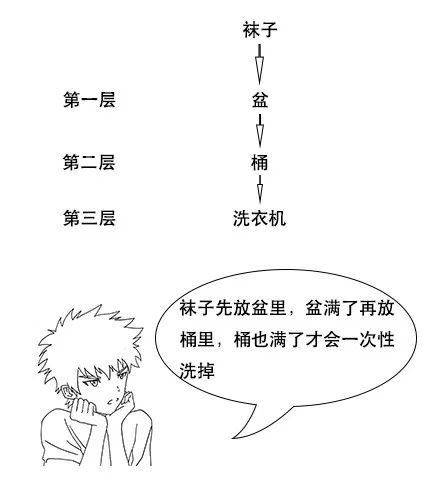
小史洋洋得意地介绍起自己洗袜子的流程。

小史一听就有点不高兴,全世界都黑程序员,没想到自己还没变成程序员就被自家姐姐黑了。

说完就进自己房间,把姐姐和吕老师晾在外面。小史姐姐也意识到不该拿程序员开玩笑,但现在也不知道该怎么办,就看着吕老师。

吕老师走进小史的房间。

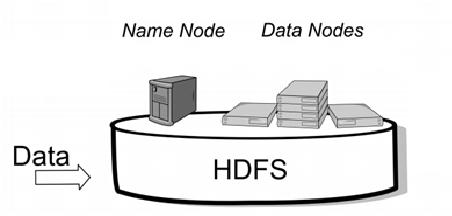
【hbase是啥】


小史:别吹了,构建在hdfs上除了能存储海量数据之外,缺点一大堆,上次你给我介绍的hdfs缺点我可没忘啊,不支持小文件,不支持并发写,不支持文件随机修改,查询效率也低。

吕老师:hdfs确实有很多缺点,但是hbase却是一个支持百万级别高并发写入,支持实时查询,适合存储稀疏数据的分布式数据库系统。


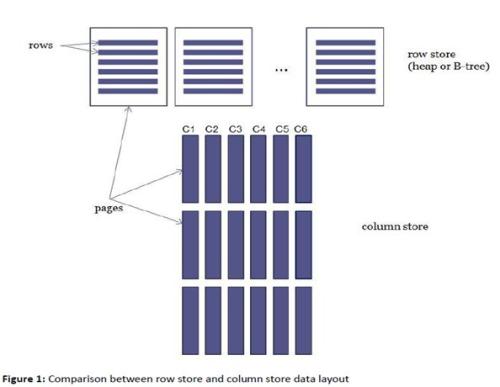
吕老师:hbase主要用于大数据领域,在这方面,确实比mysql要厉害得多啊,它和mysql的存储方式就完全不一样。mysql是行式存储,hbase是列式存储。

【列式存储】




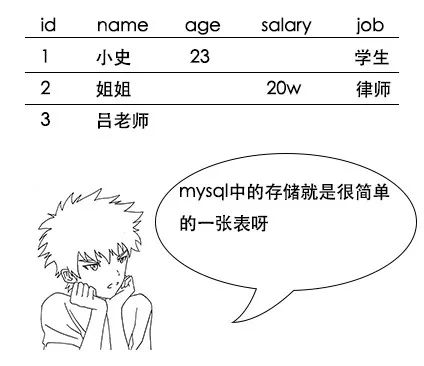


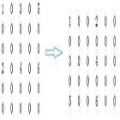
吕老师:没错,这就是行式存储系统存储稀疏数据的问题,我们再来看看列式存储如何解决这个问题,它的存储结构是这样的
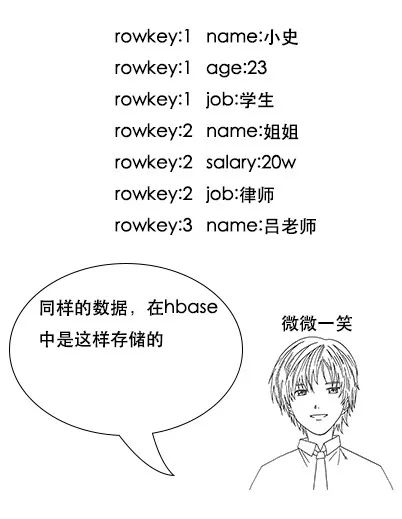

小史:这个我看懂了,相当于把每一行的每一列拆开,然后通过rowkey关联起来,rowkey相同的这些数据其实就是原来的一行。


吕老师:你这里只说到了一个好处,由于把一行数据变成了这样的key-value的形式,所以hbase可以存储上百万列,又由于hbase基于hdfs来存储,所以hbase可以存储上亿行,是一个真正的海量数据库。


吕老师:这就是hbase的威力呀,还不只如此,其实很多时候,我们做select查询的时候,只关注某几列,比如我现在只关心大家的工资,传统的按行存储,要选出所有人的工资是怎么办的呢?

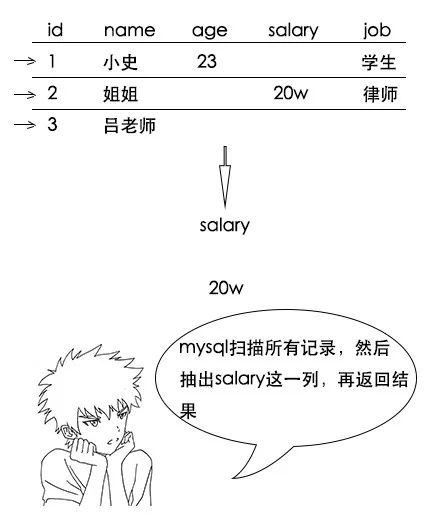

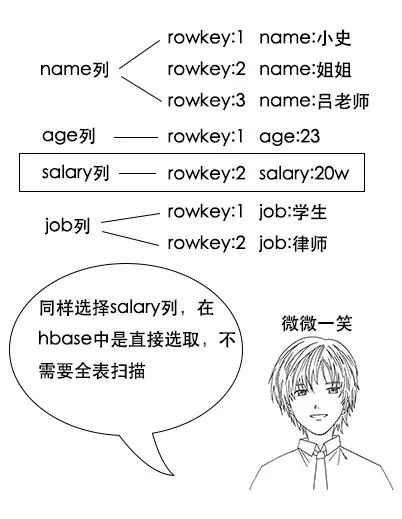

小史:哦,我大概明白了,原来是这样,所以hbase的查询效率也很高,但是我有个问题啊,如果我就要查我的所有信息,这是一行数据,hbase查询起来是不是反而更慢了呢?
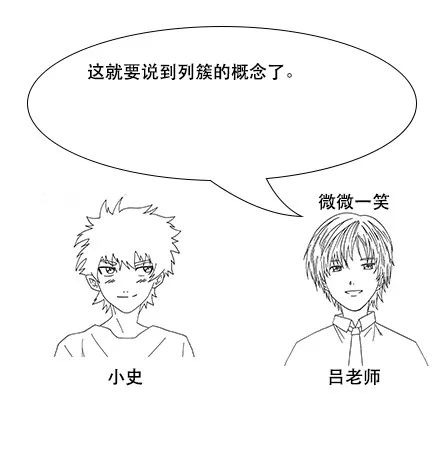
【列簇】

吕老师:列簇,顾名思义,就是把一些列放在一起咯,在hbase中,会把列簇中的列存储在一起,比如我们把和工作相关的salary和job都放在work这个列簇下,那么大概是这样的
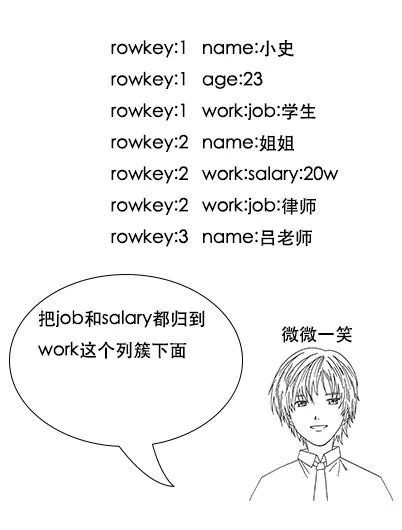


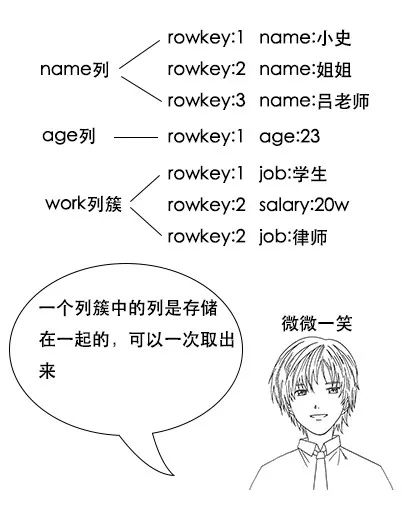

小史:哦,我明白了,这样的话,一个列簇中的列会被一次就拿出来,如果我要查所有列的信息的话,把所有信息都放在一个列簇就好了。

(注意:hbase中,其实所有列都是在列簇中,如果不指定,就在一个默认列簇中。生产环境由于性能考虑和数据均衡考虑,一般只会用一个列簇,最多两个列簇)
【rowkey设计】

(注:当然,有些中间件把sql翻译成hbase的查询规则,从而支持了sql查hbase,不在本文讨论范围内)

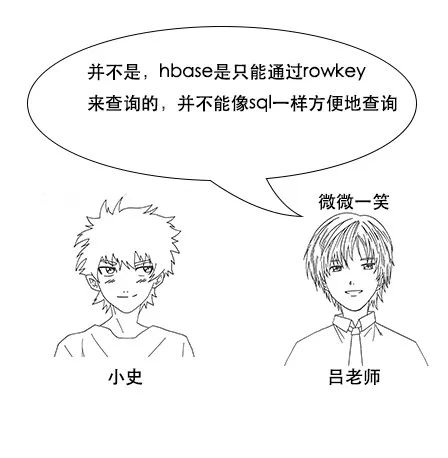
小史:啊?这和我想象的不一样啊,如果我想查询工资比20w多的记录,在mysql中,只要用一条很简单的sql就行啊,这在hbase中怎么查呢?

吕老师:在hbase中,你需要把要查询的字段巧妙地设置在rowkey中,一个rowkey你可以理解为一个字符串,而hbase就是根据rowkey来建立索引的
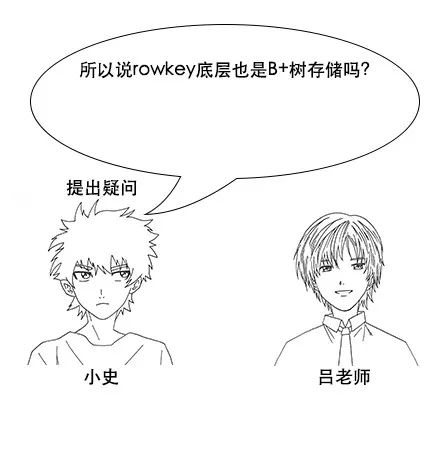
不熟悉B+树的同学可以看这篇文章。hbase也是一样的原理。


吕老师:假设员工工资9999w封顶,查询的时候可能根据员工工资查询,也可能根据名字查询一个特定的员工,那么rowkey就可以这样设计
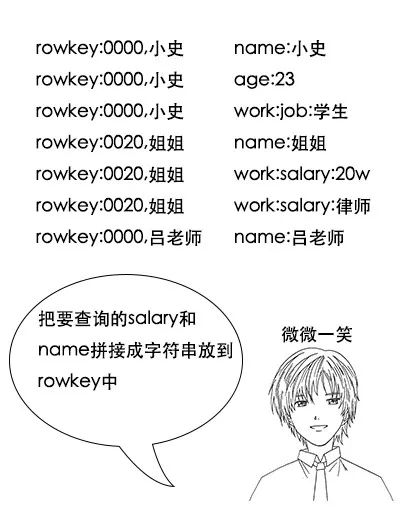
(注意,以上rowkey是简化版设计,只是为了讲清楚范围查询。实际使用中由于rowkey需要考虑散列性,所以可能不会这么用。后文会具体探讨散列性。)

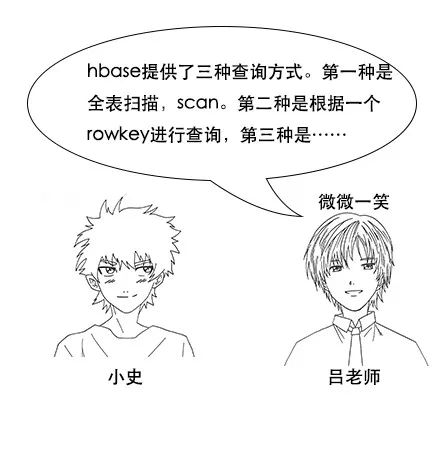
吕老师:hbase提供了三种查询方式。
第一种是全表扫描,scan
第二种是根据一个rowkey进行查询
第三种是根据rowkey过滤的范围查询
比如你要查工资不少于20w的记录,就可以用范围查询,查出从startRow=0020到stopRow=9999的所有记录,这是hbase直接支持的一种查询方式哦。

吕老师:这里要注意几点,首先,rowkey是按照字符串字典序来组织成B+树的,所以数字的话需要补齐,不然的话会出现123w小于20w的情况,但是补齐的话,你就会发现020w小于123w
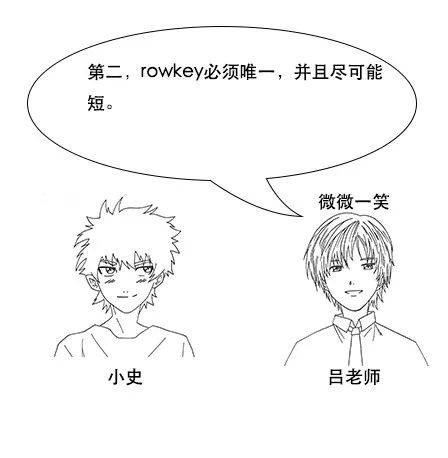

小史:哦,明白了,这都很好理解,因为rowkey是字符串形式,所以肯定是按照字符串顺序排序咯。而且rowkey有点类似于mysql中的主键吧,所以保证其唯一性也是可以理解的。还有就是因为每个key-value都包含rowkey,所以rowkey越短,越能节省存储空间。
(注意,如果rowkey复杂且查询条件复杂,hbase还针对rowkey提供了自定义Filter,所以只要数据在rowkey中有体现,能解析,就能根据自己的条件进行查询)

小史:但是吕老师,我有一个问题啊,之前说过hdfs不适合存储小文件,而hbase中的一条记录只有一点点数据,记录条数却很多,属于海量小文件,存在hdfs中不是内存爆炸了吗?
具体如何运用,我们下回分解。
生活现场是互联网侦察推出的现场系列中的另一个板块,旨在通过生活中的场景,来解释大数据微服务技术中的基本原理,希望对大家学习技术原理有所帮助。
往期回顾
还没看够怎么办?
由于大数据中间件基础加原理,介绍起来篇幅较大,有时候整篇看下来需要20~30分钟,为了增加阅读体验,将阅读时间控制在10分钟左右,特将文章进行切分,遵循少量多餐原则。
小史:大数据切块,这是学习hdfs么?
小编:额……
下一篇,我们继续。
●编号766,输入编号直达本文
●输入m获取文章目录

算法与数据结构
更多推荐《25个技术类公众微信》
涵盖:程序人生、算法与数据结构、黑客技术与网络安全、大数据技术、前端开发、Java、Python、Web开发、安卓开发、iOS开发、C/C++、.NET、Linux、数据库、运维等。