Nat. Biomed. Eng.| 综述:医学和医疗健康中的自监督学习
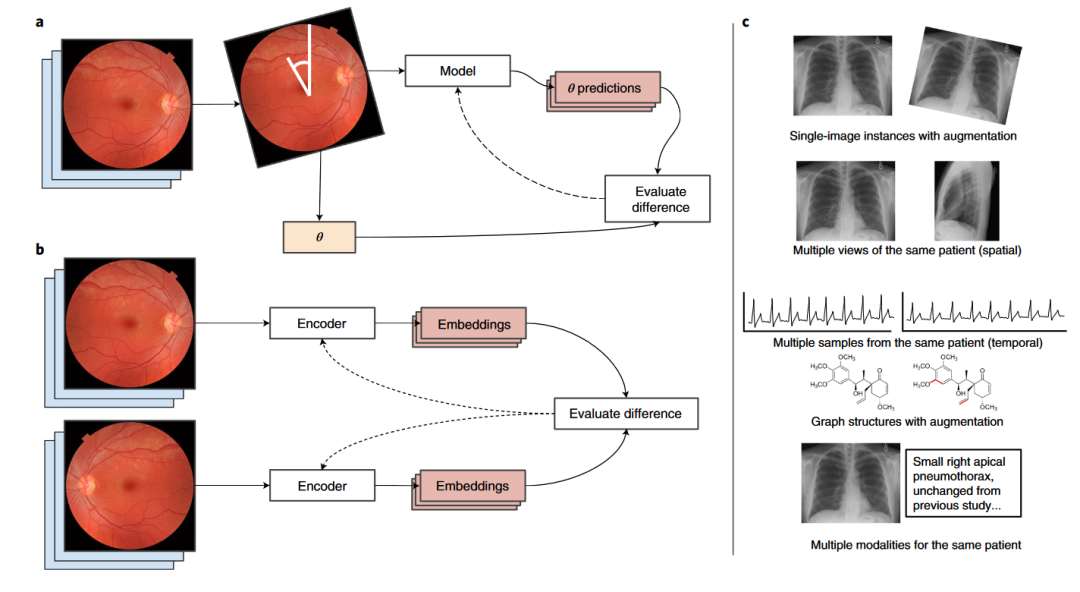
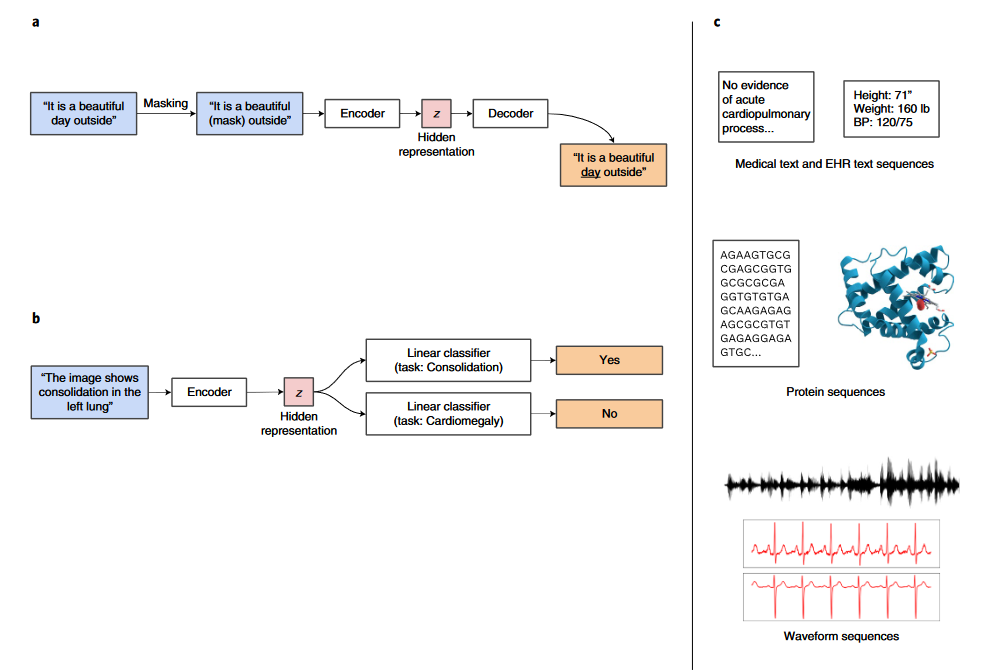
本文介绍由哈佛大学计算机科学系Rayan Krishnan 等人发表在 Nature biomedical engineering 上的一篇综述《Self-supervised learning in medicine and healthcare》。常规的深度学习模型需要大量标注的数据作为训练集,例如计算机视觉常用的数据集 ImageNet 包含了 21,000 类 1600 万张图片。然而对于医疗数据来说,想要获取这样规模的标注数据是非常困难的。一方面,标注医疗图像需要拥有专业的医疗知识;另一方面,不同于普通物体,我们一眼就可以分辨,医疗图像往往需要医学专家花费数分钟进行确认。因此,如何利用大量的无标签数据对于 AI 医疗的发展至关重要。自监督学习通过构建一系列的自监督任务来进行预训练,使得模型可以提取到更有用的特征,然后在有标签的数据集中进行进一步训练,使得模型在标注数据较少的条件下也能获得较好的泛化能力。文章展望了自监督学习应用于AI医疗的发展趋势,并介绍了两类近年来被广泛研究的用于 AI 医疗的自监督的预训练方法:对比学习和生成学习。

专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“MSSL” 就可以获取《Nat. Biomed. Eng.| 综述:医学和医疗健康中的自监督学习》专知下载链接



登录查看更多
相关内容

Arxiv
0+阅读 · 2022年11月23日
Arxiv
11+阅读 · 2021年12月16日
Arxiv
13+阅读 · 2021年4月7日




相关VIP内容
相关资讯
相关论文
Arxiv
0+阅读 · 2022年11月23日
Arxiv
11+阅读 · 2021年12月16日
Arxiv
13+阅读 · 2021年4月7日