NLP集大成之预训练模型综述


论文标题:Pre-trained Models for Natural Language Processing: A Survey
论文链接:https://arxiv.org/pdf/2003.08271.pdf
集大成系列会分享各个领域(方面)的综述论文(建议大家看原论文),分享内容主要来自于原论文,会有些整理与删减,以及个人理解与应用等等,其中涉及到的算法复现都会开源在:https://github.com/wellinxu/nlp_store ,更多内容关注知乎专栏(或微信公众号):NLP杂货铺。
-
介绍 -
背景知识 -
语言表示学习 -
NLP预训练模型简史 -
预训练任务 -
语言模型类 -
对比学习 -
其他任务 -
预训练模型的分类 -
预训练模型的扩展 -
知识增强型 -
多模态预训练模型 -
模型压缩 -
特定领域的预训练模型 -
多语言和特定语言的预训练模型 -
将预训练模型应用到下游任务中 -
怎样进行迁移学习 -
微调策略 -
预训练模型的开源资料 -
应用 -
未来方向
介绍
预训练模型的出现,将自然语言处理带入了新纪元,本论文中就此综合地介绍了自然语言的预训练模型。预训练模型主要有以下三个优点:可以从巨大的语料中学习表示,从而帮助到下游任务;提供了一个很好的模型初始化结果,有着更好的泛化能力,并且能加速下游任务的收敛。论文主要分四个内容:语言表示学习的进程,预训练模型的分类,使用预训练模型处理下游任务,以及未来的研究方向。
背景知识
语言表示学习
语言表示学习的核心思想是:使用低维实数向量对词语进行分布式表示。主要有两种形式:静态表示(非上下文依赖的),动态表示(上下文依赖的),如下图所示:
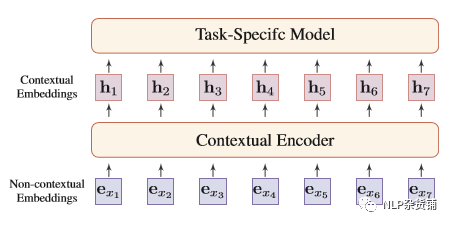
静态表示就是将词始终固定用同一个向量表示,主要有两个缺点:不善于处理多义词,难处理词表之外的词(通过处理更小的字符,如char,字可以缓解)。
动态表示因为动态地根据上下文获取词的表示,所以可以较好地处理多义词问题。动态表示的编码器大体可以归为三类:卷积模型,序列模型,基于图的模型(transformer就是一个比较好的实现)。
NLP预训练模型简史
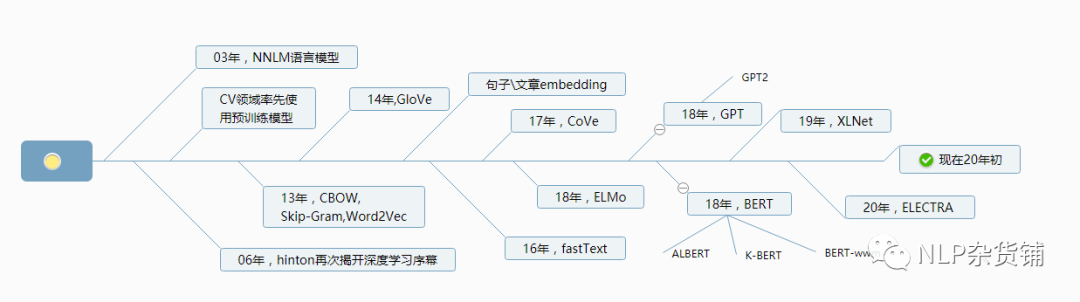
预训练任务
预训练任务对学习通用语言表示来说至关重要,通常这些任务需要具有一定难度且有大量的训练数据。在CV领域,预训练模型通常使用监督训练;但在NLP领域,通常是缺少大量监督数据的,只有在翻译任务上有足够大量的数据,所以CoVe预训练模型就是在翻译数据上训练的。NLP中常见的预训练任务有以下几种:
语言模型类
-
语言模型(LM)
LM通常特指自回归语言模型或单向语言模型,其思想是用前T个词预测第T+1个词。单向语言模型的缺点是,其只使用预测词了左边的词语,并未能使用所有上下文;一个简单解决办法是使用双向语言模型。 -
遮蔽语言模型(MLM)
MLM的思想是:先遮蔽句子中一些字词,然后使用其他的字词来预测这些被遮蔽的。但这会引起预训练与下游任务输入数据形式不同,因为下游任务不会遮蔽字词。经验上,BERT在处理输入的时候,将被遮蔽的词,随机80%用[MASK]代替,随机10%用原词代替,随机10%用一个随机词代替。MLM通常被当做分类任务处理,但也可以将其当成seq2seq问题使用encoder-decoder框架。encode的时候输入遮蔽的seq,decode的时候输出完整的句子,这样有利于处理seq2seq类型的下游任务,比如问答,摘要,翻译等等。很多模型会对MLM做些修改,RoBERTa使用了动态的MLM,UniLM使用了单向、双向、seq2seq三种形式训练,XLM用在了双语语料对上,Span-BERT和StructBert遮蔽了随机的几个连续字词,ERNIE则将短语跟实体进行了遮蔽。 -
排序语言模型(PLM)
为了解决MLM在训练与处理下游任务时输入形式不完全一致的问题,XLNet提出了排序语言模型。PLM的主要思想是:将文本序列随机打乱,随机抽取其中几种序列,再从这几个序列中选择几个词作为目标,用其他所有词和目标词的位置来预测。 -
去噪自编码器(DAE)
去噪自编码器的思想是:使用部分损坏的输入去还原未原始输入。通常损坏文本的方式有:字词遮蔽,字词删除,文本填充,句子排序,段落转换
对比学习
相比于语言模型类任务,对比学习(CTL)任务有着更低的计算复杂度,是预训练模型中较好的替代任务。其主要假设是:被观测到的文本对比随机的文本对有更高的语义相似度。
-
噪音对比估计(NCE)
Noise-Contrastive Estimation是训练一个二分类去辨别真假样本,Word2Vec中使用了相关思想。 -
深度最大互信息(DIM)
Deep InfoMax一开始是CV中提出来的概念,这里其思想是:互信息度量了文本中不同部分的依赖程度,同一文本间不同部分的互信息应该要大于不同文本间各部分的互信息。 -
替换词语检测(RTD)
Replaced Token Detection跟NCE非常相似,其思想是:根据上下文预测词是否被替换了。ELECTRA 中使用生成器来替换序列中的一些词,先使用MLM任务训练一个生产器,然后再训练一个判别器,最终处理下游任务的时候只会使用判别器,可以解决[MASK]带来的输出形式不一致的问题。 -
下句预测(NSP)
Next Sentence Prediction会预测两个句子是否是连续的两个句子。这种任务可以理解两个句子之间的关系,对问答、自然语言推断等下游任务更友好。但是NSP的有效性也收到了质疑,RoBERTa就放弃了NSP的任务,依然取得了很好的效果。 -
句子顺序预测(SOP)
Sentence Order Prediction是预测两个句子的顺序,ALBERT就使用SOP代替了NSP任务。
其他任务
当然除了这些任务之外还有一些其他的任务,比如一些给指定下游任务设计的特定task,或者增加实体知识的一些预训练任务,以及一些多模态(视觉、语音)任务。
预训练模型的分类
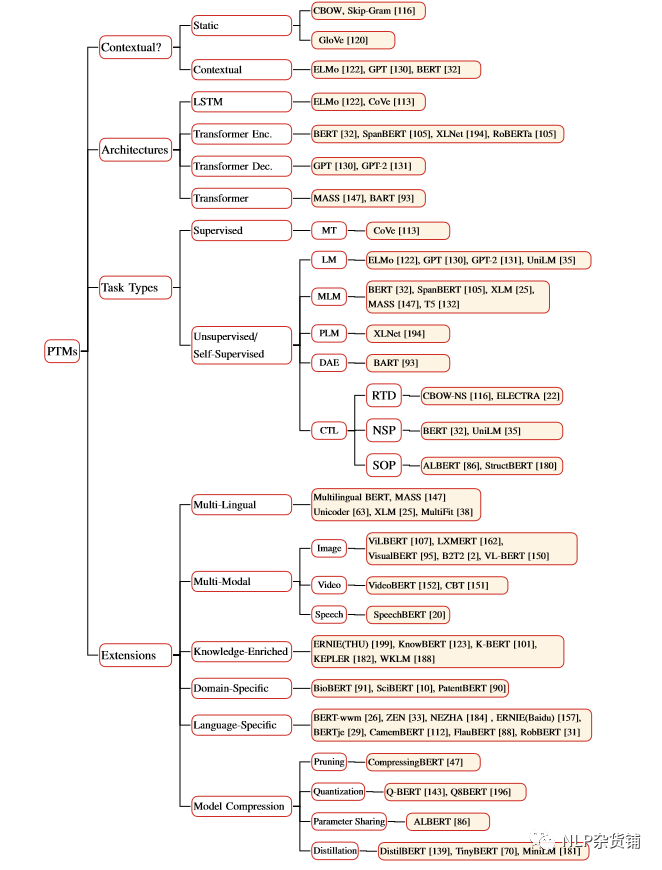
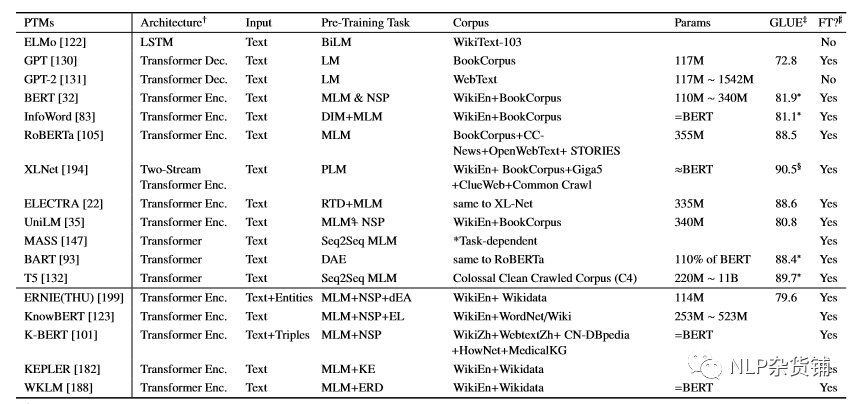
预训练模型的扩展
知识增强型
在预训练过程中,LIBERT添加了语言知识,SentiLR添加了情感极性,SenseBERT添加了Wordnet中的知识,ERNIE(THU)加入了实体embedding,KnowBERT使用了实体链接模型,KEPLER同时优化了知识embedding与语言模型,K-BERT添加了知识图谱中三元组的信息,K-Adapter则融合了多种知识信息。有的模型则在微调阶段加入信息,比如K-BERT;ConceptNet和 ATOMIC使用了常识信息。KGLM跟LRLM则允许基于知识图谱进行预测。
多模态预训练模型
视频-文本:VideoBERT,CBT,UniViLM;图片-文本:ViLBERT,LXMERT,VisualBERT,B2T2,VLBERT,Unicoder-VL,UNITER;语音-文本:SpeechBERT。
模型压缩
-
模型剪枝
模型剪枝的思想是:移除部分不重要的神经网络(参数,神经元,层,通道,attention head等),得到更小的模型以及更快的推断速度。 -
量化
量化是指将模型高精度的参数压缩成低精度的参数。 -
参数共享
通过参数共享来减少参数数量,ALBERT中就让不同层之间共享参数。 -
知识蒸馏
知识蒸馏的思想是:通过训练一个小的学生模型,来复现老师模型(比较大的模型)的行为。通常情况下,蒸馏机制可以分为三种:根据目标概率分布来蒸馏(distillation from soft target probabilities),根据其他知识来蒸馏(distillation from other knowledge),蒸馏成其他网络结构(distillation to other structures)。
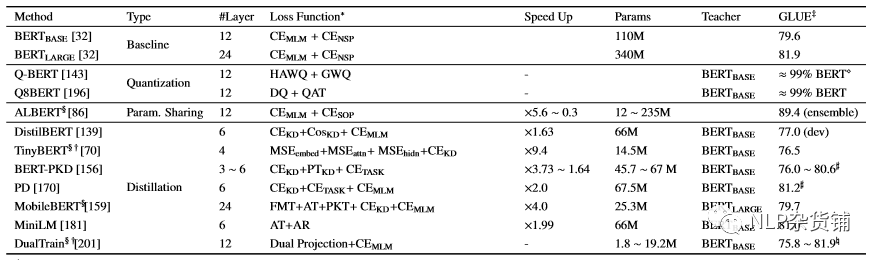
特定领域的预训练模型
BioBERT:生物医学领域文本,SciBERT :科学领域文本, ClinicalBERT:临床医学领域文本。
多语言和特定语言的预训练模型
M-BERT、MASS在多种语言上进行训练,XLM、Unicoder在其基础上添加了交叉语言任务。但很多研究表明,在单语言上训练的效果要好于多语言。
将预训练模型应用到下游任务中
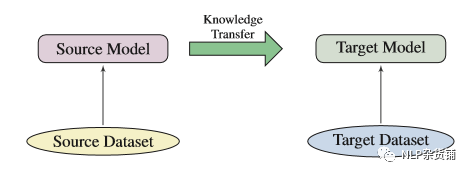
怎样进行迁移学习
-
选择合适的预训练任务,模型结构跟语料。不同的训练任务对不同的下游任务会有不同的影响,比如NSP任务就比较合适处理句子间的关系,善于处理问题或者自然语言推理等。预训练模型的结构也是很重要的,比如BERT模型,虽然可以处理很多NLP问题,但却不适合处理文本生成问题。在处理下游任务的时候,尽量选择使用同领域或者同语言语料训练的模型。 -
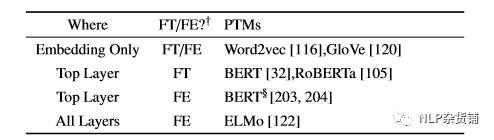
选择合适的层。预训练模型不同层的结果可能会具有不同的信息,比如BERT在底层的encode更偏向于句法信息,上层的encode则偏向于语义信息。通常有三种选择的方式:只选择embedding层,选择最顶层,选择所有层。
-
是否要微调。可以将预训练模型当做特征提取器(下游任务中预训练模型参数不变),也可以进行微调(下游任务中预训练模型参数改变)。
微调策略
-
两级微调:在预训练模型与下游之间加入一个中间任务。 -
多任务微调。 -
添加额外自适应组件微调。
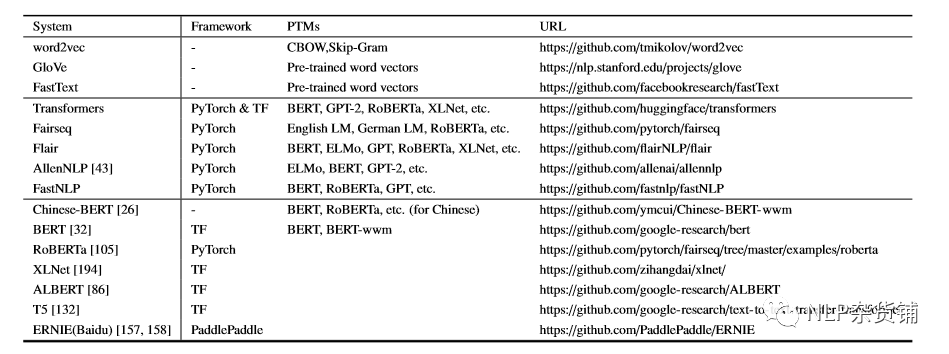
预训练模型的开源资料

应用
通用评估基准(文本分类,文本蕴涵,文本相似,相关性排序等)、翻译、问题、情感分析、摘要、命名实体识别等等。
未来方向
-
预训练模型提高能力上界
更多的训练步数,更多的语料,更深的结构往往都能提高预训练模型能力,这也表明预训练模型的上界还远没达到。 -
任务导向的预训练模型跟模型压缩
-
预训练模型的结构
-
超越微调的知识迁移能力
-
预训练模型的可解释性以及可靠性
推荐阅读
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。





