NLP预训练模型大集合!
选自GitHub
作者:Sepehr Sameni
机器之心编译
参与:路
本文经机器之心(微信公众号:almosthuman2014)授权转载,禁止二次转载
词语和句子嵌入已经成为任何基于深度学习的自然语言处理系统的必备组成部分。它们将词语和句子编码成稠密的定长向量,从而大大地提升神经网络处理文本数据的能力。近日,Separius 在 GitHub 上列举了一系列关于 NLP 预训练模型的近期论文和文章,力求全面地概述 NLP 各个方面的最新研究成果,包括词嵌入、池化方法、编码器、OOV 处理等。
GitHub 地址:https://github.com/Separius/awesome-sentence-embedding
通用框架
几乎所有句子嵌入的工作原理都是这样的:给出某种词嵌入和可选编码器(例如 LSTM),句子嵌入获取语境词嵌入(contextualized word embedding)并定义某种池化(比如简单的 last pooling),然后基于此选择直接使用池化方法执行监督分类任务(如 infersent),或者生成目标序列(如 skip-thought)。这样通常我们就有了很多你从未听说过的句子嵌入,你可以对任意词嵌入做平均池化,这就是句子嵌入!
词嵌入
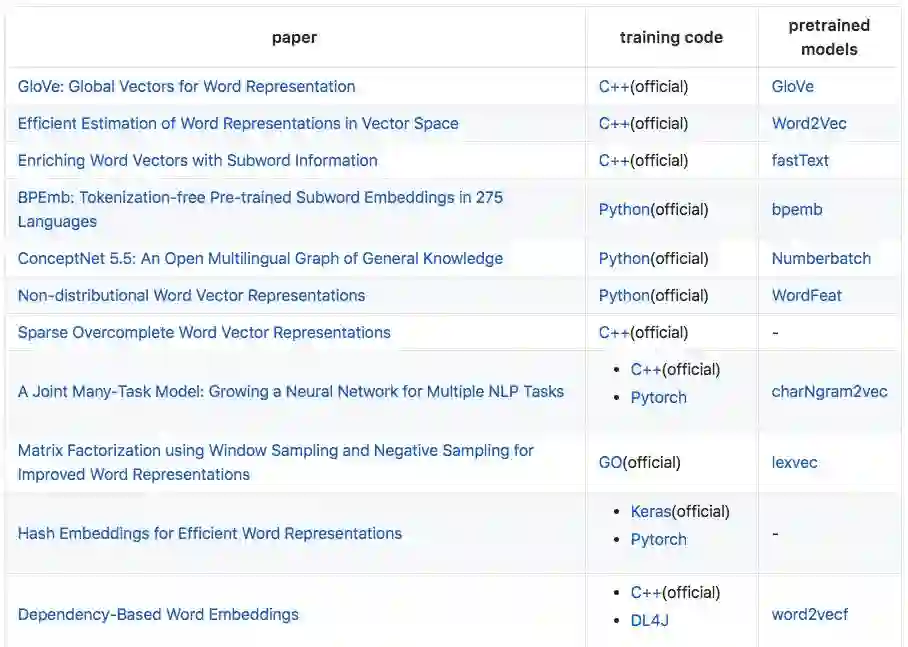
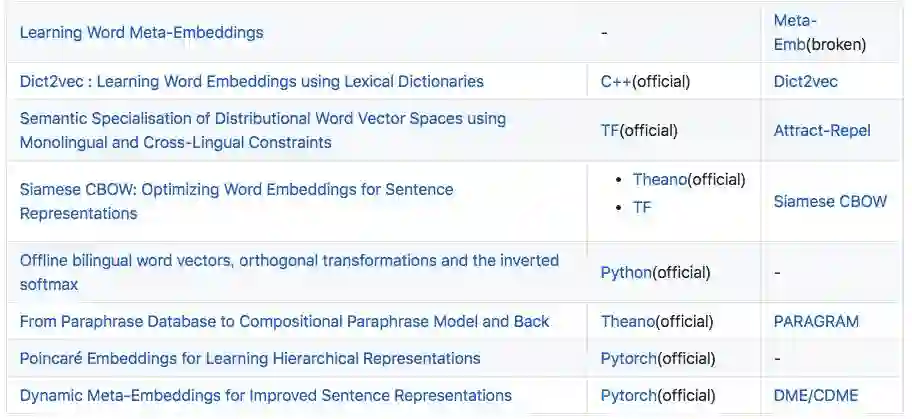
这部分 Separius 介绍了 19 篇相关论文,包括GloVe、word2vec、fastText 等预训练模型:
OOV 处理
A La Carte Embedding: Cheap but Effective Induction of Semantic Feature Vectors:基于 GloVe-like 嵌入的近期结果构建 OOV 表征,依赖于使用预训练词向量和线性回归可高效学习的线性变换。
Mimicking Word Embeddings using Subword RNNs:通过学习从拼写到分布式嵌入的函数,合成地生成 OOV 词嵌入。
语境词嵌入
这部分介绍了关于语境词嵌入的 5 篇论文,包括近期大热的BERT。
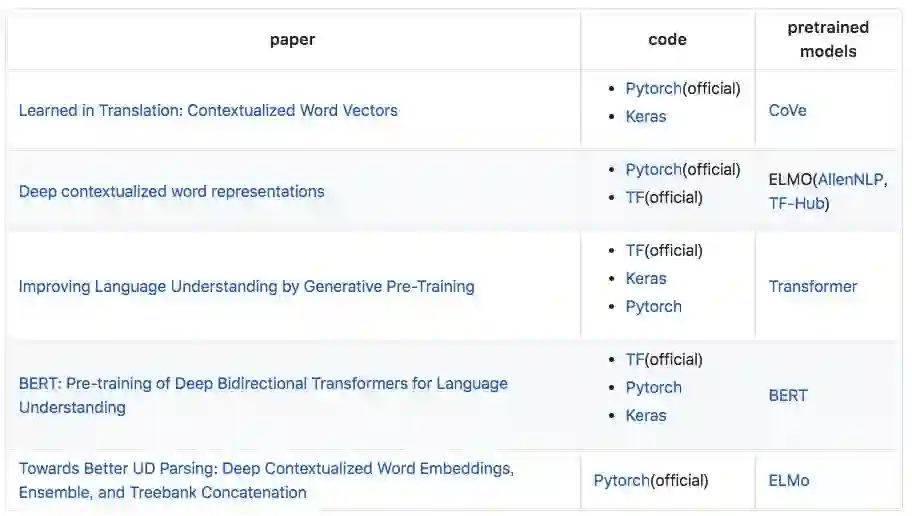
机器之心介绍过这五篇论文中的其中四篇,参见:
池化方法
{Last, Mean, Max}-Pooling
Special Token Pooling(如 BERT 和 OpenAI's Transformer)
A Simple but Tough-to-Beat Baseline for Sentence Embeddings:选择一种在无监督语料库上常用的词嵌入计算方法,使用词向量的加权平均值来表征句子,并且使用 PCA/SVD 进行修改。这种通用的方法有更深刻和强大的理论动机,它依赖于一个生成模型,该生成模型使用了一个语篇向量上的随机游走生成文本。
Unsupervised Sentence Representations as Word Information Series: Revisiting TF–IDF:提出了一种将句子建模为词嵌入的加权序列的无监督方法,该方法从无标注文本中学习无监督句子表征。
Concatenated Power Mean Word Embeddings as Universal Cross-Lingual Sentence Representations:将平均词嵌入的概念泛化至幂平均词嵌入。
A Compressed Sensing View of Unsupervised Text Embeddings, Bag-of-n-Grams, and LSTMs:从压缩感知理论的角度看结合多个词向量的表征。
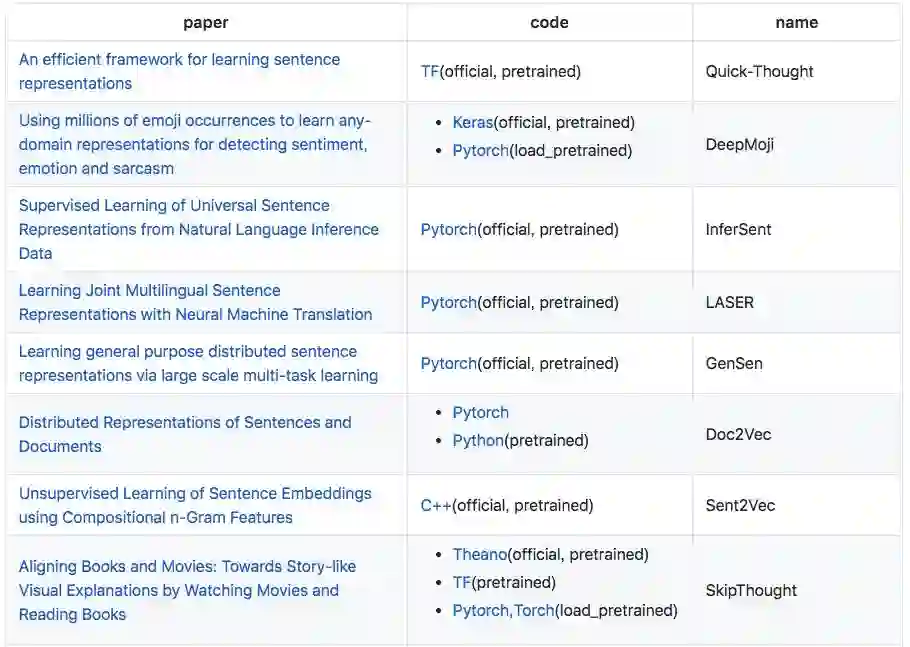
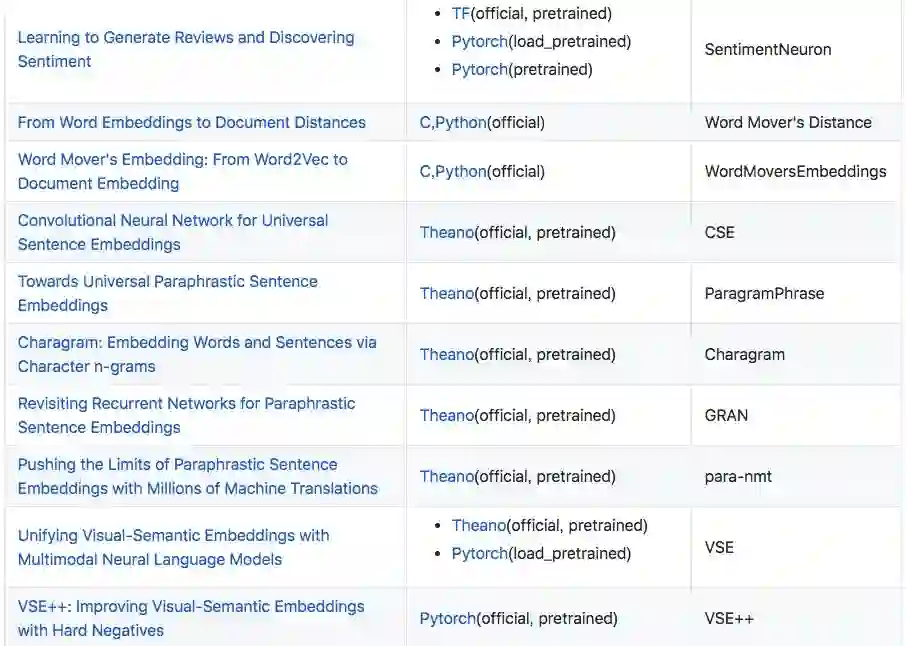
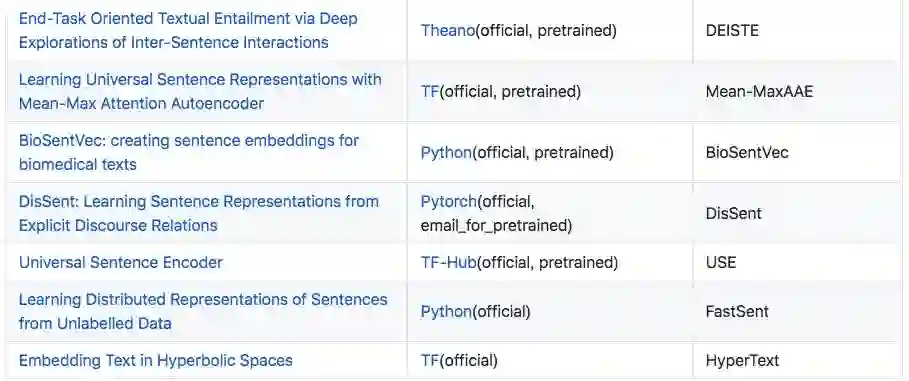
编码器
这部分介绍了 25 篇论文,包括 Quick-Thought、InferSent、SkipThought 等预训练模型。
评估
这部分主要介绍词嵌入、句子嵌入的评估和基准:
The Natural Language Decathlon: Multitask Learning as Question Answering
SentEval: An Evaluation Toolkit for Universal Sentence Representations
GLUE: A Multi-Task Benchmark and Analysis Platform for Natural Language Understanding
Exploring Semantic Properties of Sentence Embeddings
Fine-grained Analysis of Sentence Embeddings Using Auxiliary Prediction Tasks
How to evaluate word embeddings? On importance of data efficiency and simple supervised tasks
A Corpus for Multilingual Document Classification in Eight Languages
Olive Oil Is Made of Olives, Baby Oil Is Made for Babies: Interpreting Noun Compounds Using Paraphrases in a Neural Model
Community Evaluation and Exchange of Word Vectors at wordvectors.org
Evaluation of sentence embeddings in downstream and linguistic probing tasks
向量图
Improving Vector Space Word Representations Using Multilingual Correlation:提出了基于典型相关分析(CCA)结合多语言 evidence 和单语生成向量的方法。
A robust self-learning method for fully unsupervised cross-lingual mappings of word embeddings:提出一种新的无监督自训练方法,该方法采用更好的初始化来引导优化过程,这种方法对于不同的语言对而言尤其强大。
Unsupervised Machine Translation Using Monolingual Corpora Only:提出将机器翻译任务转换成无监督式任务。在机器翻译任务中,所需的唯一数据是两种语言中每种语言的任意语料库,而作者发现如何学习两种语言之间共同潜在空间(latent space)。参见:无需双语语料库的无监督式机器翻译
此外,Separius 还介绍了一些相关的文章和未发布代码或预训练模型的论文。




推荐阅读
基础 | TreeLSTM Sentiment Classification
原创 | Simple Recurrent Unit For Sentence Classification
原创 | Attention Modeling for Targeted Sentiment
 欢迎关注交流
欢迎关注交流


