Galaxy Zoo:利用众包和主动学习对星系进行分类

科学研究的方法日新月异,每天的数据都呈指数增长,但科学家的数量仍然与过去相差无几。“收集数据样本,研究样本,再围绕每个样本得出一些结论”,这种传统方法已经难以满足我们日益增长的需求。
一种解决方案是部署算法来自动处理数据,而另一种解决方案是借助大众的力量:招募公众参与进来并提供协助,也就是众包。我结合了众包与机器学习,打造出一种集二者之长的解决方案,其研究效果比单独使用任一种方案都更好。
在本文中,我将分享如何使用众包和机器学习对数百万张星系图像进行分类,以便研究星系的演化过程。在此过程中,我将分享一些用于训练卷积神经网络的模型训练技巧。此外,我还将阐述如何利用这些预测结果进行主动学习 (Active Learning),即仅标记最有助于您改善模型的数据。
望远镜越先进,问题规模越庞大
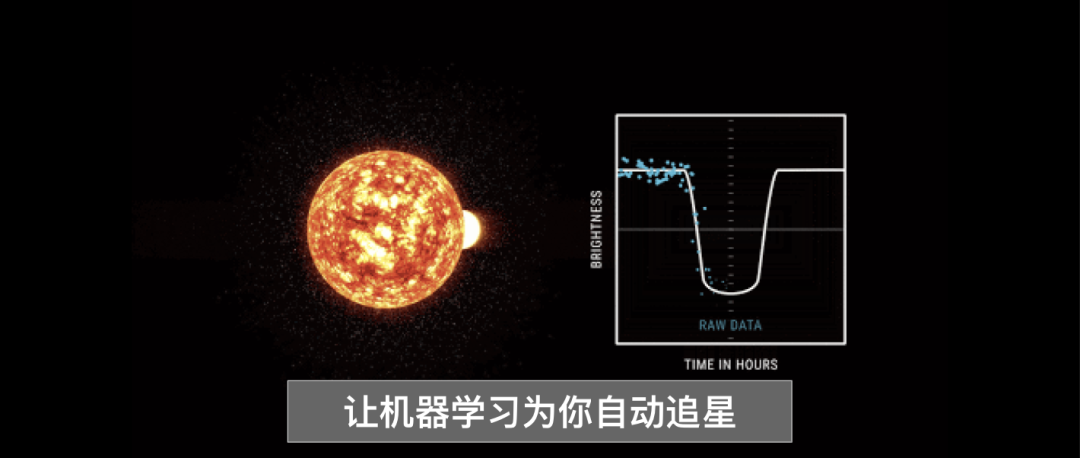
从 20 世纪 20 年代的 Edwin Hubble 开始,天文学家们一直在研究星系,并试图将各星系分为不同类型,如平滑星系、螺旋星系等。但是,星系的数量却在不断攀升。大约 20 年前,一位名叫 Kevin Schawinski 的研究生坐在堆着 90 万张星系图片的书桌前苦思冥想:相比较自己逐一分类每张图片,“肯定有更好的解决方法”。的确,他并非在孤军奋战。为了协助 Kevin 对全部 90 万个星系进行分类,一个科学家团队(包括 Kevin 在内)构建了 Galaxy Zoo。
Galaxy Zoo (http://www.galaxyzoo.org) 是一个网站,旨在邀请公众协助我们对星系进行分类。通过展示一个星系,我们会针对您看到的内容询问一些简单的问题,例如,星系是平滑的还是有其他特点?在您回答时,我们会引导您进入决策树,其中的问题均基于您先前给出的具体回答。

Galaxy Zoo 界面:请访问 (www.galaxyzoo.org) 进行查看,并一同参与科学研究
自网站发布以来,无数志愿者对数百万个星系进行了分类,从而加深了我们对超大质量黑洞、旋臂、恒星的诞生与死亡等问题的理解。但是,这种方法也存在一个问题:人力无法规模化扩增。随着星系调查的规模不断扩大,我们召集的志愿者数量却始终没有明显提升。最新的天基望远镜可以为数亿个星系拍摄图像,这一数字远超出单独使用众包方法所能标记的范畴。
为处理这些海量图像,我们使用 TensorFlow 构建了一个星系分类器。其他研究人员已使用我们收集的回答来训练卷积神经网络 (CNN,专为图像识别而设计的深度学习模型)。但传统的 CNN 有一个缺点:难以处理不确定性。
通常,研究人员会训练 CNN 预测每个标签的值并最小化均方误差,从而解决回归问题。这其实隐含了一个假设,即所有标签都具有同样的不确定性,而 Galaxy Zoo 中的情况则完全不同。此外,CNN 只会给出“最佳猜测”答案,而不提供准确性 (Error bar),因此我们很难得出科学结论。
我们在论文中使用贝叶斯 CNN 进行形态分类。贝叶斯 CNN 实现了两大改进:
从志愿者的回答中学习时会解释各种不确定性。
会预测每个星系形态的完整后验概率。
论文
https://arxiv.org/abs/1905.07424
借助贝叶斯 CNN,我们可以从繁杂的标签中学习并为亿万个星系形成可靠的预测(附带 Error Bar)。
贝叶斯卷积神经网络的工作原理
创建贝叶斯 CNN 有两个关键步骤:
1.预测概率分布的参数,而非标签本身
训练神经网络很像其他拟合问题,即需要通过调整模型来匹配观察值。如果您对所有收集到的标签抱有相同信心,则只需最小化预测值与观察值之间的差异(例如均方误差)。但对于 Galaxy Zoo 而言,很多标签的置信度都高于其他标签。
如果我发现有 30% 的志愿者认为某些星系为“棒状”,那么我对这 30% 的志愿者的信心主要是取决于给出相同回答的人数,例如人数是 4 位还是 40 位?因此,我们改为预测一般志愿者认为星系是“棒状”的概率,并最小化我们对这些志愿者总数的惊讶程度。
通过这种方式,我们的模型便会了解到,相较于参与人数较少的星系,有大量志愿者参与回答的星系误差更为严重,从而让模型从每个星系中学习。
我们在案例中发现,N 名志愿者的 k 个“棒状”回答非常像 N 个独立试验的 k 个成功次数,因此采用二项分布对我们的惊讶程度进行建模。
loss = tf.reduce_mean(binomial_loss(labels, scalar_predictions))
根据模型预测,“binomial_loss”会计算观察到的标签的惊讶程度(负对数似然):
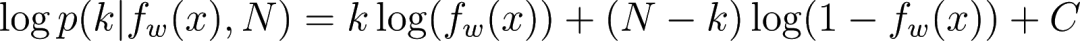
在 TF 中,我们可以使用以下方法进行计算:
def binomial_loss(observations, est_prob_success):
one = tf.constant(1., dtype=tf.float32)
# to avoid calculating log 0
epsilon = tf.keras.backend.epsilon()
# multiplication in tf requires floats
k_successes = tf.cast(observations[:, 0], tf.float32)
n_trials = tf.cast(observations[:, 1], tf.float32)
# binomial negative log likelihood, dropping (fixed) combinatorial terms
return -( k_successes * tf.log(est_prob_success + epsilon) + (n_trials - k_successes) * tf.log(one - est_prob_success + epsilon )
2.使用 Dropout 假装训练多个网络
现在,我们的模型目前可以预测概率,但如果需要训练其他模型,又会出现什么情况?这会使概率预测的结果稍有不同。要使用贝叶斯神经网络,我们需要对可能训练过的模型进行边缘化 (Marginalise) 处理。为此,我们需使用 Dropout。
在训练时,Dropout 可以通过“大致将指数级数量的众多不同神经网络架构进行有效组合”(Srivastava 于 2014 年发布)来减少过度拟合。这种操作类似于贝叶斯方法,即将网络权重视为要进行边缘化处理的随机变量。如果在测试时也应用 Dropout,我们可以利用这种对多个模型进行近似处理的想法来进行贝叶斯预测(Gal 于 2016 年发布)。
以下是使用 Subclassing API 的 TF 2.0 示例:
from tensorflow.keras import layers, Model
class SimpleClassifier(Model):
def __init__(self):
super(SimpleClassifier, self).__init__()
self.conv1 = layers.Conv2D(32, 3, activation='relu')
self.flatten = layers.Flatten()
self.d1 = layers.Dense(128, activation='relu')
self.dropout1 = layers.Dropout(rate=0.5)
self.d2 = layers.Dense(2, activation='softmax')
def call(self, x, training):
x = self.conv1(x)
x = self.flatten(x)
x = self.d1(x)
if training: # dropout typically applied only at train time
x = self.dropout1(x)
return self.d2(x)
在测试时启动 Dropout 实际上会使用更少的代码:
def call(self, x):# no ‘training’ argument required
x = self.conv1(x)
x = self.flatten(x)
x = self.d1(x)
x = self.dropout1(x) # dropout always on
return self.d2(x)Subclassing API
https://tensorflow.google.cn/guide/keras/overview#model_subclassing
您可以在下方看到运行中的贝叶斯 CNN。每行代表一个星系(如左图所示)。在中间列中,展示了 CNN 做出单个概率预测(一般志愿者回答“棒状”的概率)的预测结果。我们可以将其解释为 N 名志愿者中有 k 名回答“棒状”的后验概率(以黑色显示)。在右侧,展示了我们使用 Dropout 将多个 CNN 进行边缘化处理的结果。每个 CNN 的后验概率(灰色)都不相同,但我们可以对其进行边缘化处理,以得到多个 CNN 的后验概率(绿色),即我们的贝叶斯后验概率。

左:带有/没有棒状结构的星系输入图像;中:对于多个志愿者会回答“棒状”的单个概率预测(也表示没有 Dropout);右:使用不同的 Dropout 掩码(灰色)进行的多个概率预测,然后将其边缘化以得出近似的贝叶斯后验概率(绿色)
在量化每个星系是否具有棒状结构方面,贝叶斯后验概率的性能非常出色。请阅读此论文(并查看相关代码),了解更多相关信息。
论文
https://arxiv.org/abs/1905.07424代码
https://github.com/mwalmsley/galaxy-zoo-bayesian-cnn
主动学习
现代观测调研需要数亿个星系拍摄图像,而这一数字远超出我们能向志愿者展示的数量。因此,哪些星系的分类任务应由我们与志愿者一起完成,而哪些星系分类应由贝叶斯 CNN 完成?
理想情况下,我们只会向志愿者显示模型可以获取最多信息的图像。此模型应该能够发出请求:“嘿,这些星系对学习很有帮助,能帮我贴上标签吗?”接着,研究人员会为这些星系贴上标签,然后模型将重新训练,而这就是主动学习。在我们的实验中,应用主动学习可将达到指定性能水平所需的星系数量减少 35% 至 60%。
我们可以使用后验概率来确定哪些星系拥有的实用信息最多。请注意,我们还使用了 Dropout 对多个模型进行近似训练(请参见上文)。我们在论文中得出结论,信息丰富的星系均为那些模型严重存在分歧的星系。
为什么会这样?我们常常会对自己最不熟悉的事情振振有词,CNN 也是如此(Hendrycks 于 2016 年发布)。在没有证据支持的情况下,不同的 CNN 通常也会自信地表达反对意见。

从形式上讲,信息丰富的星系是指每个模型都存在置信度(每个模型的后验熵 H p(votes|weights) 较低)的星系,但所有模型的平均预测值都不确定(所有已平均的后验熵都很高)。这是唯一可能的情况,因为我们考虑了标签的概率并对许多模型进行了近似训练。有关详情,请参阅 Houlsby, N. (2014)、Gal 2017 或我们的代码,了解我们的实现情况。
代码
https://github.com/mwalmsley/galaxy-zoo-bayesian-cnn/blob/88604a63ef3c1bd27d30ca71e0efefca13bf72cd/zoobot/active_learning/acquisition_utils.py#L81
-
相比椭圆星系(平滑“blob”),此模型十分偏好多样化且有特点的星系。 为识别棒状结果,模型偏好解析度较高的星系(红移较低)。
这是一个自动选择的过程。事实上,看到图像时我才发现其红移偏好较低!

我们的主动学习系统选择了左侧的星系(有特点且多样化),而非右侧的星系(平滑“blob”)
主动学习如今正在 Galaxy Zoo 上选择要标记的星系。您可以访问官网(http://www.galaxyzoo.org),选择“强化”工作流以了解详情。从对上万个星系进行分类发展到对上亿个星系进行分类,科技将给我们带来哪些惊喜?让我们拭目以待。
如要了解更多详情或有任何疑问,请在官网或 Github 上与我们联系。
祝好!
Mike
*Dropout 是完整贝叶斯方法的不完美近似,此方法适用于大型视觉模型,但可能会低估不确定性。其近似结果可能会更好,对小模型来说更是如此。请参阅 Tensorflow Probability 团队的这篇博文,了解如何针对一维回归执行此操作。