Kaggle Carvana 图像分割比赛冠军模型 TernausNet 解读

AI 研习社按:2017 年 7 月,美国二手汽车零售平台 Carvana 在知名机器学习竞赛平台 kaggle 上发布了名为 Carvana 图像掩模大挑战赛(Carvana Image Masking Challenge)的比赛项目,吸引了许多计算机视觉等相关领域的研究者参与。

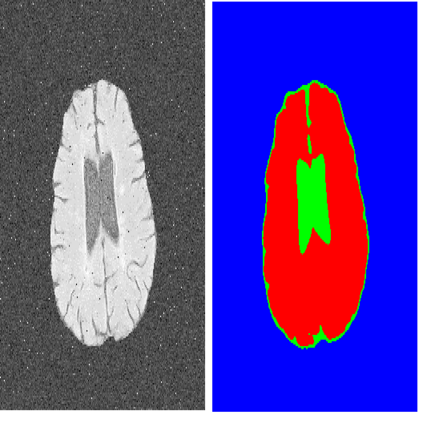
输入图像(左)和理想的输出图像(右)
Carvana 希望为消费者提供全面、透明的购车信息,以提升购买体验。传统的二手车销售平台向消费者提供的车辆展示图片往往是模糊的,缺少标准规范的汽车信息图片往往也不能全面地向消费者展示全面的信息。这严重降低了二手车的销售效率。为了解决这一问题,Carvana 设计了一套用以展示 16 张可旋转的汽车图片的系统。然而,反光以及车身颜色与背景过于相似等问题会引起一系列视觉错误,使得 Carvana 不得不聘请专业的图片编辑来修改汽车图片。这无疑是一件费时费力的工作。因此,Carvana 希望此次比赛的参赛者设计出能够自动将图片中的汽车从背景中抽离的算法,以便日后将汽车融合到新的背景中去。
此次比赛历时约 2 个月,共吸引了来自 735 支参赛队伍的 875 名选手。其中,来自 Lyft 公司的 Vladimir Iglovikov 和来自 MIT 的 Alexey Shvets 凭借名为 TernausNet 的工作拔得头筹。获奖之后他们也撰写了一篇论文介绍了自己的比赛思路和使用的模型,雷锋网(公众号:雷锋网) AI 科技评论把论文主要内容介绍如下。

近年来,用于密集计算的计算机硬件取得了进步,并且随着这些硬件越来越平民化,研究者们能够处理拥有数以百万计的参数的复杂模型。其中,卷积神经网络(CNN)是一种在图像分类、目标识别、场景分类等任务中被广泛应用的模型,取得了巨大的成功。不例外地,此次竞赛获得第一名的工作 TernausNet 也用到了基于 CNN 的神经网络组件。TernausNet 是一个可用于密集图像分割的深度学习模型,能够根据使用者的要求,对原始图像进行划分,将原始图像分成有不同意义的若干部分。避免传统的手动图像分割的耗时耗力的麻烦,达到高效、高质量、标准化的图像分割要求。
TernausNet 使用利用 ImageNet 数据预训练得到的 VGG11 编码器达到了提高 U-Net 网络性能的目的,出色的完成图像分割的任务。
网络架构
U-Net 是一种编码器-解码器结构,在网络向前传播的过程中,编码器逐渐收缩,减少池化层的空间维度;而解码器逐渐扩张,逐步修复物体的细节和空间维度。编码器和解码器之间通常存在跳跃连接(skip connection),跳跃连接能够将低层次的特征图和高层次的特征图结合起来,能帮助解码器更好地修复目标的细节,实现像素级的定位。在上采样部分,大量的特征通道能向更高分辨率的层传送上下文信息。
U-Net 的编码器是一个基于全卷积神经网络(FCN)的网络结构,即将卷积神经网络(CNN)中的全连接层替换为卷积层。FCN 可以接受任意尺寸的输入图像,采用反卷积层对最后一个卷积层的特征图进行上采样, 使它恢复到输入图像相同的尺寸,从而可以对每个像素都产生了一个预测, 同时保留了原始输入图像中的空间信息, 最后在上采样的特征图上进行逐像素分类。
具体而言,TernausNet 的模型结构如图 1 所示。编码器是一个特征图尺寸逐渐收缩、通道数逐渐增加的 FCN 网络结构,卷积层和池化层交替工作,用来捕捉上下文的信息,逐步对特征图进行下采样;解码器是一个与编码器对称的结构,其特征图尺寸逐渐扩张,通道数逐渐减少,对特征图进行上采样,逐步恢复高分辨率的图片细节。根据 U-Net 的思想,解码器可以通过跳跃连接将对应的编码器的高分辨率特征和解码器上采样得到的特征图结合起来,最终输出一个逐像素的掩码。
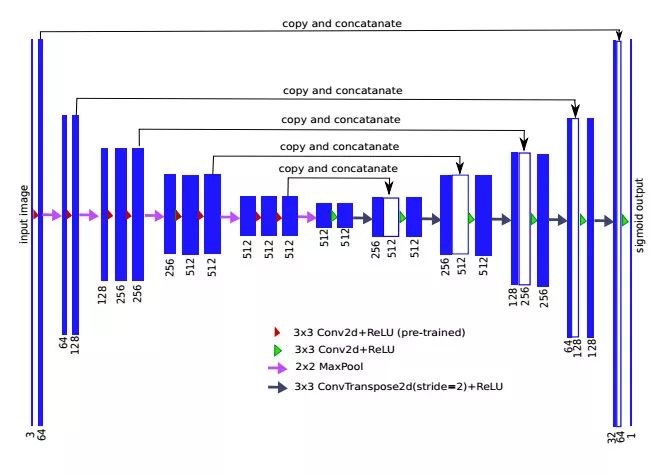
图1. U-NET 编码器-解码器神经网络架构,编码器为用单一卷积层替换全连接层的 VGG11 网络。蓝色的矩形代表经过上一阶段变换的多通道特征图。矩形的高度与特征图的尺寸成正比、宽度和通道数成正比。左侧编码器的通道数逐渐增加,右侧解码器的通道数逐渐减少。顶部连接左侧和右侧的箭头表示从编码层向相应的解码层的信息迁移。
TernausNet 采用 VGG11 作为 U-Net 网络的编码器。如图 2 所示,VGG11 由 11 个向前传播的网络层组成。其中有 8 个卷积层,每个卷积层采用了 3*3 的卷积核,每个卷积层后都紧跟一个 ReLU 激励函数层,第 1、2、4、6、8 个卷积层后都紧跟一个 2*2 的最大池化操作,每次操作后特征图尺寸减半。第一个卷积层通道数为 64,第二层通道数为 128,第三层第四层通道数为 256,第五层到第八层通道数为 512。为了达到语义分割的目的,编码器采用了类似 FCN 的设计思路,将 VGG11 的最后 3 层替换为了一个 512 通道的卷积层,它同时也是编码器与解码器的「瓶颈」,将 U-Net 的左右两个部分分开。
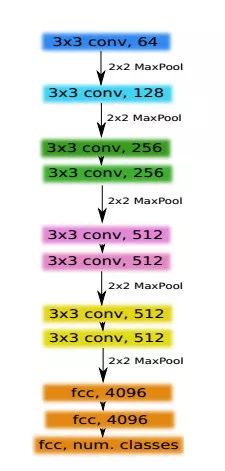
图2. VGG11网络架构。图中每个卷积层之后是ReLU激活函数。每个框中的数字表示对应特征图的通道数量
为了构建解码器,TernausNet 用两倍于特征图大小的转置卷积层同时将通道数减半。转置卷积的输出接着被连接到相应的编码器输出。得到的特征图通过卷积运算处理,保持通道数量与对应的编码器相同。上采样步骤重复了 5 次用来与 5 个最大池化层配对。如图 1 所示,由于 TernausNet 有 5 个最大池化层,每层下采样图像两次,因此,只有边可以被 32,即 2 的 5 次方,整除的图像可以用作此模型的输入。
通常 U-Net 的权重是随机初始化的。而 TernausNet 相对于传统的 U-Net 网络最大的改进在于:TernausNet 先用 ImageNet 预训练的权重初始化了 U-Net 的前几层,并应用了微调(fine tuning)。事实上,对于图像分割任务而言,手动标注的图像分割数据集往往至多也只有几千张图像,这样的数据规模相对于 ImageNet 等包含数百万张图像的数据集来说是很小的。为了避免过拟合问题,数据集合应该要足够大,然而这会带来很高的时间开销。为了减小时间开销并防止过拟合,TernausNet 使用了 ImageNet 数据集上训练的网络权重作为预训练的参数。
模型训练及实验结果
作者在 Inria 航空图像标注数据集上测试了 TernausNet 的性能。作者采用了 Jaccard 相似系数作为评价模型的标准。Jaccar 相似系数是两个有限集合之间的相似度度量。给定两个集合 A 和 B,Jaccard 相似系数定义为 A 与 B 交集的大小与 A 与 B 并集的大小的比值,定义如下:
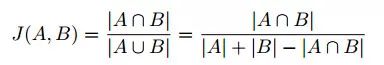
在图像分割任务中,由于图像由像素点组成,在离散问题中,我们可以将jaccard相似系数改写为:
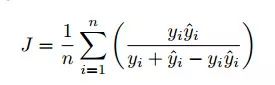
其中,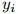
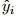
此时,可以将图像分割问题看作一个像素的二分类问题,其交叉熵损失函数可以表示为:
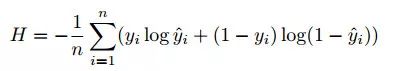
换句话说,整个 TernausNet 的损失函数可以表示为:
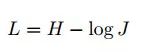
在测试集上得到的实验结果如图3所示:
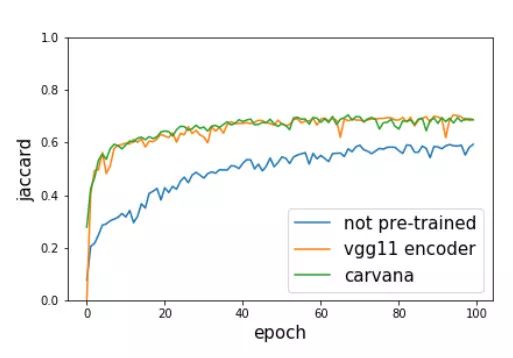
图3. 三种不同权重初始化条件下的 U-Net 模型的 Jaccard 相似系数随着训练次数的变化情况。蓝线表示随机初始化权重的模型,橙色的线表示编码器用 ImageNet 上预训练的 VGG11 网络权重初始化的模型,绿线表示网络在 Carvana 数据集上预训练的模型。
TernausNet 在 Inria 航拍图片数据集上的图像分割效果如图 4 所示:

图4. 绿色像素的二进制掩模表示分类簇(建筑物)。图 A 表示初始图像和叠加的真实掩模。图 B 到图 D 表示通过不同的方式初始化并且训练 100 次之后得到的预测结果。图 B 中的网络具有随机的初始化权重。图 C 中的模型解码器的权重是随机初始化的,编码器的权重以是在 ImageNet 上预训练的 VGG11 的网络权重进行初始化。图 D 的模型使用在 Carvana 数据集上预训练得到的权重。
TernausNet 的作者认为,未来可以考虑更多先进的预训练编码器,例如:VGG16或者ResNet,用来构造编码器-解码器模型。
原论文地址:https://arxiv.org/pdf/1801.05746.pdf

NLP工程师入门实践班:基于深度学习的自然语言处理
三大模块,五大应用,手把手快速入门NLP
海外博士讲师,丰富项目经验
算法+实践,搭配典型行业应用
随到随学,专业社群,讲师在线答疑
▼▼▼

新人福利
关注 AI 研习社(okweiwu),回复 1 领取
【超过 1000G 神经网络 / AI / 大数据,教程,论文】
分分钟带你杀入Kaggle Top 1%
▼▼▼