强的离谱!串烧70+个Transformer模型,涵盖CV、NLP、金融、隐私计算...
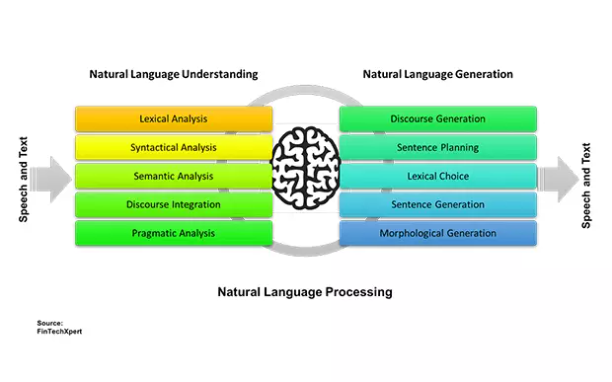
Transformer 作为一种基于注意力的编码器 - 解码器架构,不仅彻底改变了自然语言处理(NLP)领域,还在计算机视觉(CV)领域做出了一些开创性的工作。与卷积神经网络(CNN)相比,视觉 Transformer(ViT)依靠出色的建模能力,在 ImageNet、COCO 和 ADE20k 等多个基准上取得了非常优异的性能。
正如德克萨斯大学奥斯汀分校的计算机科学家 Atlas Wang 说:我们有充分的理由尝试在整个 AI 任务范围内尝试使用 Transformer。
因此,无论是学术界的研究人员,还是工业界的相关从业者,都有必要对Transformer技术深入了解,并且紧跟Transformer的前沿研究,以此来夯实自己技术积累。
AI是一门入门简单,但想深入却很难的学科,这也是为什么AI高端人才一直非常紧缺的重要原因。
在工作中:
你是否能够按照实际的场景灵活提出新的模型?
或者提出对现有模型的改造?
实际上这些是核心竞争力,同时是走向高端人才必须要经历的门槛。虽然很有挑战,但一旦过了这个门槛你就会发现你是市场中的TOP5%.
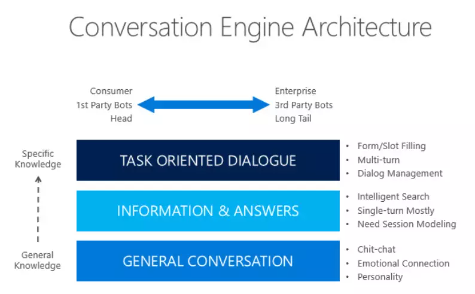
所以我们设计了这样的一门课程,目的就是一个:让你有机会成为市场中的TOP5%。在课程中,我们将由浅入深的讲解Transformer在NLP和CV领域的模型原理、实现方法以及应用技巧等,全面细致的讲解联邦学习的理论知识体系及其在隐私计算与金融领域的应用。学习过程中,可以通过六大实战项目,拓展思路,融会贯通,从而真正提高自己解决问题能力。
课程亮点
-
全面的内容讲解:涵盖当今应用和科研领域最热门的Transformer与联邦学习,包括70+Transformer模型串讲,三大联邦学习类型+应用案例。 -
深入的技术剖析:深入剖析Transformer与联邦学习模型与框架技术细节及各模块所涵盖最前沿模型原理技术。 -
六大实战项目:每个模块均设置项目,包含对话系统、文本生成、图像识别、目标检测、隐私计算、金融风控,在应用中提升学生的理论和实践能力。 -
大牛级导师团队: 每个模块均由各自领域内多年一线从业经验科学家或科研学者、工程师讲授,并配有背景优秀经验丰富的助教,致力于带来最优质的学习体验。
你将收获
助你成为行业TOP10%的工程师
对课程有意向的同学
扫描二维码咨询

下面对每个部分的内容详细做了介绍,感兴趣的朋友们可以来咨询更多。
-
全面技术讲解 课程内容涵盖 ELMo/ GPT3 Codex /Alpha-Code/ UniLM v2/ BERT/ RoBERTa /XLM/ Span BERT 等60余个模型的讲解。 -
项目实践,学以致用 学员使用Transformer模型,练习NLP领域应用最广泛的对话系统和文本生成任务。 -
专业团队严格打磨的课程内容,前沿且深入 课程内容经过前期数百小时的打磨设计,保证内容和项目节点设置合理,真正做到学有所得。 -
就业导向,目标明确 顺利完课后,优秀学员可获得字节、阿里、腾讯、美团等各互联网大厂,及商汤、旷视等AI独角兽公司的合作内推面试机会。
-
ELMo -
GPT/GPT2/GPT3 -
Codex/Alpha-Code -
UniLM/UniLM v2 -
NLP模型中的Tokenizer(wordpiece,BPE)
-
知识蒸馏方法介绍 -
知识蒸馏原理和步骤介绍 -
知识蒸馏训练方法缩减网络的实际分类网络演示 -
低秩分解原理 -
低秩分解加速计算在神经网络推理中的应用
-
Transformer-XL -
Relative Positional Embedding -
Permutation Language Model -
XLNet -
MPNet
-
对比学习中的常见损失函数 -
词粒度的对比:ELECTRA -
句子粒度的对比:ALBERT,StructBERT -
其他对比学习结构
-
ERNIE/ERNIE2.0/ERNIE3.0 -
KnowBERT -
K-BERT -
SentiLR -
KEPLER -
WKLM -
CoLAKE
-
多语言理解:mBERT,Unicoder,XLM-R,MultiFit -
多语言生成:MASS,mBART,XNLG -
处理中文的Transformer:BERT-wwm-Chinese,NEZHA,ZEN -
适用于其他语言的Transformer:BERTje,CamemBERT,FlauBERT,RobBERT
-
对话中的Transformer模型:TransferTransfo,DialoGPT,Blender Bot,Meena,PLATO,LaMDa,GALAXY -
文本摘要中的Transformer模型:BART,Pegasus
-
更快:Multi-query Attention, Sparse Attention,performer,fastformer -
更大:Mixture of Expert (MoE) -
更小: CompressingBERT, Q-BERT, ALBERT, DistillBERT, TinyBERT,MiniLM, BERT-of-Theseus。
助你成为行业TOP10%的工程师
对课程有意向的同学
扫描二维码咨询
-
全面的技术知识讲解
-
项目实践,学以致用
-
专业团队严格打磨的课程内容,前沿且深入
-
就业导向,目标明确
-
NLP中Transformer中Self-Attention 机制、并行化原理等。 -
Transformer进阶Bert基本原理。
-
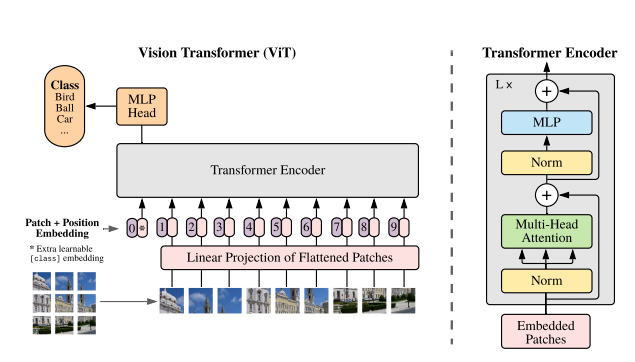
如何将Transformer设计思想应用到图像分类,语义分割问题中。
-
ViT
-
SegFormer
-
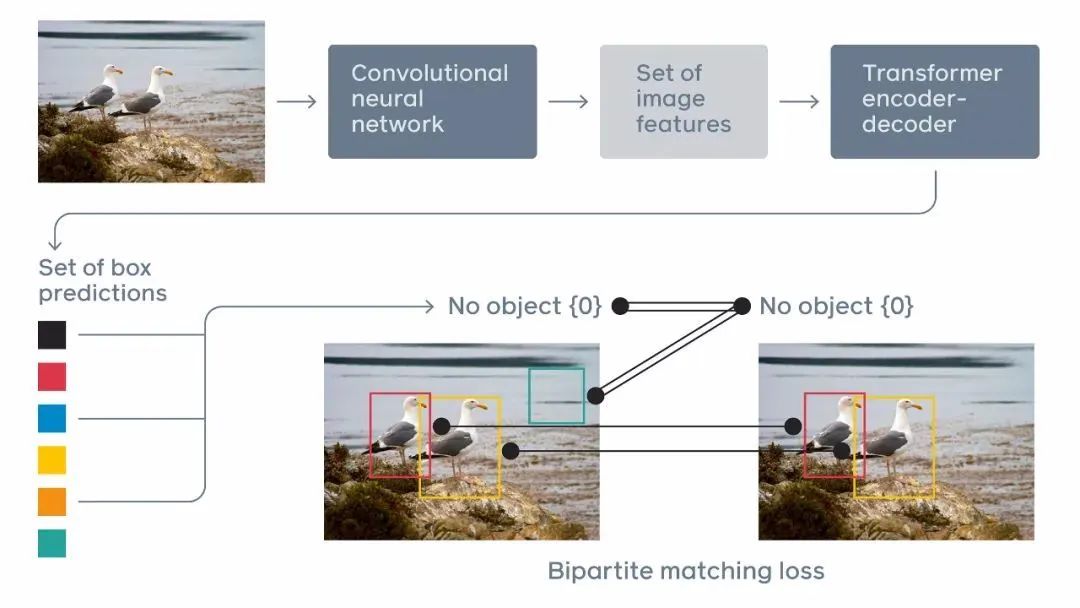
深入理解Transformer 应用到object detection的设计思想。l -
DETR -
UP-DETR
-
将Transformer设计思想扩展到时序空间上相关性建模问题上应该注意的问题
-
TimeSformer
-
Efficient Transformer设计中需要注意的问题,以及可以优化Transformer角度的探讨
-
DeiT
-
Mobile-Transformer
-
SwinTransformer 模型家族 -
SwinTransformer设计思想。思考需要设计Transformer解决新的问题时需要注意的问题
-
探讨设计Transformer处理点云数据时需要注意的事项 -
Point Transformer
-
探究设计Transformer处理multi-modal 数据时需要注意的问题 -
如何设计合适的Transformer来处理multi-modal相关问题:MTTR, MMT, Uniformer
-
首先让学生自己动手实现ViT模型,在数据集上测试结果。然后根据官方的实现做对比,如果差异较大需要自己查找原因。 -
掌握如何将Transformer中token, self-attention 思想应用到图像领域。 触类旁通,希望学生能够在深刻理解的基础上,能够学生将Transformer思想用到其他相关问题中去。
-
掌握ViT的训练方法,让学生跑完这个pipeline。从数据准备,模型训练,参数调节,到模型测试,指标计算等。
-
学生自己实现SwinTransformer代码(也可参照官方实现),并且参照官方实现优化自己的实现,如果实验效果差异较大,学生需要查找原因。 -
体会用SwinTransformer来做目标检测的思想。 -
掌握如何从代码角度优化实现SwinTransformer的self-attention机制从局部扩展到全局。 -
学生掌握如何将Transformer思想应用到自己工作或者学习中的实际问题中去。
助你成为行业TOP10%的工程师
对课程有意向的同学
扫描二维码咨询
-
全面的技术知识讲解 课程内容涵盖横向联邦学习、纵向联邦学习、联邦迁移学习三大模型架构,包含联邦学习在视觉、医疗、金融、隐私计算、政务服务等应用案例的讲解。
-
项目实践,学以致用 学员使用联邦学习框架与算法,实践金融领域隐私计算与风险检测的任务。 -
专业团队严格打磨的课程内容,前沿且深入 课程内容经过前期数百小时的打磨设计,保证内容和项目节点设置合理,真正做到学有所得。 -
就业导向,目标明确 顺利完课后,优秀学员可获得京东、百度等互联网大厂联邦学习工程师岗位的合作内推面试机会。
-
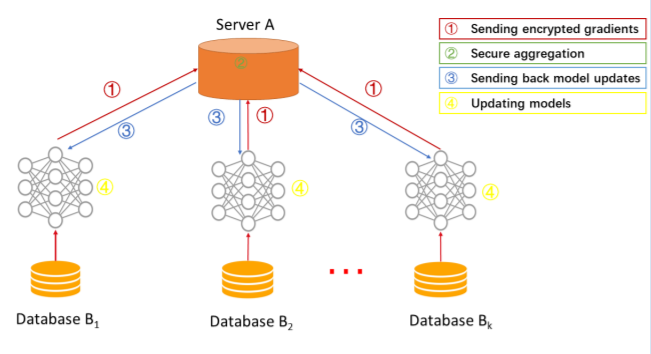
联邦学习系统架构
-
联邦学习分类
-
联邦学习常用开源平台
-
联邦学习中的隐私保护技术
-
隐私计算定义与分类
-
同态加密
-
差分隐私
-
安全多方计算
-
分布式机器学习定义
-
分布式机器学习平台
-
大规模机器学习
-
隐私保护机器学习方案
-
分布式机器学习算法
-
横向联邦学习定义 -
横向联邦学习架构 -
联邦平均算法 -
横向联邦学习算法
-
横向联邦学习构建流程
-
横向联邦学习结果分析
-
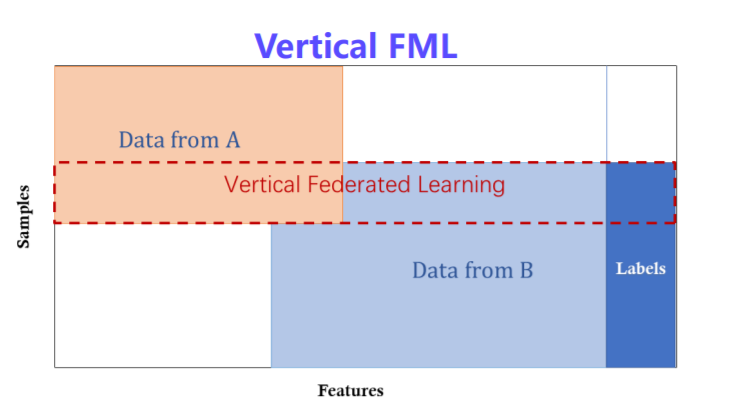
纵向联邦学习定义
-
纵向联邦学习架构
-
纵向联邦线性回归
-
纵向联邦决策树
-
联邦迁移学习定义
-
联邦迁移学习框架
-
联邦迁移学习训练与预测
-
联邦迁移学习中的同态加密
-
联邦迁移学习中的秘密共享
-
联邦学习应用案例(计算机视觉领域的联邦学习目标检测网络,政务领域的差分隐私数据共享,智能物联网中的联邦学习用户行为预测,医疗领域的联邦学习健康分析等)
-
联邦学习研究及面临问题
-
隐私计算应用案例
-
隐私计算研究及面临问题
-
金融领域风险监测模型构建流程
-
金融领域风险监测模型结果分析
助你成为行业TOP10%的工程师
对课程有意向的同学
扫描二维码咨询
适合人群
-
编程及深度学习基础良好,为了想进入AI行业发展 -
对于Transformer或联邦学习有浓厚兴趣,希望进行实践
-
工作中需要应用机器学习,深度学习等技术 -
想进入AI算法行业成为AI算法工程师 -
想通过掌握AI高阶知识,拓宽未来职业路径
导师团队





授课方式
助你成为行业TOP10%的工程师
对课程有意向的同学
扫描二维码咨询




