
一 前言
二 测试试验描述
-
实验1:恒定采集配置4,Filebeat & iLogtail 在原始日志产生速率 1M/s、2M/s、 3M/s 下的标准输出流采集性能对比。
-
实验2:恒定采集配置4,Filebeat & iLogtail 在原始日志产生速率 1M/s、2M/s、 3M/s 下的容器内文件采集性能对比。
-
实验3:恒定输入速率3M/s,Filebeat & iLogtail 在采集配置50、100、500、1000 份下的标准输出流采集性能对比。
-
实验4:恒定输入速率3M/s,Filebeat & iLogtail 在采集配置50、100、500、1000 份下的容器内文件采集性能对比。
-
实验5:iLogtail 在 5M/s、10M/s、10M/s、40M/s 下的标准输出流采集性能。
-
实验6:iLogtail 在 5M/s、10M/s、10M/s、40M/s 下的容器内文件采集性能。
三 试验环境
所有对比实验配置存储于[2], 感兴趣的同学可以自己动手进行整个对比测试实验, 以下部分分别描述了不同采集模式的具体配置,如果只关心采集对比结果,可以直接跳过此部分继续阅读。
1 环境
2 数据源
apiVersion: batch/v1kind: Jobmetadata: name: nginx-log-demo-0 namespace: defaultspec: template: metadata: name: nginx-log-demo-0 spec: restartPolicy: Never containers: name: nginx-log-demo-0 image: registry.cn-hangzhou.aliyuncs.com/log-service/docker-log-test:latest command: ["/bin/mock_log"] args: ["--log-type=nginx", "--path=/var/log/medlinker/access.log", "--total-count=1000000000", "--log-file-size=1000000000", "--log-file-count=2", "--logs-per-sec=1000"] volumeMounts: name: path mountPath: /var/log/medlinker subPath: nginx-log-demo-0 resources: limits: memory: 200Mi requests: cpu: 10m memory: 10Mi volumes: name: path hostPath: path: /testlog type: DirectoryOrCreate nodeSelector: : cn-beijing.192.168.0.140
3 Filebeat 标准输出流采集配置
: |- : 30s processors: add_kubernetes_metadata: host: ${NODE_NAME} matchers: logs_path: logs_path: "/var/log/containers/" drop_event: when: equals: : container : pretty: false queue: mem: events: 4096 : 2048 : 1s max_procs: 4 : type: container harvester_buffer_size: 524288 paths: /var/log/containers/nginx-log-demo-0-*.log
4 Filebeat 容器文件采集配置

: |- : 30s : pretty: false queue: mem: events: 4096 : 2048 : 1s max_procs: 4
: type: log harvester_buffer_size: 524288 paths: /testlog/nginx-log-demo-0/*.log processors: drop_event: when: equals: : /testlog/nginx-log-demo-0/access.log
5 iLogtail 标准输出流采集配置
{ "inputs":[ { "detail":{ "ExcludeLabel":{
}, "IncludeLabel":{ "io.kubernetes.container.name":"nginx-log-demo-0" } }, "type":"service_docker_stdout" } ], "processors":[ { "type":"processor_filter_regex", "detail":{ "Exclude":{ "_namespace_":"default" } } } ]}
6 iLogtail 容器文件采集配置
{ "metrics":{ "c0":{ "advanced":{ "k8s":{ "IncludeLabel":{ "io.kubernetes.container.name":"nginx-log-demo-0" } } }, ...... "plugin":{ "processors":[ { "type":"processor_default" } ], "flushers":[ { "type":"flusher_statistics", "detail":{ "RateIntervalMs":1000000 } } ] }, "local_storage":true, "log_begin_reg":".*", "log_path":"/var/log/medlinker", ...... } }}
四 Filebeat与iLogtail对比测试
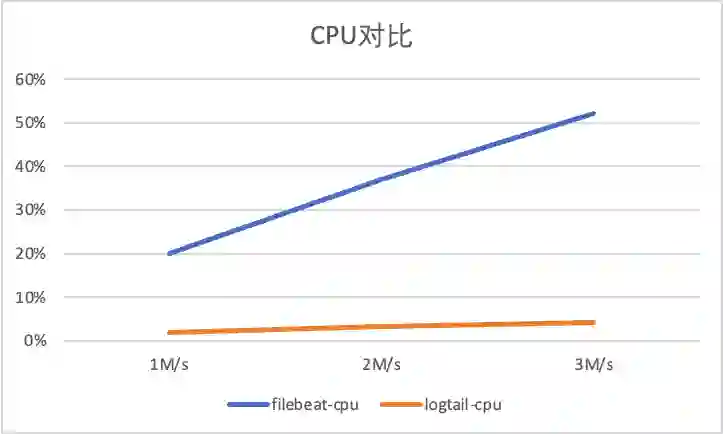
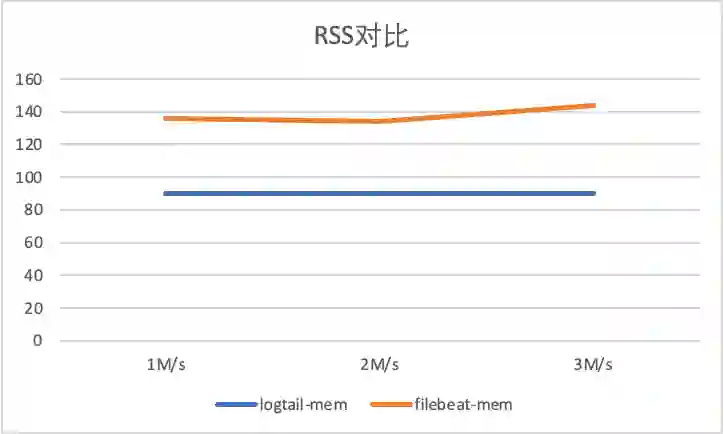
1 标准输出流采集性能对比
-
1M/s 输入日志3700条/s, -
2M/s 输入日志7400条/s,
-
3M/s 输入日志条11100条/s。
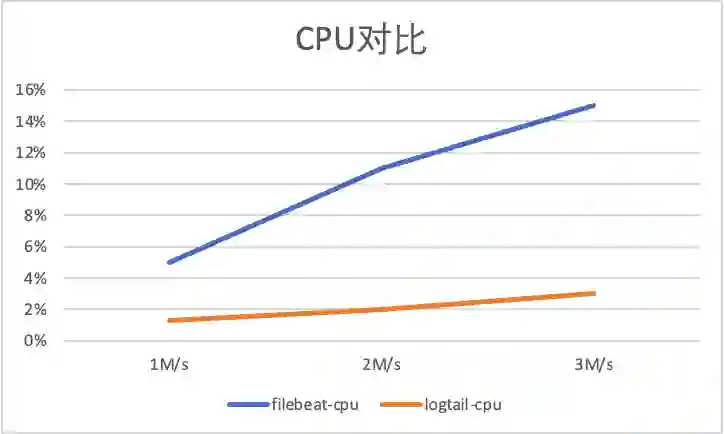
2 容器内文件采集性能对比
-
1M/s 输入日志3700条/s, -
2M/s 输入日志7400条/s,
-
3M/s 输入日志条11100条/s。
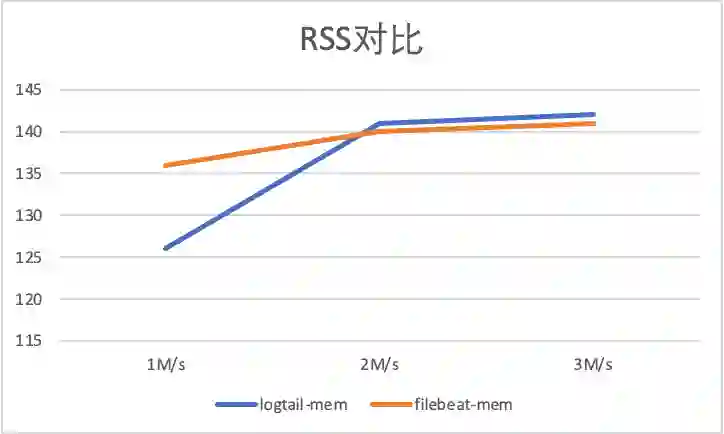
3 采集配置膨胀性能对比
标准输出流采集配置膨胀对比
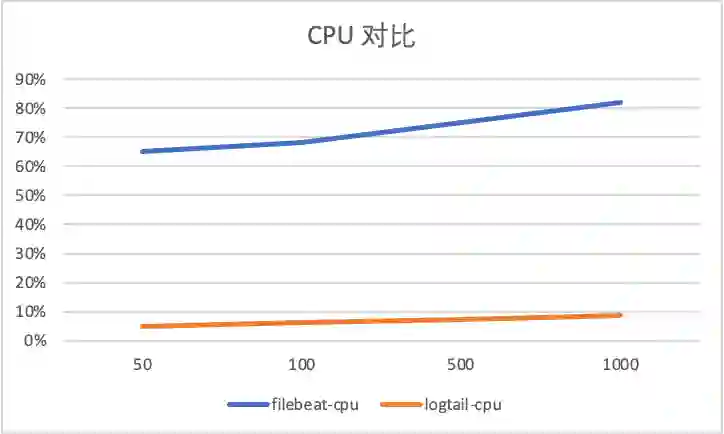
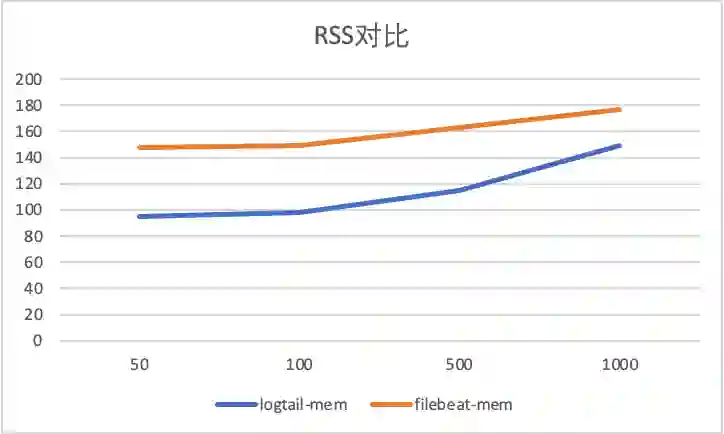
容器内文件采集配置膨胀对比

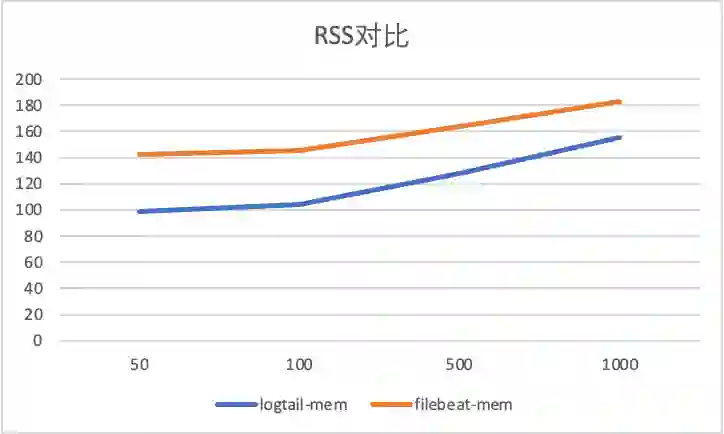
4 iLogtail 采集性能测试
-
输入源数量:10 -
单条日志大小283B
-
5M/s 对应日志速率 18526条/s,单输入源产生速率1852条/s -
10M/s 对应日志速率 37052条/s,单输入源产生速率3705条/s
-
20M/s 对应日志速率 74104条/s,单输入源产生速率7410条/s -
40M/s 对应日志速率 148208条/s,单输入源产生速率14820条/s
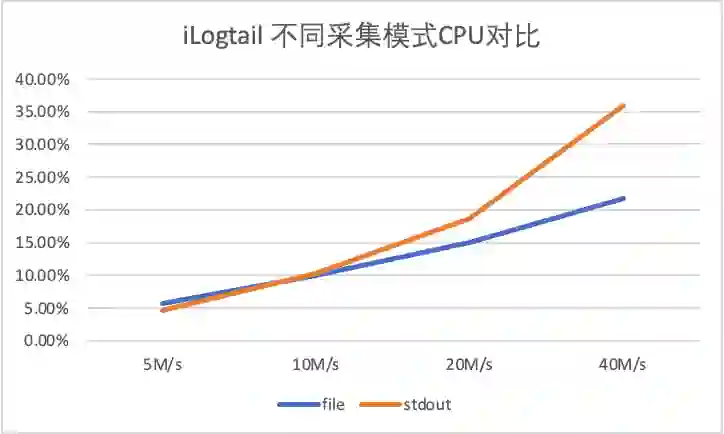
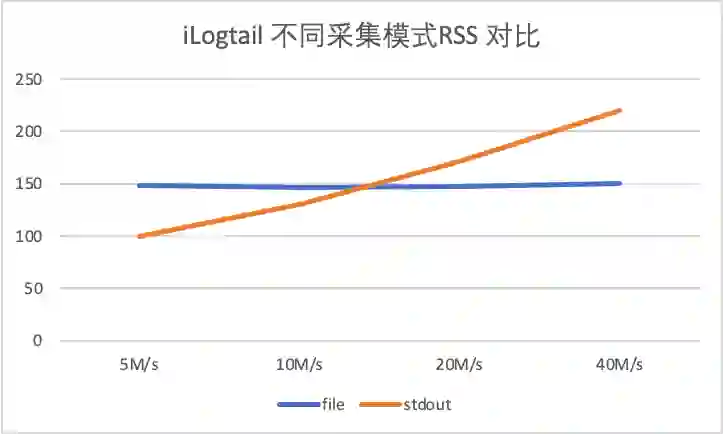
5 对比总结
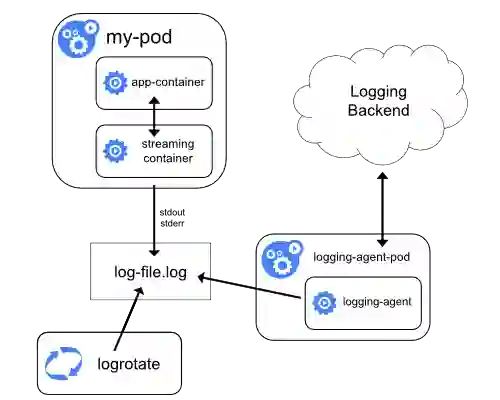
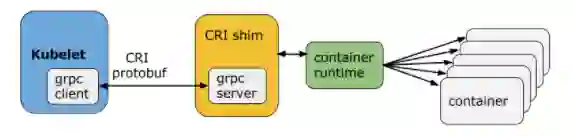
五 为什么Filebeat 容器标准输出与文件采集差异巨大?

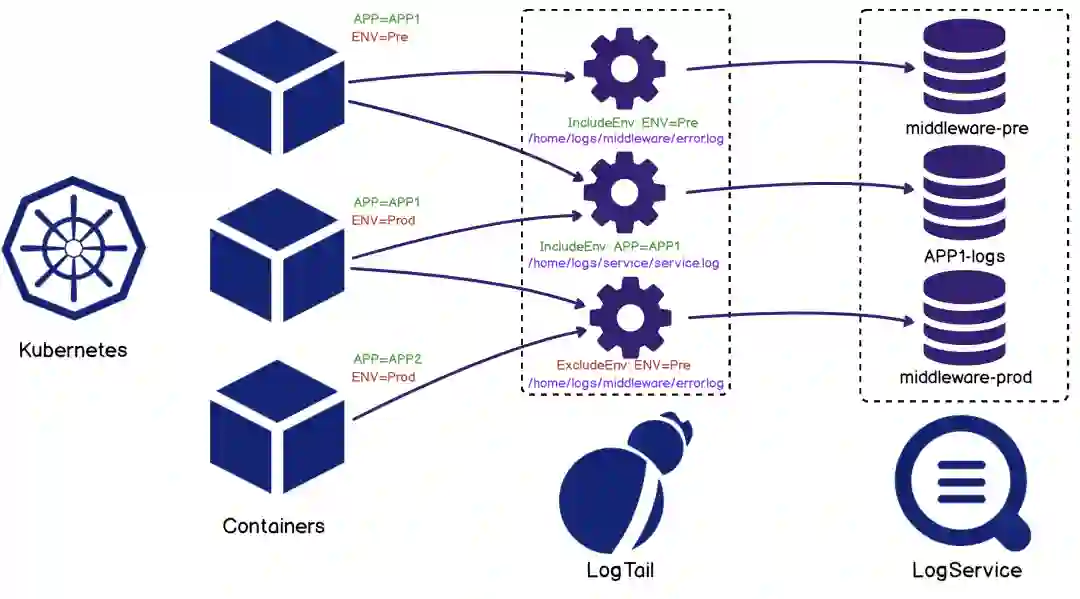
六 iLogtail DaemonSet 场景优化

-
采集路径不在依赖于静态配置路径,可以靠容器标签动态选择采集源,从而简化用户接入成本。
-
可以根据容器元信息探测容器自动挂载节点的动态路径,所以iLogtail 无需挂载即可采集容器内文件,而如Filebeat 等采集器需要将容器内路径挂载于宿主机路径,再进行静态文件采集。
-
对于新接入采集配置复用历史容器列表,快速接入采集,而对于空采集配置,由于容器发现全局共享机制的存在,也就避免了存在空轮训监听路径机制的情况,进而保证了在容器这样动态性极高的环境中,iLogtail 可运维性的成本达到可控态。
七 结语
参考文献
-
Logtail技术分享一
https://zhuanlan.zhihu.com/p/29303600
-
Logtail技术分享二
https://www.sohu.com/a/205324880_465959
-
Filebeat 配置
https://www.elastic.co/guide/en/beats/filebeat/current/filebeat-input-container.html
-
Filebeat 容器化部署
https://www.elastic.co/guide/en/beats/filebeat/current/running-on-kubernetes.html
-
iLogtail 使用指南



