Spark on Kubernetes 与 Spark on Yarn 不完全对比分析

Apache Spark 是目前应用最广泛的大数据分析计算工具之一。它擅长于批处理和实时流处理,并支持机器学习、人工智能、自然语言处理和数据分析应用。随着 Spark 越来越受欢迎,使用量越来越大,狭义上的 Hadoop (MR) 技术栈正在收缩。另外,普遍的观点和实践经验证明,除了大数据相关的工作负载,Hadoop (YARN) 不具备相应的灵活性去跟更广泛的企业技术栈融合与集成。比如去承载一些在线业务,而这正是 Kubernetes(K8s) 所擅长的领域。事实上,Kubernetes 的出现为 Spark 的改进打开了一个新世界的大门,创造了更多机遇。如果能用统一的一套集群去运行所有在线和离线的作业,也是十分吸引人的事情。
Spark on Kubernetes 于 Spark 2.3 [1] 版本引入开始,到 Spark 3.1 [2] 社区标记 GA,基本上已经具备了在生产环境大规模使用的条件。

在业内,苹果[3], 微软[4], 谷歌,网易,华为、滴滴,京东等公司都已经有内部大规模落地或者对外服务的经典成功案例。
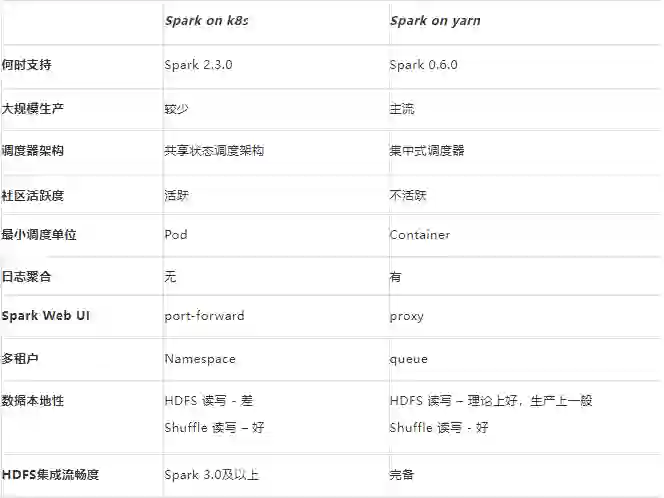
从 Spark 整体计算框架层面来看,只是在资源管理层面多支持了一种调度器,其他接口都可以完全复用。一方面 Kubernetes 的引入和 Spark Standalone、YARN、 Mesos 及 Local 等组件形成了一个更为丰富的资源管理体系。
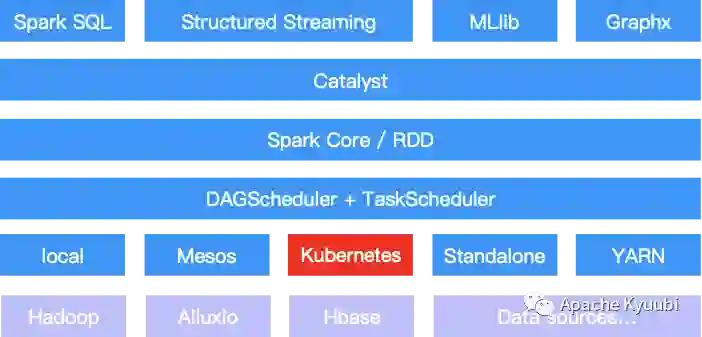
另一方面,Spark 社区在支持 Kubernetes 特性的同时,对用户 API 的兼容度也得到了最大化的保留,极大程度上方便了用户任务的迁移。比如对于一个传统的 Spark 作业而言,我们通过简单的指定 --master 参数为 yarn 或者 k8s://xxx,即可完成两个调度平台的运行时切换。其他参数诸如镜像、队列、Shuffle 本地盘等配置, yarn 和 k8s 之间都是隔离的,可以很方便地统一在配置文件中统一维护。
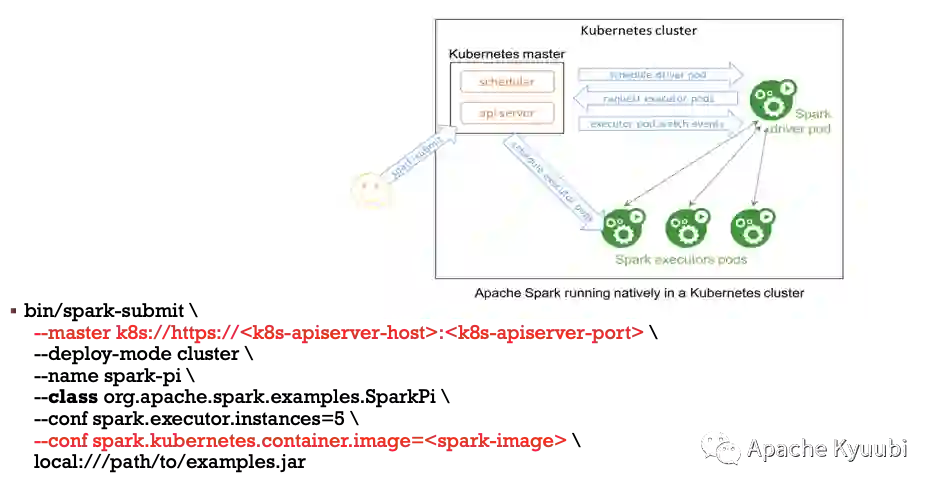
Spark Native API
以 spark-submit 这种传统提交作业的方式来说,如前文中提到的通过配置隔离的方式,用户可以很方便地提交到 k8s 或者 YARN 集群上运行,基本上一样的简单和易用。这种方式对于熟悉 Spark API 及生态的用户而言是十分友好的,基本上没有对 k8s 技术栈的硬性要求。
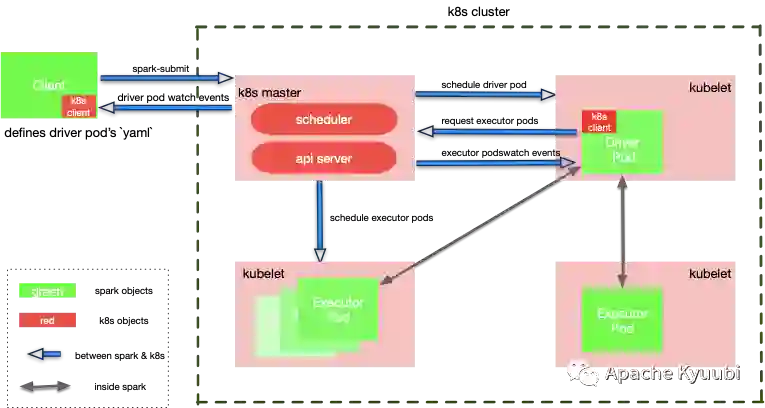
可以看到,如果我们忽略 K8s 或者 YARN 的底层细节,基本上还是熟悉的配方熟悉的味道。
Spark Operator
另外,除了这种方式, Kubernetes 在 API 上更加丰富。我们可以通过 Spark Operator[6] 的方式, 如 kubectl apply -f
Serverless SQL
当然,无论是 Spark 原生的还是 Operator 的方式,对大部分用户来说还是太原始了,不可避免的需要去感知一些底层的细节。在 Datalake/Lakehouse 场景下,数据变得民主,数据应用变得多样,很难去大范围地推广。在易用性上想更进一步,可以考虑使用 Apache Kyuubi (Incubating)[7]来构建 Serverless Spark/SQL 服务。大部分情况下,用户都可以直接使用 BI 工具或者 SQL 来直接操作数据即可。
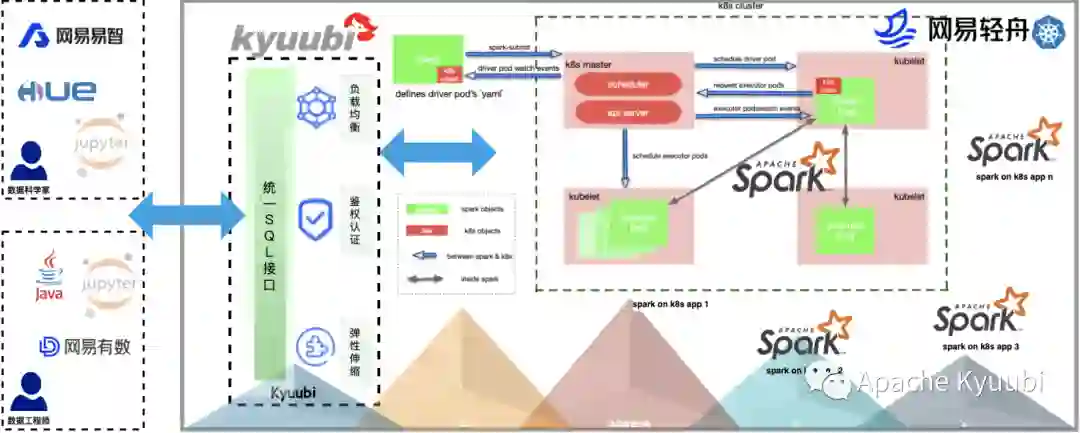
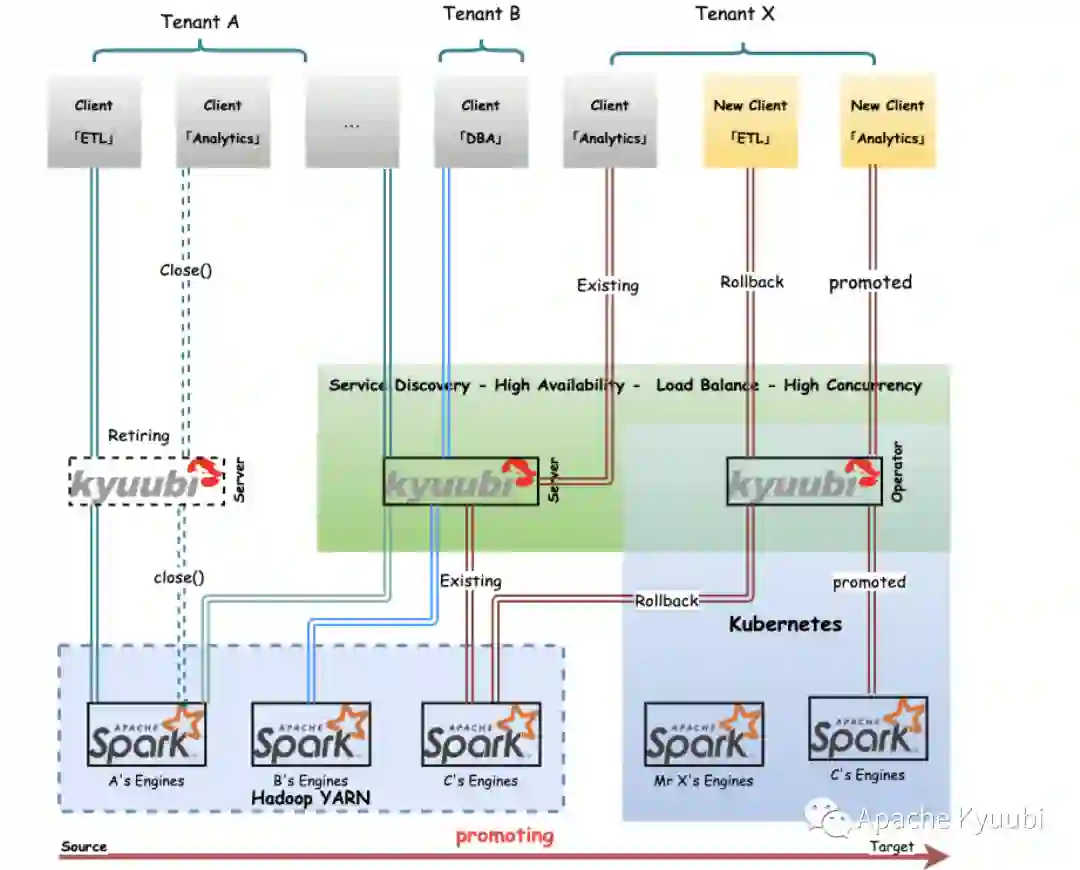
一般而言,大部分企业都会有很多离线的 Hive 或者 Spark 任务跑在 YARN 集群上,如何将大量的历史任务平滑地迁移到 Kubernetes 上也是让人头疼的问题。Kyuubi 的服务化方案,可以通过服务发现机制,提供负载均衡节点,在服务高可用的基础上,来平滑地过渡。对于个别异常迁移任务,我们也可以方便地 Rollback 到 老集群上保障执行,也留给我们定位问题的时间和空间。
从原理上,无论是 Kubernetes 和 YARN 都只起资源调度的作用,不涉及计算模型和任务调度的变化,所以在性能上的差异应该是不显著的。从部署架构上,Spark on Kubernetes 一般选择存算分离的架构,而 YARN 集群一般和 HDFS 耦合在一起,前者会F在读写 HDFS 时丧失“数据本地性”,这个由于网络带宽因素影响可能会影响性能。从存算耦合架构诞生之初经过 10 年左右的发展,随着网络的性能增长,各种高效的列式存储格式及压缩算法的加持,这点影响微乎其微。
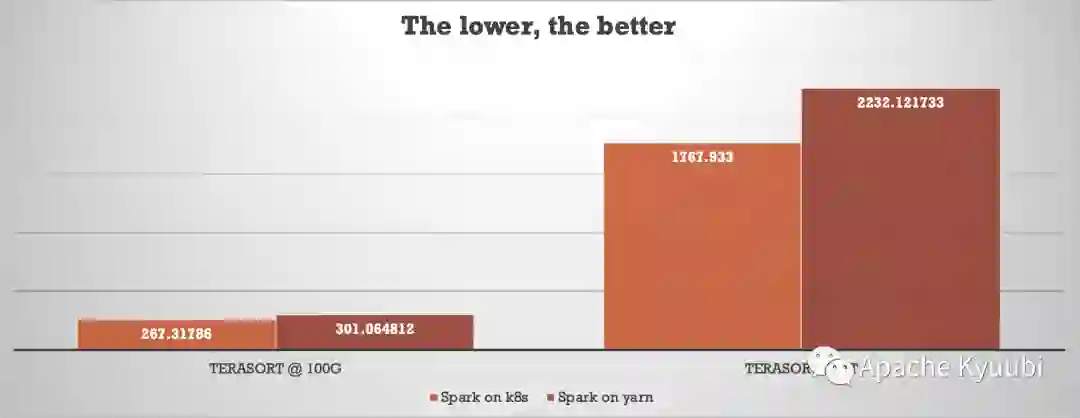
Terasort 基准测试 (By Myself)
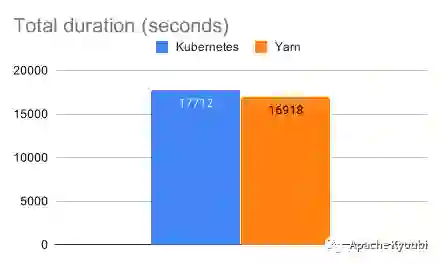
TPC-DS 基准测试(By Data mechanics)
TPC-DS 基准测试(By AWS)
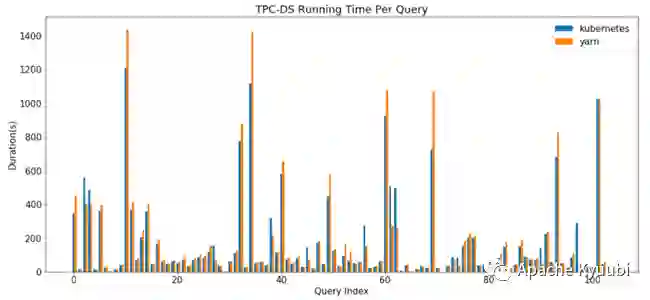
虽然这些测试结果都不是来自 TPC-DS 组织认证的官方数据,但从测试结果来自不同的机构这个因素上也有足够的说服力。我们屏蔽一些部署架构上的影响,两者的性能差距可以说是基本不存在的。
将 Spark 作业迁移至 Kubernetes 集群上,可以实现离线和在线业务的混合部署,利用两种业务特征的对计算资源潮汐错峰效应,极致的情况下光靠“离 / 在混部”就可实现 IT 总有用成本(TCO)的 50% 的节省。
另一方面,企业数据平台在不同的发展时期,集群所规划的存储算力比不同,导致服务器选型困难,而从存算分离的的角度,计算集群和存储集群分开扩容,也可以更加合理地控制 IT 成本。
此外,Spark on Kubernetes 通过 Pod 分配 Executor 模式,执行线程数(spark.executor.cores)和 Pod 的 request cpu 是分离的,可以更加细粒度的在作业级别对控制,来提升计算资源的使用效率。在我们网易的实际实践中,在不影响整体计算性能的条件下,Spark on Kubernetes 作业整体上 cpu 可以达到超 200% 的超售比。
当然,Spark on Kubernetes 在动态资源分配(Dynamic Resource Allocation)这个特性上的缺失或者不完善,可能会造成 Spark 占着资源不使用的情况。由于这个特性直接依赖外置的 Shuffle Service 服务来实现,这时候可能就需要自行去搭建 Remote/External Shuffle Service 服务。
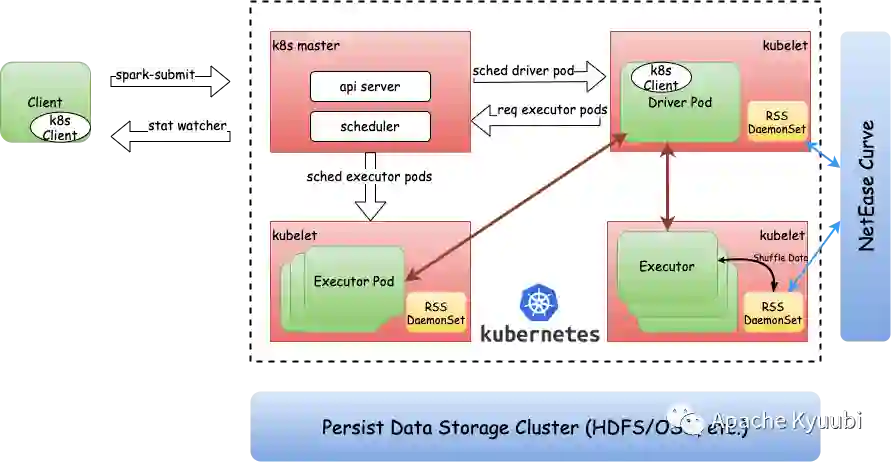
在 Spark on Kubernetes 场景下,基于 RSS/ESS 可实现临时存储与计算过程相互解耦。第一,消除本地存储依赖,使得计算节点可在异构节点上动态伸缩,在面对复杂物理或者虚拟环境时更加灵活的动态扩展。第二,离散式本地存储优化为集中式服务化存储,存储容量所有计算节点共享,提高存储资源利用率。第三,降低磁盘故障率,动态地减少标记为不可用计算节点,提升计算集群整体资源利用率。最后,转移临时存储的血缘关系,使其不再由 Executor Pod 计算节点维护,使得闲置 Executor Pod 可以被及时地释放回资源池,提升集群资源利用率。
Spark on Kubernetes 自 2018 年初随 2.3.0 版本发布以来,不知不觉已经有四个年头了,而到现在的 3.2 版本,也已经历经 5 个大版本了。在社区和用户的不断打磨下已经成为了非常成熟的特性了。
随着 Apache Spark 开源生态不断发展,如 Apache Kyuubi 等,无论是哪个调度框架,易用性上都得到大幅提升。
IT 基础设施的总拥有成本(Total Cost of Ownership, TCO) 逐年上涨,一直是困扰很多企业的难题。Spark + Kubernetes 的组合的灵活性和超高性价比,给了我们更多想象的空间。
作者介绍:
Kent Yao,网易数帆技术专家,Apache Kyuubi(Incubating) PPMC,Apache Spark Committer
参考资料:
[1]https://issues.apache.org/jira/browse/SPARK-18278
[2]https://issues.apache.org/jira/browse/SPARK-33005
[3]https://www.youtube.com/watch?v=xX2z8ndp_zg
[4]https://www.youtube.com/watch?v=hcGdW_6xTKo
[5]https://ieeexplore.ieee.org/document/9384578
[6]https://github.com/GoogleCloudPlatform/spark-on-k8s-operator
[7]https://github.com/apache/incubator-kyuubi
[8]https://aws.amazon.com/cn/blogs/containers/optimizing-spark-performance-on-kubernetes/

点个在看少个 bug 👇