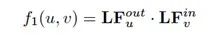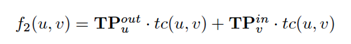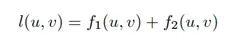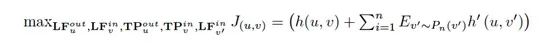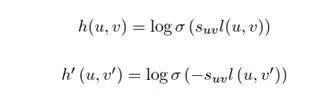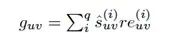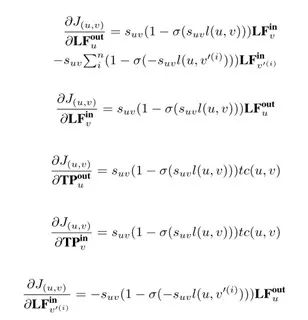寻找有效、可行的社交信任网络表示学习方法是社交网络领域关注的焦点之一。2019年,Pinghua Xu, Wenbin Hu, Jia Wu, Weiwei Liu, Bo Du, Jian Yang等学者发表了关于社交信任网络表示学习的论文《Social Trust Network Embedding》,文章综合考虑社交信任网络中与信任传递相关的两个最主要因素:用户与他人建立信任关系时的隐含因素和信任传递机制,对如何表示及同时利用以上两个因素来解决社交信任网络表示学习提出了一种新的方法-STNE。经过大量测试和论证,作者提出的方法在部分主流测试数据集上较传统方法取得了明显突破,STNE方法将对社交信任网络学习等提供理论基础,是社交信任网络表示方法非常重要的参考文献。
![]()
https://ieeexplore.ieee.org/abstract/document/8970926
寻找用于社交信任网络的有效、可行的表示学习方法是一个很重要的问题,其难点在于要同时保留用户关系中存在的隐含特征和对用户信任传播起关键作用的信任传播机制。在本研究中,我们提出了用于解决上述问题的新的表示学习方法
-STNE。
具体而言,我们基于
Skip-Gram模型,利用负抽样方法,通过迭代优化来学习用户关系中存在的隐含因素(以下简称隐含特征)和信任传播特征(以下简称传播特征)。
于此同时,我们还提出了确定社交网络用户与其他用户可能存在的隐含信任关系的方法,并使用该方法来生成我们学习算法中需要的负样本。最后,我们在几个真实网络的数据集上对
STNE的有效性进行了测试并证明了STNE方法的有效性。
目前,部分社交网站允许用户对其他用户所发布的信息进行信任或不信任评价,这种用户反馈机制在某种程度上有效提升了这些网站所提供的服务水平。
Epinions网站作为其中之一,正是利用这种用户对其他人提供的商品评价信息的信任评价,一方面根据用户反馈的信任信息将相关用户进行关联,另一方面预判不直接相关用户之间的关系,通过这种关联和预判,为用户提供更有效的反馈信息。
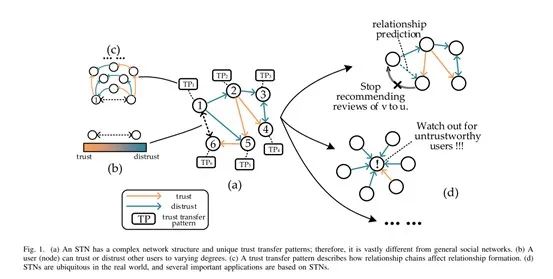
比特币平台在实际运行过程中也利用这种信用评级机制来检测网络中的不可信用户和可能存在交易风险。社交信任网络与常见的社交网络存在以下两点明显不同:第一,从网络结构上讲,用户对其他用户的信任或不信任程度使用权重来计量,而这种权重使得用户之间的关系更为复杂;第二,从更深层次讲,社交信任网络中用户间信任关系的传播机制无法使用普通社交网络内的关系传播机制来有效解释。在本论文中,我们将社交信任网络简称为
STN(social trust network),STN的主要结构和应用如下图所示:
![]()
对STN内数据信息的处理能够有效发挥STN在不同应用领域的作用。
如何将
STN内的数据信息以更有效的方式表达是该研究领域的重点研究对象之一。
本文所提供的正是一种表达学习方法。
网络表示学习(network embedding)的目的就是学习一种对网络数据更低维度的表达,并使用这种更低维度的特征来处理不同的网络数据分析任务,例如:
链路预测、节点分类网络可视化。由于图或网络中
“边”的学习时间复杂度相对高,因此,目前大多数网络表示学习都是对网络中的节点信息进行处理,换而言之,就是对节点进行表示学习。
在表示空间内,节点之间的距离能够反映出这些结点之间的结构相似性。这种从原有空间向表示空间的映射能够使在原空间内相互关联的结点在映射后具有相近的隐含特征。上述方法在现有的普通社交网络内能够取得很好的效果,但是它们并不一定适用于
STN,主要原因有:
第一,
STN内的关系更为复杂,那些无法处理复杂关系的表示学习方法无法有效抽取和保留STN网络的结构信息;
第二,信任关系的传递模式也是
STN的重要特征之一,信任关系的传递模式能够帮助我们很好的定位用户在整个STN内的角色和权重,然而,上述方法在该领域内的表现并不尽如人意。
我们所提出的
STNE(social trust network embedding)方法能够弥补上述不足,并且,STNE能够在表示学习的过程中,即对信任传递模式和结点间关系进行很好的处理,同时,又能够对结点本身的隐含特征进行保留。
STNE方法的优势也正在于对上述两点突出问题的解决。
基于该方法,每个结点的特征包括以下两对隐含特征和两对传播特征。隐含特征有:用户如何基于隐因子去信任用户(出链)和被其他用户所信任(入链);传播特征有:用户如何基于关系链去信任其他用户(外链)或被其他用户信任(入链)。基于原有在自然语言处理领域的研究成果,在
STNE方法中,我们提出了一种改进过的Skip-Gram模型,并利用结构平衡理论(structural balance theory)和随机行走(random walk),通过生成负样本,对模型进行训练和优化,从而学习这些隐含特征和传播特征。
我们在真实社交信任网络内对STNE方法进行了验证,结果表明,STNE能够有效的学习到社交信任网络的低维度表示。
该论文的其余部分组织如下:预备知识将在第二部分进行解释。我们提出的
STNE方法会在第三部分进行介绍。
第四部分详细介绍实验过程,最终结论将在第五部分给出。
在本部分,我们首先介绍符号的使用,然后介绍问题的定义。
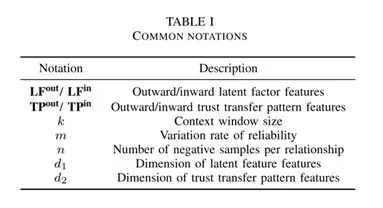
本文包含许多向量运算和一些标量参数,因此,为了避免混淆,我们遵循矩阵计算一书中的表达规则,使用粗体字母表示向量和矩阵。下表列出了常用的一些符号的定义。
![]()
STN可以定义为G=(V,E),其中,V是用户(结点)的集合,E是用户之间关系(边)的集合。
每个用户都与一个未被观测到的函数相关联,该函数表示用户的信任传递模式。每个关系euv属于E是一个二元组(u,v)
,其中u,v属于V,该关系与一个信任值tuv相关。tuv
的符号表明这种关系的性质
-信任或不信任,tuv的绝对值表示这种关系的强度。
在大多数情况下,
STN中的关系是有向的,而我们的研究也着重关注这种有向的STN。
需要强调的是,我们所提出的方法能够很好地进行泛化来解决无向
STN中用户的低维度向量表示w问题,这种泛化有助于后续的分析和研究。
由于学习用户的低维表示的目的在于支持网络分析任务,这种低维表示应该能够清晰地反映用户在网络中的各种角色。
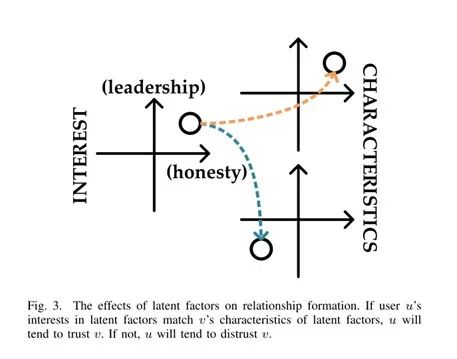
在STN中,我们假设用户u信任另外一个用户v的原因有以下两个:
一是的隐含特征中对其他用户的兴趣程度与
v的隐含特征中的自身特征相匹配。
例如:
u重视诚实,而v是诚实的,因此u相信v。
二是
u与v之间的关系链会促使u相信v,比方:u倾向于模仿他所信任的人,而他所信任的人相信v,因此,u相信v。
上述原因中,第一条与隐含特征相关,第二个与传播特征相关,因此隐含特征和传播特征都应当在用户的低维度表示中加以保留。对此,对每个用户
u我们用LFuout来表示用户的向外隐含特征,用LFuin表示用户的向内隐含特征,用TPuout表示用户的向外传播特征,用TPuin表示用户的向内传播特征。
一个简单而有效的反映用户隐含特征和传播特征的方法是将他们串接起来。还有其他方法可以用于反映用户的上述特征,我们会在未来进行研究。
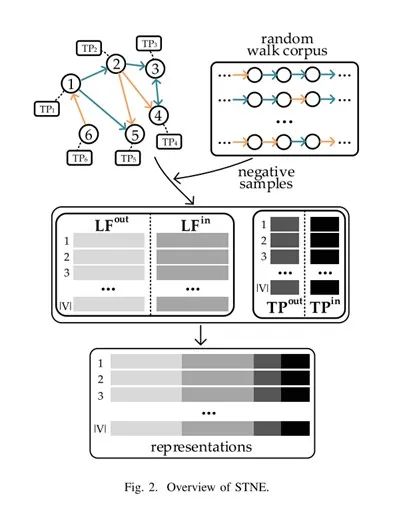
接下来的章节描述了如何衡量隐含特征和传播特征对关系形成的影响。然后,我们解释
STNE如何利用Skip-Gram和负抽样学习每个结点的隐含特征和传播特征。
具体方法见下图。
![]()
上述章节中已经说明了STN网络中的结点之间的关系是有向的,因此每一个用户既可以是关系的源,也可以是目标。
对应的,每个用户都具有两个隐含特征(具体描述前面章节已经进行了描述,这里不再重复)。需要解释的是,
u向v建立关系是基于用户u的LFuout和用户v的LFvin。
此外,STN还包含相反的关系-信任关系和不信任关系。
通常情况下,我们假设一个用户
u倾向于信任v如果u的兴趣与v的特点向吻合;
相反的,一个用户
u倾向于不信任v如果u的兴趣与v的特点差异很大(见下图)。
因此,我们使用内积来衡量不同用户之间的这种相似性。结点对(u,v
)之间的相似性为:
![]()
![]()
我们使用内积来度量相似性基于以下两个原因:首先,内积所表达的物理意义与我们的假设一致。其次,计算内积的导数很容易,这也保证了该方法具有很好的可扩展性。
对于这种计算方式,有的人可能认为它无法将信任关系和不信任关系与不存在的用户间关系(没有连边的节点对)区分开来。诚然,这是事实,但实际问题中,我们看中的是确定一个用户是否会信任或不信任其他用户,是通过表示学习来区分信任和不信任关系。
信任的传播特性是STN的一个重要特征。
对于给定的用户序列,(u0,
u1,u2,......um),其中相邻结点之间的关系可以形成一条关系链,信任传播特征描述了这些关系链如何影响u0和um之间的关系。
之前的许多研究都集中在对全网的信任传播模式的研究上。但是,在微观层面,
STN中的每个用户都具有其独自的信任传播模式,而且这种模式与全局模式并不总是一致。
提取每个用户的个性化信任传播模式能够帮助我们更好的了解每个用户的角色,而且这种角色信息对于分析而言是很有价值的。在信任传播模式中,关系链越短,传播模式对关系的形成就越重要。因此,在本研究中,我们关注长度为
3的最强关系链,其他长度的关系链对关系的形成也会产生影响,但这些我们留在未来的工作中去做。
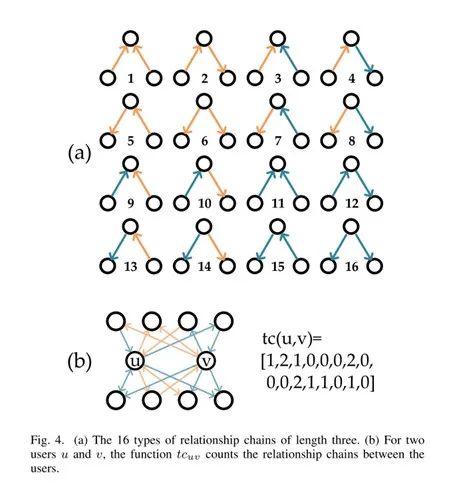
在长度为
3的关系链中,用户与用户之间的关系共有16中情况(共2条边,每条边2个方向,每条边的每个有2种含义)。
这种
16种关系枚举如下:
![]()
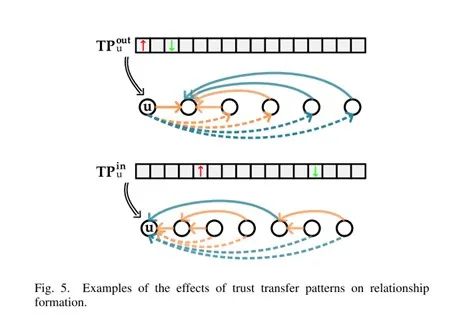
为了能够保留信任传播模式,我们给每个用户定义了一个向外的信任传递特征和一个向内的信任传播特征。上面的关系链共有
16种可能,我们使用16维向量来表示。
用户信任传播特征中的每个值表示该维度所对应的关系链对用户关系形成所能造成影响的大小。具体而言,某个维度上的正值表明用户在这种关系链上倾向于他人建立信任关系,而这个值的绝对值大小表明该关系链所表示的关系对最终形成的关系影响程度。
![]()
例如,图5所示的TPuout的第一个分量值为正且绝对值大,第三个分量值为负且绝对值也很大,这种情况表明,u会坚持他与v的关系,对于信任v的人,他会选择信任,而对于不信任v的人,他选择不信任。在图5所示的另外一个例子中,TPuin的第五个分量为正且绝对值大,第13个分量值为负且绝对值大,这表明,他人对u的信任或不信任取决于他们所认识的其他人对u是否信任。对给定的用户u和v,他们之间的16种可能存在的关系链用tc(u,v)表示,每种可能性对应一个分量,分量的值为该分量对应的关系链在u和v的所有关系链中出现的次数。我们通过以下方法来度量u和之间因关系链而形成的关系:
![]()
![]()
然后,利用调整后的Skp-Gram模型和负抽样来学习每个用户的上述4个特征。u与v之间关系的的目标函数为:
![]()
![]()
s
uv为符号函数,如果u信任v,则suv为正,反之为负。(u,v′)表示负样例,表示负抽样的概率分布。
如果
u信任v,J(u,v)随着f1(u,v)的增长而增长,反之随着f1(u,v)的降低而降低。
因此,相似用户在隐含特征空间中的他们的位置相对更近,与不相似用户位置则较远。信任传播模式模拟用户如何建立或接收关系。通过最大化目标函数,每个信任关系(不信任关系)都会增加(减少)传播特征中对应关系链所在分量的取值。
STNE的目标函数为:
![]()
通过最大化目标函数,每个结点的隐含特征和传播特征可以同时学到。
在一对关系(u,v)的目标函数中,如果u信任v,那么最大化J(u,v)将会减小l(u,v′),同时u会倾向于不信任v′。
这一过程意味着,给定一对关系
(u,v),负样本中的潜在关系应该包含和当前关系(u,v)相反的关系。
剩下的问题就是如何确定负样本的概率分布Pn(v′)满足上述要求了。也就是说,我们需要对给定的用户
u,寻找那些u倾向于信任或不信任的用户v以及这种信任或不信任的程度。
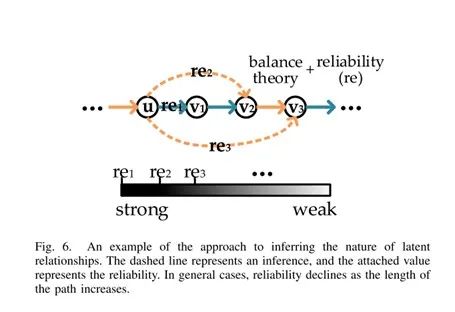
为此,我们采用random walk方法,通过生成路径集合,来获取结点之间可能存在的潜在关系。
通过设置上下文窗口,在窗口中同时出现但并没有直接联系的用户间应该具有很强的潜在关系。由于信任和不信任是对立的,所以推断潜在关系的内在本质非常关键。我们利用结构平衡理论来推断两跳路径中潜在关系的关系类型(例如我信任我信任的人)。通过不断迭代这种两跳路径,我们就能够得到一个多跳潜在关系。
显然,该理论并不是总与现实的社交网络中的真实情况一致,推论可能出现错误。因此,我们假设关系的推论的可靠性随着路径长度的增加而降低。这种推论如图
6所示。
下面的函数可以用于表述这种可靠性reuv
:
![]()
其中,luv表示u与v之间的距离,参数m决定可靠性的变化率。
如果
m=0表示推理是绝对可靠地,m=1表示可靠性随着推理次数的增加而线性下降。
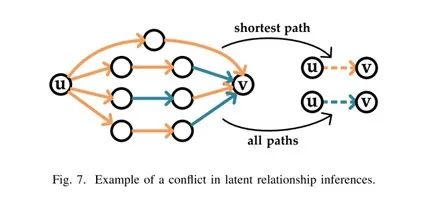
生成的路径集合中可能包含许多含有结点u和v的路径,这种情况下,可能会出现矛盾,比如某条路径推测u应该信任v而另一条路径则推测u不应该信任v。
之前有学者认为从最短路径推测得到的关系应该作为推测结果,但我们认为这种方法不一定准确。如图
7所示,最短路径认为u应该信任v,但是综合所有路径考虑,u不应该信任v。
![]()
对此,我们使用suv(i)来表示第i条路径的推测结果,reuv(i)来表示对应推测结果的可靠性。
我们将所有路径对推理的综合影响度量为:
![]()
其中,q为u和v都出现的路径的个数。
利用上面的计算结果,我们可以计算抽样样本的概率分布,具体算法见
Algorithm1。
如算法所示,计算抽样样本的概率分布的输入包括整个
STN本身和超参数k及m,其中k表示Skip-Gram方法中的窗口大小,m为计算reuv时所选取的可靠性变化率,算法的最终输出为以每个结点u为源进行抽样的概率分布,对应的正样本概率分布表示为Pnu+,负样本概率分布为Pnu-。
算法采用常用的均匀分布随机行走方法来生成路径集合,对集合中的每条路径以及路径中的每个结点,利用上文中计算reuv以及guv
的公式,计算结点u和v之间的关系(信任或不信任以及对应的度)。
对所有路径遍历结束后,利用各结点之间计算得到的guv及其符号,计算以每个结点为源的正(负)抽样概率分布Pnu+
及Pnu-。
![]()
![]()
按照随机梯度上升的方法进行优化。由于负样本中相领的样本数很少,因此在计算过程中对负样本点的传播特征可能无法得到很好地保留。为了提高迭代效率,负样本点的传播特征在计算时忽略不计。对于关系
(u,v),目标函数的导数为:
![]()
对STNE方法的优化过程可以用Algorithm2来表示:
![]()
在算法1中,计算样本概率分布的时间复杂度为O(|V|)。
当每个关系取
n个负样本时,更新,,的复杂度分别为O((n+1)d1),O(d1),O(d1)。
更新TPuout和TPvin
的复杂度为O(d2)。
大多数情况下,在训练集
T内,d1>d2,算法1的整体时间复杂度近似为O((n+1)d1|E|T)。
需要注意的是,当davgout为整个网络的平均出度时,
|E|=|V|。
由于现实社交网络往往是非常稀疏的,因此davgout
<<|V|。
同时,参数
n,d1和T的值远小于|V|。
所以,算法
2的时间复杂度为线性复杂度O(|V|),这也意味着STNE方法具有可扩展性。
为了评估STNE表示学习的效果,我们进行了一系列设计预测任务的实验。在介绍了数据集、比较方法和参数设置后,我们给出了结果,并讨论了隐含特征和传播特征。本部分以参数敏感性分析和收敛性分析结尾。
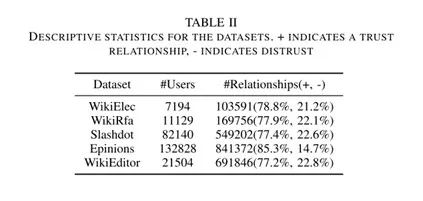
•Epinions是一个消费者评论网站。网站成员信任或不信任其他成员。
•Slashdot是一个与技术相关的新闻网站,用户可以将其他用户进行标记为朋友(信任)或敌人(不信任)。
•WikiElec是一个投票网站,用户可以投票支持(信任)或不支持(不信任)其他用户来管理网络。
•WikiEditor是基于Wikipedia共同编辑构建的。我们认为两个用户之间是信任关系如果他们共同编辑的大多数词条属于同一类别(>90%)。
![]()
预测关系时,我们随机a%的关系作为测试集,剩下的用于训练。a的取值为40,60,80。在选择的过程中没有结点或用户是孤立的并且每个随机选择都会重复10次。
我们将STNE与Node2vec、Large information network embedding(LINE)、Link-oriented signed network embedding(LSNE)、Matrix factorization(MF)、Signed directed network embedding(SIDE)和Scalable embeddings for signed networks(SIGNet)进行了比较。
在随即游走方法中,我们设w=80,l=40,k-10。STNE使用生成的路径集合计算抽样分布。客观起见,我们将基于边缘采样的方法的样本量设置为|V|wlk。对于最终学习得到的表示方法,我们设置它的维度为64,并设置STNE的d1=48,的d2=16。对于负采样,我们设置n为5,对每个点选取5个负样本。计算时,我们将m设置为1。
我们的第一组实验是为了评估STNE预测关系本质的能力。
首先从训练集中学习结点的表示方法,随后,用学习到的表示方法训练一个逻辑回归模型。
由于一个关系涉及两个结点,一个结点对的特征我们用这三种方式进行计算:
con−luv=(xu,xv),avg−luv=(xu+xv)/2,had−luv=xu◦xv。
其中是结点u的表示。
考虑到STN的不平衡性,我们使用AUC和micro-F1值来衡量计算效果。
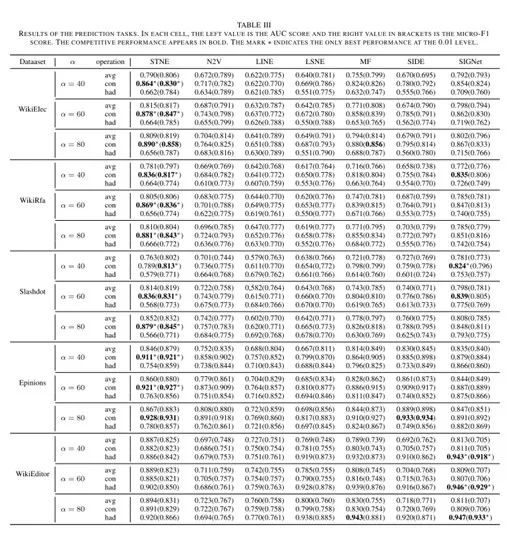
具体结果如下表所示:
![]()
•STNE在大多数情况下都表现出了良好的性能,这表明该方法在预测关系本质方面的优越性。
•虽然N2V不是为了STN复杂关系而设计的,但是它的表现超出预期。
LINE方法不如N2V,说明Skip-
Gram方法在预测方面具有一定的优势。
•LNSE本质上是LINE的升级,它的性能优于LINE。
但是LNSE的测试结果并不如SIGNet、SIDE和STNE,这种差异可能与采样策略有关。
•所有方法在Epinions数据集上的表现好于其他数据集,我们认为这是由于该数据集中不信任关系的比例
少而引起的。
从直觉上来看,更高比例的不信任关系对预测任务构成了更大的挑战。
•此外,获取结点对特征的方法对预测的准确性也有明显的影响。
在大多数情况下,串接(con)优于平均(avg)和hadamard法,因为串接能够获取更高维度的信息特征。
hadamard方法在WikiEditor数据集上的最优表现可能是因为该数据集或网络中关系的形成更依赖于隐含特征。
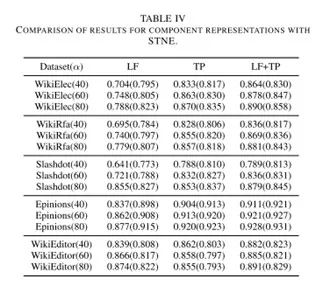
STNE方法学习到的表示方法由LF和TP组成。
在进一步实验中,我们分别评估了LF和TP对预测性能的影响。
首先我们仅适用LF进行了测评,随后仅适用TP进行了测评,最后将两者都纳入计算进行了测评,测评结果如下:
•有隐含特征和信任传播特征共同组成的表示方法由于只包含其中之一的表示方法。
这一结果说明同时考虑隐含特征和信任传播特征对预测任务至关重要。
•仅包含隐含特征或信任传播特征的表示方法也能够取得令人满意的效果。
虽然在我们的设定中,隐含特征的维度为48,是传播特征(16维)维度的3倍,但在多数情况下,信任传播特征的表示方法优于隐含特征。
这可能是因为预测任务与信任传播特征更为相关。
•尽管基于信任传播特征的预测较为可靠,但在一些特殊情况下他们的准确性并不尽如人意。
在WikiEditor网络上,仅用信任传播特征很难区分信任和不信任关系。
•总体而言,我们发现利用隐含特征和信任传播特征的组合来做预测是必要的。
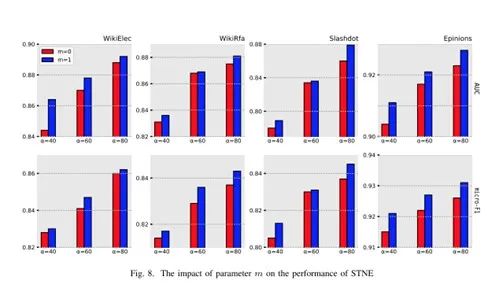
参数的敏感性分析主要是为了超参数m以及k的取值对表示学习效果的影响。
1.m取值的影响。
参数m的选择决定了推理可靠性的变化程度。
为了研究m的影响,我们固定了其他参数的取值,并对m分别取值为0和1(取值为0和1时表示的可靠性关系参照前文)进行了实验,结果如下图所示,我们发现,m为1时实验结果优于m为0时的结果,这表明结点之间关系的推论并不完全可靠,抑制这种可靠性还有助于生成更高质量的负样本。
![]()
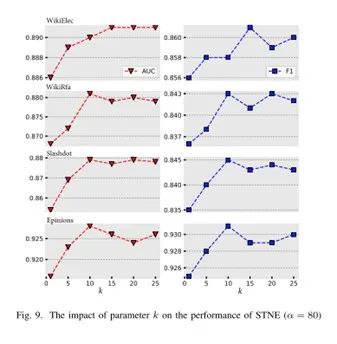
2.k取值的影响。
参数k决定了用来生成负样本的上下文窗口的大小,较大的k表明在抽样期间考虑更多的结点。
为了研究k值的影响,我们固定其他参数,k的取值范围为1,5,10,15,20。
实验结果如下图所示。
我们发现当k为1时,结点之间隐含的关系会被完全忽略,因此选取用于训练模型的负样本很难。
模型的性能也因此受损。
随着k值的增加,STNE的性能会出现增长,随后趋于稳定。
但是,更大的k会导致我们在构建样本时进行更多的计算(参照前面章节的时间复杂度分析,算法1在遍历计算时,遍历的次数与k值直接相关),因此,在计算时间和模型性能间进行这种后,我们对k取值10。
![]()
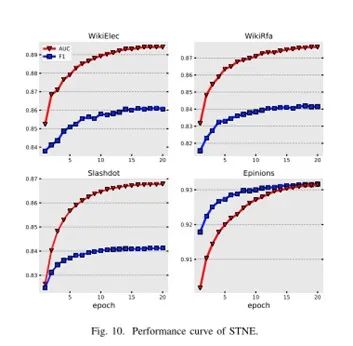
在本小节,为了评估STNE的收敛性,我们在每个epoch中使用全部的关系数据集合对模型进行训练。
我们对每个epoch训练得到的表示方法进行了保存,并用这些表示方法进行关系预测。
测试结果如下图所示。
结果表明,在所有的数据集中,STNE的表现随着训练epoch次数的增加开始增长明显,随后趋于稳定。
STNE会在开始训练后的第10个epoch取得很好的效果,这也证明了STNE具有良好的收敛性和稳定性。
![]()
通过此次研究,我们提出了新的社交信任网络表示学习方法-STNE,该方法能够同时有效处理社交网中各用户的隐含特征和传播特征并通过使用random walk方法和结构平衡理论,在社交网络中获取negative samples以优化学习方法。最终得到的基于Skip-Gram模型和negative sampling的模型能够有效地学习到社交网络中各节点的特征表示,通过在真实数据集内的测试和论证,该方法生成的节点特征适用于社交信任网络分析等领域。
[1] J. Leskovec, D. Huttenlocher,and J. Kleinberg, “ Signed networks in social media,” in Proceedings of theSIGCHI conference on human factors in computing systems. ACM, 2010, pp. 1361–1370.
[2] S. Kumar, B. Hooi, D.Makhija, M. Kumar, C. Faloutsos, and V. Subrahmanian, “ Rev2: Fraudulent userprediction in rating platforms,” in Proceedings of the Eleventh ACMInternational Conference on Web Search and Data Mining. ACM, 2018, pp. 333–341.
[3] G. Kossinets and D. J. Watts,“ Empirical analysis of an evolving social network,” science, vol. 311,no.5757, pp. 88– 90, 2006.
[4] A.-L. Barab´asi and R.Albert, “ Emergence of scaling in random networks,” science, vol. 286, no.5439, pp. 509– 512, 1999.
[5] P. Cui, X. Wang, J. Pei, andW. Zhu,“ A survey on network embedding,” IEEE Transactions on Knowledgeand DataEngineering, 2018.
[6] Y. Shen and R. Jin, “Learning personal+ social latent factor model for social recommendation,” inProceedings of the 18th ACM SIGKDD international conference on Knowledge discoveryand data mining. ACM, 2012, pp. 1303– 1311.
[7] C. Yang, M. Sun, Z. Liu, andC. Tu, “ Fast network embedding enhancement via high order proximityapproximation.” in IJCAI, 2017, pp. 3894– 3900.
[8] L. Du, Z. Lu, Y. Wang, G.Song, Y. Wang, and W. Chen, “ Galaxy network embedding: A hierarchical
community structure preservingapproach.” in IJCAI, 2018, pp. 2079– 2085.
[9] D. Zhang, J. Yin, X. Zhu, andC. Zhang, “ Sine: Scalable incomplete network embedding,” in 2018 IEEEInternational Conference on Data Mining (ICDM). IEEE, 2018, pp. 737– 746.
[10] A. Tsitsulin, D. Mottin, P.Karras, and E. M¨uller, “ Verse: Versatile graph embeddings from similaritymeasures,” in Proceedings ofthe 2018 World Wide Web Conference on World WideWeb. International World Wide Web Conferences Steering Committee, 2018, pp.539– 548.
[11] T. Mikolov, K. Chen, G.Corrado, and J. Dean, “ Efficient estimation of word representations in vectorspace,” arXiv preprint arXiv:1301.3781, 2013.
[12] K. B. Petersen, M. S.Pedersen et al., “ The matrix cookbook,” Technical University of Denmark, vol.7, no. 15, p. 510, 2008.
[13] J. A. Golbeck, “ Computingand applying trust in web-based social networks,” Ph.D. dissertation, 2005.
[14] J. L. Aditya Grover, “ node2vec:Scalable feature learning for networks,” in Acm Sigkdd International Conferenceon Knowledge Discovery Data Mining, 2016.
[15] D. Cartwright and F. Harary,“ Structural balance: a generalization of heider’ s theory.” Psychological review,vol. 63, no. 5, p. 277, 1956.
[16] M. R. Islam, B. A. Prakash,and N. Ramakrishnan, “ Signet: Scalable embeddings for signed networks,” inPacific-Asia Conference on Knowledge Discovery and Data Mining. Springer, 2018,pp. 157– 169.
[17] J. Leskovec, D. Huttenlocher,and J. Kleinberg, “ Predicting positive and negative links in online socialnetworks,” in Proceedings of the 19th international conference on World wideweb. ACM, 2010, pp. 641– 650.
[18] R. West, H. S. Paskov, J.Leskovec, and C. Potts,“ Exploiting social network structure forperson-to-person sentiment analysis,” Transactions of the Association for ComputationalLinguistics, vol. 2, pp. 297– 310, 2014.
[19] S. Kumar, F. Spezzano, and V.Subrahmanian, “ Vews: A wikipedia vandal early warning system,” in Proceedingsofthe 21th ACM SIGKDD international conference on knowledge discovery and datamining. ACM, 2015, pp. 607– 616.
[20] S. Kumar, F. Spezzano, V. Subrahmanian,and C. Faloutsos, “ Edge weight prediction in weighted signed networks,” inData Mining (ICDM), 2016 IEEE 16th International Conference on. IEEE, 2016, pp.221– 230.
[21] J. Tang, M. Qu, M. Wang, M.Zhang, J. Yan, and Q. Mei, “ Line: Largescale information network
embedding,” in InternationalConference on World Wide Web, 2015.
[22] D. Du, W. Hao, X. Tong, Y. Lu,and E. Chen, “ Solving link-oriented tasks in signed network via an
embedding approach,” in IEEEInternational Conference on Systems, 2017.
[23] C.-J. Hsieh, K.-Y. Chiang,and I. S. Dhillon, “ Low rank modeling of signed networks,” in Proceedings ofthe 18th ACM SIGKDD international conference on Knowledge discovery and data mining.ACM, 2012, pp. 507– 515.
[24] J. Kim, H. Park, J.-E. Lee,and U. Kang, “ Side: Representation learning in signed directed networks,” inProceedings of the 2018 World Wide Web Conference on World Wide Web.International World Wide Web Conferences Steering Committee, 2018, pp. 509–518.
[25] J. A. Hanley and B. J.McNeil,“ The meaning and use of the area under a receiver operatingcharacteristic(roc) curve.” Radiology, vol. 143, no. 1, pp. 29– 36, 1982.
专知,专业可信的人工智能知识分发,让认知协作更快更好!欢迎注册登录专知www.zhuanzhi.ai,获取5000+AI主题干货知识资料!
欢迎微信扫一扫加入专知人工智能知识星球群,获取最新AI专业干货知识教程资料和与专家交流咨询!
点击“
阅读原文
”,了解使用
专知
,查看获取5000+AI主题知识资源