38篇CVPR2020 GAN论文合集!
来自 | 知乎
地址 | https://zhuanlan.zhihu.com/p/114303075
作者 | 江山如画
编辑 | 机器学习算法与自然语言处理,专知公众号
本文仅作学术分享,若侵权,请联系后台删文处理
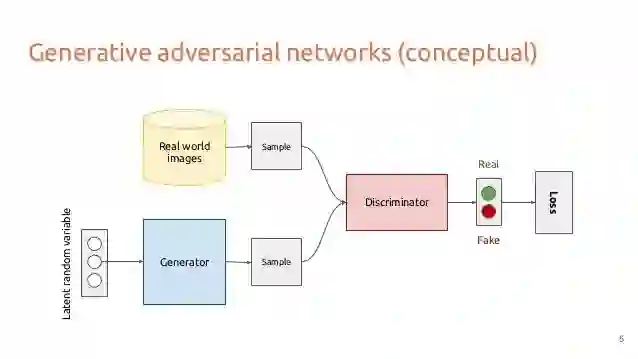
以后会持续更新,希望大家能够一起探讨,共同学习,有兴趣可以私信我。
4月29日已更新,增加3篇,共38篇。
4月24日已更新,增加2篇,共35篇。
4月17日已更新,增加4篇,共33篇。
4月14日已更新,增加1篇,共29篇。
4月10日已更新,增加4篇,共28篇。
4月06日已更新,增加1篇,共24篇。
4月02日已更新,增加3篇,共23篇。
3月31日已更新,增加3篇,共22篇。
3月30日已更新,增加2篇,共19篇。
1、Interpreting the Latent Space of GANs for Semantic Face Editing
CUHK Bolei Zhou团队的文章,第一作者Yujun Shen目前在FacekBook做Research intern。该文章主要讲对已经训练好的GAN进行编辑,训练超平面,将图像的特征和latent code对应起来,通过编辑latent code距离超平面的距离来控制图像的特征信息。主要的实验是在StyleGAN和ProGAN上进行的。目前从效果上来看尚未能够完全的将特征解耦。由于我比较关注ID信息,发现变化过程中ID信息难以维持。这篇文章挂出来比较久,应该很多人都知道了。
2、Image Processing Using Multi-Code GAN Prior
和第一篇文章是相同团队的作品,所以研究内容也是一脉相承。该文章主要讲利用已经训练好额GAN网络对训练集不可见domain图像的重构,同样也是在styleGAN和proGAN上进行试验的。由于单一噪声学习到的是训练集的分布,所以为了完成对未知domain图像的重构,作者采用多个噪声输入。作者认为“每一个噪声无法重构完整的图像,但是能够重构出图像的一部分内容,所以多个噪声联合,便能够重构出完整的图像”。当然,如果在噪声域进行联合,则依然跳不出噪声的分布,所以是在生成器的中间层,多特征进行融合。最终效果也是非常好,对于不可见图像完成逼真的重构。该方法可以作为无监督的方法实现图像的超分、去噪、上色等等。具有较大的应用价值,强烈推荐。
3、Cascade EF-GAN: Progressive Facial Expression Editing with Local Focuses
该文章主要实现的是人脸表情编辑。
4、Alleviation of Gradient Exploding in GANs: Fake Can Be Real
GAN的判别。
5、Noise Robust Generative Adversarial Networks
这篇文章讲的是在有噪声的训练集上训练GAN网络生成无噪声的图像,并且不需要预先给定噪声的分布数值。后续作者又挂出了该文章的升级版《Blur, Noise, and Compression Robust Generative Adversarial Networks》(arxiv.org/pdf/2003.0784)
6、PULSE: Self-Supervised Photo Upsampling via Latent Space Exploration of Generative Models
这篇文章是Duke大学的文章,与第二篇文章相同,同样是实现不同domain图像的重构,我看了一下,可能没懂。我感觉作者认为噪声分布能够重构出其他domain的图像。latent code对应的一个超球面上分布,基于梯度的方法无法实现在球面的上优化,而是使得latent code向球心运动,所以为了重构出其他domain的数据,需要一些技巧在球面上移动latent code。
7、A Characteristic Function Approach to Deep Implicit Generative Modeling
该文章类似于WGAN-GP,讲的是GAN的基础架构,。
8、Your Local GAN: Designing Two Dimensional Local Attention Mechanisms for Generative Models
该文章讲的是一种稀疏的注意力机制,作者认为,不仅在GAN上,在其他注意力相关任务上也可以应用。
9、Semantic Pyramid for Image Generation
该文章讲利用训练好的分类等提取高层语义的网络,通过不同layer的加入融合,来控制生成图像。语义信心越low,则图像越和输入接近,否则和输入变化越大,只是保留相同的语义。
10、MSG-GAN: Multi-Scale Gradient GAN for Stable Image Synthesis
这篇文章和proGAN比较类似,不同的是proGAN是逐层渐进训练的,而该方法是每一层都约束,由于该文章比较早就挂出来了,网上讲解的有很多。这里便不做过多介绍。
11、From Patches to Pictures (PaQ-2-PiQ): Mapping the Perceptual Space of Picture Quality

严格来说,这并不是一篇GAN的文章。而是一种图像质量的评价方法,近年来已经有很多文章研究真实的感知损失,替代在一些情况下容易失效的L1和L2 Loss。而我们知道在GAN的训练中,除了GANloss之外,其他的Loss也同样重要,所以研究感知损失,也是和GAN息息相关的。
12、CNN-generated images are surprisingly easy to spot... for now
同样,该文章也不是GAN方法的文章。而是讲述如何区分真实的图像和GAN生成的图像。那么作为“强大的敌人”,如果将其引入到GAN的鉴别器中,应该对GAN质量的提高带来一定的帮助。
13、Face X-ray for More General Face Forgery Detection
这篇文章与第12篇属于相同的范畴,不做不过介绍,对GAN和真实图像区分感性的同学可以看看。
14、Watch your Up-Convolution: CNN Based Generative Deep Neural Networks are Failing to Reproduce Spectral Distributions
这篇文章是从频率的角度来讲GAN损失情况,也就是对真实图像和GAN生成的图像进行频谱分析,发现即便是styleGAN这种效果卓群的网络,在频域上依然与真实的图像存在差异,为此设计添加频率约束的生成网络,保证了生成图像的质量。
15、On Positive-Unlabeled Classification in GAN
该文章的主要思路是,鉴别器判断图像的质量而不是图像的real和fake,通过该方式提高生成图像的质量。
16、GAN Compression: Efficient Architectures for Interactive Conditional GANs
该文章讲述的是GAN的压缩方法,在保证GAN效果的同时,能够大大降低生成器的冗余,在pixel2pixel,cycleGAN等条件GAN网络上取得了显著的效果,压缩率超过了1/9。
17、BachGAN: High-Resolution Image Synthesis from Salient Object Layout
从布局生成图像的方法,相较于GauGAN从语义生成图像,该方法对于用户的输入要求更低,只需要给出几个boundingbox便可以生成图像。同样任务论文,arxiv也新挂出来一篇,感兴趣的可以看看arxiv.org/pdf/2003.1169。这个领域应该是一个月来越得到重视的GAN的子领域。
18、Controllable Person Image Synthesis with Attribute-Decomposed GAN
北大和字节跳动的文章,主要是描写人物的合成,从文章给出的图来看效果还是很好的,可以提取不同人的特征组合出一个新的人物来,实现控制一个人的姿势穿着等等。
19、Augmenting Colonoscopy using Extended and Directional CycleGAN for Lossy Image Translation
主要是cycleGAN在医学图像转换中的应用,但是文章提出的训练技巧在所有的cycleGAN相关任务中应该都能够有着较好的应用,对于使用cycleGAN的人还是值得一看的。
20、Adversarial Feature Hallucination Networks for Few-Shot Learning
利用条件WGAN实现特征的合成,进而实现分类的数据集扩增。
21、One-Shot Domain Adaptation For Face Generation
FAIR的文章,利用已经训练好的styleGAN网络,反向编辑latent code,再微调GAN网络。生成和单张target image具有相同分布图像,实现数据集扩增。该文章已经完成解析,详见

22、Semantically Mutil-modal Image Synthesis
华中科大的文章,利用语义生成图像,GroupDNet—— Group Decreasing Network。网络非常规地采用群卷积,并修改卷积的组数以减少解码器中的数量,从而大大提高了训练效果。
23、StyleRig: Rigging StyleGAN for 3D Control over Portrait Images
将styleGAN和3DMM结合在一起,优势互补,利用训练好的styleGAN在自监督模式下,学习3DMM输入的特性,实现特定属性的人脸编辑。
24、Guided Variational Autoencoder for Disentanglement Learning
这不是一篇GAN的文章,而是VAE。但是GAN和VAE并不分家,所以VAE的文章也一并整理了。一种可以实现解纠缠的VAE算法,在表示学习和元学习中都有着应用价值。
25、S2A: Wasserstein GAN with Spatio-Spectral Laplacian Attention for Multi-Spectral Band Synthesis
该文章主要针对卫星图的合成问题,通过时空拉普拉斯频谱注意力机制进行合成。
26、PatchVAE: Learning Local Latent Codes for Recognition
这篇文章是一篇VAE的文章,主要贡献点在于提出了一种基于patch的无监督VAE方法,并且利用 bottleneck formulation实现了中间层的表示。
27、Attentive Normalization for Conditional Image Generation
相较于传统GAN方法,进行了远程依赖关系建模。并且通过注意力归一化(AN)实现远程依赖关系, 具体地,基于输入特征图的内部语义相似度将输入特征图软划分成几个区域,并分别进行归一化。它通过语义对应关系增强了遥远区域之间的一致性。与自我注意力GAN相比,注意力归一化不需要测量所有位置的相关性,因此可以直接应用于大型特征图而无需太多计算负担。
PS:今年已经有好几篇关于attention相关的GAN文章了,这个方向值得研究一下,近期会选择一篇尽心解析。
28、Semantic Image Manipulation Using Scene Graphs
图像到语义图再到图像得到处理过程,利用GAN对图像进行编辑。
29、Cross-domain Correspondence Learning for Exemplar-based Image Translation
一种图像生成的框架,该框架从给定示例图像的不同域(例如语义分割蒙版或边缘贴图或姿势关键点)的输入中合成出逼真的图像,该合成的图像与示例图像具有相似的风格(文理等)。
30、MixNMatch: Multifactor Disentanglement and Encoding for Conditional Image Generation
在FineGAN基础上,通过最小监督,实现输入特征的解纠缠,融合多种输入生成目标图像,可以用在sketch2color,cartoon2img和img2gif应用程序。
31、MineGAN: effective knowledge transfer from GANs to target domains with few images
提出了一种知识迁移的生成方法,训练一个 identifies网络,在多个domain中训练选择最接近target domain的部分。实现在target domain的良好泛化。
32、Normalizing Flows with Multi-Scale Autoregressive Priors
通过多尺度自回归先验(mAR)在潜在空间中引入基于通道的依赖关系,从而提高了基于流的模型的表示能力。对于具有分离式耦合流动层(mAR-SCF)的模型,mAR先验技术可以更好地捕获复杂多峰数据中的依存关系,提高生成网络的效果。
33、Semi-supervised Learning for Few-shot Image-to-Image Translation
半监督方法,应用了循环一致性约束,通过噪声伪标签实现image的domain transfer,原域和目标域的数据都需求较少。
34、Panoptic-based Image Synthesis
之前的条件图像合成算法主要依赖于语义图,在多个示例互相遮挡的情况下容易失败。本文提出了一种全景感知图像合成网络,在卷积和上采样层中有效地使用了全景图,以生成以全景图为条件的高保真度和真实感图像,该全景图将语义和实例信息统一起来。该方法在mIoU和detAP的度量标准方面也优于以前的最新方法。
35、Adversarial Latent Autoencoders
无监督方式的自动编码网络,通过编解码的方式生成特定属性。可以利用GAN方式进行训练。设计了两种自动编码器:一种基于MLP编码器,另一种基于StyleGAN生成器,将其称为StyleALAE。并且验证两种体系结构的解缠结特性。显示,StyleALAE不仅可以生成质量与StyleGAN相当的1024x1024人脸图像,而且在相同的分辨率下还可以基于真实图像生成人脸重建和操作。
36、Disentangled and Controllable Face Image Generation via 3D Imitative-Contrastive Learning
联合3D和对抗网络的精确人脸属性控制方法。文章中展示的效果还是很不错的,值得一读。
37、Deep 3D Portrait from a Single Image
与36相同团队的文章,由单张图非监督的人头像3D重构。
38、Neural Head Reenactment with Latent Pose Descriptors
也是人脸属性控制的方法,在姿势和表情上都能够有很好的效果。
专知便捷查看
便捷下载,请关注专知公众号(点击上方蓝色专知关注)
后台回复“GAN20” 可以获取密歇根大学28页最新《GANs生成式对抗网络综述:算法、理论与应用》最新论文-论文专知下载链接






