如何使用知识图谱增强信息检索模型?

©PaperWeekly 原创 · 作者|刘布楼
学校|清华大学博士生
研究方向|信息检索
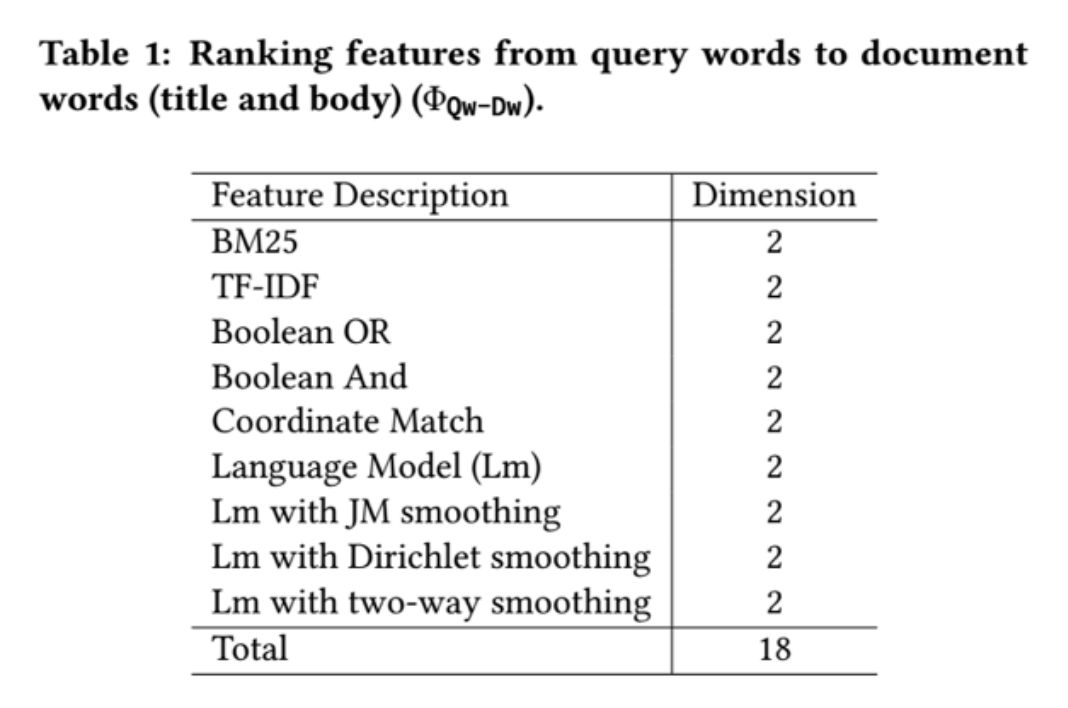
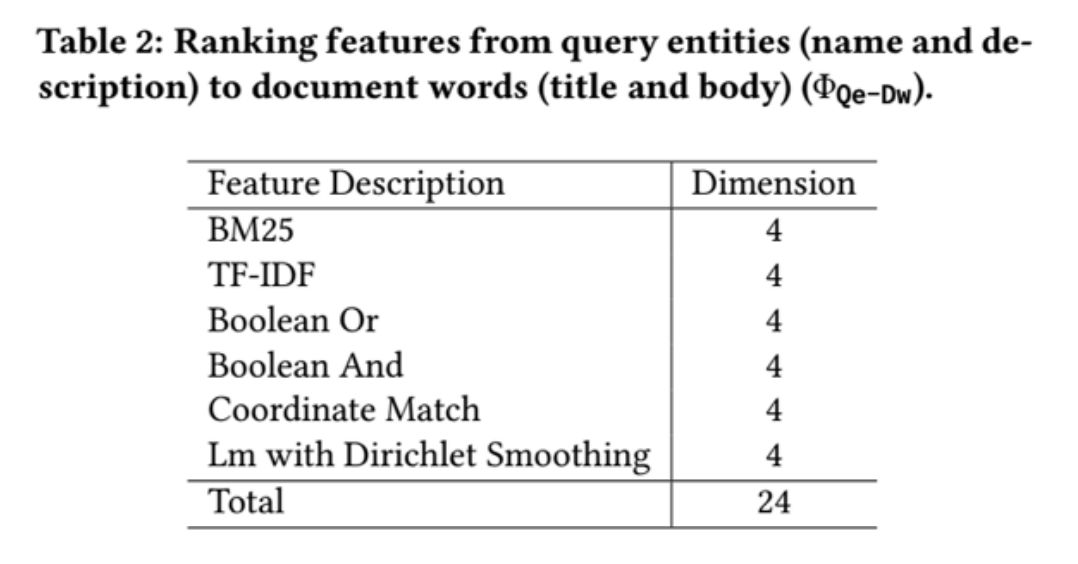
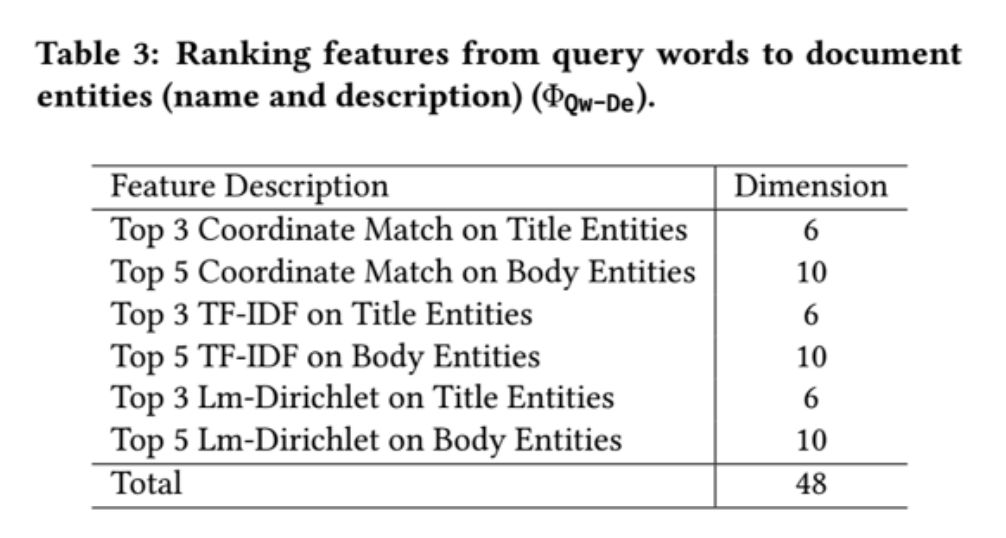
传统的信息检索模型中,文本通常使用词袋模型表示。该方法有两个较为明显的缺陷:1)只能通过 TF-IDF 等相关信号判断查询-文本相关性;2)模型没有深入理解查询和文本的语义信息,而是更多地依赖于特征工程的方法。
近年来流行的方法主要可以分为两大类:1)通过知识图谱引入背景信息和先验知识;2)通过深度学习技术从大规模的数据中学到信息的隐性表示。
本文主要针对第一种思路进行探讨:通过引入知识图谱中的实体以及实体的描述信息丰富语义,从而优化信息检索模型。知识图谱中的实体可以是一些概念、人名地名等等,这些实体排除介词的干扰,赋予查询和文本更简洁的表示,并引入知识图谱中的语义信息,增强信息检索模型的语义理解能力。
本文内容将介绍五篇通过知识图谱优化信息检索模型的论文,分别是:1)基于知识图谱的学术检索模型;2)词袋和实体的结合表示优化排序;3)结合查询实体链接特征优化排序;4)基于核方法的实体重要性建模和排序优化;5)基于实体的神经信息检索模型。

基于知识图谱的学术检索模型

当前学术检索系统面临的主要挑战是检索系统无法理解学术概念而限制了学术检索的效果。例如“Softmax Categorization”和“Softmax Classification”表达的含义相同,但是词袋模型无法将其归为一类;而“Dynamic programming segmentation”在图像处理领域中表示语义分割,在自然语言处理领域中表示分词,但是词袋模型无法区分这两种概念。
本提出的方法是借助知识图谱,在实体空间中对查询和文本进行表示,然后通过他们的知识图谱嵌入表示建立语义连接,从而优化查询的效果。
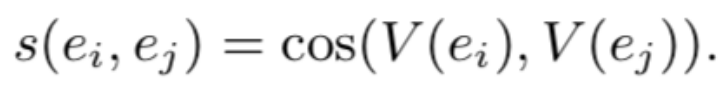
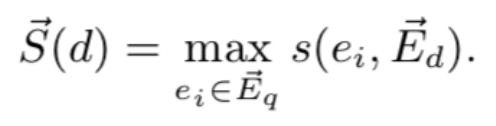
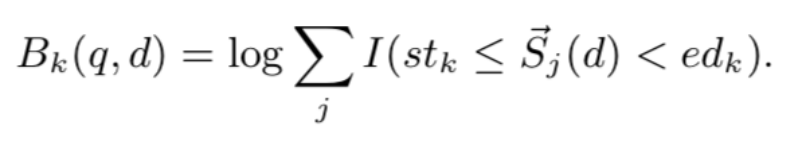
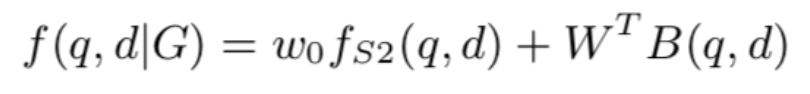
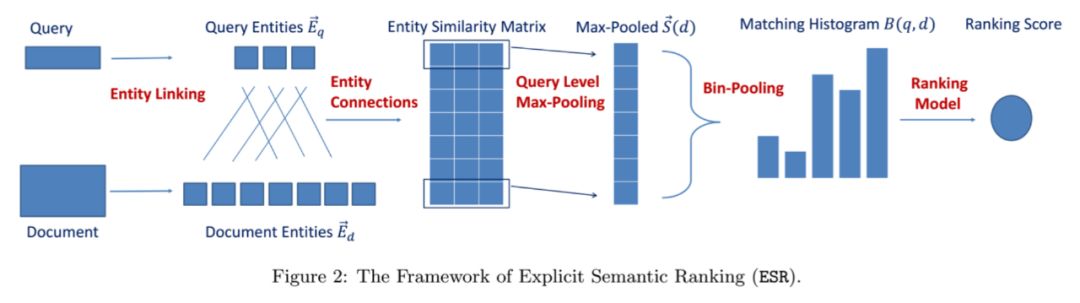



注意力机制聚合相关性信息 (attention features):
针对于查询实体可能不准确的问题,该方法针对交互特征使用注意力机制生成注意力特征(即各个特征的权重),该注意力特征主要从歧义特征和查询重要性两个方面生成,具体表示如下:
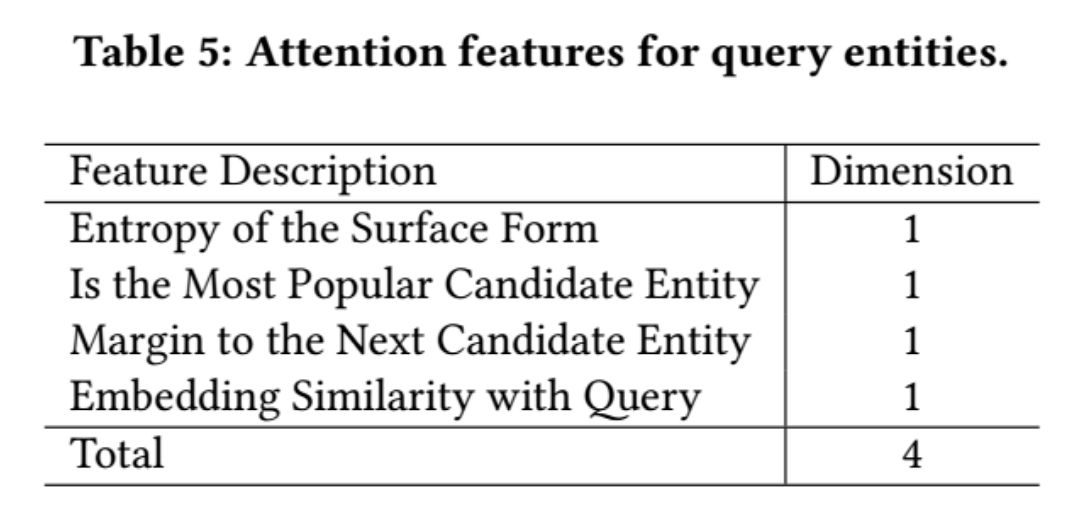
因此对查询词交互特征和查询实体相关特征进行区分,查询词注意力分数设置为 1,查询实体注意力分数根据注意力特征获得,具体表示如下:
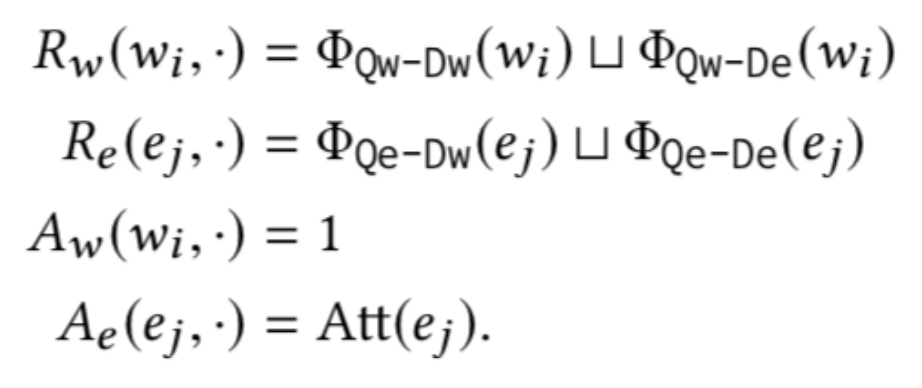
然后使用一维 CNN 聚合交互特征和注意力特征,并将二者相乘得到最后的相关性分数:
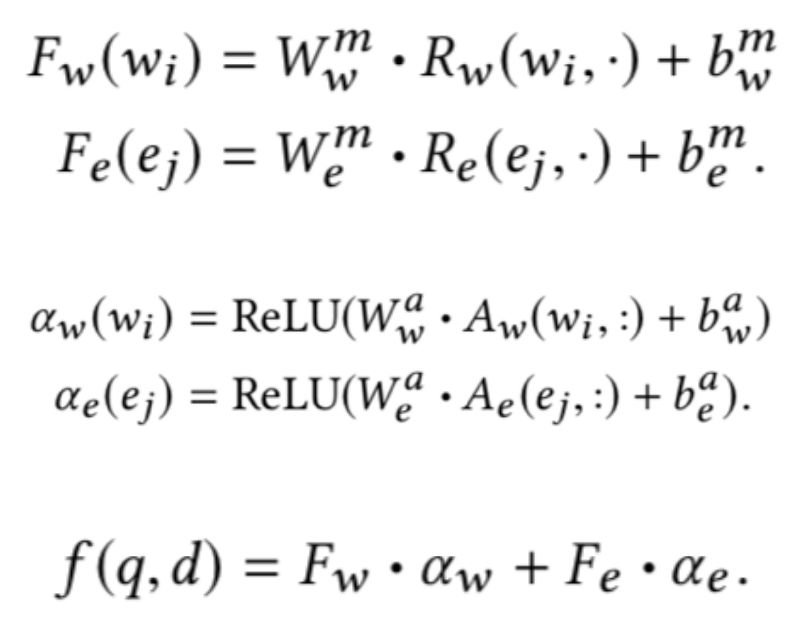
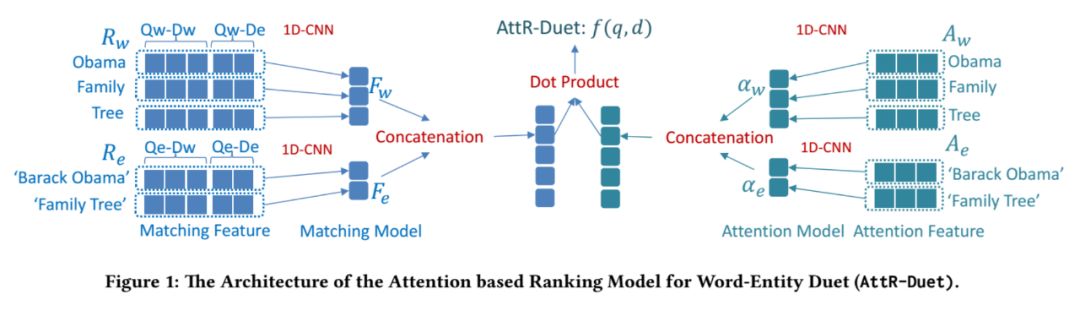


在原有的方法构建排序特征的过程中,实体链接往往只是一个预处理的步骤,而没有 将链接的信息作为特征加入到排序模型里。
本文提出了一种将查询实体链接和基于实体的文本排序模型结合起来构造语义相似度排序模型的办法。采用的方法是利用获取 surface form (spotting) 的信息和链接 (linking) 信息表示候选实体的重要性,从而通过链接实体的过程优化文本排序的特征。
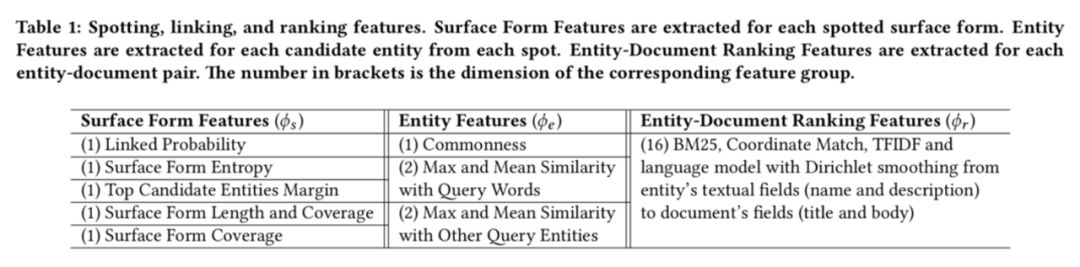
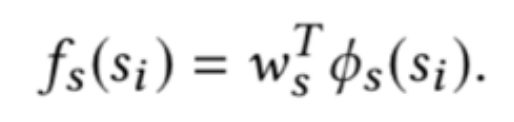
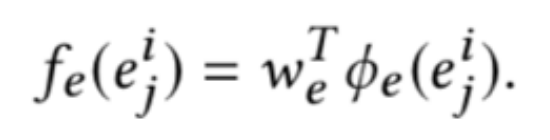
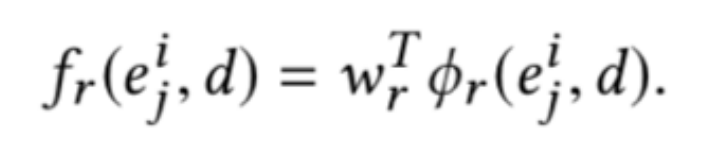
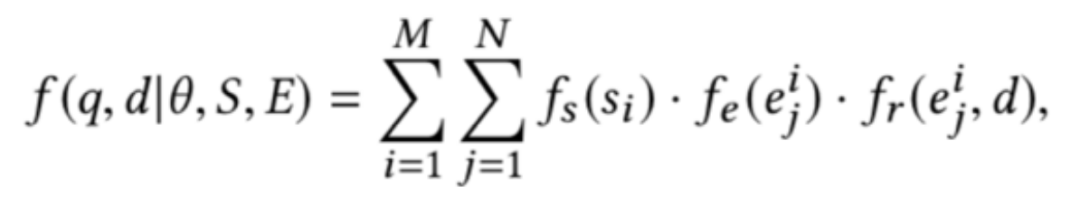


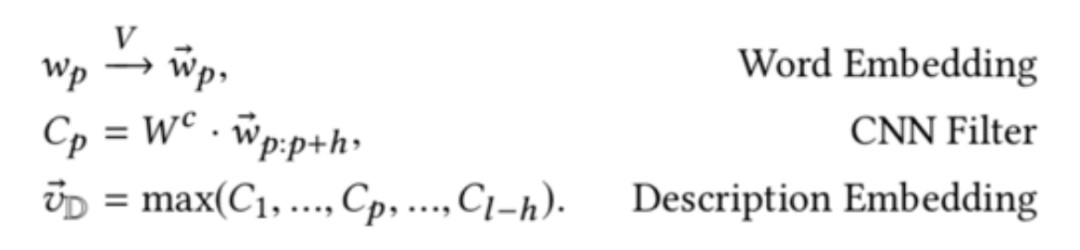

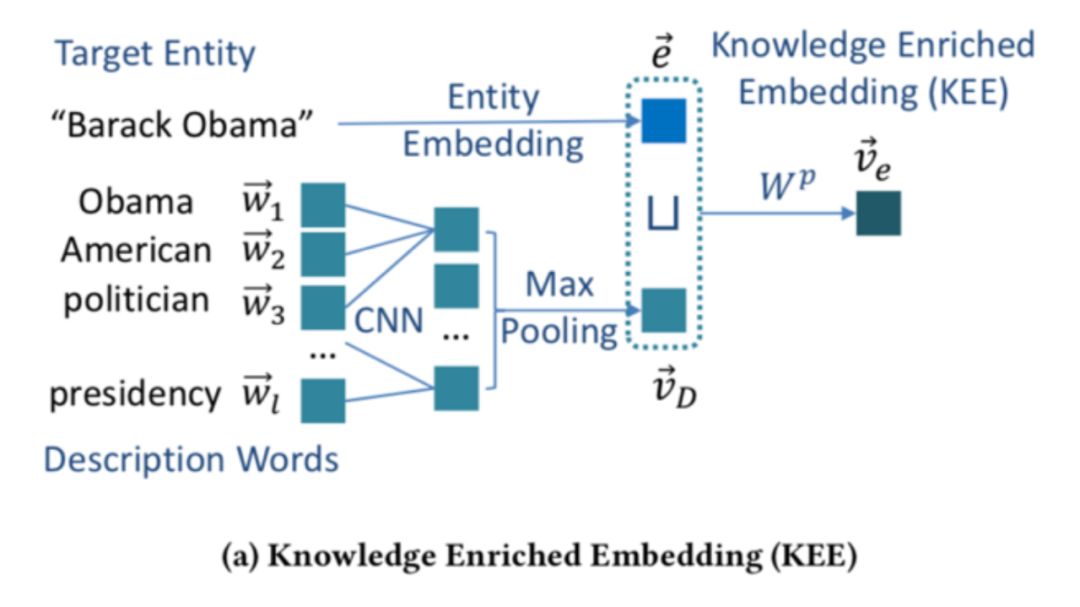
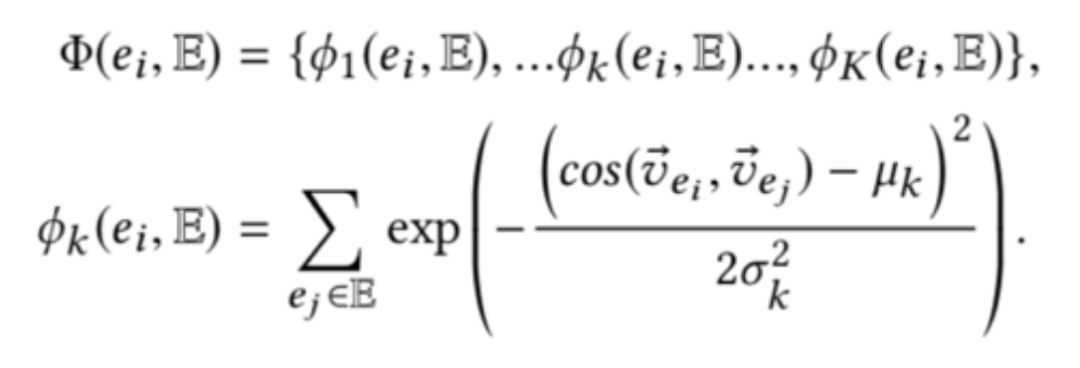
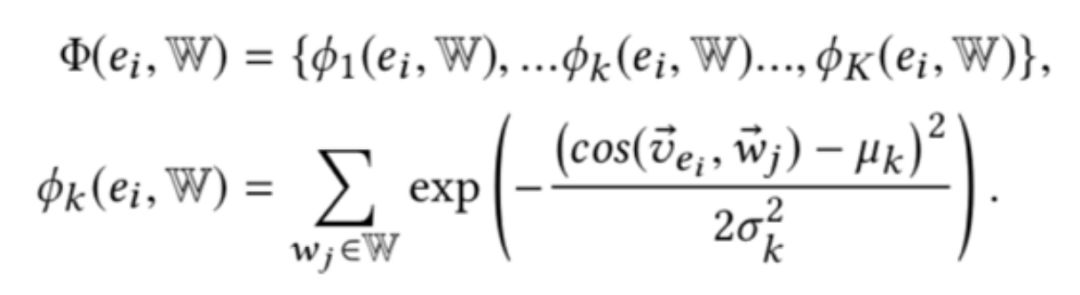
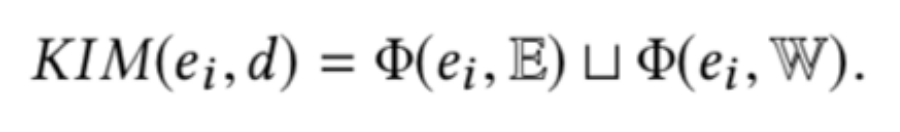
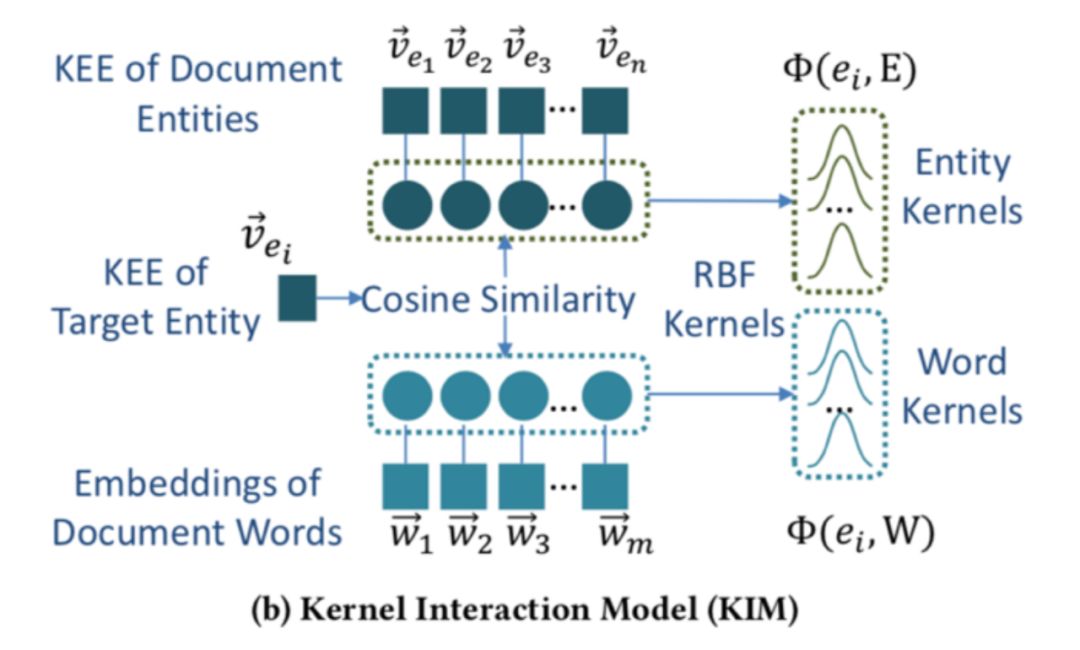
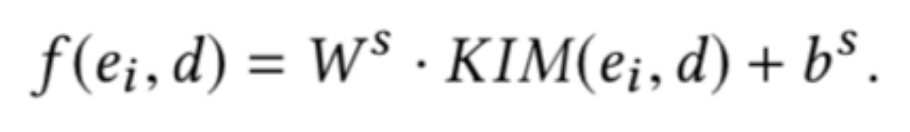
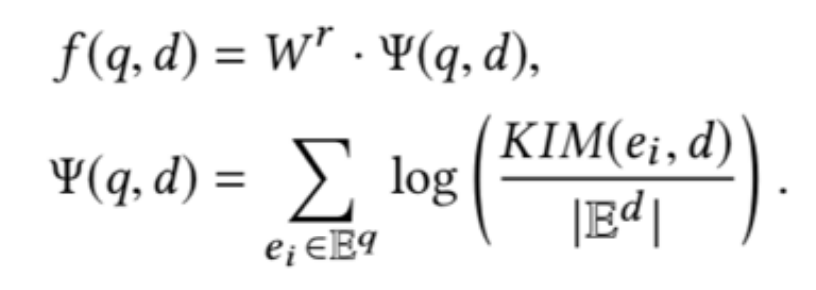
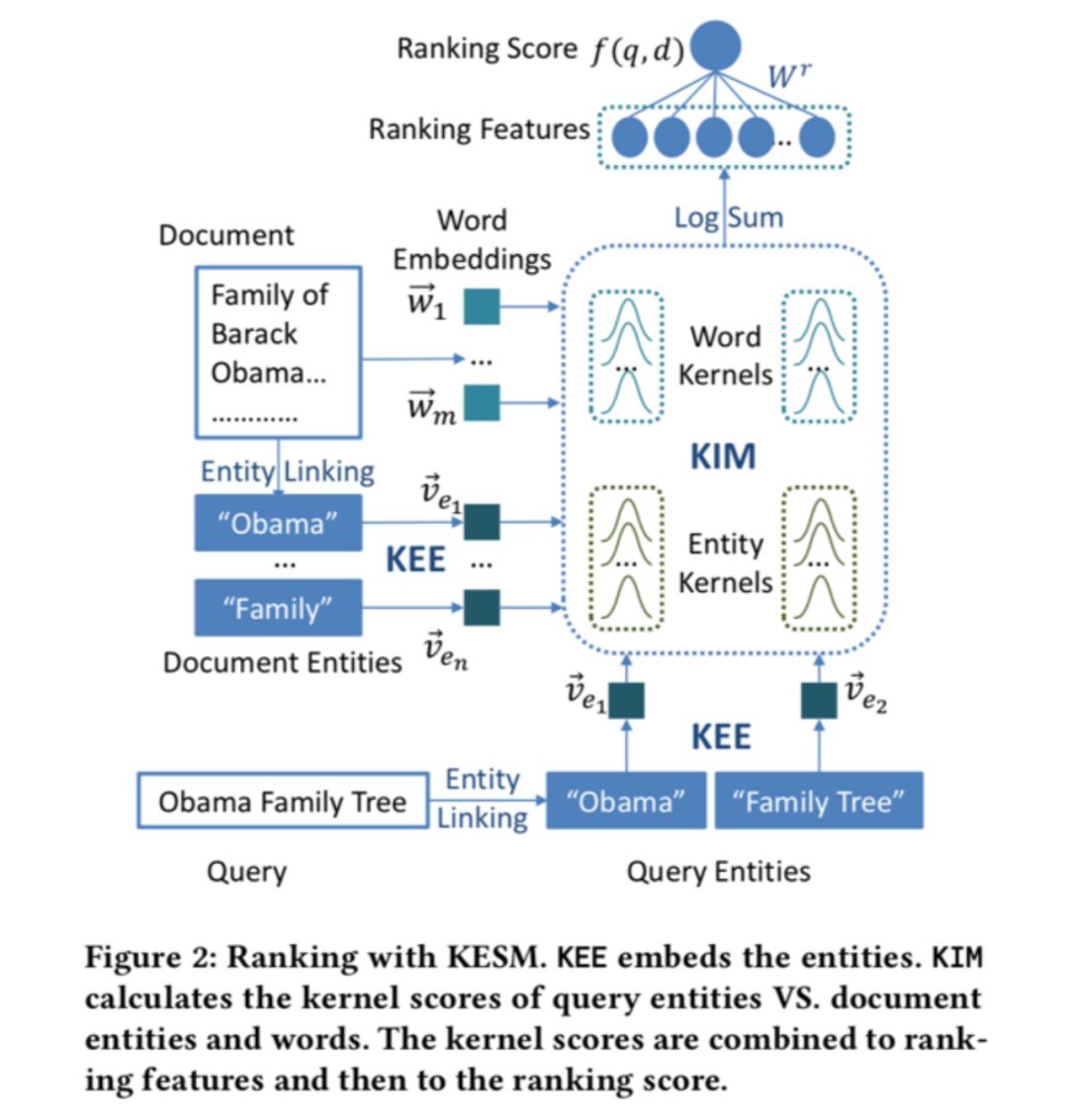


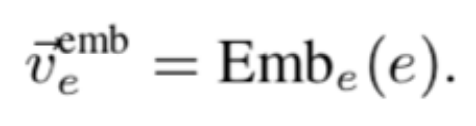
描述向量需要将实体描述的词向量通过卷积神经网络的计算得到:
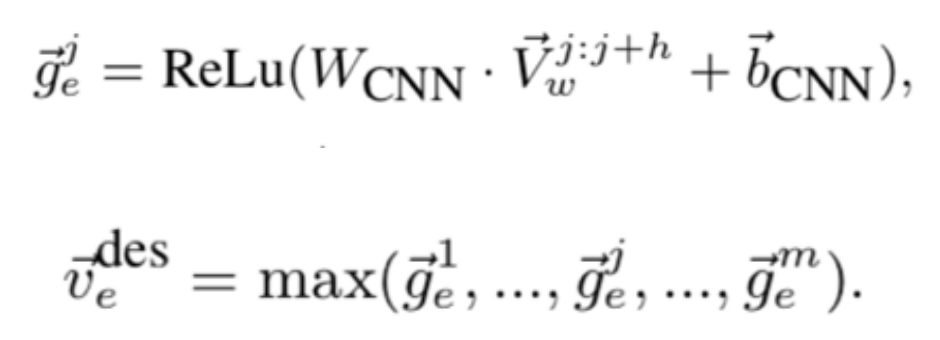
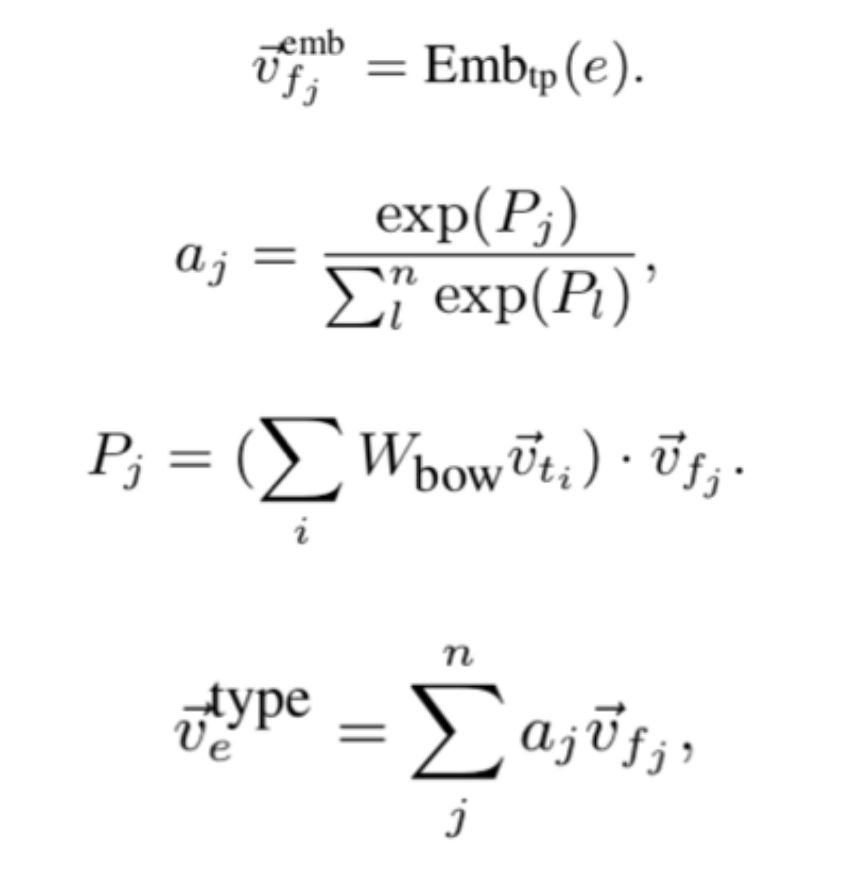
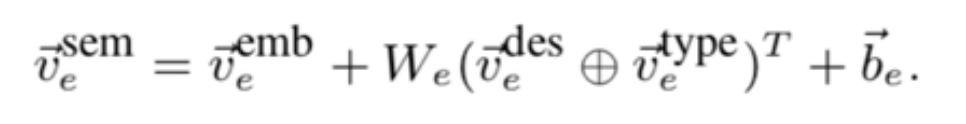
最后计算四个相关信号矩阵:查询词-文本词矩阵、查询实体-文本词矩阵、查询词-文本实体矩阵、查询实体-文本实体矩阵,并拼接得到排序特征:
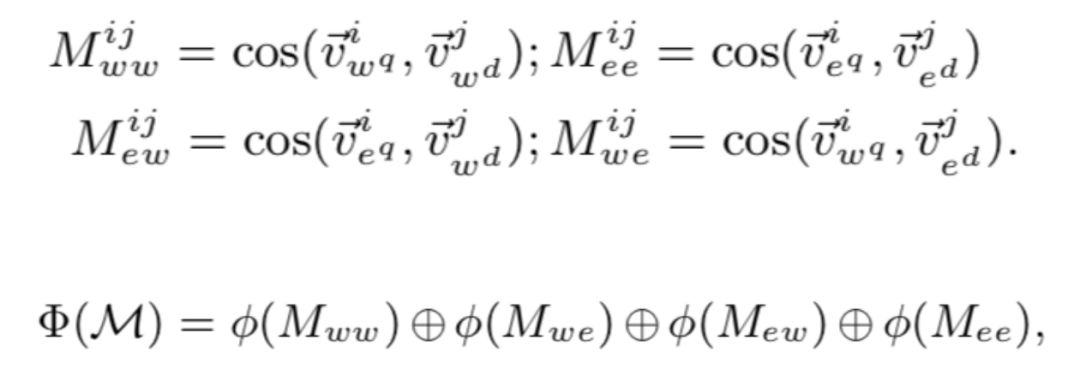
神经信息检索模型聚合相关信号:
神经信息检索模型 K-NRM 通过核池化函数抽取不同范围内的相关信号,将每个相似度矩阵输入可以得到排序特征:
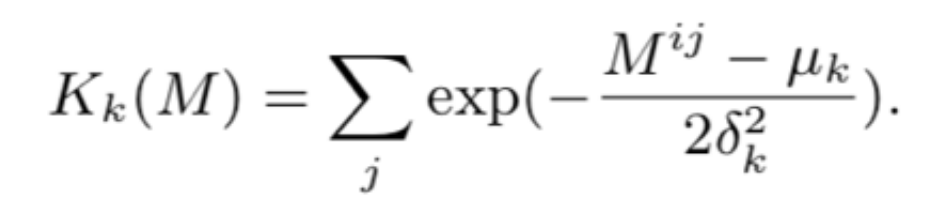
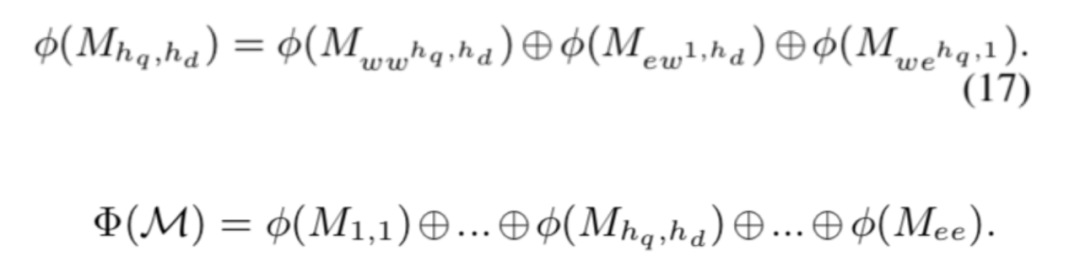
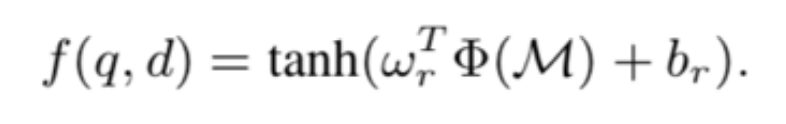
创新和发现
EDRM 模型具有较好的泛化能力,相较于原来的神经信息检索模型有更好的排序效果。
在信息较难提取的情况(如查询文本长度较短)下:
EDRM 相较于原来的神经信息检索模型有较大突破,这说明该模型可以在信息较少的情况下结合知识图谱中的信息提高查询的效果。
通过知识图谱引入背景信息和先验知识已经在信息检索模型中取得了较好的效果,证明实体语义对于理解查询意图、优化排序结果有很大的帮助,未来的研究可以从引入知识图谱的关系入手,建立更丰富、更智能化的知识指导式信息检索模型,而不仅仅局限于知识图谱中的实体语义信息。
参考文献

点击以下标题查看更多往期内容:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢?答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。






