使用Modin加速Pandas

我最近偶然发现了一个叫做Modin [1]的小型库,它声称可以让pandas运行的更快。他们用来描述这个项目的其中一句话是:
"通过更改一行代码来加速你的pandas工作流"
听起来很有趣,如果是真的话,那就意义重大了。
使用modin只需要导入modin来代替pandas,并且也不需要更改你的现有代码。
一个警告 —— modin目前使用panda 0.20.3(当使用 pip install modin 来安装modin时,至少需要安装panda 0.20)。如果你正在使用最新版本的pandas,并且需要以前版本中不存在的新功能,那么你可能需要检查一下modin—或者尝试让它与最新版本的pandas一起工作(我还没有这样做)。
安装modin:

使用modin:

就是这样。你只需要使用 import modin.pandas as pd 而不是 import pandas as pd,然后你就可以获得额外的速度优势。
根据文档,modin利用了现代机器上的多核技术,而pandas没有。从他们的网站可以看到:
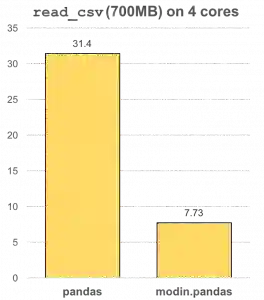
Modin提供的一个Read CSV基准
在pandas中,当你做任何类型的计算的时候你每次只能使用一个核心。但是使用Modin,你可以使用机器上的所有CPU内核。即使在read_csv中,通过有效地在整个机器上分布工作,我们也看到了巨大的成效。
我们来试一试,看看它是如何工作的。
在这个测试中,我将尝试他们的read_csv方法,因为这是他们所强调的亮点。对于这个测试,我有一个105MB的csv文件。让我们给pandas 和 modin计时,看看它们是如何工作的。
我们先从pandas开始。
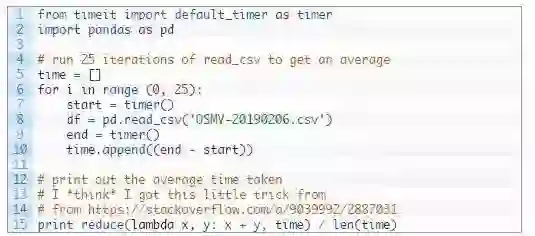
使用pandas,读取一个105MB csv文件平均需要1.26秒。
现在,我们来看一下modin。
在继续之前,我应该和大家分享一下,除了执行 pip install modin 之外,我还需要执行一些额外的步骤才能让modin正常工作。我还必须安装typing和dask。

使用与上面完全相同的代码(除了导入modin的一点小更改—— import modin.pandas as pd)。
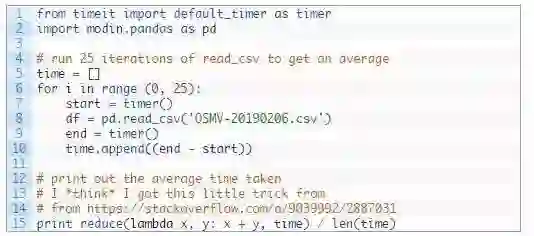
使用modin时,读取一个105MB csv文件平均需要0.96秒。
在这个示例中,使用modin,我可以从读取这个105MB csv文件的平均读取时间中节省0.3秒。这可能看起来不是很多时间,但是节省了大约27%。想象一下,如果你有5000个大小相似的csv文件要读取,这平均可以节省1500秒的时间,仅仅在读取文件上就可以节省25分钟的时间。
Modin使用Ray [2]来加速pandas,所以如果你使用Ray的一些设置,可能会节省更多的时间。
我将在以后的一些项目中更多的使用modin来提高效率。好好看一下它,然后告诉我你的想法。
相关链接:
[1]——https://github.com/modin-project/modin
[2]——https://github.com/ray-project/ray/
英文原文:https://pythondata.com/quick-tip-speed-up-pandas-using-modin/
译者:一瞬


