ECCV 2020 | 北大提出ACL-GAN:基于对抗一致性的非匹配图像转换
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

本文转载自:北京大学前沿计算研究中心
关键词:GAN; Deep Learning


导读
本文是计算机视觉领域顶级会议 ECCV 2020 入选论文《Unpaired Image-to-Image Translation using Adversarial Consistency Loss》的解读。
声明:本文首发于知乎,经作者授权标注“原创”发表于此。转载需标注首发出处。
知乎原文:https://zhuanlan.zhihu.com/p/156092551
论文地址:https://arxiv.org/abs/2003.04858


01
问题引入
在图像处理、图形学和计算机视觉中有大量问题是将一个图片域的图片转换到另一个图片域,比如前一阵刷屏朋友圈的换脸应用。这种问题可以统称为图像到图像转换(image-to-image translation)[1]。目前基于深度学习,特别是生成对抗网络(generative adversarial networks, GANs)[2] 的方法在图像到图像转换中取得了很大的进步。
然而,目前的主流方法有若干局限性,导致不能支持很多应用。其中最大的一个局限性是目前的主流方法基于循环一致性损失(cycle consistency loss,以下简称cycle loss)[2]。Cycle loss 缺陷的主要原因在于其要求转换回来的图片要和原图完全一致(图2右侧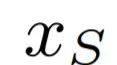
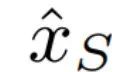

图1. 眼镜去除的例子
今天介绍一篇 ECCV 2020 上最新的工作 ACL-GAN,提出从数据分布角度约束不可逆图像转换过程,主要解决了以下问题:
规避了 cycle loss 的缺点;
转换后图像与原图具有相关性;
对于同一张输入,可以输出合理高质量的多模态输出;
利用较少的网络参数,降低了训练和使用成本。
该方法生成的图片令人难辨真假,而且在量化评价上,也超过现有方法,成为 state-of-the-art。
02
方法简介
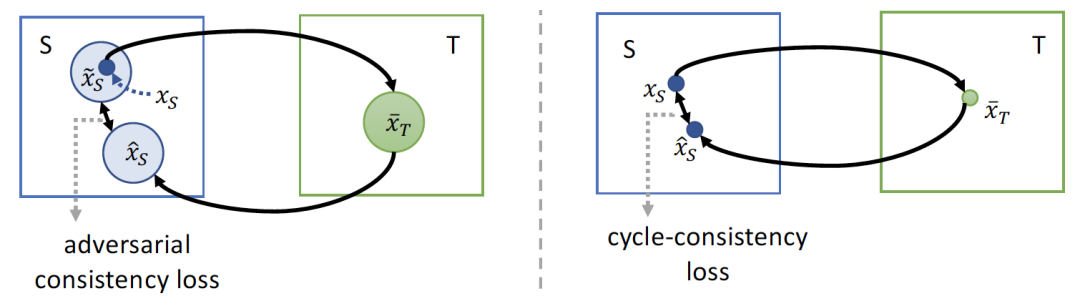
图2. ACL loss(左)和cycle loss(右)的对比
ACL-GAN 为了规避生成器“作弊”留下眼镜痕迹,并不限制点到点的相同,而是将各种眼镜统统纳入怀中。为了允许不同细节的图片都被认为和原图相同,该方法将原图 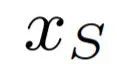
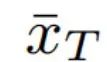
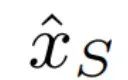
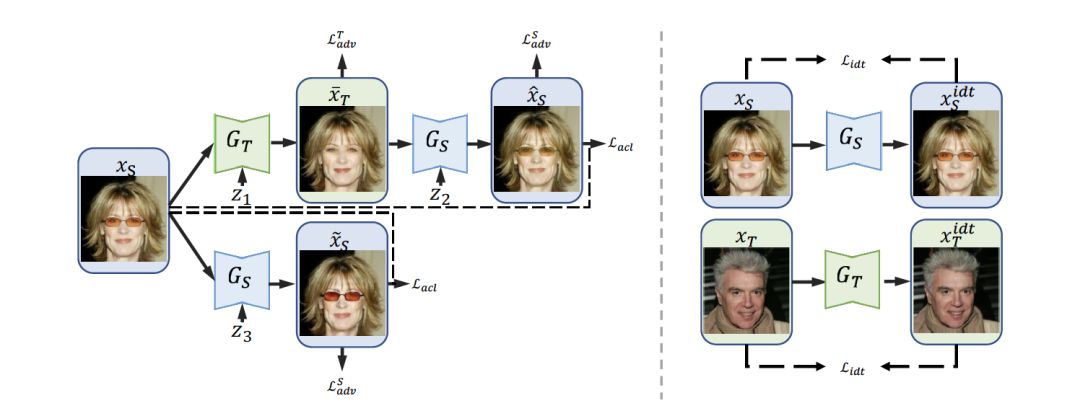
图3. ACL-GAN的模型框架
同时,图像转换任务中有些信息是我们希望完全不变的(如背景)。该方法采用注意力机制(attention mechanism),令生成器同时生成注意力遮罩,区分前景和背景(0表示背景,1表示前景)。但现有的方法往往不限制遮罩的形态,本文作者提出 Bounded focus mask,对注意力遮罩增加两种限制:1)每一个像素趋向于0/1,即明显划分前景和背景;2)前景的面积根据不同任务限制在特定范围。Bounded focus mask 可以帮助生成器集中精力在需要修改的区域,从而提高生成效果。
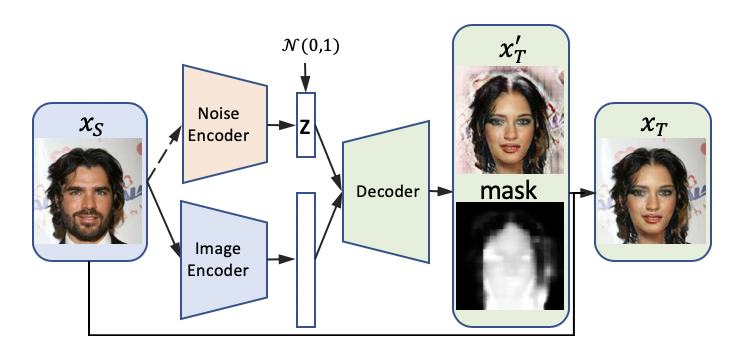
图4. Bounded focus mask示例
03
实验结果
为说明每一部分loss的有效性,该工作进行了消融实验,结果如下(量化测试见原论文):

图5. 消融实验结果
其中ACL-GAN是有所有loss的模型;ACL-A是去掉ACL loss;ACL-I是去掉identity loss;ACL-M是去掉mask loss。
虽然每一种模型都成功实现了性别转换,而且结果已经可以以假乱真,但仔细比较,我们仍然可以发现不同约束的作用,增强了该方法的可解释性。该实验结果符合分析:ACL-A 的结果虽然成功转换,但生成图片和原图之间关联性不强,如发色、肤色、周围、牙齿等发生明显变化;ACL-I 的结果视觉上差距不大,但量化指标略低于 ACL-GAN;ACL-M 的背景明显发生变化,图片质量也略低于 ACL-GAN,原因是 mask 可以帮助生成器将注意力集中在前景上。
为了验证该方法在不同任务上的表现,作者在眼镜去除、性别转换和自拍到动漫转换三个任务上,与多个现有方法进行了比较,这三个方法对生成器的要求侧重各不相同,通过结果很明显可以看出来生成器完美胜任了这三个任务,而且规避了 cycle loss 的缺点。

图6. 眼镜去除任务比较
眼镜去除任务主要有两大难点:1)眼镜外的区域要求完全保留不变;2)眼镜隐藏的部分信息要合理的补充出来,如太阳镜完全遮住眼睛。可以看到,ACL-GAN 不仅成功完成上述任务,而且没有留下任何“作弊”的痕迹。

图7. 性别转换任务比较
性别转换任务具有公认的三大难点:1)多模态变化,对于同一张输入,可以有多种输出对应;2)性别转换不仅要求改变颜色和纹理,还需要改变形状(如头发);3)配对的数据无法获得。即使面对这些难点,ACL-GAN 仍然很好的完成了该任务,无论是头发、胡须的变化,还是五官特征、背景的保留,都优于现有方法。

图8. 自拍到动漫转换任务比较
自拍到动漫转换任务改变幅度最大,整张图片风格和主题都需要发生较大改变。ACL-GAN 生成的结果自然,而且符合动漫人物的特征(如大眼睛、小嘴巴等) ,而且也与原图有更大的相关性。
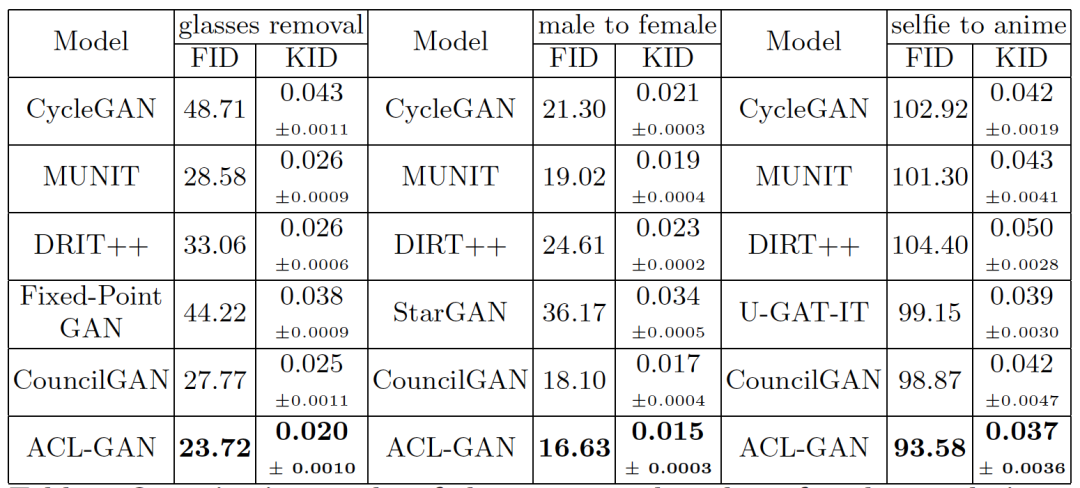
图9. 多种方法在不同任务上量化比较
为了进一步证明该方法的有效性,作者采用 FID、KID 指标量化评价三个任务上不同方法的表现,ACL-GAN都取得了最优的成绩,大部分结果都远远优于采用 cycle loss 的方法。

除此以外,该方法的网络参数较小,与大部分已有方法相当。ACL-GAN 的参数数量甚至不到表现相近方法(CouncilGAN、U-GAT-IT)的一半。具有较小的训练和存储开销。
04
结语
不可逆的图像转换任务具有广泛的应用场景,也是计算机视觉中重要的任务之一。本文从数据分布的角度约束对抗生成网络,在多种不同场景上达到 state-of-the-art,体现其有效性,为图像转换提供了新思路。
参考文献
[1] Pix2Pix: Image-to-Image Translation with Conditional Adversarial Networks. Phillip Isola, Jun-Yan Zhu, Tinghui Zhou, Alexei A. Efros. CVPR 2017.
[2] GAN: Generative Adversarial Nets. Ian Goodfellow, Jean Pouget-Abadie, Mehdi Mirza, Bing Xu, David Warde-Farley, Sherjil Ozair, Aaron Courville, Yoshua Bengio. NIPS 2014.
[3] CycleGAN: Unpaired Image-to-Image Translation using Cycle-Consistent Adversarial Networks. Jun-Yan Zhu, Taesung Park, Phillip Isola, Alexei A. Efros. ICCV 2017.

图文 | 赵怡浩
Hyperplane Lab
下载
在CVer公众号后台回复:ECCV2020,即可ECCV 2020代码开源的论文合集
重磅!CVer-论文写作与投稿交流群成立
扫码添加CVer助手,可申请加入CVer-论文写作与投稿 微信交流群,目前已满2000+人,旨在交流顶会(CVPR/ICCV/ECCV/ICML/ICLR/AAAI等)、顶刊(IJCV/TPAMI等)、SCI、EI等写作与投稿事宜。
同时也可申请加入CVer大群和细分方向技术群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如论文写作+上海+上交+卡卡),根据格式备注,可更快被通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
点赞和在看!让更多CVer看见



