清华提出首个退化可感知的展开式Transformer|NeurIPS 2022

来源:新智元
本文为约1898字,建议阅读3分钟
本文介绍了
NeurIPS 2022 关于 Spectral Compressive Imaging (SCI)重建的工作。


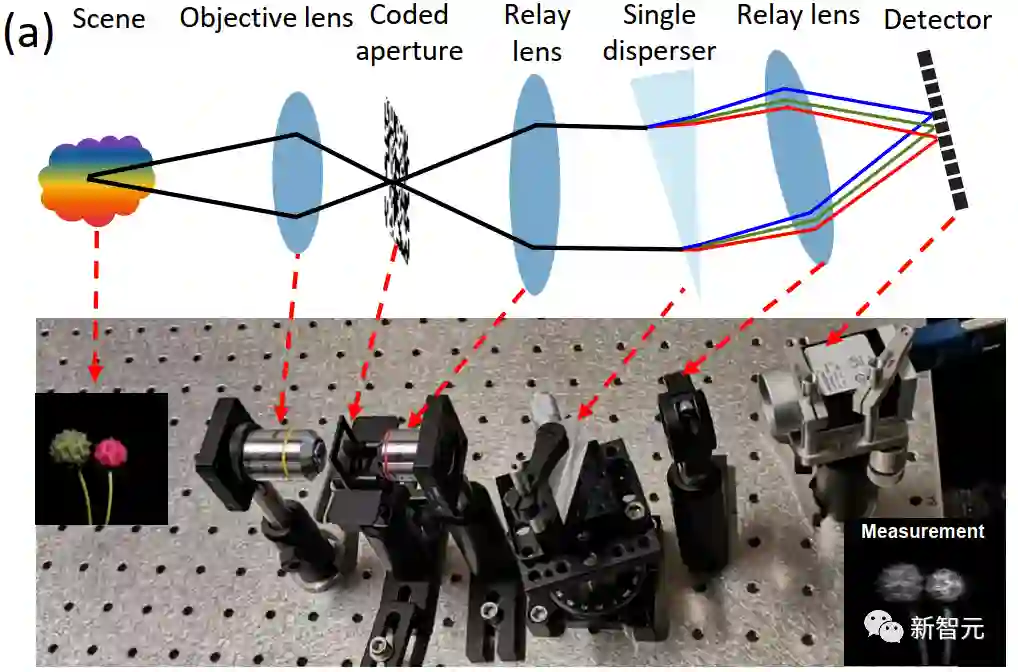 图1 单曝光快照压缩成像光学系统
图1 单曝光快照压缩成像光学系统
端到端的方法直接采用一个深度学习模型,去拟合一个从 2D 快照压缩估计图到 3D 高光谱数据的映射。这种方法比较暴力,确实可解释性。
深度展开式方法将神经网络嵌入到最大后验概率(Maximum A Posteriori,MAP)模型中来迭代地重建出高光谱图像,能更好地和光学硬件系统适配。因此,本文主要研究深度展开式算法。当前这些方法主要有两大问题:
当前的深度展开式框架大都没有从 CASSI 中估计出信息参数用于引导后续的迭代,而是直接简单地将这些所需要的参数设置为常数或者可学习参数。这就导致后续的迭代学习缺乏蕴含 CASSI 退化模式和病态度信息指导。
-
当前的Transformer 中全局的 Transformer 计算复杂度与输入的图像尺寸的平方成正比,导致其计算开销非常大。而局部 Transformer 的感受野又受限于位置固定的小窗口当中,一些高度相关的 token 之间无法match。
CASSI 压缩退化的数学模型
退化可感知的深度展开框架
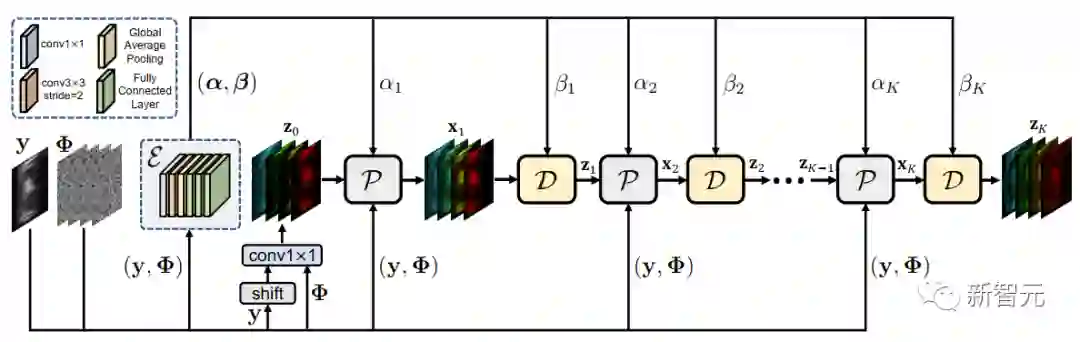
图2 退化可感知的深度展开式数学框架
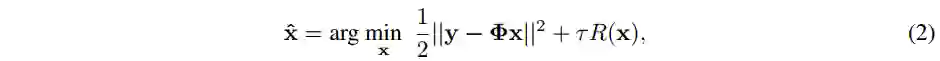


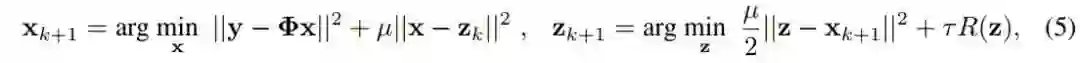
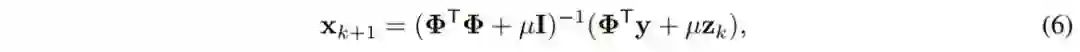
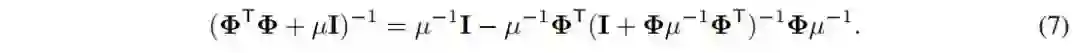
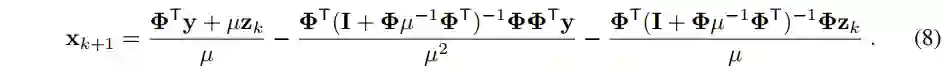
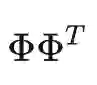 是一个对角矩阵,定义
是一个对角矩阵,定义
 ,由此可得:
,由此可得:
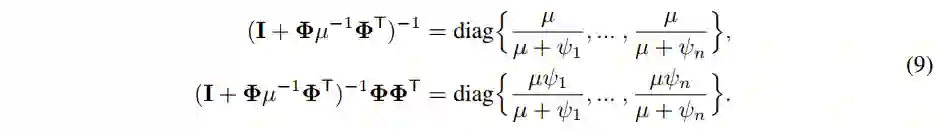
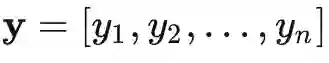 且
且
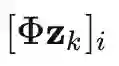 表示
表示
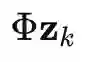 的第 i 个元素,将公式(9)代入公式(8),可得:
的第 i 个元素,将公式(9)代入公式(8),可得:
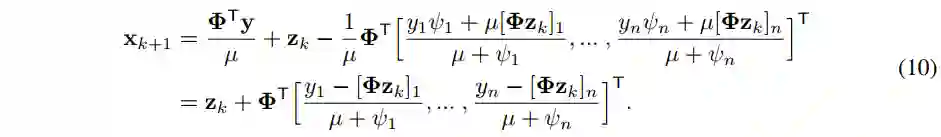
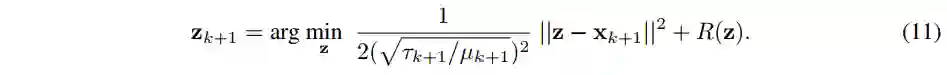
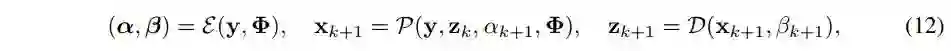
半交互式 Transformer
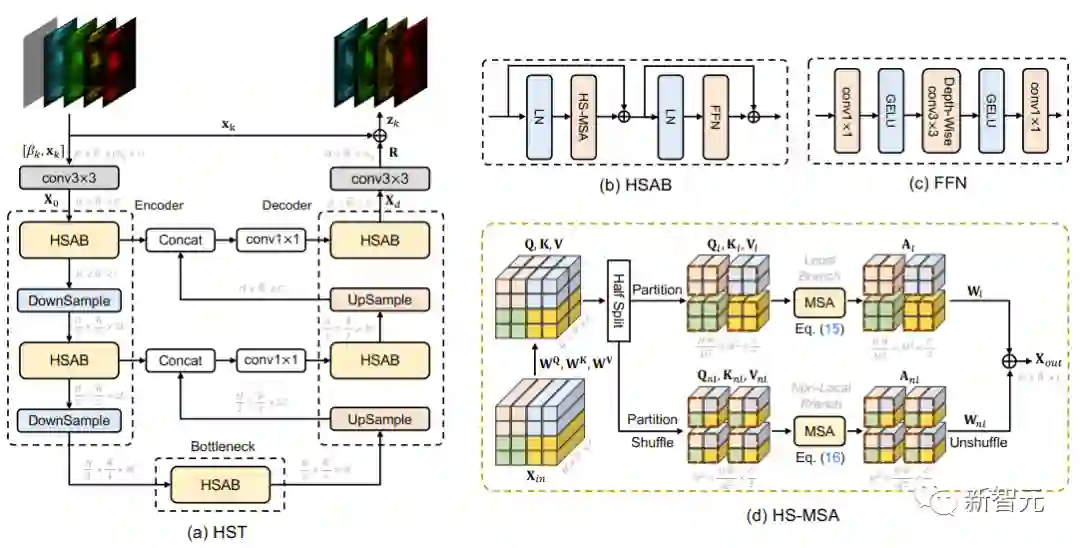
网络整体结构
Half-Shuffle Multi-head Self-Attention
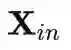 线性映射为:
线性映射为:
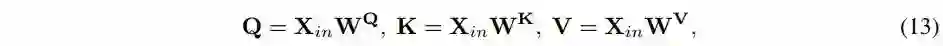
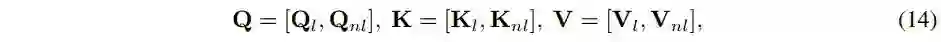
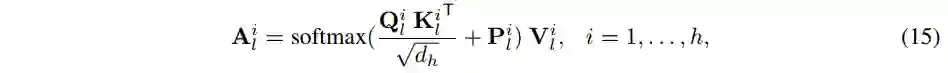
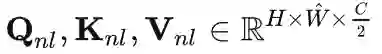 进行 网格划分,再reshape,从
进行 网格划分,再reshape,从
 ,然后再计算 self-attention 如下:
,然后再计算 self-attention 如下:
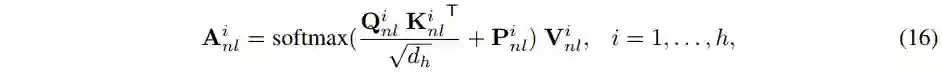
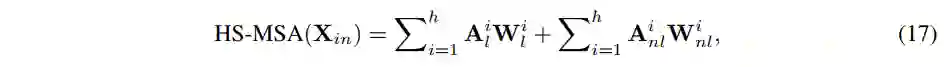
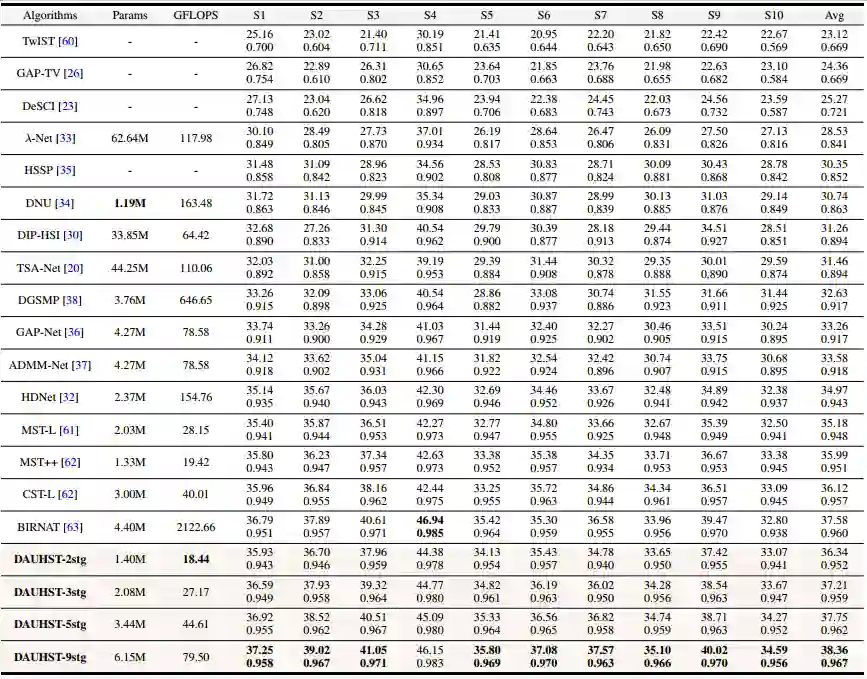
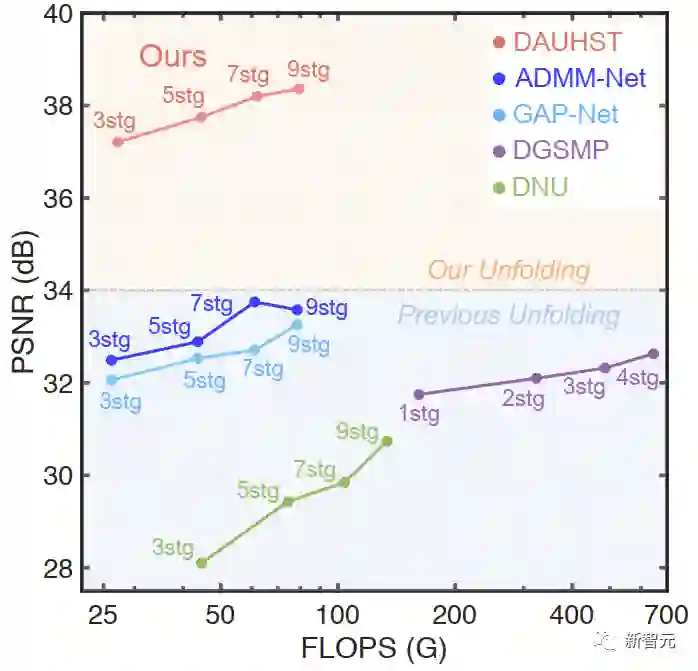
定量实验对比
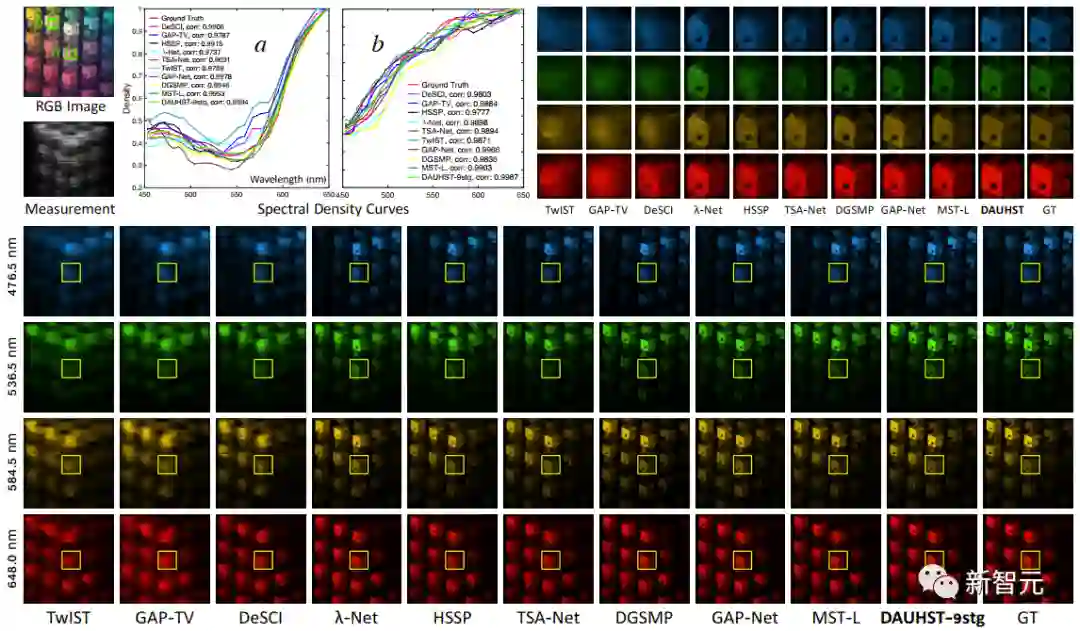
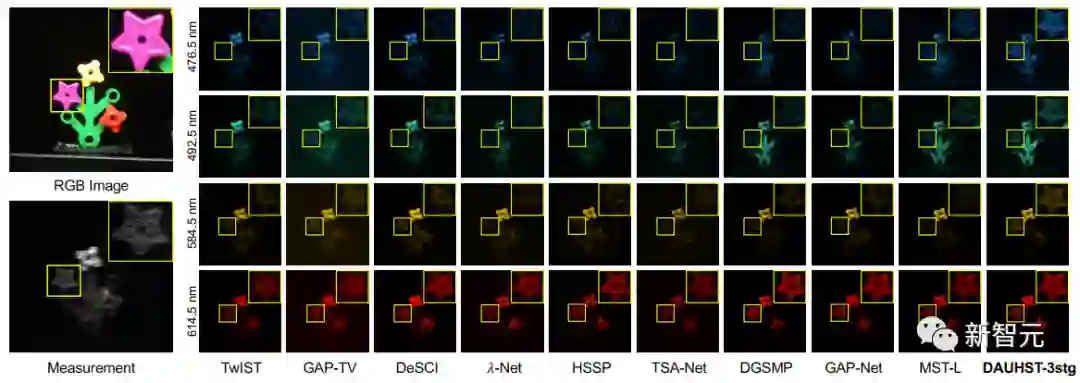
定性实验对比
[CVPR 2022 & NTIRE 冠军] 首个高光谱图像重建Transformer
[ECCV 2022] CST: 首个嵌入光谱稀疏性的Transformer


登录查看更多
相关内容

相关VIP内容
相关资讯