一文搞懂K近邻算法(KNN),附带多个实现案例

简介:本文作者为 CSDN 博客作者董安勇,江苏泰州人,现就读于昆明理工大学电子与通信工程专业硕士,目前主要学习机器学习,深度学习以及大数据,主要使用python、Java编程语言。平时喜欢看书,打篮球,编程。学习为了进步,进步为了更好的学习!
一、KNN回顾
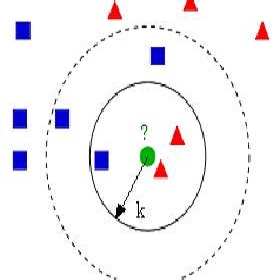
k 近邻学习是一种常用的监督学习方法,比如:判断一个人的人品,只需要观察与他来往最密切的几个人的人品好坏就可以得出,即“近朱者赤,近墨者黑”。
理论/原理:“物以类聚,人以群分”
相同/近似样本在样本空间中是比较接近的,所以可以使用和当前样本比较近的其他样本的目标属性值作为当前样本的预测值。
k 近邻法的工作机制很简单:
给定测试样本,基于某种距离度量(一般使用欧几里德距离)找出训练集中与其最靠近的k个训练样本,然后基于这k个“邻居”的信息来进行预测。
二、KNN三要素
1、K值的选择
对于K值的选择,一般根据样本分布选择一个较小的值,然后通过交叉验证来选择一个比较合适的最终值;
当选择比较小的K值的时候,表示使用较小领域中的样本进行预测,训练误差会减小,但是会导致模型变得复杂,容易导致过拟合;
当选择较大的K值的时候,表示使用较大领域中的样本进行预测,训练误差会增大,同时会使模型变得简单,容易导致欠拟合;
2、距离度量
一般使用欧几里德距离
关于距离度量,还有其他方式
3、决策规则
KNN在做回归和分类的主要区别在于最后做预测时的决策方式不同:
(1)分类预测规则:一般采用多数表决法或者加权多数表决法
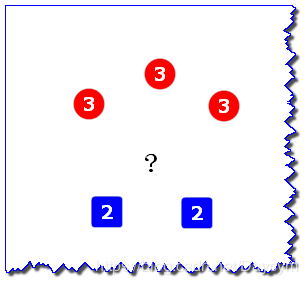
假设图中 “?”表示待预测样本,红色圆表示一类,蓝色方块表示一类,2和3表示到待预测样本的距离
1. 多数表决法:
每个邻近样本的权重是一样的,也就是说最终预测的结果为出现类别最多的那个类;
如图,待预测样本被预测为红色圆
2. 加权多数表决法:
每个邻近样本的权重是不一样的,一般情况下采用权重和距离成反比的方式来计算,也就是说最终预测结果是出现权重最大的那个类别;
如图,红色圆到待预测样本的距离为3,蓝色方块到待预测样本的距离为2,权重与距离成反比,所以蓝色的权重比较大,待预测样本被预测为蓝色方块。
(2)回归预测规则:一般采用平均值法或者加权平均值法
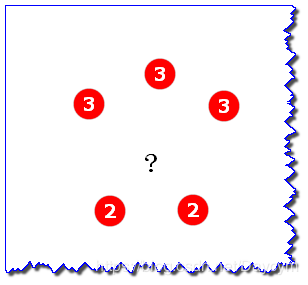
假设上图中的2和3表示邻近样本的目标属性值(标签值),此时没有类别,只有属性值
1、平均值法
每个邻近样本的权重是一样的,也就是说最终预测的结果为所有邻近样本的目标属性值的均值;
如图,均值为(3+3+3+2+2)/5=2.6
2、加权平均值法
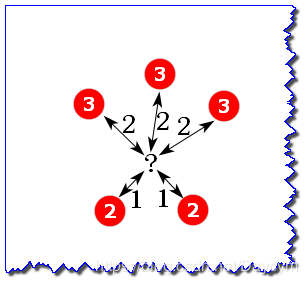
图中,双箭头线上的数表示到待预测样本的距离
每个邻近样本的权重是不一样的,一般情况下采用权重和距离成反比的方式来计算,也就是说在计算均值的时候进行加权操作;
如图,权重分别为(各自距离反比占距离反比总和的比例):
属性值为3的权重:
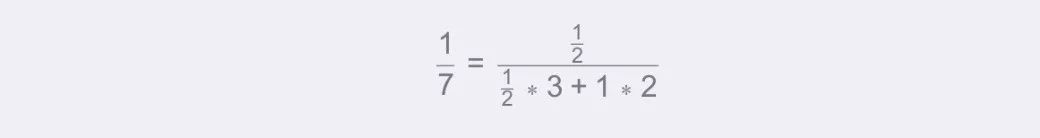
属性值为2的权重:
待预测样本的加权平均值为:
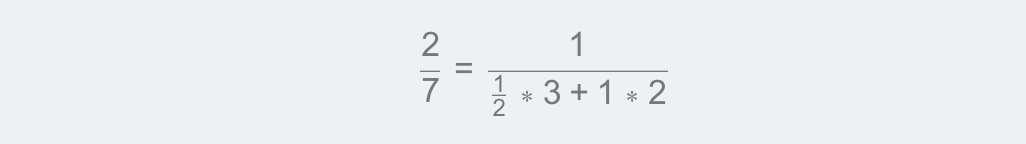
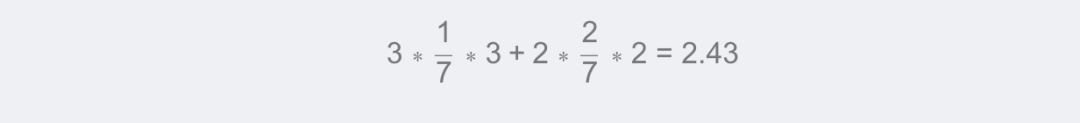
三、手写 k 近邻算法
实现kNN分类算法的伪代码:
对未知类别属性的数据集中的每个点依次执行一下操作:
(1)计算已知类别数据集中的点与当前点之间的距离
(2)按照距离递增次序排序
(3)选取与当前点距离最小的k个点
(4)确定前k个点所在类别的出现频数
(5)返回当前k个点出现频数最高的类别作为当前点的预测分类
欧氏距离公式:
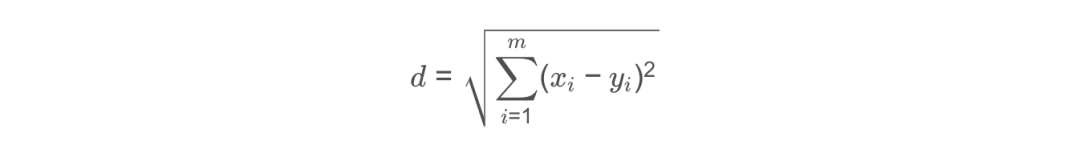
例如求点(1,0,0,1) (1,0,0,1)(1,0,0,1)和(7,6,9,4) (7,6,9,4)(7,6,9,4)之间的距离:
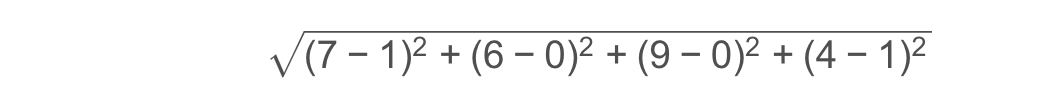
检测分类器效果:
可以使用已知类别的数据(当然不告诉分类器),检验分类器给出的结果是否与已知类别相同,通过大量的测试数据,我们可以计算出分类器的错误率。
以上算法的实现是用于分类的,决策规则使用了多数表决法;此算法通过改变决策规则,同样可以用于回归。
源代码可见:https://github.com/Daycym/Machine_Learning/tree/master/03_KNN;01_k近邻算法.py
四、使用手写k kk 近邻算法的案例
1、案例1:约会网站的配对效果
样本包括3种特征:
每年获得的飞行常客里程数
玩视频游戏所耗时间百分比
每周消费的冰淇淋公升数
样本包括3种标签:
不喜欢的人
魅力一般的人
极具魅力的人
部分数据格式为:

代码可见:02_约会网站的配对效果.py
2、案例2:手写数字识别系统
数据集包括训练集和测试集
数据是32*32的二进制文本文件
需要将文本数据转换为Numpy数组
如下是0的一种表示:
100000000000001100000000000000000
200000000000011111100000000000000
300000000000111111111000000000000
400000000011111111111000000000000
500000001111111111111100000000000
600000000111111100011110000000000
700000001111110000001110000000000
800000001111110000001110000000000
900000011111100000001110000000000
1000000011111100000001111000000000
1100000011111100000000011100000000
1200000011111100000000011100000000
1300000011111000000000001110000000
1400000011111000000000001110000000
1500000001111100000000000111000000
1600000001111100000000000111000000
1700000001111100000000000111000000
1800000011111000000000000111000000
1900000011111000000000000111000000
2000000000111100000000000011100000
2100000000111100000000000111100000
2200000000111100000000000111100000
2300000000111100000000001111100000
2400000000011110000000000111110000
2500000000011111000000001111100000
2600000000011111000000011111100000
2700000000011111000000111111000000
2800000000011111100011111111000000
2900000000000111111111111110000000
3000000000000111111111111100000000
3100000000000011111111110000000000
3200000000000000111110000000000000
预测错误的总数为:10
手写数字识别系统的错误率为:0.010571
代码可见:03_手写数字识别系统.py
五、KD树
KNN算法的重点在于找出K个最邻近的点,主要方法如下:
1、蛮力实现(brute)
计算出待预测样本到所有训练样本的训练数据,然后选择最小的K个距离即可得到K个最邻近点;
当特征数比较多,样本数比较多的时候,算法的执行效率比较低。
2、KD树(KD_Tree)
KD_Tree算法中,首先是对训练数据进行建模,构建KD树,然后再根据构建好的模型来获取邻近样本数据
KD_Tree是KNN算法中用于计算最近邻的快速、便捷构建方式
除此之外,还有一些从KD_Tree修改后的求解最邻近点的算法,比如:Ball Tree、BBF Tree、MVP Tree等
当样本数据量少的时候,我们可以使用brute这种暴力的方式进行求解最近邻,即计算到所有样本的距离。
当样本量比较大的时候,直接计算所有样本的距离,工作量有点大,所以在这种情况下,我们可以使用kd tree来快速的计算。
(1)KD数的构建
KD树采用从m个样本的n维特征中,分别计算n个特征取值的方差,用方差最大的第 k 维特征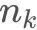
假设二维样本为:{(2, 3), (5, 4), (9, 6), (4, 7), (8, 1), (7, 2)},下面我们来构建KD树:
1、计算每个特征的方差,取方差最大的作为根节点
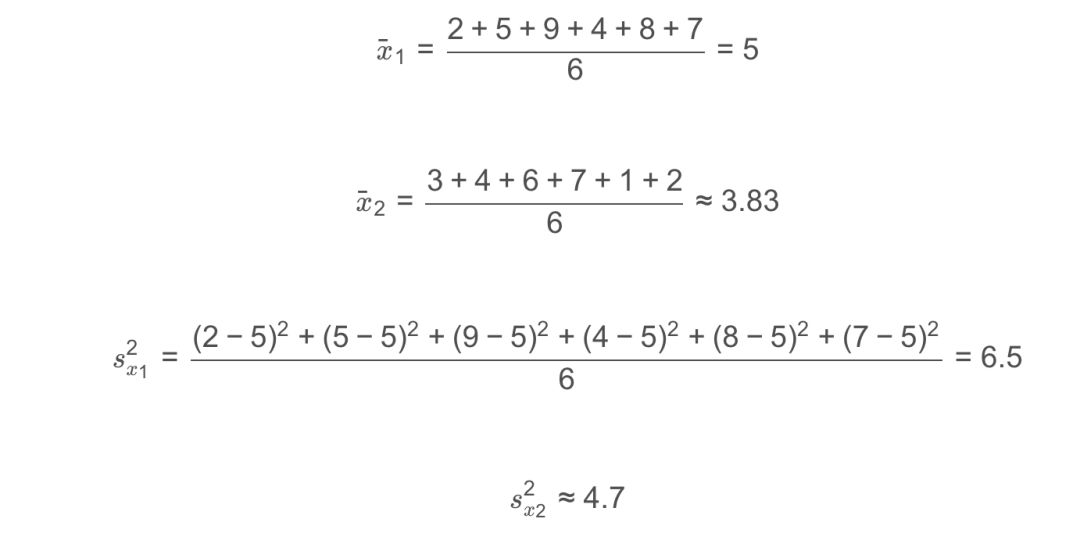
方差表示数据的离散程度,离散程度越大,值越大。因此,选择第1维特征x1作为根节点。
2、选取中位数作为划分点
x1取值为2,4,5,7,8,9 2,4,5,7,8,92,4,5,7,8,9中位数取7来划分,小于该值的放在左子树,大于该值的放在右子树
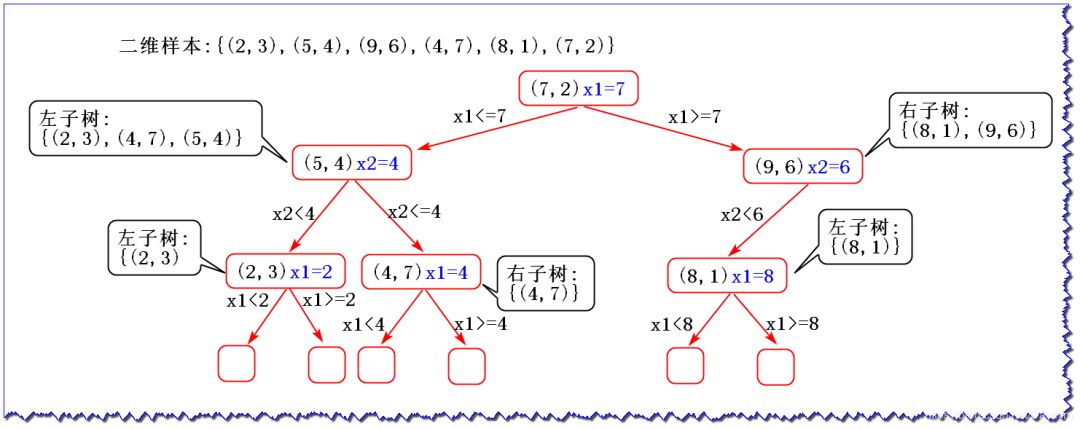
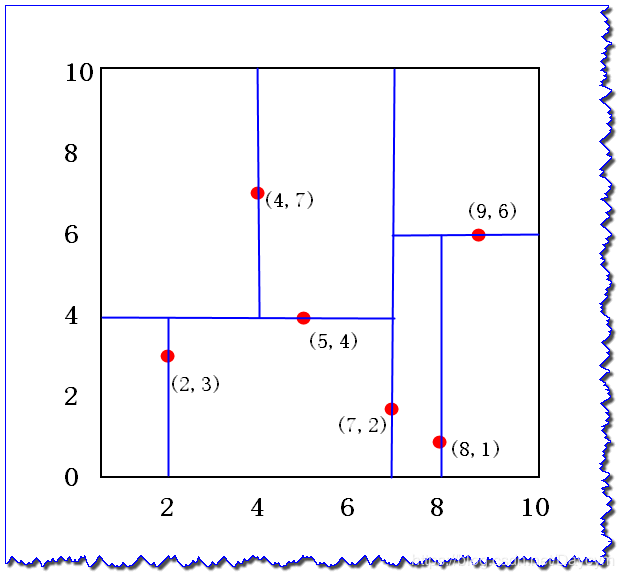
3、特征空间划分:
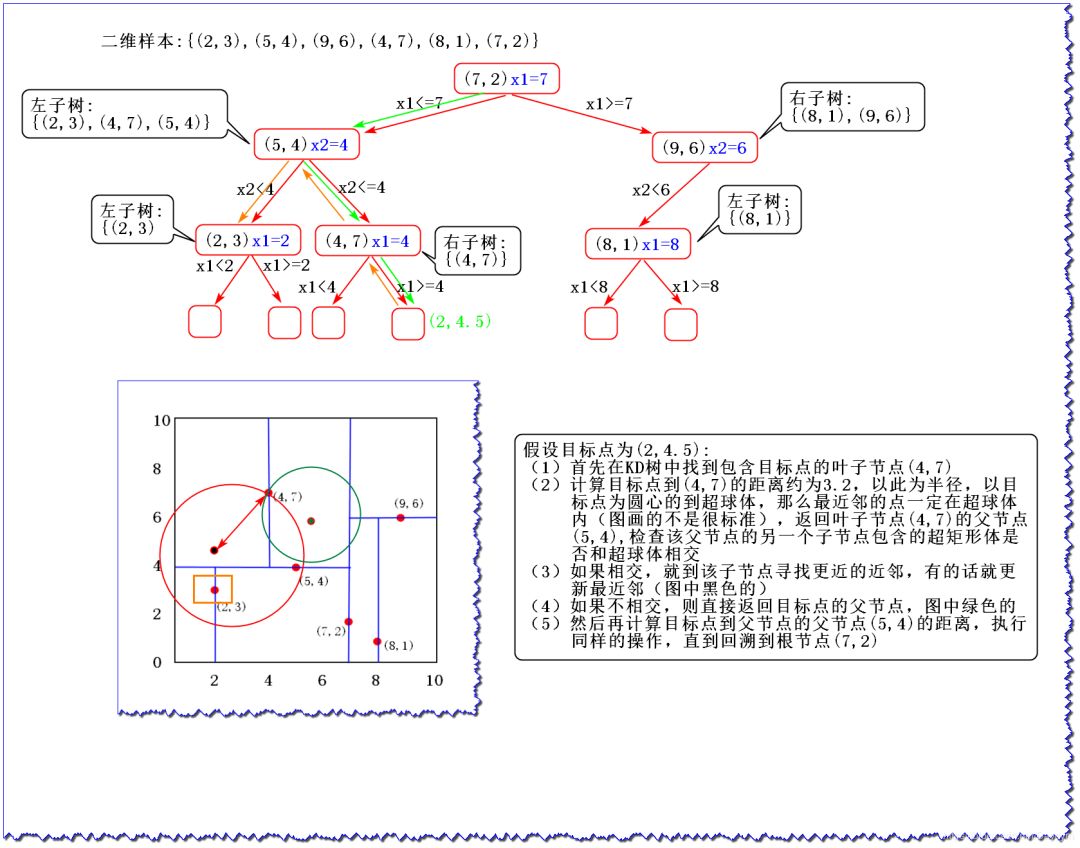
(2)KD tree查找最近邻
当我们生成KD树以后,就可以取预测测试集里面的样本目标点了。
对于一个目标点,我们首先在KD树里面寻找包含目标点的叶子节点;
以目标点为圆心,以目标点到叶子节点样本实例的距离为半径,得到一个超球体,最近邻的点一定在这个超球体内部;
然后返回叶子节点的父节点,检查另一个子节点包含的超矩形体是否和超球体相交,如果相交就到这个子节点寻找是否有更加近的近邻,有点话就更新最近邻;如果不相交那就直接返回父节点的父节点,在另一个子树继续搜索最近邻;
当回溯到根节点时,算法就结束了,保存最近邻节点就是最终的最近邻。
假设要寻找点(2,2.5) (2,2.5)(2,2.5)的最近邻点:
六、KNN案例
1、鸢尾花数据分类
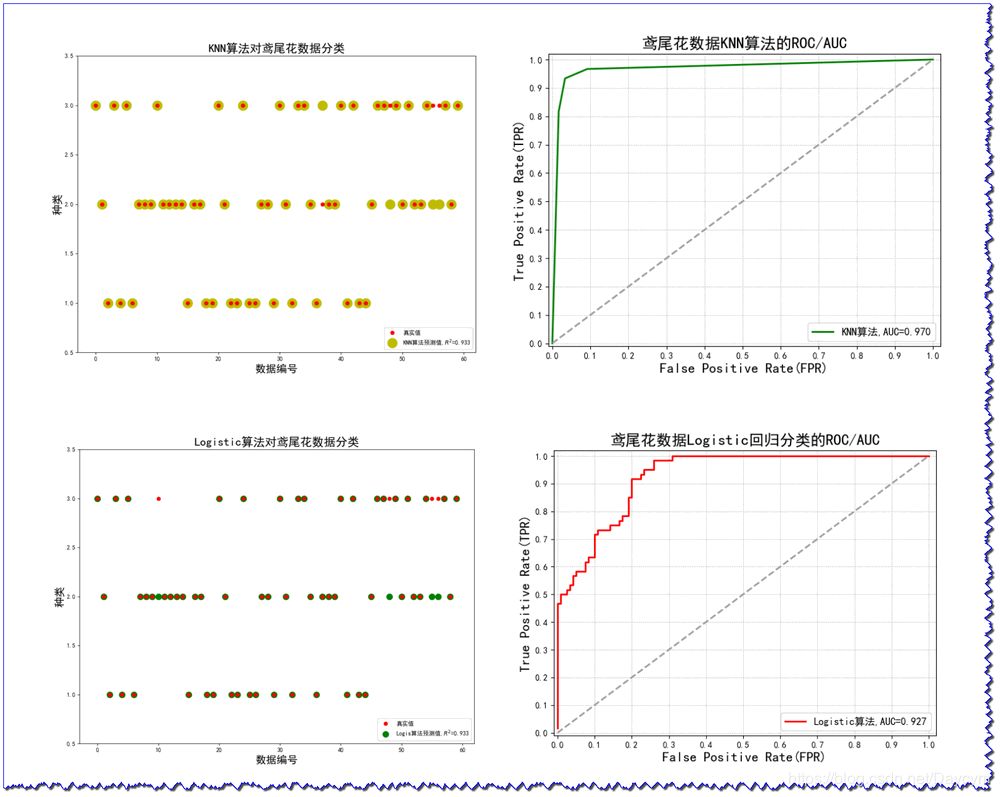
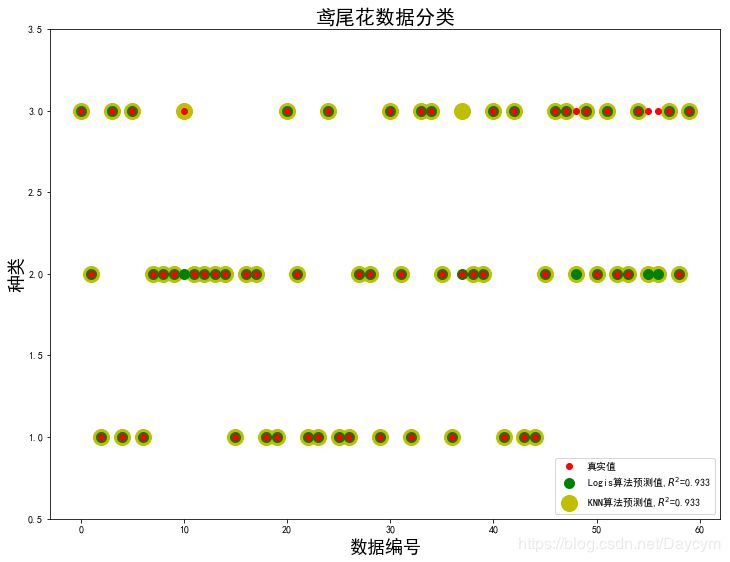
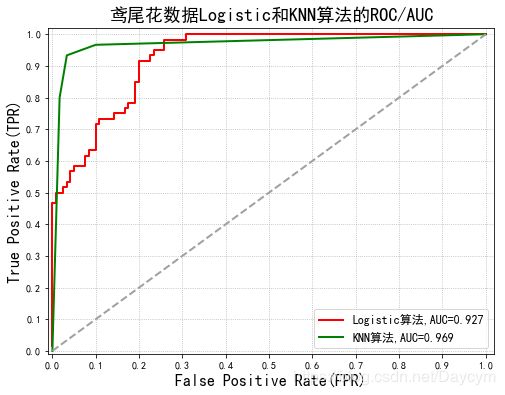
使用Logistic算法和KNN算法对鸢尾花数据进行分类,比较结果;
具体内容在代码的注释中有介绍;
画出下面两张图,需要将代码整合起来,才能画出来。
代码可见:https://github.com/Daycym/Machine_Learning;02_Logistic回归下05_鸢尾花数据分类.py,以及03_KNN目录下04_鸢尾花数据分类.py。
2、信贷审批
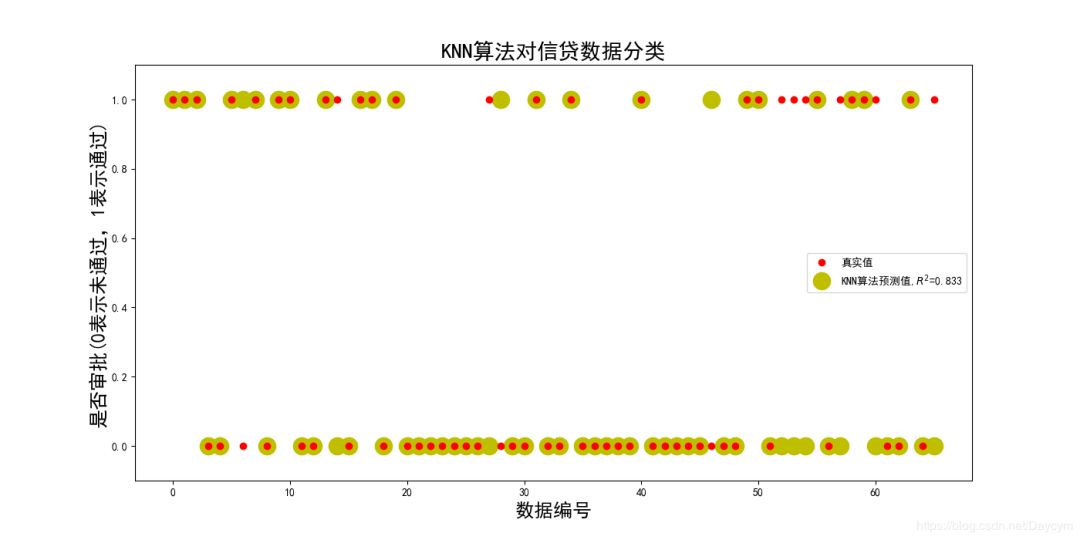
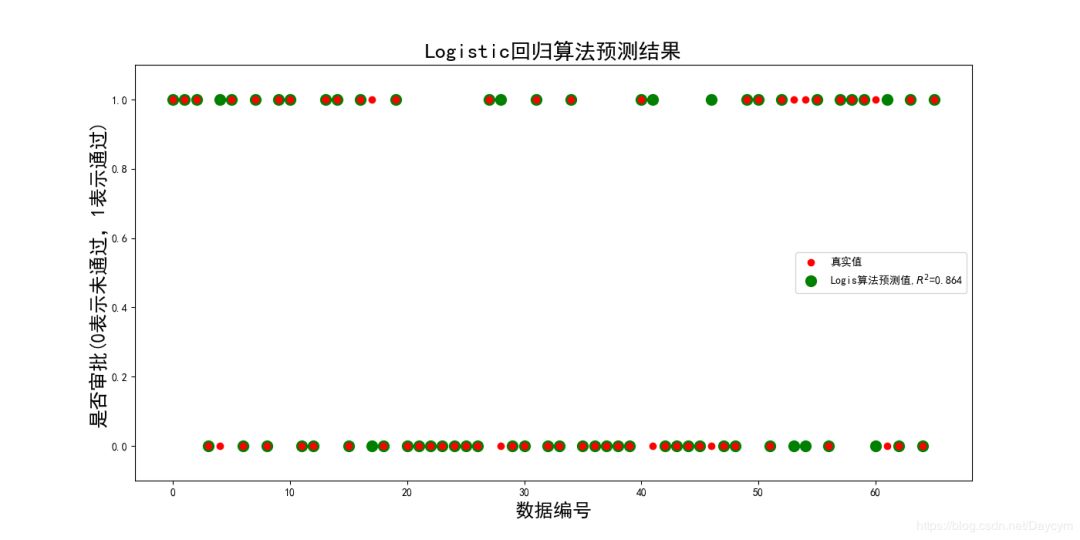
具体内容将在代码中介绍
代码可见:https://github.com/Daycym/Machine_Learning;02_Logistic回归下03_信贷审批.py,以及03_KNN目录下05_信贷审批.py。
七、总结
本篇主要通过简单的暴力求解的方式实现KNN算法,有助于理解KNN算法
后面又介绍了KD树找K个最近邻,此算法是最快捷的
最后通过sklearn库下的KNeighborsClassifier实现了两个案例,来属性KNN模型的构建
原文链接:
https://blog.csdn.net/Daycym/article/details/84452786
(*本文为AI科技大本营转载文章,转载请联系原作者)
◆
推荐
◆

推荐阅读