有趣!机器学习预测《守望先锋》里的赢家

网络游戏及电竞流媒体业务正在崛起为一个巨大的市场。在去年的英雄联盟世界锦标赛中,仅一场半决赛就有高达 1.06 亿人观看,甚至超过了 2018 年“超级碗”的观看人数。另一个成功的例子是 Twitch,目前有数千游戏玩家在上面直播玩游戏,平台也早已收获数千万观众。而专门向游戏玩家提供个性化游戏分析报告的公司 Visor,正积极搭建模型,用于实时预测游戏比赛中的胜负。
Twitch上的游戏主播
能够预测游戏胜负的模型
这种能够预测游戏胜负的模型会有很多用途,例如为玩家提供有益的反馈,帮助他们改进技术;从观众角度讲,会成为很好的参与工具,特别是能吸引那些对游戏尚不熟悉的潜在观众群体;最最重要的是,如果模型能比人类更准确的预测比赛,那么它在电竞投注方面会有史无前例的应用前景。

守望先锋角色合影
为《守望先锋》建模
我(作者 Bowen Yang——译者注)为游戏《守望先锋》搭建了一个模型。《守望先锋》是一款基于团队的多人在线 FPS 游戏。每个团队有 6 名玩家,每个玩家选择一个英雄(见上图),然后同另外一队作战。每场游戏在一个特定的游戏地图上进行,在游戏开始前就会确定地图。简单做个比喻,就跟足球赛差不多,有两支队伍,在某个球场上踢球。
预测一场游戏的胜负涉及到很多因素,这些因素大部分都是类别特征。例如,英雄的选择状况很大程度上预示了游戏结果,特别是在早期阶段。

例如低分段的比赛里“半藏+黑百合”的组合胜率奇低
因此,我们挑战就是如何处理这些类别特征。如果我只用独热编码,特征空间会很容易的超过几百个维度。不幸的是,几乎不可能收集到足够多的游戏视频去供给维度如此之高的“怪物”。
然而,这个凶神恶煞的“怪物”也是可以被打败的。在本文,我会讲解如何用“嵌入”(embeddings)为游戏中的角色建模,以及如何优化预测。
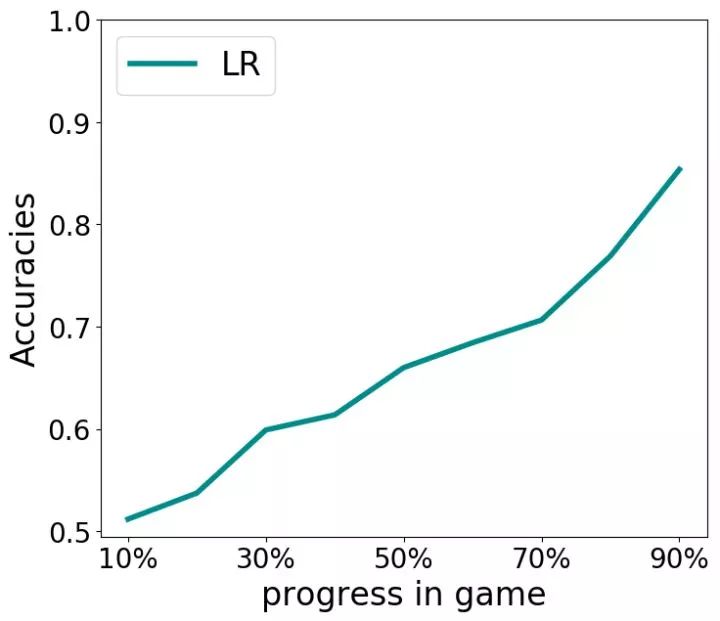
上图为预测准确率 VS 游戏进度。预测由逻辑回归、独热编码和特征选择进行建模后得出。预测值在游戏即将结束时越来越准确,但在游戏开始阶段几乎都是随机猜测(50%的准确率)。我们的挑战是怎样优化游戏开始阶段时的预测准确率。
团队组建
团队是现代多人在线游戏的核心概念,从 RPG 游戏如《魔兽世界》到竞技游戏如《Dota2》、《英雄联盟》、《守望先锋》,莫不如此。而英雄人物正是团队的组建基石。
《守望先锋》中的英雄可以分为3个子类别:进攻者(DPS)、防守者(坦克)、支援者(奶妈)。每个英雄都有他/她自己的长处和短处。一个团队的构成应当均衡配置(这样不会有特定的瓶颈)、密切协作(这样能优势互补),并且根据玩家的技术水平和当前地图组队。这跟篮球队的组队很像,比如要考虑前锋、中锋和后卫的配置。因此,在团队构成上是由一定的模式可循的。说得更正式些,某些英雄有可能往往共同出现在同一队中。

一个典型的平衡配置的《守望先锋》队伍包含两名攻击者,两名防守者和两名支援者。
和均衡组合的篮球队很像。
如果我们更进一步讲,在某些情况下,人类和这些英雄也很相似。我们每个人都各不相同,仍然在这个社会上分工协作。在团队中工作,身处朋友圈子中,共享利益。而为《守望先锋》中的英雄建模的背后理念就如同为人类(或商业活动中的用户)建模。问题是,我们该如何以紧凑且有意义的方式为这些英雄建模。
词汇组成句子
将词汇和游戏中的英雄进行类比,我们能获得直觉的感知。词汇包含了很多意义,如果它们组成句子或文章时,会更有意义。同样,游戏中的这些英雄背后也有很多“意义”或个性,比如有些英雄擅长进攻,有些擅长防守,如果他们组成队伍的话,情况会变得更为复杂。
传统上,我们用独热编码为词汇建模,但这很容易受到维度的影响,因为如果词汇很大的话,特征空间很容易就会有成百上千个维度。独热编码简单假设词汇相互独立,也就是说它们的表示相互正交,因此无法捕捉词汇的语义。另一方面,词汇也能用分布式表征(也叫词向量)来表示。在这种情况下,可以用更低维度的稠密向量(嵌入)捕捉到词汇的语义。
以分布式表征表示词汇的一种现代方法就是著名的 Word2vec 模型。关于这种模型已经有了很多详细解释和应用指南。
超越 Word2vec
词向量的背后目的不仅仅是嵌入词汇。为了能利用嵌入的强大力量,我们需要考虑几个方面。
相似性。相似性代表了输入之间的“重叠”。例如,“国王”和“王后”都代表统治者。输入之间的重叠越多,它们的嵌入就会越密集(维度更少)。换句话说,不同的输入会映射到相同的输出。如果输入从内在上正交,进行嵌入操作就没有意义了。
训练任务。嵌入是从训练任务中学习到的(或预先学习到)。因此训练任务应和我们自己的训练任务相关,这样嵌入的信息才可以迁移。例如,用谷歌新闻训练 Word2vec,将其用于机器翻译。它们就是相关的,因为两者可以共享词汇的隐含语义。
大量数据。如果想全面找出输入背后的相似性或关系,需要有大量的数据来探索高维度空间。通过分布式表征进行降维操作的“黑色魔术”很大程度上是由于有大量数据适用于非监督式学习。例如,Word2vec 模型就是用数十亿词汇训练而成。在某种程度上,嵌入就是独热编码输入和下游任务之间一个额外层的权重,仍然需要大量的数据来填充高维度输入空间。
团队:“CBOH”算法
这里的“CBOH”是“Continuous Bag of Heroes”的简写,你也应该猜到了,就是仿自 Word2vec 中的 CBOW 算法,即 Continuous Bag of Words。
根据我们上文谈论的几点需要考虑的地方,我逐步设计了 Hero2vec 模型。
相似性。之前提过,《守望先锋》中的英雄可以归为一定的类别。这种相似性表明他们也能够通过分布式表征进行表示,而非独热编码。
训练任务。Word2vec 会通过为中心词汇和语境词汇共同出现的状况建模来捕捉词汇的整体语义。同样地,游戏中能优势互补的英雄也会出现同一队伍中,也就是说,联合概率P(h0, h1,… h5)很高(h代表英雄)。不过,建模这种联合概率仍不是很直接。那么我们可以试着将条件概率P(h0|h1, h2,… h5)最大化。因为比赛结果的预测值就是概率P(结果|h0, h1,… h5, 其它因素),因此这两个任务高度相关。

图:根据团队中5个“上下文”英雄,是有可能预测最后一个英雄(“中心词”)的。例如,如果队伍已有2个攻击者、2个防守者和1个支援者,那么剩下的那个很高概率是个支援者。
数据。 Visor 提供给我超过 3 万个游戏团队的队伍构成数据,用以预训练嵌入。和数十亿的词汇相比,3 万可能看起来是个很小的数目,但和词汇(维度 26,000+)相比,我的输入的维度也小得多(26 个英雄)。考虑到训练数据的需求会随着维度呈指数级增长,3 万这个数字实际上足够我训练模型了。
模型。概率P(h0|h1, h2,… h5)和 Word2vec 模型的 CBOW 算法中所用的 P(中心词汇|语境词汇)的形式一模一样。更直观的讲,不像词汇,(h1, h2,… h5)的排列状况不影响概率,因此(h1, h2,… h5)的嵌入之和是输入的很好总结。模型的架构说明见下方。这里有个小技巧,除了P(h0|h1, h2,… h5)外,我们也可以这样建模 P(h1|h0, h2,… h5)等等,因此数据集可以有效的扩充 6 倍。
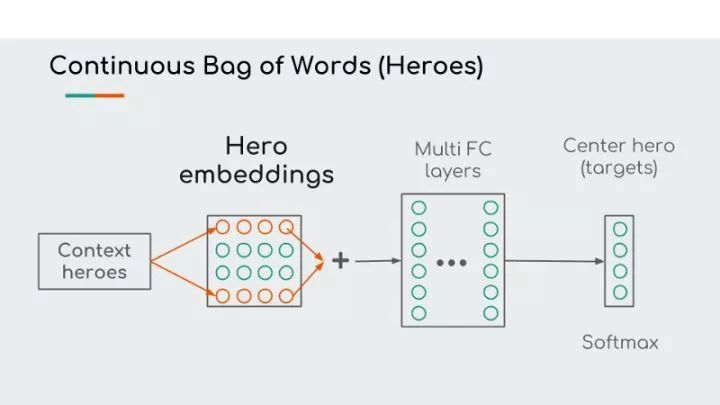
上图是 Hero2vec 模型的架构,包括一个嵌入层、一个全连接层和一个softmax层。由于 softmax 层只有26个目标,无需进行负采样。
将游戏英雄可视化
游戏英雄的嵌入(这里是 10 个维度)可以通过将它们投射到一个二维平面上(用 PCA)进行可视化,如下所示。
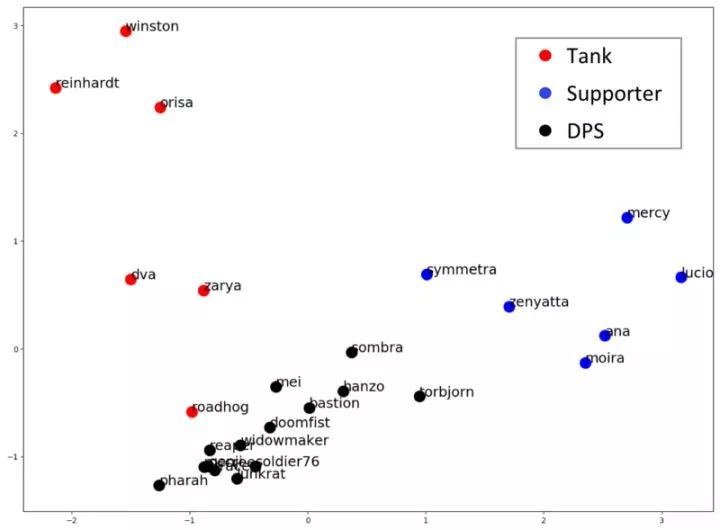
游戏英雄的嵌入(投射到2维平面上)
很明显,嵌入成功地捕捉了这些英雄背后的游戏设计理念。他们趋向于根据自身的角色和类别聚集在一起。更有意思的是,嵌入还捕捉到了这些英雄超出类别特征之外的微妙特点。例如,路霸被很多玩家当成 DPS 英雄(2333333),虽然他被设计成坦克;尽管被认为是支援型英雄,“秩序之光”并没有怎么治愈盟友,所以她更接近于 DPS 英雄和坦克等。对于熟悉《守望先锋》的人来说,值得一提的是进攻型和防守型 DPS 英雄之间并没有明确的界限,建议玩家别真的按游戏设计的类别来使用他们。

很难说秩序之光是一个传统的支援型英雄
因此,和英雄(或商业产品)的硬编码类别相比,嵌入在捕捉它们的个性或属性方面会更灵活更准确,也就是说,玩家(顾客)和游戏设计者(商家)都能从嵌入中获取更有用的信息和见解。玩家可以用它们更好的理解或享受游戏,游戏设计者也能用它们优化游戏的设计。
Map2vec
目前为止,我聊到了如何为《守望先锋》中的英雄建模。在详谈英雄的嵌入如何帮助预测游戏结果之前,我想简单说说怎样处理另一个类别特征,也就是游戏地图。
每局《守望先锋》游戏都是在一个特定的地图上开战(不同地图里各个英雄的优势体现也有所不同),队伍配置实际上也是根据地图所决定,也就是 P(团队|地图)。用贝叶斯定理重写 P(团队|地图)~P(地图|团队)P(团队)。那么可以将 P(地图|团队)建模为嵌入到地图中,如下所示:
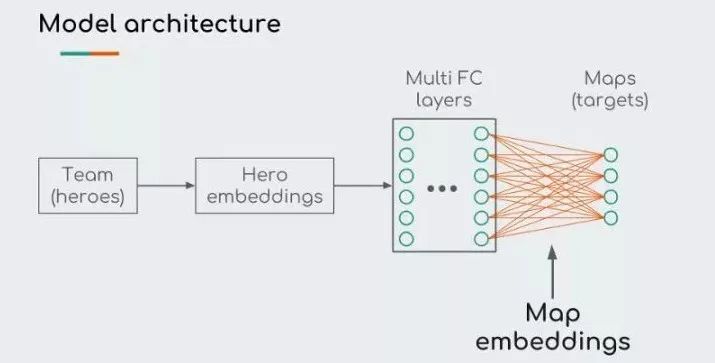
图:模型 map2vec 的架构,包含一个英雄的嵌入层,一个全连接层和一个 softmax 层。 Softmax 层的权重为地图的嵌入。
和上面的 Hero2vec 模型有一点不同,地图的嵌入来自模型最后的线性层。其灵感源自 Word2vec 模型中输入嵌入和输出嵌入都能用于表示词汇。
我们可以简单的将地图的嵌入可视化。
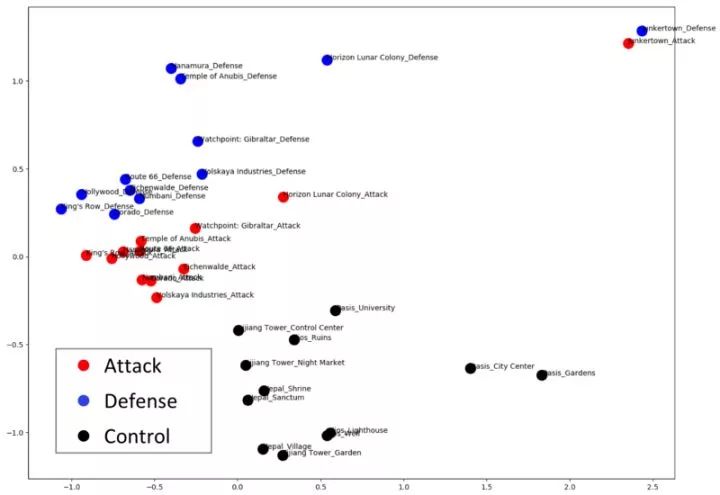
地图的嵌入
嵌入也能很好的理解地图背后的游戏设计。对于那些熟悉《守望先锋》的朋友来说,可以看出单局地图上攻击区和防守区之间的差别要比不同地图之间的差别大得多。
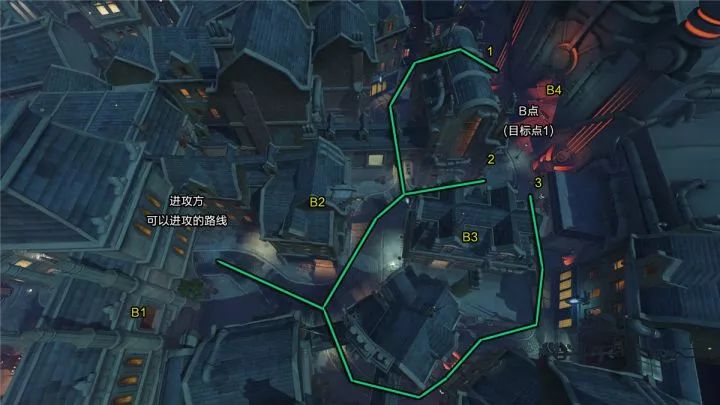
国王大道这种巷战地图很适合法老之鹰、狂鼠这类具有范围伤害的英雄
这种架构也可以泛化,用于为任何共同出现的情况建模。例如,输入可以是一些电影,目标可以是喜欢这些电影的详细观众。训练整个流水线更衣让我们获得电影和观众两方面的嵌入。
用游戏英雄的嵌入预测游戏结果
有了游戏英雄的嵌入以后,就能进一步优化游戏结果预测的准确率,如下所示:

图:预测准确率 VS 游戏进度。使用了 Hero2vec 嵌入后,逻辑回归模型在游戏早期阶段的预测准确率大幅提升。
在都使用逻辑回归方法的情况下,当输入嵌入英雄的嵌入时,其整体准确率要高于只将输入简单地独热编码。更有价值的是,英雄的嵌入真的能提高在游戏开始/中间阶段时的结果预测准确率,而且在游戏越早的时候越难预测结果。
队伍构成同样饱含信息的一个原因是,在游戏开始阶段,数值特征几乎没有任何方差,因此它们几乎没有用处。而随着游戏进行,越来越多的信息开始汇聚在数值特征中,因此这时队伍构成相对来说就没那么重要了。所以,在接近游戏结束时,由于数值特征的方差很大,已经大到足以揭示游戏的结果,这时两个预测值会出现重叠。
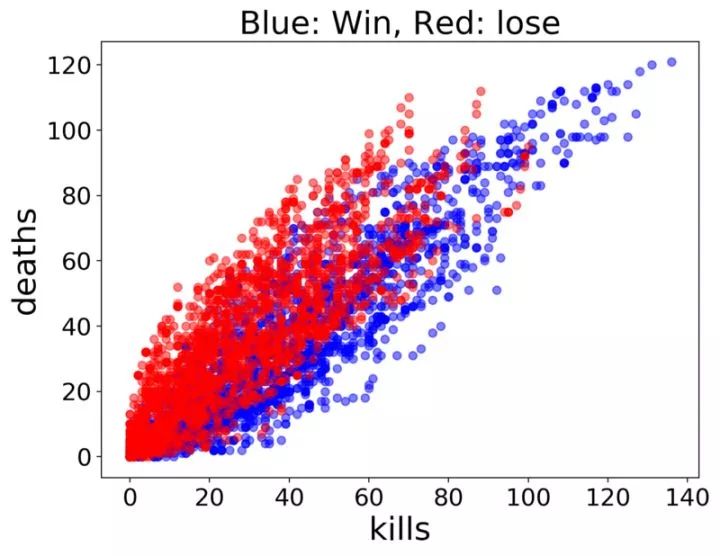
上图为游戏结果 VS 两个重要数值特征。在游戏开始阶段(左下角),数值特征中并无多少方差,结果几乎是重叠的。随着游戏进行(朝右上角发展),方差越来越大,结果很明显开始分离。
结语
总的来看,本文讨论了如何用低维分布式表征来表示高维类别特征,然后解释了神经语言模型和 Word2vec 背后的逻辑。
通过预训练《守望先锋》中的英雄角色,我搭建了一个能预测比赛中团队正确率的模型,而且该模型在游戏开始阶段的预测效果很理想。
除了预测《守望先锋》输赢外,这种逻辑原理也能应用到任何我们感兴趣的领域。我很期待从嵌入中获取的这种知识将来能应用到多种任务上,未来我会继续探索此类问题。
本模型及相关代码参见我的 Git 库:
https://link.zhihu.com/?target=https%3A//github.com/ybw9000/hero2vec
原文链接:https://zhuanlan.zhihu.com/p/37379591
- 加入AI学院学习 -

点击“ 阅读原文 ”进入学习



