一文概览图卷积网络基本结构和最新进展(附视频&代码)

来源:机器之心
本文长度为3476字,建议阅读7分钟
本文为你介绍图卷积网络的基本结构和最新的研究进展,并用一个简单的一阶 GCN 模型进行图嵌入。
本文介绍了图卷积网络的基本结构和最新的研究进展,并指出了当前模型的优缺点。通过对半监督学习应用 GCN 证明三层 GCN 模型不需要节点的任何特征描述就可以对只有一个标签实例的类进行线性分离。
GitHub 链接:https://github.com/tkipf/gcn
论文链接:https://arxiv.org/abs/1609.02907
概览
在当今世界中许多重要的数据集都以图或网络的形式出现:社交网络、知识图表、蛋白质交互网络、万维网等。然而直到最近,人们才开始关注将神经网络模型泛化以处理这种结构化数据集的可能性。
在过去几年间,许多论文都重新注意起将神经网络泛化以处理任意结构图的问题,例如:
2014 年 Bruna 等人发表在 ICLR 的文章:
http://arxiv.org/abs/1312.6203;
2015 年 Henaf f 等人发表的文章:
http://arxiv.org/abs/1506.05163;
2015 年 Duvenaud 等人发表在 NIPS 的文章:http://papers.nips.cc/paper/5954-convolutional-networks-on-graphs-for-learning-molecular-fingerprints;
Li 等人在 2016 年发表在 ICLR 的文章:
https://arxiv.org/abs/1511.05493;
Defferrard 等人 2016 年发表在 NIPS 的文章:https://arxiv.org/abs/1606.09375;
以及 Kipf&Welling 在 2017 年发表在 ICLR 的文章:http://arxiv.org/abs/1609.02907。
目前其中有一些在专业领域中都得到了非常好的结果,在这之前的最佳结果都是由基于核的方法、基于图论的正则化方法或是其他方法得到的。
在这篇文章中,我将简要介绍一下这个领域的最新进展,并指出各种方法的优缺点。这里主要对最近的两篇论文进行讨论:
Kipf & Welling (ICLR 2017), Semi-Supervised Classification with Graph Convolutional Networks:
http://arxiv.org/abs/1609.02907
Defferrard et al. (NIPS 2016), Convolutional Neural Networks on Graphs with Fast Localized Spectral Filtering:
https://arxiv.org/abs/1606.09375
本文还将对 Ferenc Huszar 发表的综述《How powerful are Graph Convolutions?》(http://www.inference.vc/how-powerful-are-graph-convolutions-review-of-kipf-welling-2016-2/)进行讨论。在这篇文章中作者对这几类模型的局限性进行了简短的讨论。我对 Ferenc 这篇综述的看法见本文文末。
大纲
神经网络图模型的简要介绍
谱图卷积和图卷积网络(GCNs)
演示:用一个简单的一阶 GCN 模型进行图嵌入
将 GCNs 视为 Weisfeiler-Lehman 算法的可微泛化
如果你已经对 GCNs 及其相关方法很熟悉了的话,你可以直接跳至“GCNs 第 Ⅲ 部分:嵌入空手道俱乐部网络”部分。
图卷积网络到底有多强大
近期文献
将成熟的神经模型(如 RNN 或 CNN)泛化以处理任意结构图是一个极具挑战性的问题。最近的一些论文介绍了特定问题的专用体系结构,例如:
Duvenaud 等人 2015 年发表在 NIPS 的文章:http://papers.nips.cc/paper/5954-convolutional-networks-on-graphs-for-learning-molecular-fingerprints;
Li 等人 2016 年在 ICLR 发表的文章:
https://arxiv.org/abs/1511.05493;
Jain 等人 2016 年发表在 CVPR 的文章:
https://arxiv.org/abs/1511.05298。
还有一些根据已知的谱图理论构建的卷积图,例如:
Bruna 等人 2014 年在 ICLR 发表的文章:
http://arxiv.org/abs/1312.6203;
Henaff 等人 2015 年发表的文章:
http://arxiv.org/abs/1506.05163。
来定义在多层神经网络模型中使用的参数化滤波器,类似于我们所知且常用的“经典”CNN。
还有更多最近的研究聚焦于缩小快速启发式和慢速启发式之间的差距,但还有理论更扎实的频谱方法。Defferrard 等人(NIPS 2016,https://arxiv.org/abs/
1606.09375)使用在类神经网络模型中学习得到的具有自由参数的切比雪夫多项式,在谱域中得到了近似平滑滤波器。他们在常规领域(如 MNIST)也取得了令人信服的结果,接近由简单二维 CNN 模型得到的结果。
在 Kipf & Welling(ICLR 2017,http://arxiv.org/abs/1609.
02907)的文章中,我们采取了一种类似的方法,从光谱图卷积框架开始,但是做了一些简化(我们将在后面讨论具体细节),这种简化在很多情况下都显著加快了训练时间并得到了更高的准确性,在许多基准图数据集的测试中都得到了当前最佳的分类结果。
GCNs 第 Ⅰ 部分:定义
目前,大多数图神经网络模型都有一个通用的架构。在此将这些模型统称为图卷积网络(Graph Convolutional Networks,GCNs)。之所以称之为卷积,是因为滤波器参数通常在图中所有位置(或其子集,参阅 Duvenaud 等人 2015 年发表于 NIPS 的文章:http://papers.nips.cc/paper/5954-convolutional-networks-on-graphs-for-learning-molecular-fingerprints)共享。
这些模型的目标是通过图上的信号或特征学习到一个函数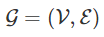
每个节点 i 的特征描述 x_i,总结为一个 N * D 的特征矩阵 X(N:节点数量,D:输入特征数量)
图结构在矩阵形式中的一个代表性描述,通常以邻接矩阵 A(或一些其他相关函数)表示
之后会生成节点级输出 Z(N * F 特征矩阵,其中 F 是每个节点的输出特征的数量)。图级输出可以通过引入某种形式的池化操作建模(例如 Duvenaud 等人在 2015 年发表于 NIPS 的文章 http://papers.nips.cc/paper/5954-convolutional-networks-on-graphs-for-learning-molecular-fingerprints)。
然后每一个神经网络层都可以被写成一个非线性函数: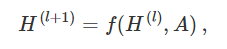
GCNs 第 Ⅱ 部分:一个简单示例
我们先以下述简单的层级传播规则为例: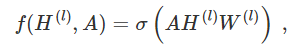
但是首先我们要明确该模型的两个局限性:
与 A 相乘意味着,对每个节点都是将所有相邻节点的特征向量的加和而不包括节点本身(除非图中存在自循环)。我们可以通过在图中强制执行自我循环来"解决"这个问题——只需要将恒等矩阵添加到 A 上。
第二个局限性主要是 A 通常不是归一化的,因此与 A 相乘将完全改变特征向量的分布范围(我们可以通过查看 A 的特征值来理解)。归一化 A 使得所有行总和为 1,即 D^-1 A,其中 D 是对角节点度矩阵,这样即可避免这个问题。归一化后,乘以 D^-1 A 相当于取相邻节点特征的平均值。在实际应用中可使用对称归一化,如 D^-1/2 A D^-1/2(不仅仅是相邻节点的平均),模型动态会变得更有趣。结合这两个技巧,我们基本上获得了 Kipf&Welling 文章(ICLR,2017,http://arxiv.org/abs/1609.02907)中介绍的传播规则:
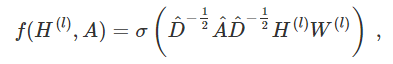
式中 Â =A+I,I 是单位矩阵,D̂ 是 Â 的对角节点度矩阵。
在下一节中,我们将在一个非常简单的示例图上进一步研究这种模型是如何工作的:Zachary 的空手道俱乐部网络(请务必查看维基百科的文章 https://en.wikipedia.org/wiki/Zachary%27s_karate_club)。
GCNs 第 Ⅲ 部分:嵌入空手道俱乐部网络
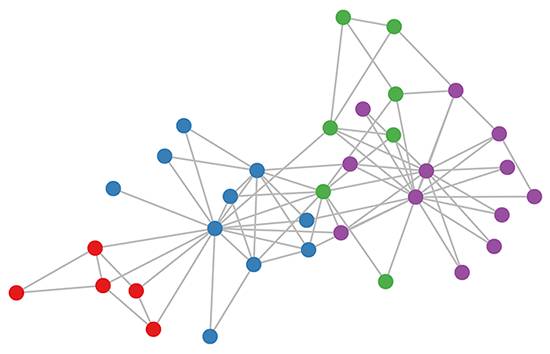
空手道俱乐部图的颜色表示通过基于模块化的聚类而获得的共同体(详情参阅 Brandes 等人发表于 2008 年的文章 http://citeseerx.ist.psu.edu/viewdoc/
summary?doi=10.1.1.68.6623)。
让我们看一下我们的 GCN 模型(参见上一节或 Kipf&Welling 于 2017 年在 ICLR 上发表的文章 http://arxiv.org/abs/1609.02907)是如何在著名的图数据集上工作的:Zachary 的空手道俱乐部网络(见上图)。
我们采用了随机初始化权重的 3 层 GCN。现在,即使在训练权重之前,我们只需将图的邻接矩阵和 X = I(即单位矩阵,因为我们没有任何节点特征)插入到模型中。三层 GCN 在正向传递期间执行了三个传播步骤,并有效地卷积每个节点的三阶邻域(所有节点都达到了三级"跳跃")。值得注意的是,该模型为这些节点生成了一个与图的共同体结构非常相似的嵌入(见下图)。到目前为止,我们已经完全随机地初始化了权重,并且还没有做任何训练。
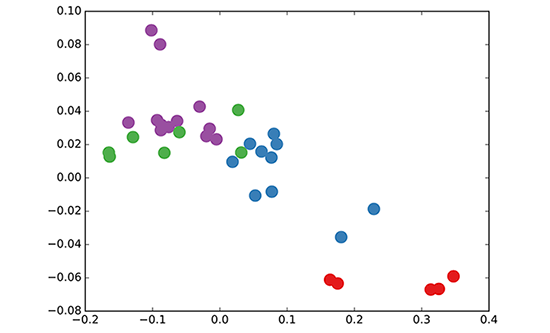
GCN 节点在空手道俱乐部网络中的嵌入(权重随机)
这似乎有点令人惊讶。最近一篇名为 DeepWalk 的模型(Perozzi 等人 2014 年发表于 KDD https://arxiv.org/abs/1403.6652)表明,他们可以在复杂的无监督训练过程中得到相似的嵌入。那怎么可能仅仅使用我们未经训练的简单 GCN 模型,就得到这样的嵌入呢?
我们可以通过将 GCN 模型视为图论中著名的 Weisfeiler-Lehman 算法的广义可微版本,并从中得到一些启发。Weisfeiler-Lehman 算法是一维的,其工作原理如下 :
对所有的节点
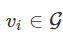
求解邻近节点 {vj} 的特征 {h_vj}
通过 h_vi←hash(Σj h_vj) 更新节点特征,该式中 hash(理想情况下)是一个单射散列函数
重复 k 步或直到函数收敛。
在实际应用中,Weisfeiler-Lehman 算法可以为大多数图赋予一组独特的特征。这意味着每个节点都被分配了一个独一无二的特征,该特征描述了该节点在图中的作用。但这对于像网格、链等高度规则的图是不适用的。对大多数不规则的图而言,特征分配可用于检查图的同构(即从节点排列,看两个图是否相同)。
回到我们图卷积的层传播规则(以向量形式表示):
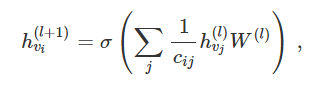
式中,j 表示 v_i 的相邻节点。c_ij 是使用我们的 GCN 模型中的对称归一化邻接矩阵 D-1/2 A D-1/2 生成的边 (v_i,v_j) 的归一化常数。我们可以将该传播规则解释为在原始的 Weisfeiler-Lehman 算法中使用的 hash 函数的可微和参数化(对 W(l))变体。如果我们现在选择一个适当的、非线性的的矩阵,并且初始化其随机权重,使它是正交的(或者,例如使用 Glorot&Bengio 于 2010 年发表于 AISTATS 的文章 http://jmlr.org/proceedings/papers/v9/glorot10a/
glorot10a.pdf 中的初始化),那么这个更新规则在实际应用中会变得稳定(这也归功于归一化中的 c_ij 的使用)。我们得出了很有见地的结论,即我们得到了一个很有意义的平滑嵌入,其中可以用距离远近表示局部图结构的(不)相似性!
GCNs 的第 Ⅳ 部分:半监督学习
由于我们模型中的所有内容都是可微分且参数化的,因此可以添加一些标签,使用这些标签训练模型并观察嵌入如何反应。我们可以使用 Kipf&Welling(ICLR 2017,http://arxiv.org/
abs/1609.02907)文章中介绍的 GCN 的半监督学习算法。我们只需对每类/共同体(下面视频中突出显示的节点)的一个节点进行标记,然后开始进行几次迭代训练:
用 GCNs 进行半监督分类:用每类的一个单独的标签进行 300 次迭代训练得到隐空间的动态。突出显示标记节点
请注意,该模型会直接生成一个二维的即时可视化的隐空间。我们观察到,三层 GCN 模型试图线性分离这些(只有一个标签实例的)类。这一结果是引人注目的,因为模型并没有接收节点的任何特征描述。与此同时,模型还可以提供初始的节点特征,因此在大量数据集上都可以得到当前最佳的分类结果,而这也正是我们在文章(Kipf&Welling,ICLR,2017,http://arxiv.org/abs/
1609.02907)中描述的实验所得到的结果。
结论
有关这个领域的研究才刚刚起步。在过去的几个月中,该领域已经获得了振奋人心的发展,但是迄今为止,我们可能只是抓住了这些模型的表象。而神经网络如何在图论上针对特定类型的问题进行研究,如在定向图或关系图上进行学习,以及如何使用学习的图嵌入来完成下一步的任务等问题,还有待进一步探索。本文涉及的内容绝非详尽无遗的,而我希望在不久的将来会有更多有趣的应用和扩展。
编辑:文婧
校对:王懿璇
为保证发文质量、树立口碑,数据派现设立“错别字基金”,鼓励读者积极纠错。
若您在阅读文章过程中发现任何错误,请在文末留言,或到后台反馈,经小编确认后,数据派将向检举读者发8.8元红包。
同一位读者指出同一篇文章多处错误,奖金不变。不同读者指出同一处错误,奖励第一位读者。
感谢一直以来您的关注和支持,希望您能够监督数据派产出更加高质的内容。




