Paper | ACL2018 抽取式摘要之 NEUSUM

论文题目:Neural Document Summarization by Jointly Learning to Score and Select Sentences.
论文作者:Qingyu Zhou, Nan Yang, Furu Wei, Shaohan Huang, Ming Zhou, Tiejun Zhao.
下载链接:https://aclweb.org/anthology/P18-1061
代码:https://github.com/magic282/NeuSum
来源:ACL 2018
分类:NLP / 文本摘要 / 抽取式摘要
太长不看版
本文提出了一种端到端的抽取式文本摘要模型(NEUSUM)。
该模型将选择策略集成到打分模型中,解决了此前抽取式文本摘要中句子打分和句子选择这两部分割裂的问题,端到端且不再需要人为干预。
并达到了 CNN/Daily Mail 数据集的 state-of-the-art。
主要思想
基于深度学习的抽取式摘要的方法基本分为以下四个步骤:句子编码、文章编码、句子打分、摘要选择。
这其中摘要选择部分的顺利进行依赖于句子可以很好的打分,然而在此前的研究方法句子打分与句子选择(即摘要选择)这两个环节常常被割裂开来。
本文针对这一现象,提出了一种端到端的抽取式文本摘要模型(NEUSUM),将选择策略集成到打分模型中,解决了此前抽取式文本摘要中句子打分和句子选择这两部分割裂的问题,端到端且不再需要人为干预。并达到了 CNN/Daily Mail 的 state-of-the-art。
问题定义
抽取式摘要的目的在于抽取能够包含文章重要信息的句子,句子打分越高,其包含的信息越重要,越成为表示文章的摘要句。
本模型的训练目标即学到一个score function(打分函数)g,该函数目的是计算加入当前句子后生成的摘要能得到的ROUGE F1的收益。在测试时,模型在每一个 step t 选出能使打分函数 g 最高的句子。
公式中函数 r 即表ROUGE F1。S表示当前句子与已经选出的句子集合。在每一个时间步 t,模型会选出能够得到最大收益(即使函数 g 得到最大值的句子)直至达到摘要限制长度。
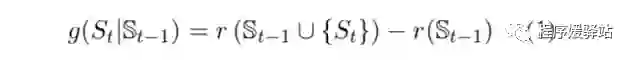
模型结构
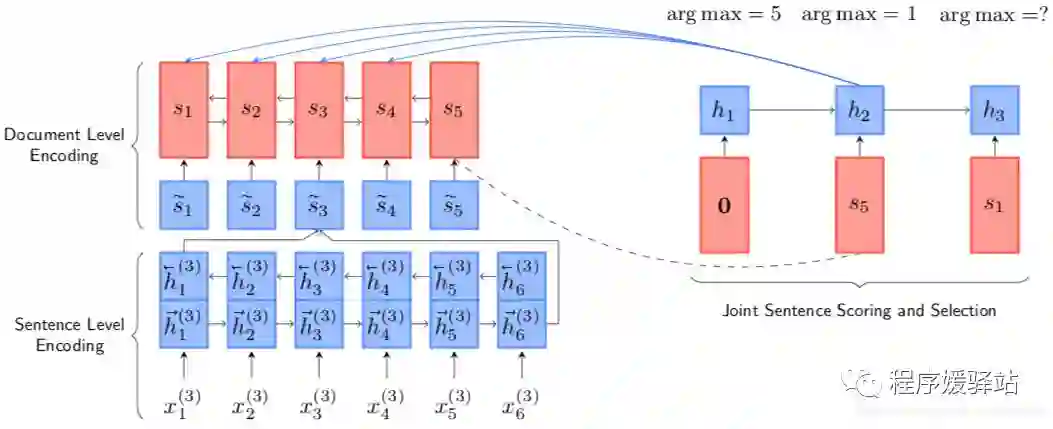
基于深度学习的抽取式摘要的方法基本分为以下四个步骤:1.句子编码、2.文章编码、3.句子打分、4.摘要选择。
而在本文的模型中:
1-2)Document & Sentence Encoding:句子编码、文章编码使用BiGRU
3-4)Sentence Scoring and Selection:句子打分、摘要选择两部分融合到一起
融合到一起的好处:
a. 句子打分时可以看到前面句子的信息(前人方法的句子打分时句子间相对独立)
b. 打分函数 g 的存在简化了句子选择模块
句子打分的具体实现:
句子打分需要同时考虑当前句子的重要性和已经选出的summary,此处加入另一个GRU(公式10)。
然后在GRU之上连接句子打分器(scorer)。
The sentence scorer 是一个双层MLP,两个向量作为输入:current hidden ht 和 sentence vector si(公式11(有bias,为了简化在公式中省略)),计算得到的即为在 t 时刻所有句子的分数。

然后选择得分最高的句子作为时刻 t 模型选择的摘要句。
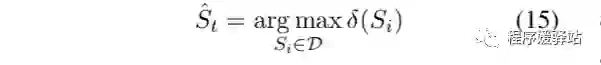
损失函数:
模型预测值 P 与标准值 Q 之间的数据分布差异我们使用KL散度进行计算,其中 P 分布的归一化计算公式:
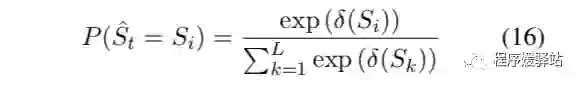
Q 分布的计算公式:
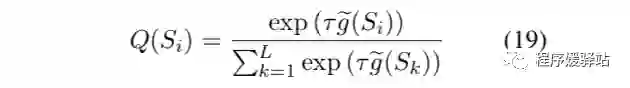
Objective Function:KL-loss-function: J = DKL(P || Q) (20)
数据构建
CNN/Daily Mail 是人为标注的生成式摘要的数据集。本文构建抽取式摘要训练数据的方法是 maximizing the ROUGE-2 F1 score。
数据预处理部分(包括sentence splitting, word tokenization)参照See et al. (2017), 使用非匿名版本。
CNN/Daily Mail 数据集统计如下表:

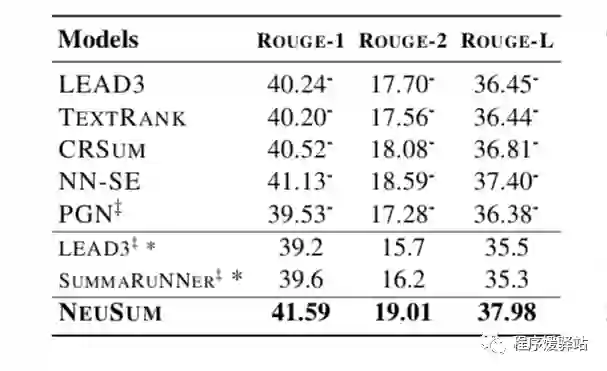
实验结果:
结论
本文的方法与以前的方法最大的不同之处在于,它将句子评分和选择结合成一个阶段。
每次选择一个句子,根据已输出摘要和当前状态对句子进行评分。
最终的ROUGE评价结果表明,本文提出的联合评分和选择方法明显优于以往的分离方法。
推荐阅读
文本自动摘要任务的“不完全”心得总结番外篇——submodular函数优化
斯坦福大学NLP组Python深度学习自然语言处理工具Stanza试用
太赞了!Springer面向公众开放电子书籍,附65本数学、编程、机器学习、深度学习、数据挖掘、数据科学等书籍链接及打包下载
数学之美中盛赞的 Michael Collins 教授,他的NLP课程要不要收藏?
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLPer(id:ainlper),备注工作/研究方向+加群目的。

阅读至此了,点个在看吧👇



