仅用200个样本就能得到当前最佳结果:手写字符识别新模型TextCaps
选自 arxiv
作者:Vinoj Jayasundara 等
机器之心编译
参与:李诗萌、王淑婷
由于深度学习近期取得的进展,手写字符识别任务对一些主流语言来说已然不是什么难题了。但是对于一些训练样本较少的非主流语言来说,这仍是一个挑战性问题。为此,本文提出新模型TextCaps,它每类仅用200个训练样本就能达到和当前最佳水平媲美的结果。
由于深度学习模型近期取得的进展,对于许多主流语言来说,手写字符识别已经是得到解决的问题了。但对于其它语言而言,由于缺乏足够大的、用来训练深度学习模型的标注数据集,这仍然是一个极具挑战性的问题。
尽管 CNN 可以很好地理解图片中的低级和高级特征,但这样做会在池化层上丢失有价值的信息。CNN 的训练需要大量训练样本(一般每一类需要数千或数万个样本)才能成功地对图像分类。因此人们对用少量训练样本训练成功的 CNN 有着浓厚兴趣。
本文提出了一种技术,它借助胶囊网络(Capsule Networks,CapsNets)[4] 解决了标注数据集太小的问题。我们仅通过操纵实例化参数 [5],利用了 CapsNet 增强数据的能力。在本文的例子中,CapsNet 不仅识别了字符图像,还学习了它的属性。这让 CapsNet 得以在标注数据很少的字符识别问题中大展拳脚。
本文的架构以 Sabour 等人提出的 CapsNet 架构 [4] 为基础,该架构是由胶囊网络和全连接解码器网络组成的。研究人员用反卷积网络(deconvolutional network)代替了解码器网络,同时还对胶囊网络做了一些小改动。
通过给表征实体属性的实例化参数加入一些可控噪声,研究人员转换实体以表征现实中发生的实际变化。这样就产生了一种全新的数据生成技术,这种技术生成的数据会比基于仿射变换生成的增强数据更加逼真。
重建准确率在很多情况下也很重要,因此研究人员提出了一种从经验上讲很合适的策略,这种策略结合了可以显著提升重建性能的损失函数。该系统在每类样本只有 200 个数据点的情况下得到了和当前最佳结果相当的结果。如果用更多训练数据,可以得到更好的结果。
本文的主要贡献如下:
在所有可用训练样本上训练该系统后,在 EMNIST-letters、EMNIST-balanced 以及 EMNIST-digits 字符数据集上得到的结果都优于当前最佳结果;
研究人员还在非字符数据集 Fashion-MNIST 上评估了该架构,以确保模型的灵活性和鲁棒性。他们用 200 个训练样本得到了非常好的结果,并用完整的数据集得到了当前最佳的结果;
研究人员提出了一种用少量训练样本(每一类 200 个数据)训练胶囊网络的新技术,并在相同数量的测试样本上实现了当前最佳的性能。和当前最佳的系统相比,我们的模型只需要 10% 的数据就可以得到类似的结果;
研究人员还提出并评估了解码器网络的几个变体,用不同的损失函数分析了解码器网络的性能,以提供组合损失函数的适当策略。
论文:TextCaps : Handwritten Character Recognition with Very Small Datasets

论文地址:https://arxiv.org/pdf/1904.08095.pdf
摘要:尽管字符识别系统进展很快,但由于缺乏大量有标注的训练数据,很多本地化语言还是难以从中获益。这是因为这样的语言难以获得大量标注数据,而深度学习还无法通过少量训练样本正确学习。
为了解决这个问题,我们引入了一种根据现有样本生成新训练样本的技术。通过给相应的实例化参数添加随机可控噪声,这个新技术可以产生逼真的增强数据,这些增强数据也会反映出人类实际手写字符时会出现的一些变化。
我们只用每类 200 个训练样本的数据进行训练,就得到了超越基于 EMNIST-letter 数据集所获的现有字符识别的结果,同时还获得了与 EMNIST-balanced 、EMNIST-digits 以及 MNIST 这三个数据集相当的现有结果。
我们还开发了一种用损失函数组合有效改善重建能力的策略。我们的系统在缺乏大量标注训练数据的本地化语言的字符识别任务中很有用,甚至在其它相关的通用内容(比如目标识别)上也是如此。
用胶囊网络进行字符识别
我们提出了一种由胶囊网络和解码器网络组成且针对字符识别任务的架构,如图 1 和图 2 所示。
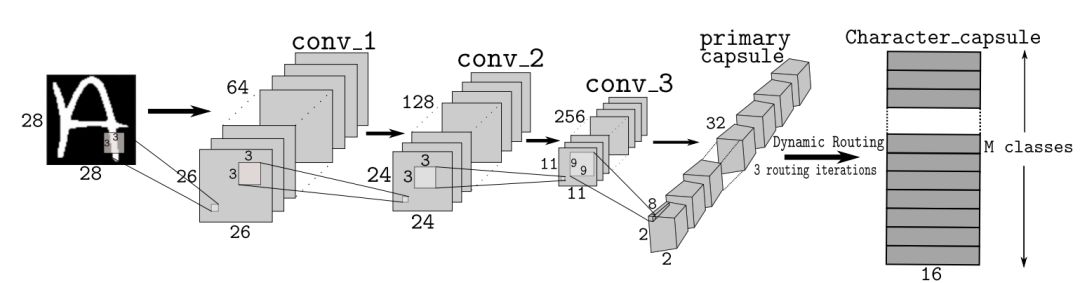
图 1:TextCap 模型:用于字符分类的 CapsNet 模型。

图 2:TextCap 解码器:用于字符重建的解码器网络。通过屏蔽 TextCap 分类器的 DigitCaps 层来获得网络的输入。
基于实例化参数扰动的图像数据生成技术
用预训练的解码器网络,我们可以只用实例化参数向量成功重建原始图像。该扰动算法背后的原理是,通过在实例化向量值中添加可控的随机噪声,我们可以创建和原始图像迥然不同的新图像,从而有效扩大训练数据集。
图 3 展示了改变一个特定实例化参数后产生的图像变体。
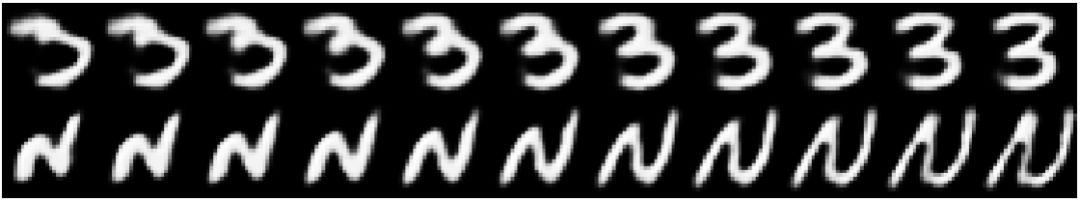
图 3:扰动实例化参数后产生的字符变体。
类似地,每一个实例化参数都分别或共同负责图像的某个特定属性。因此,我们提出了一种新技术,它可以根据训练样本有限的数据集产生新数据集,如图 4 所示。
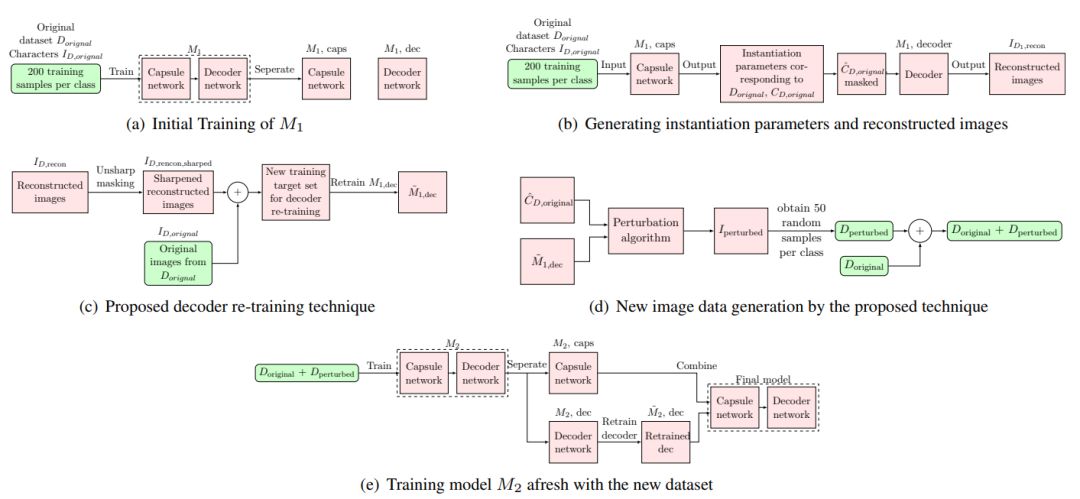
图 4:提升解码器性能的整体方法。
实验和结果
我们从表 1 中每个数据集的训练集中选取了 200 个训练样本来训练 TextCaps,并用每个数据集的完整测试集进行测试。为了测试 TextCaps 架构的性能,我们还用完整的训练集训练了模型,并用完整的测试集进行测试。
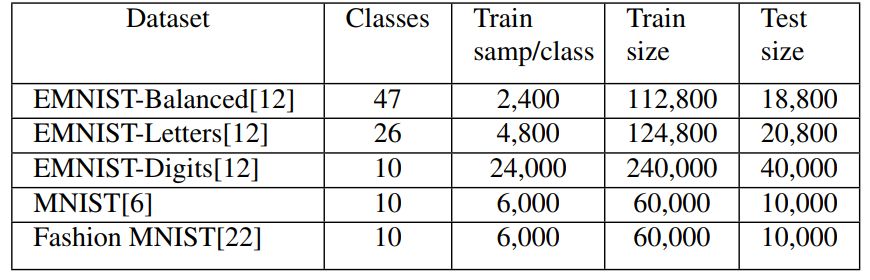
表 1:用于评估 TextCaps 的五个数据集。
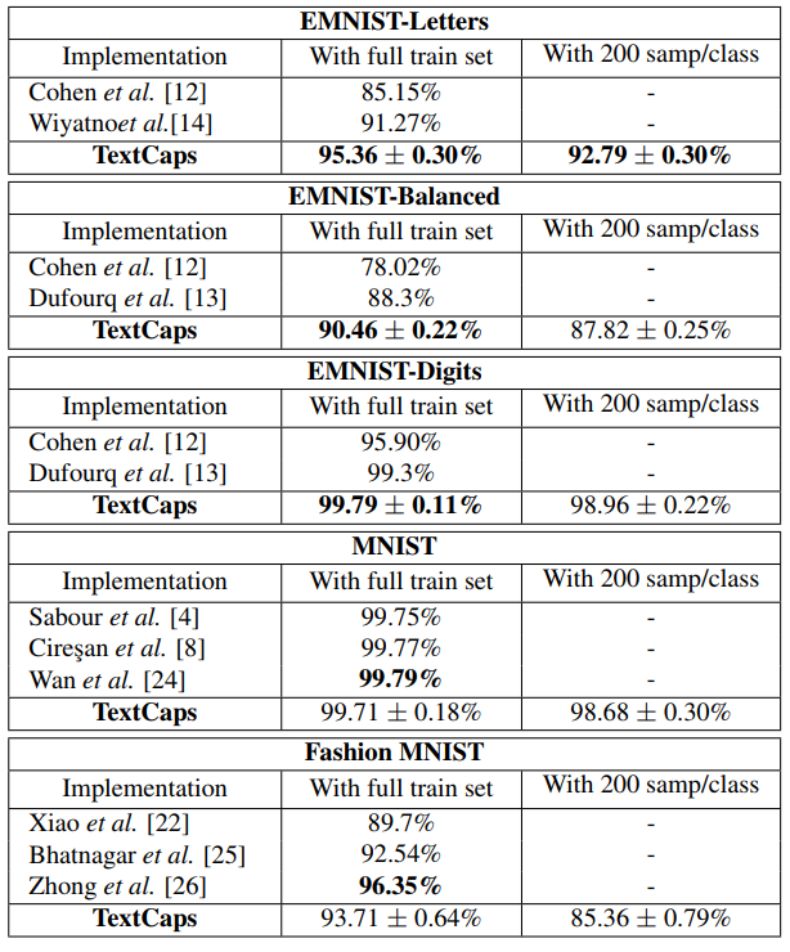
表 2:TextCaps 和当前最佳结果的比较,表中展示了 3 次试验的平均值和标准差。
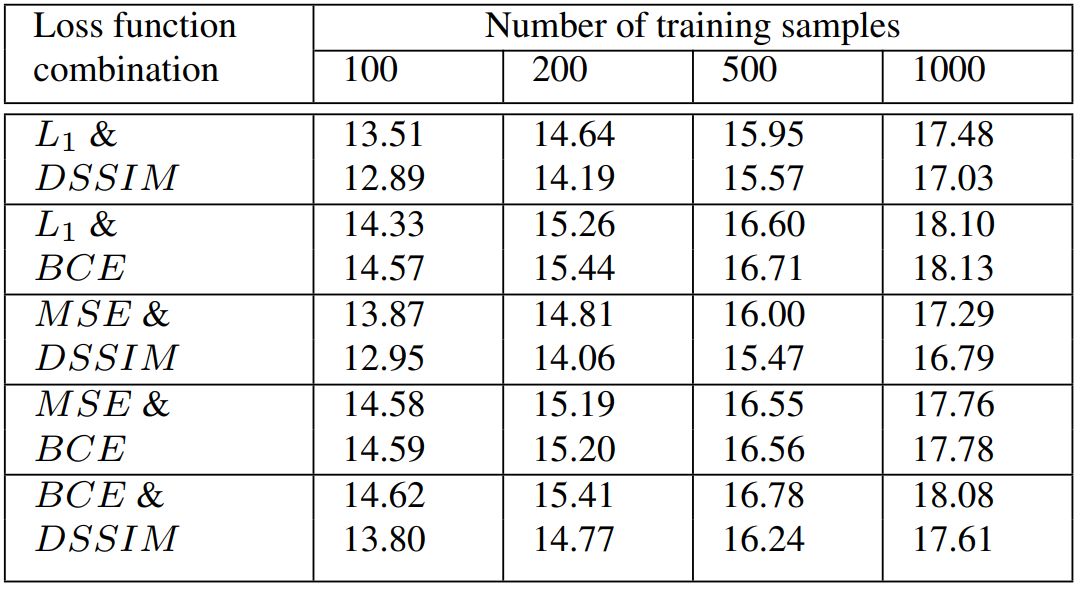
表 3:使用不同的损失函数组合时产生的每个重建结果的 PSNR 值。我们在这里用了两个解码器网络模型,每个解码器都有一个损失函数。对每一个损失函数组合来说,第一行的 PSNR 值对应第一个重建损失函数(用在第一个解码器中),第二行对应的是第二个损失函数(用在第二个解码器中)。

原文链接:https://arxiv.org/abs/1904.08095
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者 / 实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告 & 商务合作:bd@jiqizhixin.com

