MIT将开源OPAL:面对GDPR,安全的数据分享应该这样做!

更多干货内容请关注微信公众号“AI 前线”,(ID:ai-front)
在我们现今这个世界,大数据对于人们的生活无疑变得越来越重要。无论是最近几年火热的 AI,还是正在风口浪尖的新零售,又或者各种金融科技公司,以及各种 X 联网公司。支撑这些业务的延展性和想象空间的最为核心的要素,就是数据。
所以产生了这么一个说法:“数据是新的石油”。不过这句话可能只说对了一半,因为数据只有真正能够产生价值,才能成为“石油”。而让数据产生价值的前提条件,是数据需要能够被安全的分享、探索、加工,然后变成支撑业务价值的服务。可是由于前面提到的数据安全问题,以及对于拥有数据的企业如何保护数据资产的安全,这些都极大的阻碍了数据变成价值的过程。
面对这个挑战,很多企业和科研机构都在积极探索不同的方法,希望找到一条既能够保护数据隐私和资产安全,同时又能让数据能够更好的发挥自身价值的道路。来自于麻省理工学院连接科学研究所(MIT Connection Science)的“可穿戴设备之父”彭特兰教授(Alex Pentland)带领的一个团队,针对这个问题给出了自己的解决方案,那就是 OPAL-Open Algorithms(项目官网:https://www.trust.mit.edu/projects)。
OPAL 是 Open Algorithms 的简称,这个项目的最初目的是 MIT 为了能够使用野生动物相关的数据(比如位置数据)进行研究,同时又能够保证这些数据的安全,比如位置数据不会被泄露,避免野生动物的行踪被盗猎者发现。这个项目的核心理念如下:
将算法的执行放在数据侧。这意味着原始数据不需要离开数据拥有方,而开放出去的是对原始数据进行处理后的结果数据
算法可审查。由于算法是对数据的操作,因此算法需要接受审查,避免算法会泄露不该泄露的数据结果
数据一直处于加密状态
OPAL 的基础逻辑架构如下:
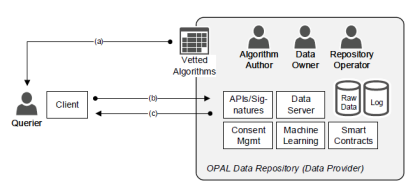
在这个架构中,包含如下几个角色:
Algorithm Author 是在数据集上面向业务问题进行算法和模型开发的人员,通常就是数据科学家。他们具备非常好的数据科学和算法背景,并且具备一定的领域知识,可以基于数据提供方提供的数据集,进行算法开发和模型构建。开发好的算法和模型被审核后,在 OPAL 框架的调度下,可以被 Querier 调用。
Querier 是希望用数据和模型解决问题的最终用户。Querier 会查询在 OPAL 框架保护下的数据集以及对应的 Vetted Algorithms(被审查过的算法),然后按照自自身需求来请求对 Vetted Algorithms 的访问,获取查询结果。
Data Owner 是数据的拥有者,数据拥有者希望能够在保护数据隐私、并且原始数据不泄漏的情况下,通过受审核的算法来获取数据价值。
Repository Operator 是 OPAL 服务的运营者,有可能是 Data Owner 自己,也有可能是一个数据联盟的运营者。通过运营 OPAL 服务,来保证数据拥有者的数据能够在被保护的情况下,实现数据价值的获取。
在整个架构中,有几个关键的模块,分别如下:
Vetted Algorithms 是被审查后,可以在数据集上进行运行的算法的列表库。每个需要被调用的算法或者模型,必须在审查后才可以进入 Vetted Algorithms,并且被 Querier 请求调用。
发起请求的客户端,选择合适的算法,按照协议的要求构造对应的算法请求,并且对请求签名,然后将请求发送给对应的数据提供方。
接受访问的 API 模块,并且对从 Client 过来的请求进行签名、以及算法的认证,并且将请求返回给 Client。
Data Server 是数据提供方提供数据的服务器,一般提供了进行模型训练或者提供模型运行时依赖的数据。
a)Querier 首先去 Vetted Algorithms 去查询一个数据提供方提供的被审查过的算法,选择一个或者多个算法。
b)Querier 会验证算法的签名,确定算法是由数据提供方或者算法提供方签名的算法,然后构造一个 OPAL 合约请求,这个请求含了算法 ID,然后将这个请求签名后发送给数据提供方。数据提供方会验证签名,然后在自己的数据集上执行算法。
c) 算法执行结束后,数据提供方会将结果构造成一个 OPAL 应答,进行数字签名后返回给请求者。
在前面提到了 OPAL 的逻辑架构以及对应的不同角色的定义,从这个逻辑架构中,我们可以比较清晰的理解 OPAL 的核心是为了数据安全,采用了模型在数据侧运行,而且通过模型的审查来保证模型不会泄露隐私数据或者数据提供方不愿意输出的数据。
在 MIT 提出 OPAL 框架后,有包括 TalkingData、NEC 等来自于工业界的公司加入到 OPAL 组织,从而能够将工业界的一些场景带入到 OPAL 中。同时 MIT Connection Science 也和帝国理工大学、Orange 通信、哥伦比亚电信以及全球经济论坛(WEF)等机构合作建立了 OPAL Project(https://www.opalproject.org),期望将 OPAL 打造为一个平台,在 OPAL 的保护下,利用电信运营商的数据来服务于政府和公共事业。
在这个项目中,采用的技术架构如下图:
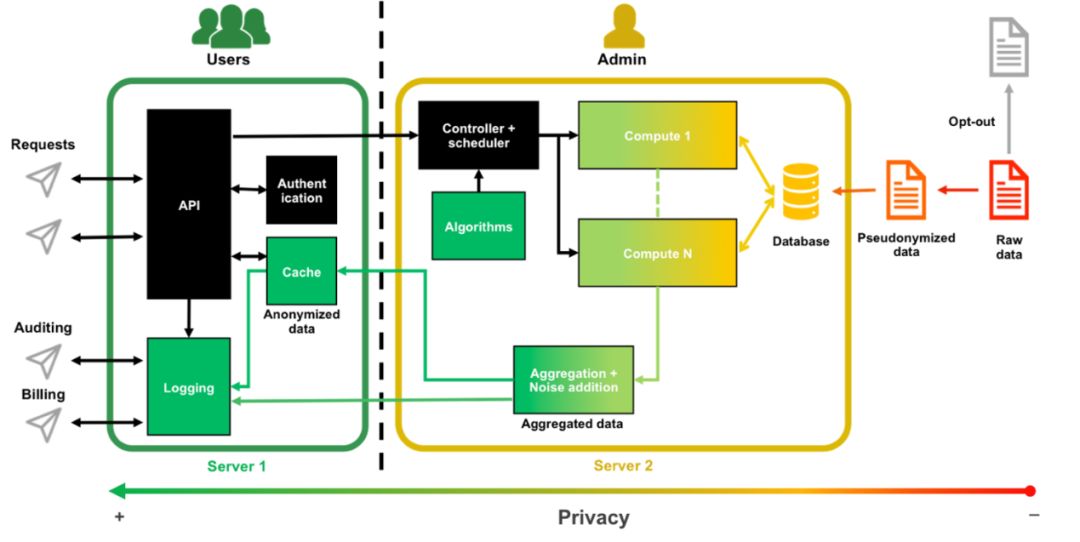
在这个具体实现 OPAL 的技术架构中,包含两大部分,分别是提供用户访问的用户部分以及提供算法调度和结果合并处理的管理部分。这个架构采用微服务架构,从而能够支持弹性扩充,并且可以对每个微服务进行单独的测试和持续集成。
整个架构包含的模块如下:
API 模块 – 由整个 OPAL 平台对外提供基于数据的公开可以访问的问答式 API。认证模块 – 对用户进行认证的模块,只有被认证的用户才能进行访问。
控制 / 调度模块 – 接收由用户发来的 API 请求,将 API 所对应的算法运行在对应的数据上,从而实现真正的计算。
数据注入模块 – 将数据提供者提供的数据在匿名脱敏后放入到 OPAL 的数据库中。这些数据一般是对原始日志数据进行处理后、便于算法或者模型运行的数据。对于一般的数据提供企业,属于 ETL 的工作。
数据库模块 – 在 OPAL 平台中算法模型运行以来的数据存储的数据库,一般为了性能考虑,要针对具体算法或者模型,选择合适的数据库。
汇聚服务模块 – 算法或者在模型执行的结果需要通过汇聚服务模块,由汇聚服务模块进行隐私数据的检查和过滤,同时通过差分隐私算法增加噪音,从而使得输出的结果不会泄露隐私。
缓存模块 – 缓存模块会将一些非常通用的算法和模型的结果缓存,从而能够提供用户访问 OPAL 平台时的性能。
审计模块 – 由于 OPAL 平台是面向不同用户提供在数据上执行算法模型的服务,因此对于从请求开始到结果返回的审计就变得非常的重要。审计模块会将每次的请求都记录审计日志,从而便于在未来进行问题追溯。
对于 OPAL 平台来讲,算法的执行采用 MapReduce 的思想,如下图:
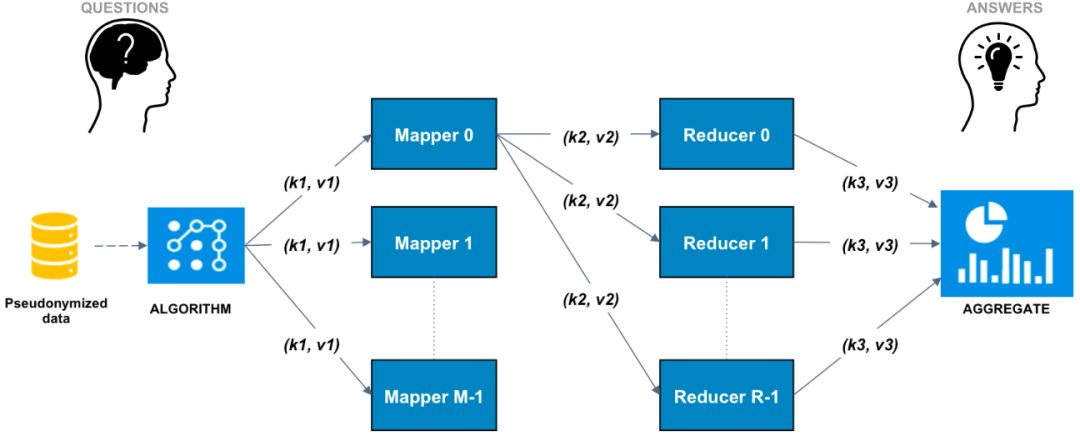
算法会在不同的数据记录或者数据集上分开执行,也就是 Map 过程。随后结果会 Reduce,最终形成一个汇集的结果,然后返回。
在 OPAL 的参考实现中,隐私保护主要通过三个方法来实现:
数据匿名化和算法审查 – 进入到 OPAL 平台的数据库中的数据必须要经过数据匿名化的处理,从而确保数据库中不存在隐私数据。而提供服务的算法需要通过审查,从而保证算法不会被用来获取隐私数据。另外,返回的结果通过汇聚服务模块,进行隐私数据的过滤和差分隐私处理,进一步保证结果数据的安全性。OPAL API – 通过 OPAL API 的访问控制,可以使得用户的请求在授权之后才能访问平台的 API,并且对于所有的访问都进行审计,从而进一步增加系统的安全。
网络安全 – 整个平台采用支持 TLS 的安全的网络协议,使得数据能够安全的传输。
前面提到的参考实现的架构,是 OPAL 项目为了验证 OPAL 思路而实现的最小原型法的架构,我们会看到整个架构还有很多不完善的地方,比如谁来进行算法的开发?如何进行算法的开发?算法开发后如何进入到算法库?如下是 OPAL 项目组对于未来架构的一个思考:
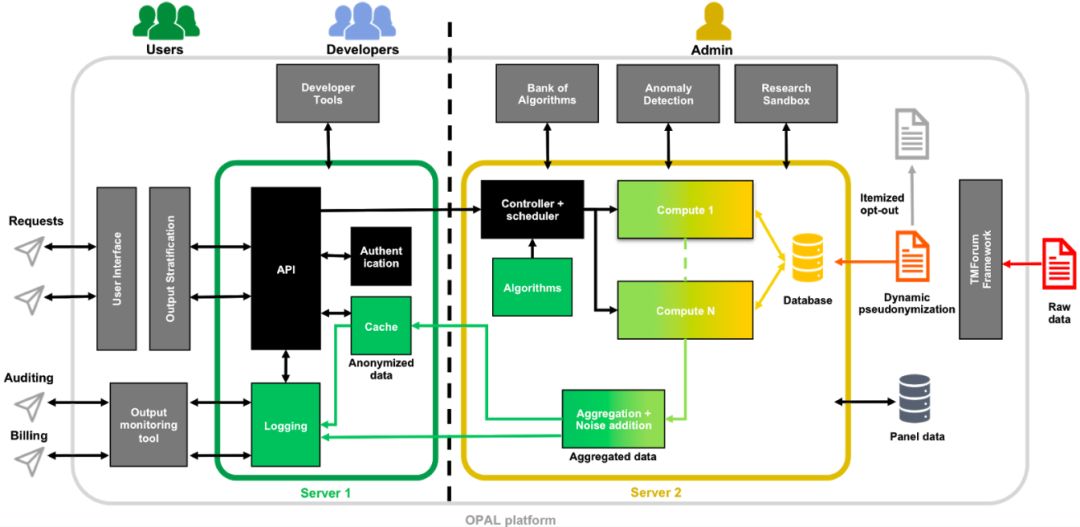
在这个架构中,比较值得注意的是引入了“开发者”的角色。开发者是基于数据进行算法模型开发的数据科学家。同时对平台也进行了增强,值得注意的增强模块包括:
开发工具 – 在这个架构中,引入了进行模型开发的开发工具。在真正的数据业务中,通常需要模型构建方基于数据提供方提供的数据进行算法模型的开发,因此开发工具就变得非常重要。
沙箱 – 在这个架构中,配合开发工具,还引入了沙箱模块。用于研究的数据可以先放到安全沙箱中,开发者可以利用开发工具对在沙箱中的数据进行研究探索,构建合适的模型。
算法银行 – 因为有了开发者这个角色,开发的算法实际上是数据商业化中的关键的一个环节,开发者开发的算法可以被审查后进入算法银行,实现算法的变现。
从前面介绍的关于 OPAL 的相关内容可以看到,由于数据本身包含着各种隐私、安全、合规等等问题,在目前对隐私安全越来越重视的大背景下,数据流动基本变成了一个不可能的任务。
将算法移动到数据侧去执行,将有价值的结果返回,而不是流动原始数据,就变成了一个现实可行的方案。MIT Connection Science 正在积极的完善 OPAL 的方案,同时也在积极与工业界的企业一起将方案在不同的场景中进行落地,不久的将来也会将 OPAL 开源。TalkingData 正在积极与 MIT 合作,努力将 OPAL 在国内落地。TalkingData 接下来会在数据智能市场中结合 OPAL 的能力,配合安全数据沙箱、数据科学平台和模型部署平台,希望能够给国内大数据的价值实现提供一套可行的技术方案。OPAL

如果你喜欢这篇文章,或希望看到更多类似优质报道,记得给我留言和点赞哦!



