你的模型可以轻松使用TPU了!DeepMind 开源分布式机器学习库TF-Replicator

新智元报道
新智元报道
来源:DeepMind
编辑:肖琴
【新智元导读】今天,DeepMind又放福利:开源了一个内部的分布式机器学习库TF-Replicator,可以帮助研究人员将TensorFlow模型轻松部署到GPU、TPU,并实现不同类型加速器之间的无缝切换。
最近 AI 领域的突破,从 AlphaFold 到 BigGAN 再到 AlphaStar,一个反复出现的主题是,对方便、可靠的可扩展性的需求。
研究人员已经能够获取越来越多计算能力,得以训练更大的神经网络,然而,将模型扩展到多个设备并不是一件容易的事情。
今天,DeepMind 又将其内部一个秘密武器公之于众 ——TF-Replicator,一个可以帮助研究人员将他们的 TensorFlow 模型轻松部署到 GPU、Cloud TPU 的分布式机器学习框架,即使他们之前完全没有使用分布式系统的经验。
TF-Replicator 由 DeepMind 的研究平台团队开发,初衷是为 DeepMind 的研究人员提供一个简单的接入 TPU 的 API,现在,TF-Replicator 已经是 DeepMind 内部最广泛使用的 TPU 编程接口。
TF-Replicator 允许研究人员针对机器学习定位不同的硬件加速器进行,将工作负载扩展到许多设备,并在不同类型的加速器之间无缝切换。
虽然它最初是作为TensorFlow上面的一个库开发的,但目前TF-Replicator的API已经集成到TensorFlow 2.0新的tf.distribute.Strategy中,作为 tf.distribute.Strategy的一部分开源:
https://www.tensorflow.org/alpha/guide/distribute_strategy
团队还公开了相关论文:TF-Replicator: Distributed Machine Learning for Researchers,全面描述了这个新框架的技术细节。
https://arxiv.org/abs/1902.00465
接下来,我们将介绍 TF-Replicator 背后的想法和技术挑战。
虽然 TensorFlow 为 CPU、GPU 和 TPU 设备都提供了直接支持,但是在目标之间切换需要用户付出大量的努力。这通常涉及为特定的硬件目标专门编写代码,将研究想法限制在该平台的功能上。
一些构建在 TensorFlow 之上的现有框架,例如 Estimators,已经试图解决这个问题。然而,它们通常针对生产用例,缺乏快速迭代研究思路所需的表达性和灵活性。
我们开发 TF-Replicator 的初衷是为 DeepMind 的研究人员提供一个使用 TPU 的简单API。TPU 为机器学习工作负载提供了可扩展性,实现了许多研究突破,例如使用我们的 BigGAN 模型实现了最先进的图像合成。
TensorFlow 针对 TPU 的原生 API 与针对 GPU 的方式不同,这造成了使用 TPU 的障碍。TF-Replicator 提供了一个更简单、更用户友好的 API,隐藏了 TensorFlow 的 TPU API 的复杂性。此外,研究平台团队与不同机器学习领域的研究人员密切合作,开发了TF-Replicator API,以确保必要的灵活性和易用性。
使用 TF-Replicator 编写的代码与使用 TensorFlow 中为单个设备编写的代码类似,允许用户自由定义自己的模型运行循环。用户只需要定义 (1) 一个公开数据集的输入函数,以及 (2) 一个定义其模型逻辑的 step 函数 (例如,梯度下降的单个 step):
# Deploying a model with TpuReplicator.repl = tf_replicator.TpuReplicator(num_workers=1, num_tpu_cores_per_worker=8)with repl.context():model = resnet_model()base_optimizer = tf.train.AdamOptimizer()optimizer = repl.wrap_optimizer(base_optimizer)# ... code to define replica input_fn and step_fn.per_replica_loss = repl.run(step_fn, input_fn)train_op = tf.reduce_mean(per_replica_loss)with tf.train.MonitoredSession() as session:repl.init(session)for i in xrange(num_train_steps):session.run(train_op)repl.shutdown(session)
将计算扩展到多个设备需要设备之间进行通信。在训练机器学习模型的背景下,最常见的通信形式是累积梯度 (accumulate gradients) 以用于优化算法,如随机梯度下降。
因此,我们提供了一种方便的方法来封装 TensorFlow Optimizers,以便在更新模型参数之前在设备之间累积梯度。对于更一般的通信模式,我们提供了类似于 MPI 的原语,如 “all_reduce” 和 “broadcast”。这些使得实现诸如全局批标准化之类的操作变得非常简单,这是扩展 BigGAN 模型训练的关键技术。
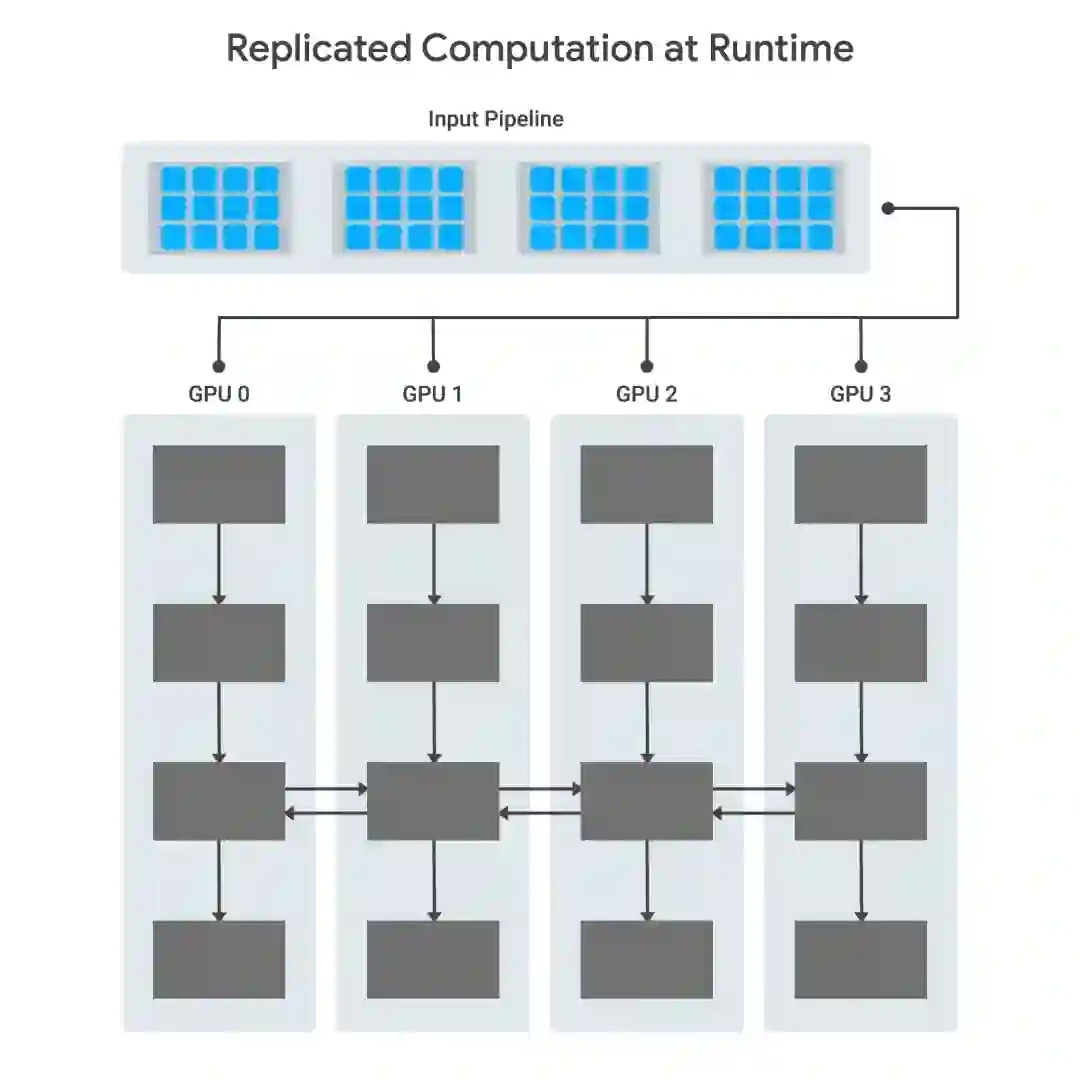
输入数据从主机发送到各个 GPU, GPU 立即开始处理。当需要在 GPU 之间交换信息时,它们会在发送数据之前进行同步。
对于多 GPU 计算,TF-Replicator 依赖于 “图内复制”(“in-graph replication) 模式,其中每个设备的计算在同一个 TensorFlow graph 中复制。设备之间的通信是通过连接设备对应子图中的节点来实现的。在 TF-Replicator 中实现这一点很具挑战性,因为在TensorFlow graph 中的任何位置都可能发生通信。因此,构造计算的顺序至关重要。
我们的第一个想法是在一个单独的 Python 线程中同时构建每个设备的子图。当遇到通信原语时,线程同步,主线程插入所需的跨设备计算。之后,每个线程将继续构建其设备的计算。
然而,在我们考虑这种方法时,TensorFlow 的图形构建 API 不是线程安全的,这使得在不同线程中同时构建子图非常困难。相反,我们使用图形重写 (graph rewriting) 在所有设备的子图构建完成后插入通信。在构造子图时,占位符被插入到需要通信的位置。然后,我们跨设备收集所有匹配占位符,并用适当的跨设备计算替换它们。

当 TF-Replicator 构建一个 in-graph replicated 计算时,它首先独立地为每个设备构建计算,并将占位符留给用户指定的跨设备计算。构建好所有设备的子图之后,TF-Replicator 通过用实际的跨设备计算替换占位符来连接它们。
通过在 TF-Replicator 的设计和实现过程中与研究人员密切合作,我们最终构建一个库,让用户能够轻松地跨多个硬件加速器进行大规模计算,同时让他们拥有进行前沿 AI研究所需的控制和灵活性。
例如,在与研究人员讨论之后,我们添加了 MPI 风格的通信原语,如 all-reduce。TF-Replicator 和其他共享基础架构使我们能够在稳健的基础上构建越来越复杂的实验,并在整个 DeepMind 快速传播最佳实践。
在撰写本文时,TF-Replicator 已经成为 DeepMind 应用最广泛的 TPU 编程接口。虽然这个库本身并不局限于训练神经网络,但它最常用来训练大量数据。例如,BigGAN 模型是在一个 512 核的 TPUv3 pod 训练的,batch size 为 2048。
在采用分布式 actor-learner 设置的增强学习智能体中,例如我们的重要性加权 actor-learner 架构,可扩展性是通过让许多 actor 通过与环境的交互生成新的体验来实现的。然后,learner 对这些数据进行处理,以改进 agent 的策略,表示为一个神经网络。为了应对越来越多的actor,TF-Replicator 可以很轻松地将 learner 分布在多个硬件加速器上。
这些以及更多例子在我们的 arXiv 论文中有更详细的描述。
Blog:
https://deepmind.com/blog/tf-replicator-distributed-machine-learning/
Paper:
https://arxiv.org/abs/1902.00465
更多阅读
【加入社群】
新智元AI技术+产业社群招募中,欢迎对AI技术+产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)



