推荐工业界大规模实战角度详解TensorFlow源码如何实现Wide & Deep模型(一)
作者:石塔西
来源:https://zhuanlan.zhihu.com/p/47293765
整理:深度传送门
背景
之前在一家公司做个性化新闻推荐,决定尝试一下Wide & Deep模型。当时的TensorFlow还没自带Wide & Deep实现,所以,我用TensorFlow从头到尾实现了一遍。Wide & Deep理论上并不复杂,我花了1天多,就用Keras搭建了一个原型系统。但是面对每天1T的日志,用Keras搭建的原型系统,训练一次(7天做train,一天做test)需要花费1.5天的时间,完全满足不了“每天更新模型”的需求。
接下来的时间,主要花费在提升这个模型的训练效率,实现了
稀疏矩阵相乘
数据输入时,用TensorFlow Data API代替最初的feed_dict
用TFRecords文件格式代替最初的csv来存储训练数据,并且实现在Hadoop上并发生成TFRecords数据文件
多进程并行:多个读进程将HDFS上的TFRecords下载到本地,一个进程负责训练
多GPU同时并行训练
通过以上改进,一次模型更新(7天日志做train,一天日志做test)的时间由原来的1.5天下降到不到4个小时,能够满足“每天更新模型”的需求了。
后来,新版本TensorFlow自带了DNNLinearCombinedClassifier实现了Wide&Deep模型,再使用Wide&Deep,只需要几行代码即可。而且,因为DNNLinearCombinedClassifier继承自Estimator,基类已经自动实现了如定时保存模型、重启后自动加载模型继续训练、自动保存metric供模型可视化、分布式训练等一系列的“小而重要”的功能,“一切都仿佛非常美好”。
最近才抽空阅读了一下DNNLinearCombinedClassifier的源码,摸清了TensorFlow实现Wide & Deep的思路,欣慰地发现在一些细节处理上,我当初的处理手法与TensorFlow是一致的。而且,通过阅读代码,也掌握了一些TensorFlow高级API的使用方法,便于我将来摆脱Estimator的限制,用TensorFlow底层API来实现更复杂的模型。
我将在这个系列,“提纲挈领”地解析TensorFlow DNNLinearCombinedClassifier源码代码,帮助感兴趣的同学理清Wide & Deep的实现脉络。这个系列计划分为3(+1)个部分:
第一部分,即本文,是一个开场白,并谈一下我对Wide & Deep的理解。我将包括Wide&Deep在内的”基于深度学习的推荐算法”总结成三个关键词:“记忆与扩展”、“类别特征”和“特征交叉”。个人以为,这三个关键词,基本刻画了推荐系统中深度学习算法的发展脉络。
第二部分介绍Feature Column。Wide&Deep本身没有什么,无非就是DNN+LR,精华在于特征工程,特别是对Categorical特征的处理。Feature Column实现了推荐算法常见的特征处理方法,是Wide & Deep(乃至其他DNN推荐算法)的基础。
第三部分介绍DNNLinearCombinedClassifier。在充分理解各个Feature Column之后,理解DNNLinearCombinedClassifier也就水到渠成。
最后,如果时间允许的话,我将把我的Wide&Deep代码,删除其中的业务细节并开源出来。尽管不如TensorFlow自带实现那般功能强大,但更加清晰易读,对初学者掌握如何用tensorflow实现一个企业级的系统,还是有帮助的。
本文假定读者已经理解Wide & Deep的算法思路,并且熟悉TensorFlow Estimator API。对于不熟悉Wide & Deep的同学,请参考《Wide & Deep Learning for Recommender Systems》这篇论文。对于不熟悉Estimator API的同学,请参考TensorFlow Guide相关文档。
Wide & Deep的三个关键词
这个系列的重点是Wide & Deep的实现,但是在正式介绍如何实现之前,我想先谈一谈我对包括 Wide & Deep 在内的“基于深度学习的推荐算法”的理解,与感兴趣的同学一同探讨。毕竟,如何实现是“术”,而掌握技术脉络才是“道”。
我用三个关键词:“记忆与扩展”、“类别特征”和“特征交叉”,来描绘推荐算法的发展脉络。沿着这一脉络,结出了Wide&Deep, FM/FFM/DeepFM, Deep&Cross Network, Deep Interest Network等果实。
记忆与扩展
Wide&Deep全文围绕着“记忆”(Memorization)与“扩展(Generalization)”两个词展开。实际上,它们在推荐系统中有两个更响亮的名字,Exploitation & Exploration,即著名的EE问题。
论文中说,Wide侧用于“记忆”。那Wide侧能记住什么?我们又该将什么样的特征输入wide侧?
我的理解是:Wide侧记住的是历史数据中那些常见、高频的模式,是推荐系统中的“红海”。实际上,Wide侧没有发现新的模式,只是学习到这些模式之间的权重,做一些模式的筛选。正因为Wide侧不能发现新模式,因此我们需要根据人工经验、业务背景,将我们认为有价值的、显而易见的特征及特征组合,喂入Wide侧。
比如对电商网站,将<中国人,春节,饺子>、<美国人、感恩节、火鸡>、<夏天、冰欺凌>都是历史常见模式,匹配上任何一条,都有推荐价值,至于价值多少?在推荐列表中排名如何?就是Wide侧学习到的权重决定的了。
而一个推荐系统不能只给用户推荐他已经买过的东西,不能推荐他已经阅读过的文章,而要能替用户发现他的兴趣。这就需要推荐系统能够从历史数据中发现低频、长尾的模式,发现用户兴趣的“蓝海”,即具备良好的“扩展”能力。
还以电商为例,历史数据中只有<中国人,春节,饺子>、<美国人、感恩节、火鸡>、<夏天、冰欺凌>这样的历史记录。如果推荐系统只会“记住”,那么<中国人,感恩节,火鸡>的组合,因为和所有历史记录都不匹配,推荐系统只能打0分,将不会推荐给中国用户,从而失去了开发“中国人喜欢赶时髦过洋节”这一“蓝海”的机会。
而Deep侧,通过embedding+深层交互,能够学到国籍、节日、食品各种tag的最优的向量表示,推荐引擎给<中国人,感恩节,火鸡>这种新组合,可能会打一个不低的分数(比<美国人、感恩节、火鸡>打分低,而比<中国人、感恩节、冰激凌>打分高),从而有机会推荐给中国用户。简单来说,Deep侧是通过embedding将tag向量化,变tag的精确匹配,为tag向量的模糊查找,使自己具备了良好的“扩展”能力。
类别特征
深度学习的这一波热潮,发源于CNN在图像识别上所取得的巨大成功,后来才扩展到推荐、搜索等领域。但是实际上,推荐系统中所使用的深度学习与计算机视觉中用到的深度学习有很大不同。其中一个重要不同,就是图像都是稠密特征,而推荐、搜索中大量用到的是稀疏的类别/ID类特征。Google在其著名的《Ad Click Prediction: a View from the Trenches》一文中提到,因为稀疏/稠密的区别,CNN中效果良好的Dropout技术,运用到CTR预估、推荐领域反而会恶化性能。
相比于实数型特征,稀疏的类别/ID类特征,才是推荐、搜索领域的“一等公民”,被研究得更多。即使有一些实数值特征,比如历史曝光次数、点击次数、CTR之类的,也往往通过bucket的方式,变成categorical特征,才喂进模型。
推荐、搜索喜欢稀疏的类别/ID类特征,我觉得有三方面的原因:
LR, DNN在底层还是一个线性模型,但是现实生活中,标签y与特征x之间较少存在线性关系,而往往是分段的。以“点击率~历史曝光次数”之间的关系为例,之前曝光过1、2次的时候,“点击率~历史曝光次数”之间一般是正相关的,再多曝光1、2次,用户由于好奇,没准就点击了;但是,如果已经曝光过8、9次了,由于用户已经失去了新鲜感,越多曝光,用户越不可能再点,这时“点击率~历史曝光次数”就表现出负相关性。因此,categorical特征相比于numeric特征,更加符合现实场景。
推荐、搜索一般都是基于用户、商品的标签画像系统,而标签天生就是categorical的
稀疏的类别/ID类特征,可以稀疏地存储、传输、运算,提升运算效率。
但是,稀疏的categorical/ID类特征,也有着单个特征表达能力弱、特征组合爆炸、分布不均匀导致受训程度不均匀的缺点。为此,一系列的新技术被开发出来:
算法上,FTRL这样的算法,充分利用输入的稀疏性在线更新模型,训练出的模型也是稀疏的,便于快速预测。
Parameter Server这样的分布式系统被开发出来,充分利用特征的稀疏性,不必在各机器之间同步全部模型,而让每台机器“按需”同步自己所需要的部分模型权重,“按需”上传这一部分权重的梯度,提升了分布式计算的效率。
接下来要介绍的TensorFlow Feature Column类,除了一个numeric_column是处理实数特征的,其实的都是围绕处理categorical特征的,封装了常见的分桶、交叉、哈希等操作。
特征交叉
上文所述,推荐/搜索系统中大量运用的是categorical/ID类特征,但是单个categorical/ID特征,其表达能力又是极弱的,因此,必须做特征交叉,以增强categorical特征的表达能力。而围绕着如何做特征交叉,衍生出各种算法。
假设将所有categorical特征都按照One-Hot-Encoding(OHE)展开后,一共有n个特征,可想而知,这个特征矩阵是大而稀疏的。
如果在普通的LR中直接加入特征交叉,即使只考虑二项式交叉(如下所示),那也要学习1(bias)+n(一次项)+1/2*n(n-1)(二次项)=1+n+0.5n(n-1)个权重。计算量大,容易过拟合,而且大量的交叉项 
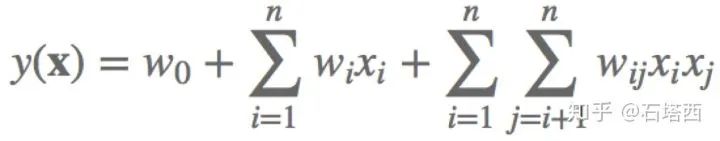
为此,发明了Factorization Machine(FM)算法。第i维特征,对应一个k维隐向量 

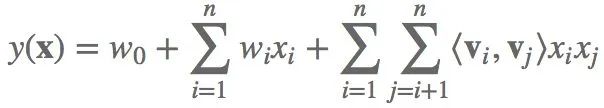
FM的优势:
将需要优化的权重,由1+n+0.5n(n-1)减小到1+n+n*k,而k<<n,即减少了计算量,也降低了过拟合的风险。
公式(1)中只有
都不为0,
才有训练的机会。而在FM公式中,所有
的样本都可以训练
,而所有
的样本都可以训练
,权重得到训练的机会大大增加。




FM一般只限于二次特征交叉。而深度神经网络(DNN)先将categorical/id特征通过embedding映射成稠密向量,再喂入DNN,让DNN自动学习到这些特征之间的深层交叉。
本系列关注的Wide&Deep是DNN+LR的结合。
Wide侧就是普通LR,一般根据人工先验知识,将一些简单、明显的特征交叉,喂入Wide侧,让Wide侧能够记住这些规则。
Deep侧就是DNN,通过embedding的方式将categorical/id特征映射成稠密向量,让DNN学习到这些特征之间的深层交叉,以增强扩展能力。
如上所述,Wide&Deep中Wide侧还需要人工构造特征交叉,而DeepFM在Wide侧用一个FM模型替换了LR,能够自动学习到所有二次交叉项的系数。
关键在于Deep侧与Wide侧共享一个embedding矩阵来映射categorical/id特征到稠密向量
Deep侧将embedding结果喂入DNN,来学习深层交互的权重,着重“扩展”
Wide侧将embedding结果喂入FM,来学习二次交互的权重,着重“记忆”
以上介绍的Wide&Deep, DeepFM都用一个DNN来学习特征之间的深层交互。但是这种所谓的“深层交互”是隐式的,比如我们不知道DNN学到的到底是哪些特征的几阶交互。Google的Deep&Cross Network允许显式指定交叉阶次,并高效地学习。
小结
这个系列解析TensorFlow自带的Wide & Deep实现。本文是这个系列的第一篇,重点介绍了“记忆与扩展”、“类别特征”和“特征交叉”三个关键词,借助这三个关键词,梳理了“基于深度学习的推荐算法”的发展脉络。
下一篇文章,将介绍推荐、搜索中常见的特征工程方法,并且看TensorFlow Feature Column是怎么实现的。
本文转载自公众号:深度传送门,作者 石塔西
推荐阅读
大幅减少GPU显存占用:可逆残差网络(The Reversible Residual Network)
AINLP-DBC GPU 云服务器租用平台建立,价格足够便宜
我们建了一个免费的知识星球:AINLP芝麻街,欢迎来玩,期待一个高质量的NLP问答社区
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。



