新智元专访CVPR2019程序主席微软华刚 :arXiv让双盲评审形同虚设,单纯刷分把研究机械化,暴力化
新智元原创
作者:闻菲
新智元启动 2017 最新一轮大招聘: COO、总编、主笔、运营总监、视觉总监等8大职位全面开放。
新智元为COO和执行总编提供最高超百万的年薪激励;为骨干员工提供最完整的培训体系、高于业界平均水平的工资和奖金。加盟新智元,与人工智能业界领袖携手改变世界。
简历投递:jobs@aiera.com.cn HR 微信:13552313024
【新智元导读】CVPR 2019程序主席微软首席研究员华刚博士近日接受了新智元的独家专访,谈到了当前学术界的一些流行趋势和问题所在。 华刚博士在肯定arXiv加速学术交流的同时,一针见血地指出,“arXiv让学术会议的双盲评审形同虚设”,arXiv上的论文质量也是“鱼龙混杂”。他在访谈中分享了地计算机视觉研究情况的观察,认为预期3个方向近两年会有发展:一是基于图像、视频建模的无监督学习;二是基于任务的视觉建模机制;三是基于知识和小样本学习进行视觉建模。
“微软研究院的实力核心在于人才,以及能够自己培养人才、让年轻人快速成长的能力。”微软研究院首席研究员华刚博士在接受新智元专访时说。当前人工智能人才竞争激烈,微软成为巨头“挖角”最佳目标,腾讯甚至把研究院开到了西雅图微软研究院家门前——马化腾公开坦承,这是因为很多微软研究员不愿意离开西雅图。因此,“微软如何应对AI人才流失?”成了不可避免的问题。而华刚博士的回答则令人顿感“AI黄埔军校”的气度和风范。

作为CVPR 2019的程序主席,CVPR 2017和ICCV 2017的领域主席,华刚表示他很高兴看到在本届CVPR上出现了不少尝试进一步理解深度学习在解决计算机视觉问题中的工作机制,和将计算机视觉领域知识用于指导深度学习的论文。去年,新智元报道CVPR 2016时,提到了法国 Inria 研究所的研究员 Nikos Paragios 对深度学习“一统天下”的担忧,Paragios 撰文指出:2016年各个研究都专注于使用深度学习的方法解决计算机视觉问题,口头报告更是接近100%都来自深度学习领域;虽然这样做没有问题,这些论文也都体现了实力,但Paragios想知道这些研究“增加的”科学价值在哪里。华刚博士在接受新智元专访时也表示了同样的担忧,他多次提到“多样化”、“深度学习结合传统方法”以及“老树开新花”,希望看到更多新的技术和新的思路。
作为CVPR 2019的程序主席,华刚预测未来两年图像视频理解相关的研究仍然会是计算机视觉领域的热点,其中:①基于图像、视频建模的无监督学习;②基于任务的视觉建模机制;以及③基于知识和小样本学习进行视觉建模这3个领域会有所发展。更远一些,语音、图像等人工智能的各个子领域会有相互融合的趋势,因为“要做一个AI系统,它必定是多模态的,多个层面多种模块的系统结合”。
arXiv虽然是一个非同行评议论文库,但其活跃度让如今大多数研究人员都把arXiv作为一个定期跟踪的信息源。但是,身为多个学术会议的主席以及多本学术期刊的编委,华刚博士在肯定arXiv加速学术交流的同时,一针见血地指出,“arXiv让学术会议的双盲评审形同虚设”,arXiv上的论文质量也是“鱼龙混杂”。
“单纯的刷分是对研究的暴力化、机械化”,“为了写论文而刷分是没有意义的”,开玩笑自称“70后”的华刚博士说,他认为研究是一项高尚的职业,他选择留在微软研究院的原因也很简单——开心,每天都能学到新的东西。最近,他对计算机视觉技术的商业应用也产生了兴趣,认为现在是“很好的时机”。早在2008年就创立和奠定了微软的人脸识别引擎(现已进一步发展并整合成为微软认知服务的Face API),并因对图像和视频中无限制环境人脸识别研究做出杰出贡献而在2015年被国际模式识别联合会(International Association on Pattern Recognition,IAPR)评为“生物特征识别杰出青年研究员”,华刚博士在谈到他对人脸识别的商业应用时说:“前段时间不是有新闻说在天坛公园卫生间安装人脸识别机吗?抛开别的不谈,我从这个事件中看到了巨大的商机(笑)。”
介绍微软在本届CVPR的表现时滔滔不绝,但说起CMU的精彩论文也毫不吝啬赞美之词,这就是微软研究院首席研究员华刚。本文带你走近这位CVPR 2019程序主席以及CVPR 2017和ICCV 2017领域主席,谈谈他心目中的微软研究院、学术会议,还有计算机视觉技术、应用及发展。
华刚博士的研究重点是计算机视觉、模式识别、机器学习,人工智能和机器人,以及相关技术在云和移动智能领域的创新应用。他是通过对语境建模使用弱监督或者无监督方法解决无限制环境下计算机视觉问题的倡导者,其研究在学术界和工业界都产生了广泛的影响。华刚博士在2008年创立和奠基了微软的人脸识别引擎,现在已发展成为微软认知服务(Cognitive Services)中的人脸识别应用程序接口(Face API)。
在学术方面,华刚博士已在国际顶级会议和期刊上发表了130多篇同行评议论文。他将担任CVPR 2019的程序主席,以及CVPR 2017和ACM MM 2017的领域主席。不仅如此,华刚还担任过CVPR 2015、ICCV 2011、ACM MM 2011/ 2012/ 2015、ICIP 2012/ 2013/ 2015、ICASSP 2012/ 2013等十多个顶级学术会议的领域主席,以及IEEE Trans. on Image Processing(2010-2014)的编委。目前,华刚博士还担任着IEEE Trans. on Image Processing、IEEE Trans. on Circuits Systems and Video Technologies、IEEE Multimedia、CVIU、MVA和VCJ的编委。
2011年,华刚博士在国际顶级期刊IEEE Trans. on Pattern Analysis and Machine Intelligence(IEEE模式分析和机器智能汇刊)领导组织的“现实世界人脸识别”专刊,对推动无限制环境下人脸识别的研究产生了深远的影响。因其在图像和视频中无限制环境人脸识别研究所做出的杰出贡献,2015年华刚博士被国际模式识别联合会(International Association on Pattern Recognition,IAPR)授予“生物特征识别杰出青年研究员”。2016年,华刚博士被评选为IAPR会士(IAPR Fellow) 和 ACM杰出科学家 (ACM Distinguished Scientist)
|
新智元:微软被誉为“AI黄埔军校”,当前巨头间人才竞争激烈,微软成为“挖角”最佳目标,腾讯甚至把研究院开到西雅图的微软对面。您为什么选择继续留在微软?在人才的吸收、培养和保留方面,您认为微软如何保有竞争力?
华刚:我选择留在微软,主要还是喜欢这里耐心、包容、重视人才的氛围。能在一个开放、多样化的环境里工作,每天都能学到新的技能,我觉得很开心。在微软的研究院,年轻人成长速度一般都比较快,这也是因为院里对员工重视程度很高, 给予员工比较大的自由成长的空间,和各方面技能培训的机会。我是“70后”,觉得研究是高尚的职业,但现在年轻人成长环境不同,选择也跟我们当初有很大变化。例如,很多年轻人毕业就选择出来创业,这也许是社会、经济发展的必然,这是正常的现象。不过,微软研究院的优势在于能够自己培养人才,这个核心能力很关键,我们能吸引和培养对研究真正感兴趣的人。当然,我们也跟产品部门有深入的沟通——计算机视觉是微软研究院成立最早的一个研究方向,微软会在计算机视觉方面的研究和相关产品的开发上持续投资。微软亚洲研究院的计算视觉组也会两条腿走路,对学术界和对微软本身视觉相关的产品持续地做出贡献。作为一名研究员,能看到自己做的事情产生影响(impact),比如用在了产品里,或者获得了某个会议的最佳论文,又或者技术被很多人使用,这些都让人充满成就感。
新智元:您怎么看以arXiv为代表的这类非同行评议的论文库,以及将论文上传到arXiv这种行为?媒体应该如何对待arXiv上的论文?
华刚:在2015年以前,我是从来没有把论文发布到arXiv上的。实际上,我所认识的很多稍微传统,或者“老派”(笑)一点的研究员,都不会将论文在同行评议完成之前过早的发布到arXiv上。不过,2016年起,我和一些同事也会把尚未发表但相对成熟的工作发布到arXiv上。这样确实加快了交流讨论的速度,但由于没有经过同行评议,所以,arXiv上论文的质量鱼龙混杂,其中有些论文的观点是不一定正确的,或者带有偏见的。如果媒体希望报道arXiv上没有经过同行评议的论文,而编辑部本身没有专业领域的研究人员,我的建议是综合作者提供的信息,以及各个论坛像Hacker News、Reddit、Twitter的讨论,如果有条件还应该邀请几位相关领域的专业的研究人员写评论,尽可能的将信息客观、全面的地传达给读者,避免产生误导。
新智元:最新一期Science封面论文Deep Stack,也是很早就上传到arXiv了。
华刚:这稍微有些不同。期刊评议是单盲,评审人知道作者,作者不知道评审人是谁,因此上传到arXiv也不会有多大的影响。因为期刊论文评议可以有评议完成之后大修和小修的周期。相比之下,学术会议采用双盲同行评议,评审人和作者彼此都不知道谁是谁,尽管现在很多会议也有作者答辩评审这一环节,会议论文评审结果从本质上来讲还是“一锤子买卖”,因此评议也会更为凌厉直接。关于arXiv,我最主要的意见是,由于论文上传以后作者姓名是公开的,这样很多会议如CVPR双盲评审形同虚设。2015年,德国马克思普朗克研究所的Michael Black教授(他也在布朗大学任职多年)曾经提出动议并被PAMI-TC通过——凡是和媒体讨论过并进行过宣传的论文一律该被CVPR给拒绝掉,因为这直接影响了双盲的同行评议公正性,为评议过程带来了不必要的额外的偏差(bias)。(参见:http://www.cv-foundation.org/CVPR2015/tc_meeting_060915_presentation.pdf)
新智元:您是CVPR 2019的程序主席(Program Chair),您和bidding团队拿下CVPR 2019主办权的原因是什么?作为CVPR 2019程序主席,您对会议有什么规划?
华刚:实际上CVPR、ICCV的管理是通过一个松散的,非常民主化的学术组织,叫做PAMI-TC(Technical Committee on Pattern Analysis and Machine Intelligence)的委员会完成的。要做会议的主办方,需要在当年会议开始前提前一个月申报去申请三年后的举办权,PAMI-TC组委会的成员现在通过网络投票(早年就是开会现场大家举手投票,有很多有趣的故事),多的时候会有3到4个团队在争取。申请2019年CVPR的主办权的是我们团队和另一个团队,我们能够拿下的原因主要有3点:第一是团队强,我们的团队成员里有很多知名、资深的学术代表;第二是我们充分考虑到了多样性,不仅有领域非常资深的研究员,也有领域里面在职业中期的中坚力量,和不少学术新星。有来自各大洲的代表,也有很多女性成员;第三则是我们有为领域服务好的责任心,并制定了周详的组织计划,提前预计到很多可能出现的困难以及解决方案。举例来说,2003年是我第一次参加CVPR,那时候的参会人数大约是900,到2016年时CVPR的参会人数已经达到3000人了。我们估计到CVPR 2019,参会人数有5000人的规模,因此特地选择了美国长滩的会馆,能够容纳下这么多人。
还有一点,在各个学术会议中,CVPR的参会注册费实际上是最低的,学生注册费大体上在300美元左右,研究员则在600~700美元的样子——其他学术会议这个价格都会上千。因为洛杉矶地区的餐饮相对便宜,我们团队预计在CVPR 2019能够覆盖参会者的餐费,也就是可以免费的提供早中晚餐给参会者提供。因此,从组织团队成员背景、多样性以及办会地点实际情况调研等多个方面,我们都做了周全的考虑,这就是我们获得主办权的原因。大家可以参看我们争取CVPR 2019举办权的报告(http://www.cv-foundation.org/CVPR2019/Long_Beach_for_CVPR19.pdf)。
当然,我们能够得到主办权也离不开华人学生、学者的支持。如今,参加CVPR的华人学生、学者实际上已经超过总人数的50%。但是,在各个主席职位,比如领域主席(area chair)、程序主席(program chair),还有大会主席(general chair)这些位置上,华人学者并不多,至少从参会人数应有的比例上看是远远不够的。我们主办CVPR 2019,其中一点也是希望进一步提高和展现华人的工作和领导能力。
至于在CVPR 2019特别想做的,就是为大家呈现一个优秀的,让大家满意的计算机视觉的学术盛会,期望看到更多新思维、新方法以及新老方法的相互融合。著名法国学者Nikos Paragios,《计算机视觉与图像理解》期刊(Computer Vision and Image Understanding Journal,CVIU)的主编(华刚博士是CVIU的编委),他在LinkedIn上写了一篇文章,我印象很深。Paragios在文中提到,以前的计算机视觉是很包容的,会议上能看到各种方法,比如统计、几何、代数……都有,氛围十分活跃,参加这样一次会议,能得到计算机视觉技术的现状、问题及发展比较综合的理解。但是,深度学习出现以后,大有一统天下之势,这不一定是好事。其中,也包括有些好的想法被深度学习这一波浪潮所淹没。
新智元:您是指这样的情况吗——有论文提出了新的想法,但由于种种原因结果并不出彩,或者在现有条件下论证还没那么充分;而使用深度学习方法的论文做出的效果很好,或者在各项基准测试都取得了当前最好的结果,于是,后者被接收,而前者被拒绝了?
华刚:这是其中一种。深度学习在计算及视觉领域这一波的浪潮是从2012年开始兴起的。那么2012年以后进入计算机视觉领域的学生,按照时间来讲,今年正好是博士毕业。这一批人会慢慢成为会议审稿的主要力量,由于接受的训练主要以深度学习为主,就可能会进一步产生这种倾向。这类审稿人对问题理解的深度,还有思维模式(mindset)需要重塑。现在我们对深度学习的局限性也有了更全面的认识,这也是为什么我说要多看10年、20年前论文的原因。
新智元:您对计算机视觉技术未来2年的发展有什么预期——作为CVPR 2019的程序主席,您需要掌握领域的总体发展趋势,深度学习、神经网络还会继续盛行吗?您认为什么技术和研究方向会成为届时的热点?什么新技术会崛起?什么现在尚未解决的问题到时候有可能被攻克?
华刚:这个问题提得很好。就像我以前说过的一样,研究的英文是“Research”,也就是“Re-Search”——再搜索。有时候,完全脱离领域历史沿革的全新(brand-new)技术的出现是很少的。任何新的研究工作和思想,或多或少都会受到前人的工作和思想的影响。就如牛顿说的,“我比别人看到更远,是因为我站在巨人的肩膀上”。我想一个健康的研究领域,更多还是要一种多样性的融合,共同推动领域发展,比如将深度学习和以前的方法相结合,所谓“老树开新花”。什么技术或方向会成为热点?谈一个我个人感兴趣的方向吧:知识描述、知识表征,也就是用语言的方式将视觉内容表征出来,成为知识的一种载体,来更好的解决计算机视觉的问题。就好比人类使用语言可以传递信息和知识,只有有了对知识的表征,智能体相互之间才能沟通学习。不过,要完成这个项目,两年的时间估计不够(笑)。
宽泛一些来说,我认为以下3个方面在接下来两年会有所发展:
一是基于图像、视频建模的无监督学习;
二是基于任务的视觉建模机制;
三是基于知识和小样本学习进行视觉建模。
这3点的排列也是由易到难,基于“任务”就是理解有一个明确的目标,而基于“知识”则是知道该怎么去做这件事。打个比方,两者的区别就像是知道了“授人以鱼”和“授人以渔”中的“鱼”和“渔”。总之,最终的目标都是朝着一个综合、集成的智能系统去服务。
新智元:您是这届CVPR的领域主席(area chair)。现在CVPR 2017接收论文已确定,能透露一下这届会议从论文中体现出了什么趋势吗,果然深度学习、神经网络还是关键词?有什么其他亮点吗?
华刚:这届CVPR 我是领域主席,每个领域主席可以选择自己感兴趣和负责的研究议题(topic)——我的研究兴趣和研究方向比较广,所以大概覆盖了30多个topic中的10多个,我在评审过程中全权负责的论文有三四十来篇,加上评议圆桌讨论和别的领域主席复议的论文,了解到的论文大约只占最后全部接收论文的1/6~1/5。令人欣喜的是,这届CVPR涌现了很多结合领域知识(domain knowledge)尝试去理解、去反思深度学习机制的论文。不过,让我现在谈CVPR 2017的整体论文体现了什么趋势、有什么亮点,这还得等到会议开始后才能知道。
新智元:那在您所了解的范围内,有什么研究让您印象特别深刻吗?
华刚:CMU有一篇估计运动姿态的论文,里面的Demo给我们领域主席圆桌讨论复议时留下了非常深刻的印象,实现了多线程的多人关键点实时检测,将同一个视频里很多人的运动姿态都同时捕捉下来。这篇论文也是CVPR 2017口头汇报的论文之一,其代码赢得了2016年MSCOCO关键点挑战赛以及2016年ECCV最佳演示奖。论文提出了一种自下而上的方法进行多人姿态估计,而不需要任何行人检测的算法。
摘要
我们提出了一种有效地检测图像中多个人 2D 姿态的方法。该方法使用非参数表征,我们将其称为部分亲和字段(PAF),能够学习将身体部分与图像中的个体关联起来。该架构对全局环境进行编码,允许一个贪心的自下而上的解析步骤(parsing step),保持高精度的同时,实现实时性能,无论图像中的人数有多少。这一架构旨在通过同一个顺序预测过程的两个分支,联合学习局部位置及其关联。我们的方法在 COCO 2016 关键点挑战赛中取得了第一名,与 MPII MultiPerson 基准此前最好的结果相比,我们的方法在性能和效率上都高出很多。 |

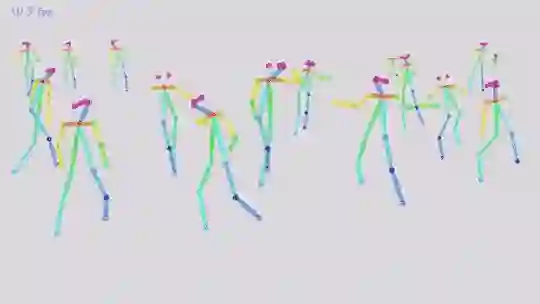
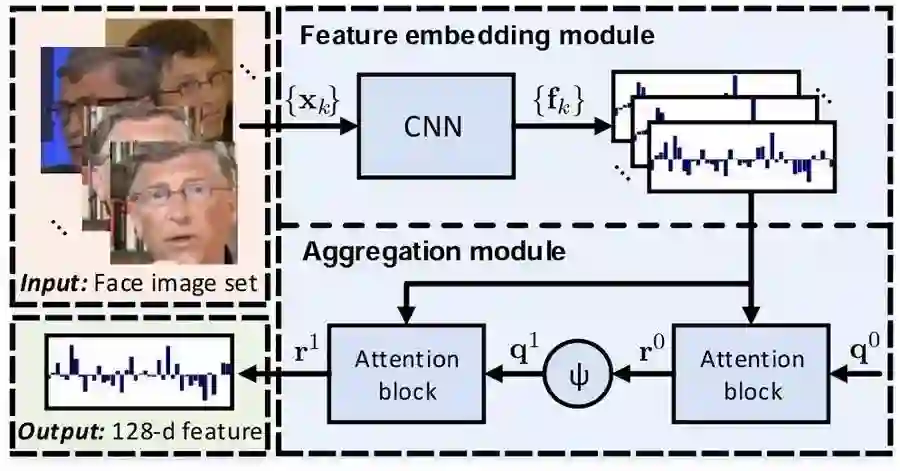
另外,我也简单介绍一下微软的工作。微软这次被CVPR接收的论文一共有30篇左右,跟我们在过去15年来每年在CVPR上发表的论文数大体相当,其中微软亚洲研究院有18篇,各个方向都有,3D建模、计算摄影,图像视频分析、理解、分割……覆盖率还是比较广的。其中一项视频人脸识别方面的研究,将视频中每一帧的人脸都提取出来,得出一个紧凑的固定长度的表征,更快更精确的进行人脸识别。
摘要
本文提出了一种用于视频人脸识别的神经聚合网络(Neural Aggregation Network,NAN)。网络将一个人脸部的视频或者一组数量不同的脸部图像数据集作为输入,并且生成一个紧凑(compact)、维度固定的特征表征,可用于识别。整个网络由两个模块组成。特征嵌入模块是一个深度卷积神经网络(CNN),它将每幅人脸图像都映射成一个特征向量。聚合模块由两个注意力模块(attention block)组成,它们能够自适应地聚合特征向量,在它们所覆盖的凸包(convex hull)中形成单个特征。由于注意力机制,聚合不会因图像顺序的变化而发生改变。我们的 NAN 由一个标准分类或验证损失训练,没有接收任何额外的监督信号,但我们发现它能够自动学习优选(advocate)高质量的脸部图像,同时排除(repel)低质量的图像,比如模糊、有遮挡和姿态不端(improperly exposed)的面部图像。在 IJB-A、YouTube Face、Celebrity-1000 视频脸部识别基准测试的实验表明,NAN 始终优于朴素聚合方法,并且实现了当前最高的精度。
图1. NAN视频面部识别的网络架构。所有输入面图像{xk}由具有深度CNN的特征嵌入模块处理,产生一组特征向量{fk}。接着这些特征被传递到聚合模块,产生单个128维向量r1表示输入的人脸图像。这种紧凑的表征(compact representation)可用于识别。
图6. YTF数据集上的典型示例,显示了我们的NAN计算的视频每帧的权重。每一行表示从视频采样5个帧,并根据其权重(图片左上角矩形中的数字)进行排序; 最右边的条形图显示所有帧的排序权重(高度缩放)。
http://www.ganghua.org/publication/CVPR17e.pdf |


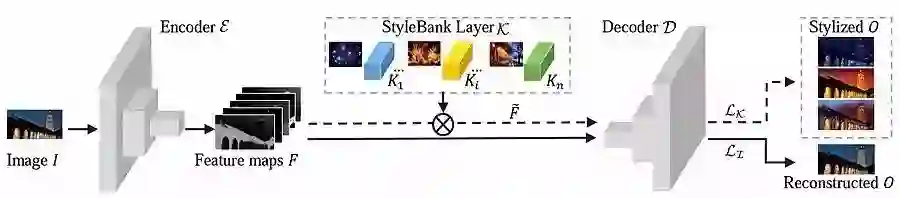
另一项是图像风格化的工作,这是第一次对图像风格做出了明确的物理和数值表征,我们能够将风格表征和图像内容分离出来,因此能用一个网络做很多不同的风格。现在学习一个风格只需要8分钟,转换的话只要几秒,我们正在把这个技术用应用到微软的产品中间去。
根据CCF多媒体技术专委会新技术选介17-04期的介绍,该论文采用了自编码器与滤波器组(filter bank)相结合的结构,能够同时对多种风格进行学习,将不同风格存储到各自对应的filter bank中,从而只使用一个前馈网络就能进行多种风格的迁移。
网络分为三个部分:编码器E、解码器D和风格库(style bank)K。输入图像I经过编码器编码为特征图(feature map)F,接着分为两路:下侧的实线箭头代表自编码器支路,F不经过风格库处理,直接经过解码器解码,得到O,O应该与I相似;上侧的虚线箭头代表风格化支路,F经过代表第i种风格风格库Ki滤波后得到特征图Fi,再经过D解码为风格化后的结果Oi。 图1. 网络分为3部分:编码器E、风格库K和解码器D。
这篇文章的作者认为,目前的前馈网络之所以每次只能描述一种风格,是因为这些网络并没有完全将图像的内容和风格区别开来。为了解决这个问题,作者借鉴了传统纹理合成方法中纹理基元(texton)的概念,将纹理基元通过深度网络学习并存储在滤波器组中,作者称之为风格库(style bank),每类风格生成一个与之对应的风格库。在前向传播时,只需选择需要的风格库,就能完成指定风格的迁移,结合了快速和风格多样化两种优势。这些风格库建立在自编码器提取的特征空间基础上,能更好地描述每类风格。同时,自编码器与风格库的结合还具有易于扩展的优势:对于新的风格,只需要训练新的风格库,不必重新训练整个网络。最后,因为内容与风格有效分离,训练得到的自编码器能对图像内容进行有效的区域划分,实现了基于区域的风格化。 图2.左:编码得到的feature map的聚类结果。右:风格化结果。 图3. 两种风格的融合。
经过实验,作者发现:
图4.与基于迭代优化的方法[1]进行比较。从左至右:输入图像,本文结果,[1]的结果 图5.与基于前馈网络的方法[2]进行比较。从左至右:输入图像,本文结果,[2]的结果
[1] Gatys L A, Ecker A S, Bethge M. Image style transfer using convolutional neural networks. CVPR, 2016. [2]Ulyanov D, Lebedev V, Vedaldi A, Lempitsky V. Texture networks: Feed-forward synthesis of textures and stylized images. ICML, 2016.
论文地址:http://www.ganghua.org/publication/CVPR17f.pdf
|





新智元:在CV领域有各类竞赛,“刷分”现象普遍存在,业界对此褒贬不一。您对“刷分”怎么看?
华刚:首先,我自己从来不做单纯“刷分”的事情,也基本不参加所谓的竞赛。研究成果,归根结底,是说你有没有为这个领域提供新的知识。所以,“刷分”应该是作为验证你的研究的一种“手段”,而不是最终目的。研究和评审过程中唯“分数”论,都是将研究机械化和暴力化,是不值得提倡的。不过,刷分做宣传那又另当别论了,可以理解,但我自己是不会做的。当然,我所指的单纯刷分是指你在刷分过程中并没有对问题的理解提供新的知识,也没有为领域发展开拓新的方法,打个比如说,我集成了10个最好的模型,当然会取得最好的结果。但是,集成这10个模型的方法算不算创新——集成也是需要技术的——有没有给学界带来新的知识呢?如果你的集成方法是大多数时候圈内人都知道怎么做的,只是不屑于做罢了,那样的刷分,是机械的,暴力的,是没有多少价值的。
新智元:在迭代如此快速、深度学习不断刷新各种性能的情况下,微软各研究院的研究人员如何从事“有意义/价值”的研究?如何产出高质量的论文(不被其他人抢先发表)?
华刚:在微软,我们有一个研究的周期(cycle),在选题(研究方向)、实验等各个环节,花费时间和精力最更多的其实是在选题上。2001年我还在西安交通大学读研究生的时候,沈向洋博士到学校做了一个报告,当时他提到:最好的研究员发现新问题,好的研究员创造新方法解好问题,一般的研究员跟随别人的方法解问题。也就是说,创新是研究的本质,只要你把问题或者方向想清楚、想透彻了,别人还是很难catch up的。当然,你说的被人抢先发表的情况偶尔也会有,那就是执行力的问题了。
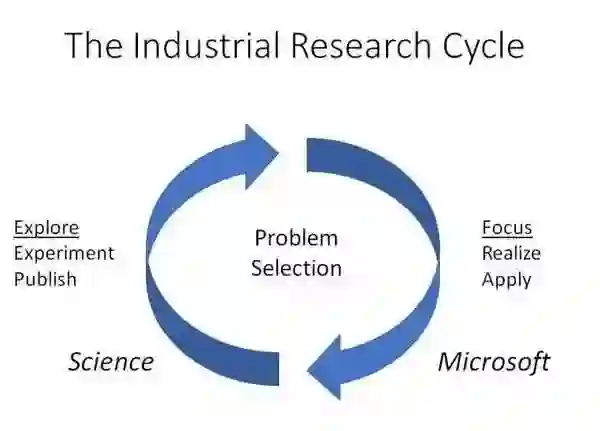
以下是微软研究院软件工程研究(RiSE)组研究经理Thomas Ball在今年,也是他进入微软第17年写下的文章《微软研究院的产业研究周期》(Microsoft Research and the industrial research cycle),介绍了微软研究院的Research Cycle:
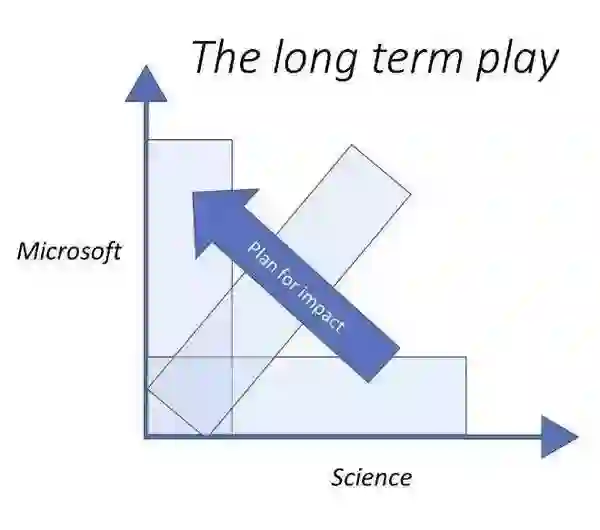
微软研究院不仅为你提供了如学术界一样充分探索和增进科学知识的自由,也需要你将自己的科学追求与公司的问题结合起来,致力推动微软的发展,这一要求也会随着你的年资增长而提高,这也反映了微软研究院在推进科学前沿研究的同时也要给公司带来正向推动的双重使命。 Thomas Ball写道:“[微软研究院的]研究人员可以自由地选择研究问题,并在各自学科(周期的左侧)探索,从而推进科技的进步。同时,他们也有责任和机会在进行了充分探索后,将注意力集中在他们认为可能对公司(周期右侧)产生影响的领域。理想情况下,研究人员对科学研究问题解决方案的探索最终会对公司的技术应用产生影响。”
在如上多次循环的过程中,研究人员的个人影响力如下图中的阴影面积表示:横轴表示科学影响力,纵轴表示对微软的影响力。在初期探索阶段,个人影响曲线的形状一般是水平的,因为主要受众还局限于科学界;后期在找准方向开始专注的阶段,个人曲线的形状通常是垂直的,并且建立在先前探索阶段的基础之上。 Thomas Ball还在文章里写道:“我们鼓励研究人员积极著述,但微软研究院并不强调发表数量。质量是我们的首要目标。” “微软研究院在科研上的投资可能不会立即对微软产生影响,但从长远来看将为公司培养新的力量/能力。要将科学结果转化为公司影响力离不开协调而长期的努力。” |

新智元:此前新智元采访李开复老师,他提到优秀企业的稀缺造成资本过度追逐,仅做人脸识别的初创公司估值接近独角兽不合理。李开复还预计一年后计算机视觉会出现一个短暂的寒冬。您认为单做人脸识别的创业公司价值如何?一年之后计算机视觉会迎来短暂的寒冬吗?
华刚:我尊重李开复老师的看法,但我持比较中立的态度,主要是我对这些创业公司的具体业务细节并不是很了解。单从技术角度说,计算机视觉发展这么多年,作为一项生物识别技术,在图像识别、金融、安防等很多领域技术已经成熟,到了可以商业应用的阶段。我对计算机视觉商业化一直有自己的兴趣,最近也进行了一些深入的思考。在微软计算机视觉多年积累的基础上,我今后的工作有一部分也会关注将相关技术产品化,参与相关商业化策略的制定和整合上面。
从商业的角度看,在亚洲做人脸识别整体而言是有优势的,主要是公众对个人隐私的关切度相比之下没有那么高。实际上,美国政府早在30多年前就开始了人脸识别项目,联合了政府、高校、研究所等众多机构的力量。然而,这么多年的投入,在民用领域的应用并没有特别多——在美国,人脸识别主要还是用于国土安防和反恐等政府应用。在中国,人脸识别的民间应用渗透度很高,前段时间不是有新闻提到,北京天坛公园卫生间里安装了人脸识别系统限制固定时间内用户取纸的数量么?,抛开别的不谈,我认为这可是一个巨大的商机(笑)。
至于单个公司是否能赚钱,实际上当前人脸识别的技术门槛并不高,这样技术壁垒就很难建立起来。单纯通过增加训练数据和加深网络深度已经对进一步解决人脸识别这个问题和进一步的商业应用并不能提供更多的帮助。即便有技术基础的公司,如果没有找到合适的商业应用场景,没把握住市场发展的趋势,那么碰到困难的可能性也很大。
不过,作为一个研究领域,计算机视觉正处于上升趋势,在研究领域一年后应该会继续蓬勃发展。无论在中美,政府部门对这个研究领域的投入也在加强,例如美国政府IARPA的JANUS计划,这是美国政府最近资助的无限制条件式人脸识别的研究。Facebook在2014年时首次推出了DeepFace,那是他们结合从2006年就开始做的让他们的用户在自己的在线相册里面标注他们的朋友,这么多年积累下来的一个人脸数据库——当然,在2014年时他们的技术并不完美,但DeepFace无疑将整个人脸识别往前推进了一大步。2007年,我开始在微软做人脸识别的研究并在2008年创立并奠基了微软的第一个完整的人脸识别引擎,现在已经持续发展并整合成为微软智能云平台认知服务里的Face API。
新智元:从您的专业角度看,这几年的CV发展趋势是怎么样的,近5年,近10年,近30年?您对未来3~5年计算机视觉领域的发展有什么期望吗?
华刚:这是一个很大的问题。计算机视觉作为一门科学最早于1955年提出。真正意义上现代计算机视觉的研究实际上是从20世纪70年代年末80年代初开始的。美国政府DARPA当时设立了一个图像理解研究项目(DARPA Image Understanding Research Program),早期很多计算机视觉研究者都接受并得益于DARPA的资助。当时DARPA的Image Understanding Workshop也是早年计算机视觉研究从业人员的一个主要平台。可以说是DARPA的这个图像理解研究项目奠定了现代计算机视觉研究的基础。随后第一届CVPR在1983年举办,ICCV则是1987年,为全世界的计算机视觉研究者提供了更大的交流舞台。
计算机视觉实际上是一门涵盖很广的学科,主要分为4个层次的任务:①图像获取,比如各种成像方法,怎么制作摄像头获取图像,包括红外摄像头、深度摄像头;②图像处理,这也是通常所说的低级视觉的问题,主要在像素级上进行处理,比如图像变换、滤波;③图像分析,这算是中级视觉的问题,通过分割和特征提取,将像素图像描述转变为比较简洁的描述,常见的纹理分析、运动、分割、3D视频,都属于这类;最后是④图像理解,也是通常所说的高级视觉的问题,包括物体识别,行为识别,和语义分割等等。
一直以来,计算机视觉研究者都致力于从下往上打通这套系统(pipeline)。过去10年,大部分研究集中在物体识别(object recognition),主要的方法是统计机器学习的方法和大规模图像数据库的结合。虽然我不喜欢用“热门”这个词,但过去5年,深度学习确实很热门,在ImageNet 图像数据库也取得了很好的成果。不过,计算机视觉有过很多种“流行”方法:2001年到2007年,Boosting和SVM是最受欢迎的方法;2007年到2012年则是基于稀疏表征的识别;2012年以后,深度学习的潜力被充分发挥出来。这些其实都属于统计机器学习,统计模式识别的方法。作为计算机视觉研究者,我不希望大家一提到“计算机视觉”就只想到“图像分类”。这些年,计算机视觉的每个领域都在向前发展,比如微软的Kinect Camera,能在成像过程中自动获取像素的景深。希望大家综合了解整个领域的发展,不要把计算机视觉的研究机械化成为是机器学习的一个简单应用。我不觉得单纯增加数据库或神经网络层数是解决高级视觉问题的正确途径。任何方法,必须要结合计算机视觉的领域知识(domain knowledge),充分利用图像,视频数据本身的特性,才能在计算机视觉研究方面取得真正的进展。
至于未来的发展,这并不好“预测”。我个人的观点,图像理解仍然会是近期关注的热点。再长远一些,计算机视觉实际上是人工智能的一个分支。早些年,计算机视觉也好、自然语言处理也好,大家都是投稿到AAAI。经过一段时间的发展,各个分领域都有了各自的会议,比如计算机视觉有了CVPR、ICCV,自然语言处理有了ACL……俗话说“天下大事合久必分,分久必合”,我相信未来语音、视觉、包括自然语言等再度融合的可能性很高。因为如果我们的目标是要做一个AI系统,它必定是多模态的,多个层面多种模块的结合。所以,在CVPR未来我们可能看到AI子领域相互融合,或者说朝着通用AI这个方向的研究会越来越多。
©️本文为新智元原创文章,未经授权请勿转载。在新智元后台回复“转载”了解转载规则。
新智元招聘
职位:客户总监
职位年薪:30 - 60万(工资+奖金)
工作地点:北京-海淀区
所属部门:客户部
汇报对象:COO
下属人数:8 人
年龄要求:25 岁 至 40 岁
性别要求:不限
工作年限:5 年
语 言:英语 + 普通话
学历要求:全日制统招本科
职位描述:
热爱人工智能,在行业内有一定的人脉资源和影响力;
为客户制定媒体关系策略和公关活动策划,达成客户的市场或传播目标;
负责监督公关项目的计划和实施,使项目能按期在预算内完成;
积极拓展客户资源,开发公司业务,与既有客户保持紧密的业务联络和沟通;
监督、管理及考核客户服务团队,全面提升公司客户服务质量;
理工科背景优先,有知名企业或知名媒体机构工作经验者优先。
应聘邮箱:jobs@aiera.com.cn
HR微信:13552313024
新智元欢迎有志之士前来面试,更多招聘岗位请点击【新智元招聘】查看。






