ICML 2020 | PEGASUS:文本摘要中的SOTA

论文标题:PEGASUS: Pre-training with Extracted Gap-sentences for Abstractive Summarization
机构:Google Research
作者:Jingqing Zhang, Yao Zhao, Mohammad Saleh, Peter J. Liu
论文地址:https://www.aminer.cn/pub/5dfb4b2f3a55acc4878bd402
收录会议:ICML 2020
论文代码:https://github.com/google-research/pegasus
近些年 Transformers 在海量语料上进行自监督预训练再到下游各种NLP任务(当然也包括文本摘要)上微调的方案已取得巨大成功。但是,尚未有针抽象文本摘要(abstractive text summarization)定制预训练目标。此外,目前抽象文本摘要任务也缺乏跨领域的系统评价。
为此,本文提出了一种新的自监督预训练目标:GSG(Gap Sentences Generation),以适配 Transformer-based 的 encoder-decoder 模型在海量文本语料上预训练。在 PEGASUS 中, 将输入文档中的“重要句子”删除或者遮蔽,再利用剩余的句子在输出中生成这些被删除或遮蔽的句子。从输入和输出看,该目标与文本摘要类似。
本文以 12 个文本摘要数据集(包括新闻、科学、故事、使用说明、电子邮件、专利和立法议案)对最好的 PEGASUS 模型进行全面测试。实验结果是:PEGASUS 刷新 12 个数据集的 ROUGE 得分记录。另外,PEGASUS 模型在处理低资源摘要数据集也显示出惊人的性能,在 6 个数据集上仅以 1000 个样本就超过了之前的最先进结果。最后,本文还对 PEGASUS 模型生成的摘要结果进行人工评测,结果表明本文的模型在多个数据集上达到与人工摘要相媲美的性能。
各种 Transformer 模型与自监督预训练技术(如 BERT、GPT-2、 RoBERTa、XLNet、ALBERT、T5、ELECTRA)相结合,已被证明是学习生成通用语言的强大框架。之前的工作中,预训练使用的自监督目标对下游应用有一定程度的不可知性,即不考虑下游任务,如此有利于模型通用性的学习。本文认为如果预训练的自监督目标更接近最终的任务,那么最终的下游任务能取得更好的结果。
实验证明,将输入文档中部分句子遮蔽掉,用剩余的句子生成被遮蔽掉句子的这种预训练目标很适用于文本摘要任务。这种预训练目标确实适合于抽象摘要,因为它非常类似于下游任务,从而促进模型对整个文档的理解和类似摘要的生成。需要指出的是,选择重要句子比随机选择或者选择前几句的结果性能都要好。
在 C4 语料上预训练出的最好 PEGASUS 模型,参数只有 568M,但在 12 个评测数据集上评测能够比肩此前最优结果,甚至超越它们刷新纪录。另外,本文为进一步提升最先进结果,引入了一个新收集的文本语料库,该语料库由新闻类文章组成包括 XSum 和 CNN/DailyMail 摘要数据集,统称为 HugeNews。此外,将本文的模型应用了低资源文本摘要任务上时,实验结果表明本文的模型能够非常快速适用于少量监督对的微调,并仅以 1000 个样本即在 6 个数据集中斩获桂冠。最后,还将文本模型的结果与人工摘要结果做对比,结果表明本文的模型可以达到与人工摘要相媲美的效果。
总结下本文的贡献:
(1)提出了一个新的自监督的预训练目标(GSG)用于抽象摘要任务,并研究相应的句子选择策略。
(2)用多个领域的摘要任务数据集对 GSG 进行广泛评测,并仔细地选择最佳的模型设置,训练一个参数量仅为 568M 的 PEGASUS 模型。该模型在全部的 12 个下游数据集上能够超过或与当前最先进水平持平。
(3)对于低资源任务数据集,通过微调 PEGASUS 模型,可以在广泛的领域实现良好的抽象摘要效果。在多个任务上,仅需 1000 个样本就超过了以前的最先进的结果。
(4)对模型结果进行人工评估,结果表明在 XSum, CNN/DailyMail 和 Reddit TIFU 上的摘要效果与人工摘要比肩。
模型
本文假设预训练自监督的目标越接近最终的任务则结果性能越好。在 PEGASUS 预训练中,将文件里的几个完整句子删除,而模型的目标就是要恢复这些句子,换句话说,用来预训练的输入是有缺失部分句子的文档,而输出则是缺失句子的串连。这是一项难以置信的艰巨任务,甚至对人人类来说也是不可能的,我们并不期望模型能完美地解决它。然而,这样一个具有挑战性的任务促使模型学习到关于语言的知识和这个世界的一般事实,以及如何从整个文档中提取信息,以便生成类似于微调摘要任务的输出。这种自监督的优点是,可以创建与文档一样多的示例,而不需要任何人工注释,而这通常是纯监督系统的阿喀琉斯之踵。
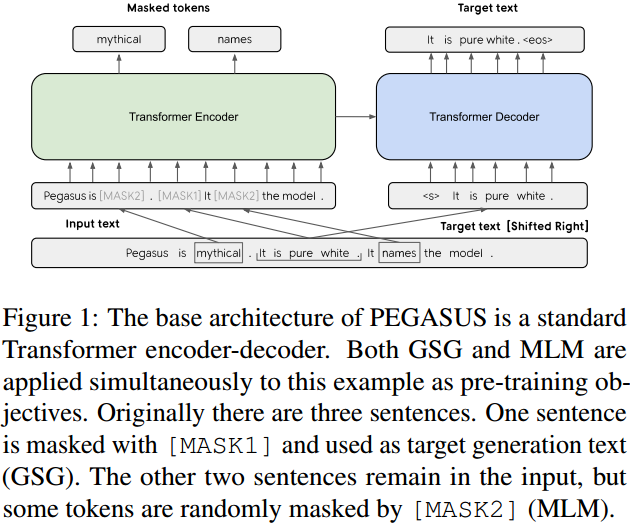
实验发现,选择重要的句子来遮蔽效果最好,让自监督示例的输出结果更像摘要。那么怎么选择重要的句子?根据 ROUGE 度量标准,通过查找那些与文档的其他部分最相似的句子,自动地识别出这些句子。ROUGE 计算两个文本的 n-gram 重叠,从而得到文本之间的相似性(ROUGE-1、ROUGE-2 和 ROUGE-L 是三种常见的变体)。句子选择策略如 Figure 2 所示:

预训练语料和下游任务
与 T5 类似,本文预训练所用的海量语料也是通过网络爬取。接着在 12 个抽象摘要数据集上微调 PEGASUS,以 ROUGE 得分来看取得当下最好结果,但参数量只有 T5 的 5%。参与评测的 12 个数据集是多样的的,包括新闻文章、科学论文、专利、短篇小说、电子邮件、法律文件和使用指南,这表明模型框架适用于广泛的主题,具有一定通用性。
预训练的语料具体如下:
(1)C4,这是 T5 中引入的语料
(2)HugeNews,这是本文新引入的
下游任务具体如下:
(1)XSum(2)CNN/DailyMail(3)NEWSROOM(4)Multi-News(5)Gigaword(6)arXiv(7)PubMed(8)BIGPATENT(9)WikiHow(10)Reddit TIFU(11)AESLC(12)BillSum
PEGASUS_{base}版:
参数量为 223M,L=12,H=768,F=3072,A=12,batch size=256。
PEGASUS_{large}版:
参数量为 568M,L=16,H=1024,F=4096,A=16,batch size=8192。
消融研究
模型的消融研究基 于PEGASUS_{BASE},研究对象:预训练语料、预训练目标、词典尺寸。
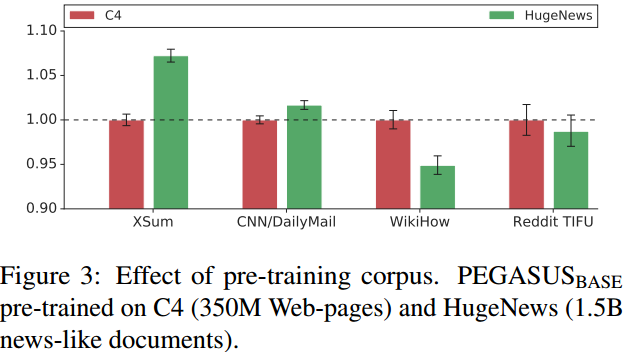
预训练语料的影响如 Figure 3 所示:
预训练目标的影响如 Figure 4 所示:
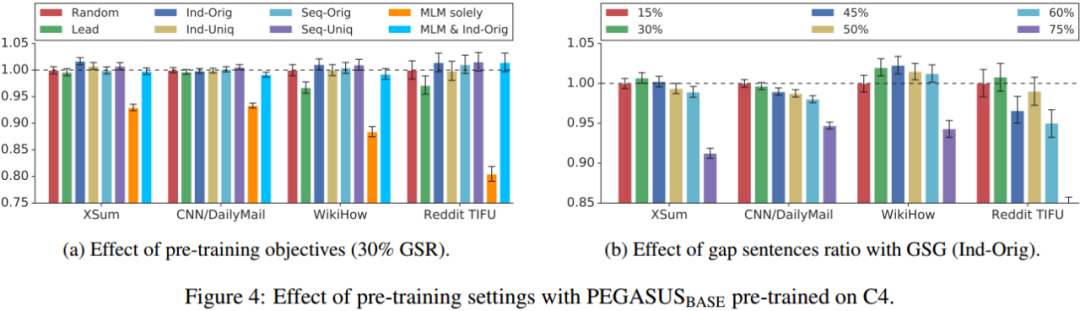
Figure 4a 可以看出 Ind-Orig 的方案最佳,Seq-Uniq 次之。Figure 4a 展示了 gap-sentences 比例(GSR)的影响。实验表明 GSR 低于 50% 较好,在 CNN/DailyMail 数据集上 15% 的比例可以得到最优结果。而 XSum/Reddit TIFU 和 WikiHow 的最佳值分别是 30% 和 45%。
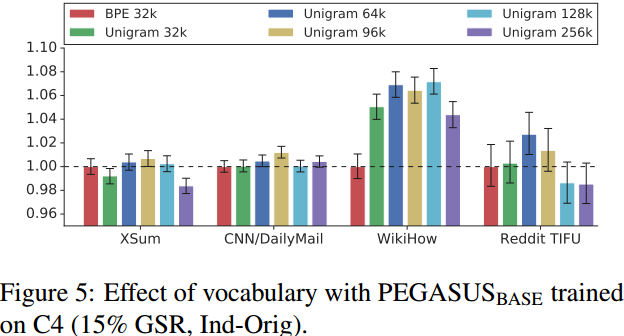
Figure 5 展示了词典大小的影响:
Larger 模型效果
基于之前的实验,在 Large 版的模型中选用的是 GSG(Ind-Orig)预训练目标(不带有MLM)、Unigram 词典大小 96k。
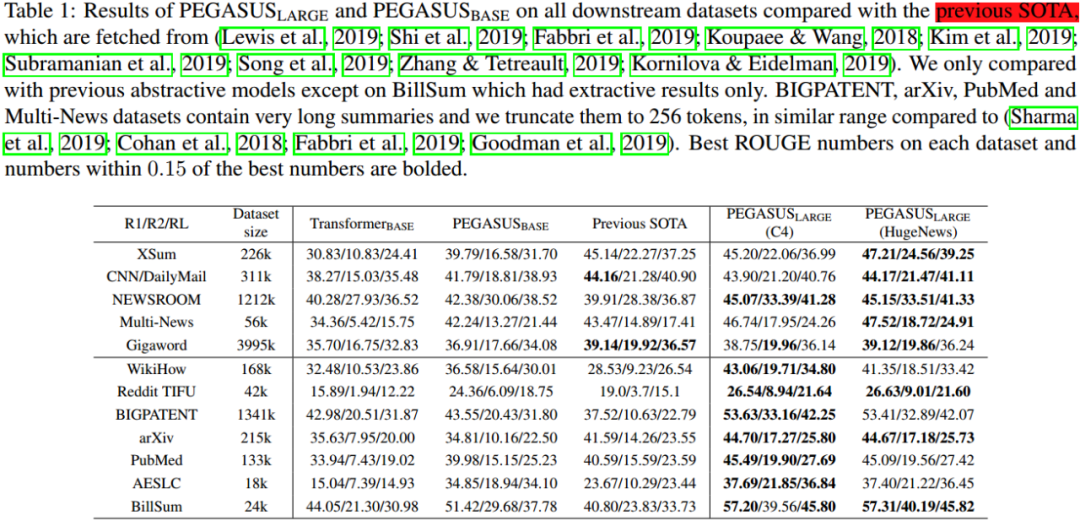
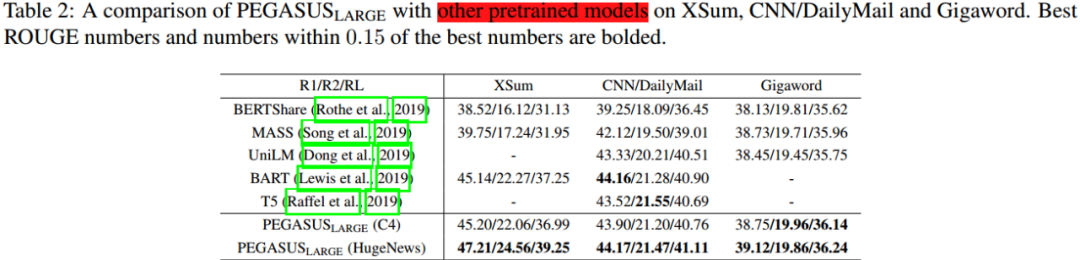
Table 1和 Table 2展示了 PEGASUS_{BASE} 和 PEGASUS_{LARGE}在下游任务上的表现。PEGASUS_{BASE}在多项任务上超过当前最优结果,PEGASUS_{LARGE} 则在全部下游任务超越当下最优结果。
经过大型语料预训练的 PEGASUS 模型,该模型不需要大量的样本进行微调,就可以获得接近最先进的性能。Figure 6 展示了 PEGASUS 模型在 8 个数据集下使用不同样本数进行微调的结果。
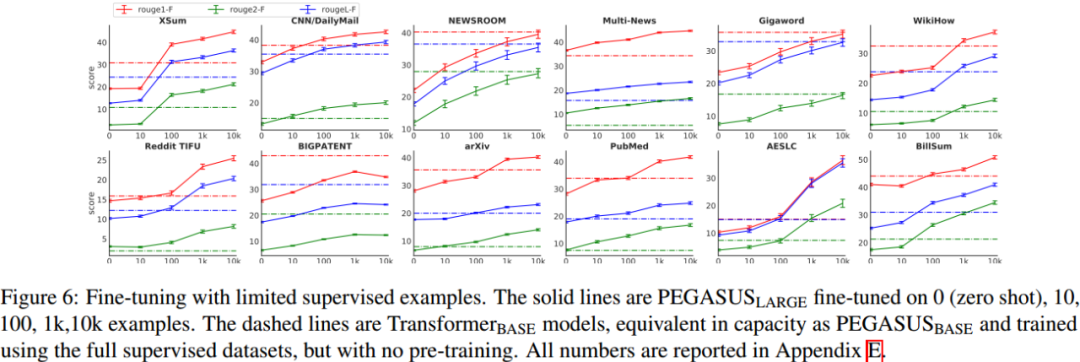
Large 版只要用 100 个样本进行微调就可以得到与 Base 版在 20k 到 200k 样本上进行监督训练相近的结果。Large 版在其中的 6 个任务上以 1000 个微调样本量就超越了之前的最优结果。在只有 1000 个微调样本的情况下,在大多数任务中都比使用完整监督数据的强基线(Transformer 编码器-解码器)执行得更好,在某些情况下,强基线(Transformer 编码器-解码器)使用的是多个数量级的样本。这种“样本效率”极大地提高了文本摘要模型的有用性,因为它显著地降低了监督数据收集的规模和成本,而在摘要的情况下,监督数据收集的成本是非常昂贵的。
人工评测
虽然使用像 ROUGE 这样的自动度量标准在模型开发过程中作为度量标准有用,但是该标准提供的信息有限,比如无法获悉文本摘要的流畅性或者与人类性能相比较结果如何。为此,本文还进行了一次人工评估,要求评分者将文本的模型摘要结果与人工摘要进行比较(不知道哪个是哪个)。这与图灵测试有一些相似之处。

总结
联系笔者
刘杰鹏,毕业于华中科技大学,研究方向机器阅读理解、文本生成等。现居深圳,微信号 onepieceand,欢迎同道中人进一步交流。






