线性模型已退场,XGBoost时代早已来
什么是 XGBoost?如何直观理解 XGBoost?它为什么这么优秀?
我对十五年前第一天工作的情况还记忆犹新。彼时我刚毕业,在一家全球投资银行做分析师。我打着领带,试图记住学到的每一件事。与此同时,在内心深处,我很怀疑自己是否可以胜任这份工作。感受到我的焦虑后,老板笑着说:
「别担心,你只需要了解回归模型就可以了。」
我当初想的是「我知道这个!」。我知道回归模型——线性回归和 logistic 回归都知道。老板是对的。我在任职期间仅仅构建了基于回归的统计模型。我并不是一个人。事实上,当时的回归模型在预测分析中独占鳌头。而十五年后的今天,回归模型的时代已经结束了。迟暮的女王已经退场,取而代之的是名字时髦、活力满满的新女王——XGBoost(Exterme Gradient Boosting,极限梯度提升)。
什么是 XGBoost?
XGBoost 是基于决策树的集成机器学习算法,它以梯度提升(Gradient Boost)为框架。在非结构数据(图像、文本等)的预测问题中,人工神经网络的表现要优于其他算法或框架。但在处理中小型结构数据或表格数据时,现在普遍认为基于决策树的算法是最好的。下图列出了近年来基于树的算法的演变过程:
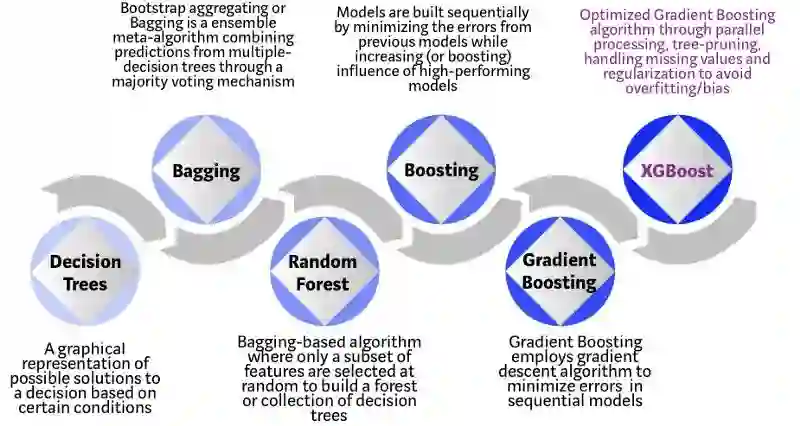
从决策树到 XGBoost 算法的演变。
XGBoost 算法最初是华盛顿大学的一个研究项目。陈天奇和 Carlos Guestrin 在 SIGKDD 2016 大会上发表的论文《XGBoost: A Scalable Tree Boosting System》在整个机器学习领域引起轰动。自发表以来,该算法不仅多次赢得 Kaggle 竞赛,还应用在多个前沿工业应用中,并推动其发展。许多数据科学家合作参与了 XGBoost 开源项目,GitHub 上的这一项目(https://github.com/dmlc/xgboost/)约有 350 个贡献者,以及 3600 多条提交。和其他算法相比,XGBoost 算法的不同之处有以下几点:
应用范围广泛:该算法可以解决回归、分类、排序以及用户自定义的预测问题;
可移植性:该算法可以在 Windows、Linux 和 OS X 上流畅地运行;
语言:支持包括 C++、Python、R、Java、Scala 和 Julia 在内的几乎所有主流编程语言;
云集成:支持 AWS、Azure 和 Yarn 集群,也可以很好地配合 Flink、 Spark 等其他生态系统。
对 XGBoost 的直观理解
决策树是易于可视化、可解释性相对较强的算法,但是要建立下一代基于树的算法的直观理解可能就有些棘手了。为了更好地理解基于树的算法的演变过程,我对其做了简单的类比:
假设你是面试官,要面试几名资历非常优秀的求职者。基于树的算法演变过程的每一步都可以类比为不同版本的面试场景。
决策树:每一名面试官都有一套自己的面试标准,比如教育水平、工作经验以及面试表现等。决策树类似于面试官根据他(她)自己的标准面试求职者。
袋装法(Bagging):现在面试官不只有一个人,而是一整个面试小组,小组中的每位面试官都有投票权。Bagging(Boostrap Aggregating)就是通过民主投票过程,综合所有面试官的投票,然后做出最终决定。
随机森林(Random Forest):这是基于 Bagging 的算法,但与 Bagging 有明显区别——它随机选择特征子集。也就是,每位面试官只会随机选择一些侧面来对求职者进行面试(比如测试编程技能的技术面或者是评估非技术技能的行为面试)。
Boosting:这是一种替代方法,每位面试官根据前一位面试官的反馈来调整评估标准。通过部署更动态的评估流程来「提升」面试效率。
梯度提升(Gradient Boosting):这是 Boosting 的特例,这种算法通过梯度下降算法来最小化误差。用面试类比的话,就是战略咨询公司用案例面试来剔除那些不符合要求的求职者;
XGBoost:将 XGBoost 视为「打了鸡血」的梯度提升(将这种算法称为「极限梯度提升」是有原因的!)。这是软硬件优化技术的完美结合,它可以在最短时间内用更少的计算资源得到更好的结果。
为什么 XGBoost 如此优秀?
XGBoost 和梯度提升机(Gradient Boosting Machine,GBM)都是用梯度下降架构增强弱学习器(一般是 CART)的集成树方法。但 XGBoost 通过系统优化和算法增强改进了基础 GBM 框架。
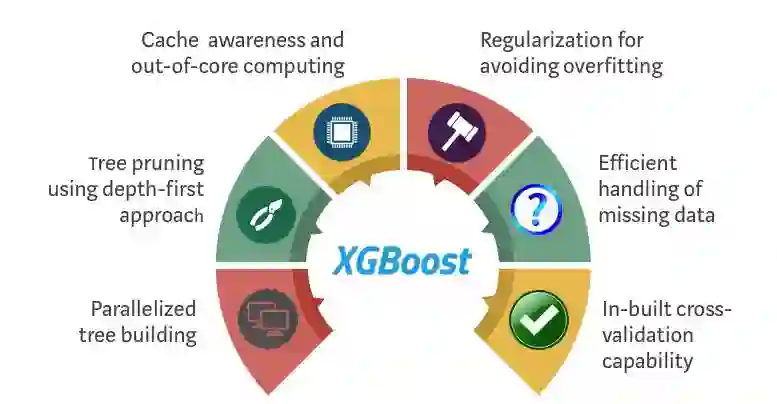
XGBoost 是如何优化标准 GBM 算法的
系统优化
并行:XGBoost 用并行的方式实现了序列树的构建过程。考虑到用于构建基础学习器的循环、枚举树的叶节点的外部循环以及计算特征的第二个内部循环的可互换性,这是完全有可能实现的。由于没有完整的内部循环就无法启动外部循环(两个循环要求的计算资源更多),因此这种嵌套的循环限制了并行。为了改善运行时,就要交换循环的顺序,这通过对所有实例进行全局扫描来执行初始化以及用并行线程排序来实现。这样的变换抵消了计算中并行所需的开销,从而提升了算法性能。
剪枝:从本质上讲 GBM 框架内树分裂的停止标准是贪婪的,这取决于分裂点的负损失。XGBoost 优先使用指定的「max_depth」参数,然后开始后向修剪树。这种「深度优先」的方法显著提升了计算性能。
硬件优化:XGBoost 算法可以有效利用硬件资源。这是通过缓存感知(cache awareness)实现的,而缓存感知则是通过在每个线程中分配内部缓冲区来存储梯度统计信息实现的。「核外」计算等进一步增强措施则在处理与内存不兼容的大数据帧时优化了可用磁盘空间。
算法增强:
正则化:用 LASSO(L1)正则化和 Ridge(L2)正则化惩罚更复杂的模型,以防止过拟合。
稀疏性感知(Sparsity Awareness):XGBoost 根据训练损失自动「学习」最佳缺失值,从而承认输入的稀疏特征,还可以更高效地处理数据中不同类型的稀疏模式。
加权分位数略图(Weighted Quantile Sketch):XGBoost 用分布式加权分位数略图算法(https://arxiv.org/pdf/1603.02754.pdf)高效地从加权数据集中找到最佳分裂点。
交叉验证:该算法在每次迭代时都使用内置的交叉验证方法,这样就无需特地为搜索编程,也不需要每次运行时都指定所需迭代增强的确切数目。
证据在哪里?
我们用 Scikit-learn 中的「Make_Classification」(https://scikit-learn.org/stable/modules/generated/sklearn.datasets.make_classification.html)数据包创建包含 100 万个数据点的随机样本,其中包含 20 个特征(2 个是信息性的,2 个是冗余的)。我们测试了几种算法,比如 Logistic 回归、随机森林、标准梯度提升,以及 XGBoost。
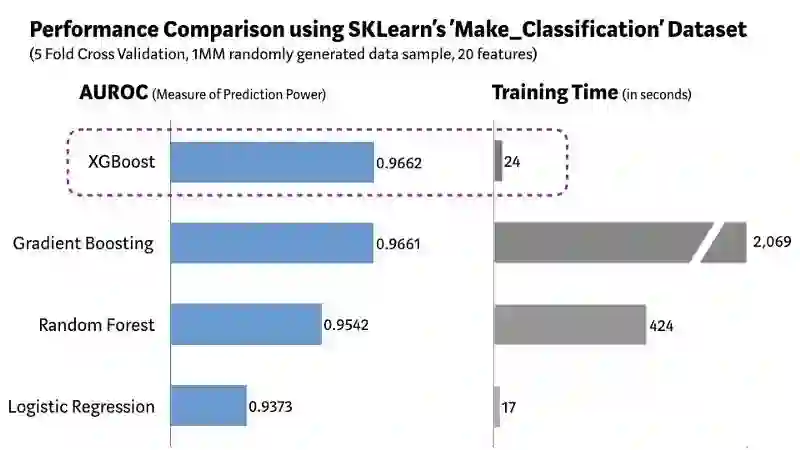
使用 SKLearn 中 Make_Classification 数据集的 XGBoost 算法和其他 ML 算法。
如上图所示,和其他算法相比,结合预测性能和处理时间两项来看,XGBoost 是最好的。其他严格的基准研究(https://github.com/szilard/benchm-ml)也得到了类似的结果。这也难怪 XGBoost 广泛应用于近期的数据科学竞赛了。
「如有疑问,用 XGBoost 就好」——Owe Zhang,Kaggle Avito 上下文广告点击大赛冠军。
那么我们应该一直用 XGBoost 吗?
无论是机器学习还是生活,没有免费的午餐都是一条铁律。作为数据科学家,我们必须要测试所有能处理手头数据的算法,才能判断哪种算法是最好的。此外,只是选择正确的算法还不够。我们必须针对要处理的数据集调整超参数,从而选择合适的配置。此外,要选择合适的算法还要考虑其他因素,比如计算复杂度、可解释性以及易于实现性。这是机器学习从科学走向艺术的开始,但说实话,这也正是见证奇迹的时刻!
原文链接:https://towardsdatascience.com/https-medium-com-vishalmorde-xgboost-algorithm-long-she-may-rein-edd9f99be63d
作者: Vishal Morde来源:towardsdatascience,机器之心等
广告 & 商务合作请加微信:kellyhyw
投稿请发送至:mary.hu@aisdk.com