学界 | 斯坦福论文提出MoleculeNet:分子机器学习新基准
选自arXiv
机器之心编译
参与:路雪、李泽南
分子机器学习快速发展,但是缺少用于对比不同方法性能的标准基准,算法进步因此受到限制。斯坦福的研究者提出一种适合分子机器学习的大型基准 MoleculeNet,并在 arXiv 上发布论文。机器之心对该论文进行了编译。
论文地址:https://arxiv.org/abs/1703.00564

过去几年中,分子机器学习快速发展成熟。方法的改进和大型数据集的出现使得机器学习算法对分子特性的预测精度变高。但是,由于缺乏对比不同方法性能的标准基准,算法进步受到限制。大多数新算法以不同数据集为基准,这使得评估方法的质量难度很高。本研究介绍了用于分子机器学习的大型基准 MoleculeNet。MoleculeNet 提供多个公共数据集、建立了评估度量,并提供之前提出的多个分子特征化(molecular featurization)和学习算法的高质量开源实现(作为 DeepChem 开源库的一部分发布)。MoleculeNet 基准证明可学表征是分子机器学习的强大工具,能够广泛提供最优性能。然而,仍然有一些需要注意的地方。可学表征仍然需要在数据匮乏和分类严重不均衡的情况下处理复杂任务。对于量子力学和生物物理数据集来说,物理性特征化的使用比特定学习算法更加重要。
方法
MoleculeNet 基于开源包 DeepChem。图 1 展示了带注释的 DeepChem 基准脚本。注意数据分割、特征化和可用模型的不同选择。DeepChem 还可以直接提供 molnet 子模块以支持基准测试。下面的命令行可以在指定数据集、模型和特征器上运行基准测试,还支持能够处理 DeepChem 数据集的用户定义模型。
本文将进一步介绍基准系统、可用数据集和已实现的分割、度量、特征化和学习方法。
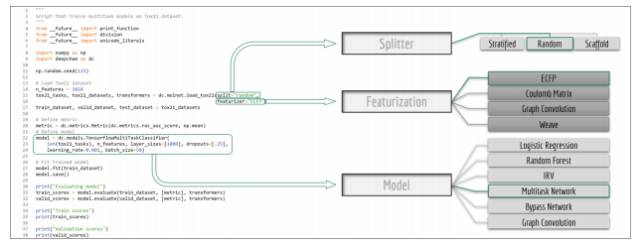
图 1:使用 DeepChem 进行基准评估的代码示例,提供多种方法用于数据分割、特征化和学习。
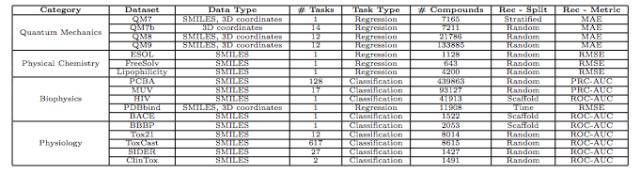
表 1:数据集细节:化合物和任务的数字、推荐的数据分割和度量。

图 2:反映分子性质不同级别的不同数据集中的任务。
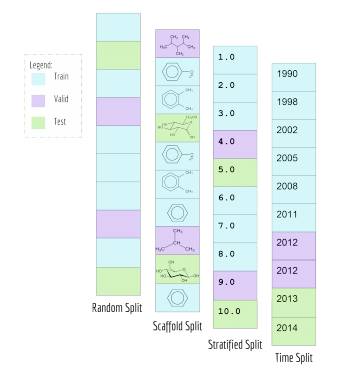
图 3:MoleculeNet 中的数据分割。
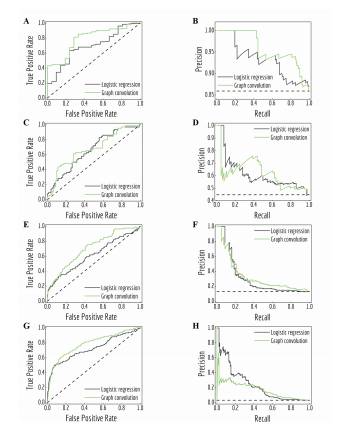
图 4:不同类别不均衡条件下,logistic 回归和图卷积模型预测的受试者工作特征(ROC)曲线和准确率-召回率曲线(PRC)。A、B:测试子集 ClinTox 中的「FDA APPROVED」任务;C、D:测试子集 SIDER 中的「Hepatobiliary disorders」任务;E、F:验证子集 Tox21 的「NR-ER」任务;G、H:测试子集 HIV 的「HIV active」任务。黑色虚线代表随机分类器的性能。
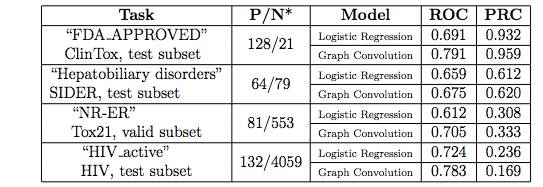
表 2:任务详情和示例曲线的曲线下面积(AUC)的值。第二栏为正样本数量/负样本数量。
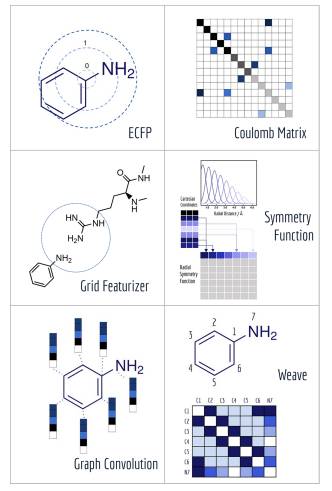
图 5:MoleculeNet 中的特征化图解。
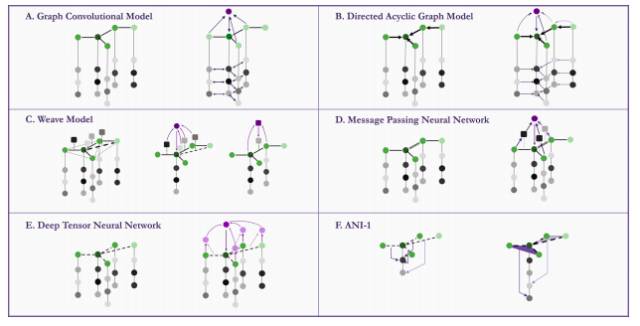
图 6:MoleculeNet 中实现的基于图的模型的核心结构。目的在于为中间的深绿色原子构建特征:A 图卷积模型(Graph Convolutional Model):特征通过邻近原子的连接进行更新;B 有向无环图模型(Directed Acyclic Graph Model):所有连接直接围绕中心原子,特征通过直接连接从最远的原子传送到中心原子;C Weave Model:每对原子(包括不直接连接的成对原子)都可以组对,中心原子的特征通过所有其他原子和相关的对进行更新,对特征通过组对的两个原子的连接进行更新;D 消息传递神经网络(Message Passing Neural Network):邻近原子的特征输入依赖连接类型的神经网络,再输出(消息)。中心原子的特征通过输出进行更新;E 深度张量神经网络(Deep Tensor Neural Network):没有明确的连接信息,特征通过其他原子对应的物理距离进行更新;F ANI-1:特征通过成对原子(径向对称函数)之间的距离信息和三个原子(角对称函数,angular symmetry function)之间的角度信息构建而成。
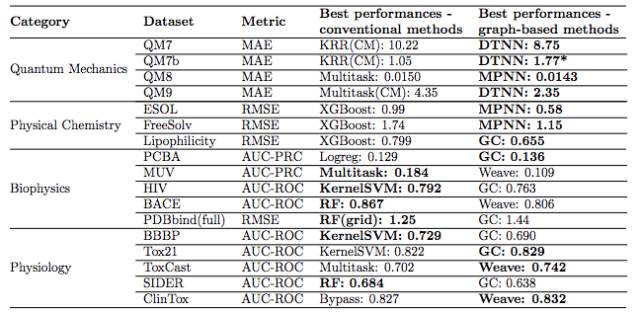
表 3:(测试集)性能总结:传统方法 VS. 基于图的方法。基于图的模型性能在 11/17 个数据集上优于传统方法。
点击阅读原文,在 PaperWeekly 参与对此论文的讨论。
本文为机器之心编译,转载请联系本公众号获得授权。
✄------------------------------------------------
加入机器之心(全职记者/实习生):hr@jiqizhixin.com
投稿或寻求报道:content@jiqizhixin.com
广告&商务合作:bd@jiqizhixin.com




