一文超详细讲解文本风格迁移
点击上方,选择星标或置顶,每天给你送干货
阅读大概需要33分钟
跟随小博主,每天进步一丢丢



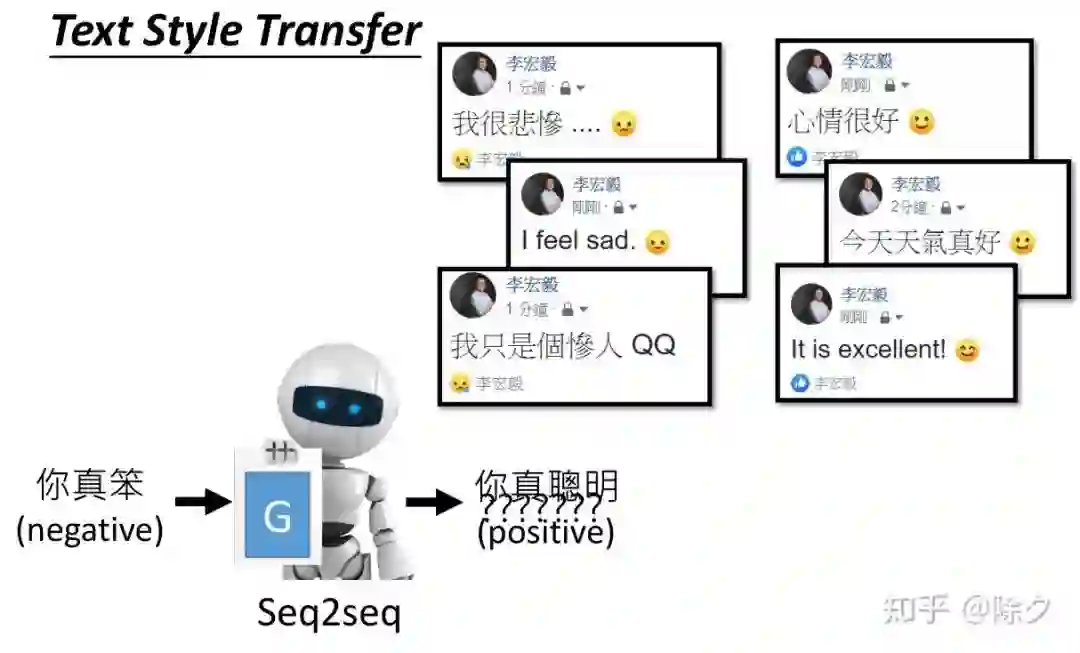
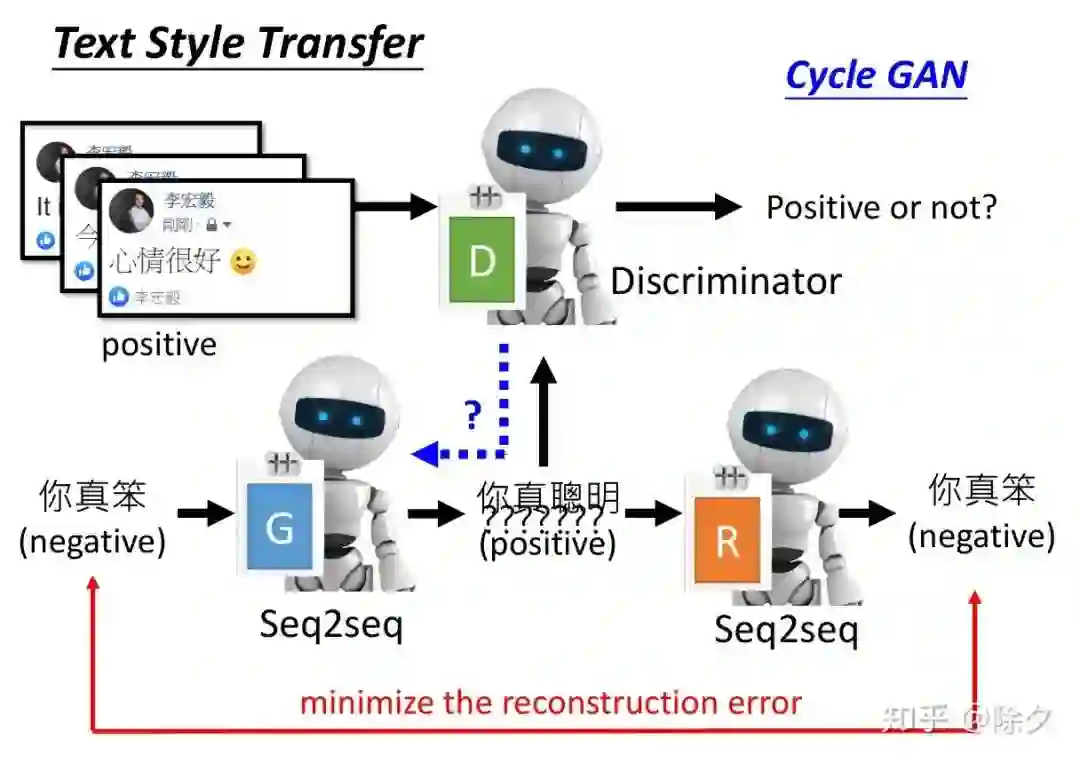
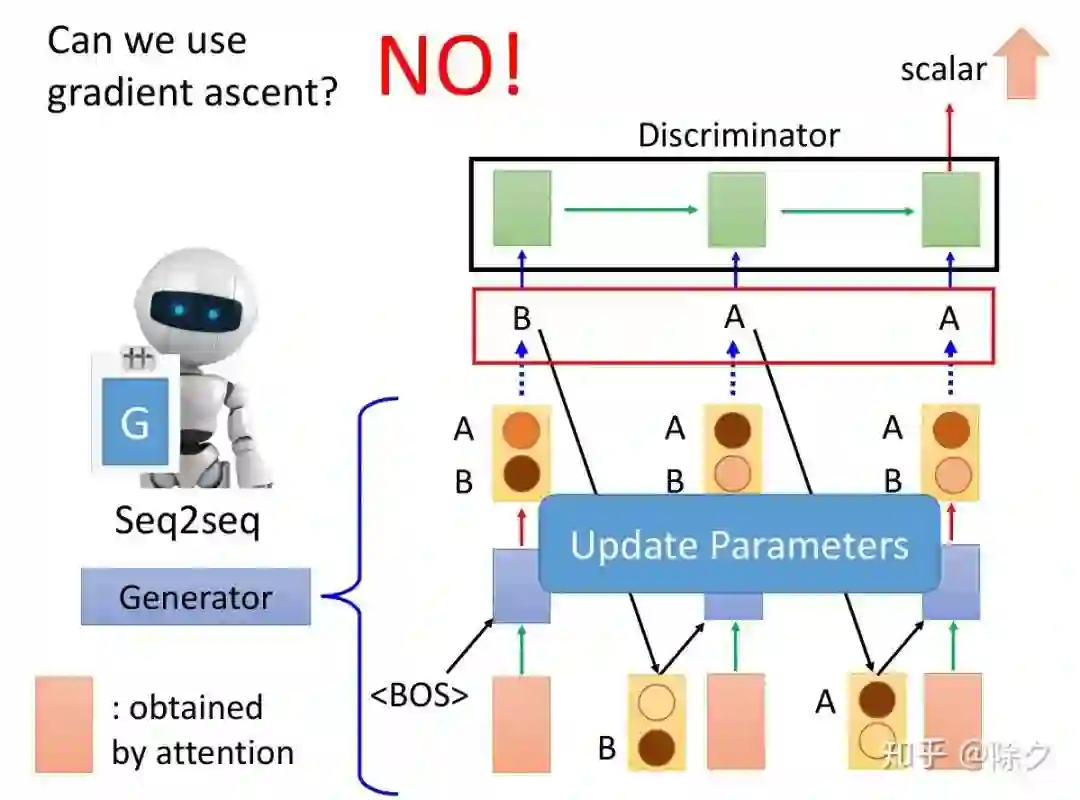

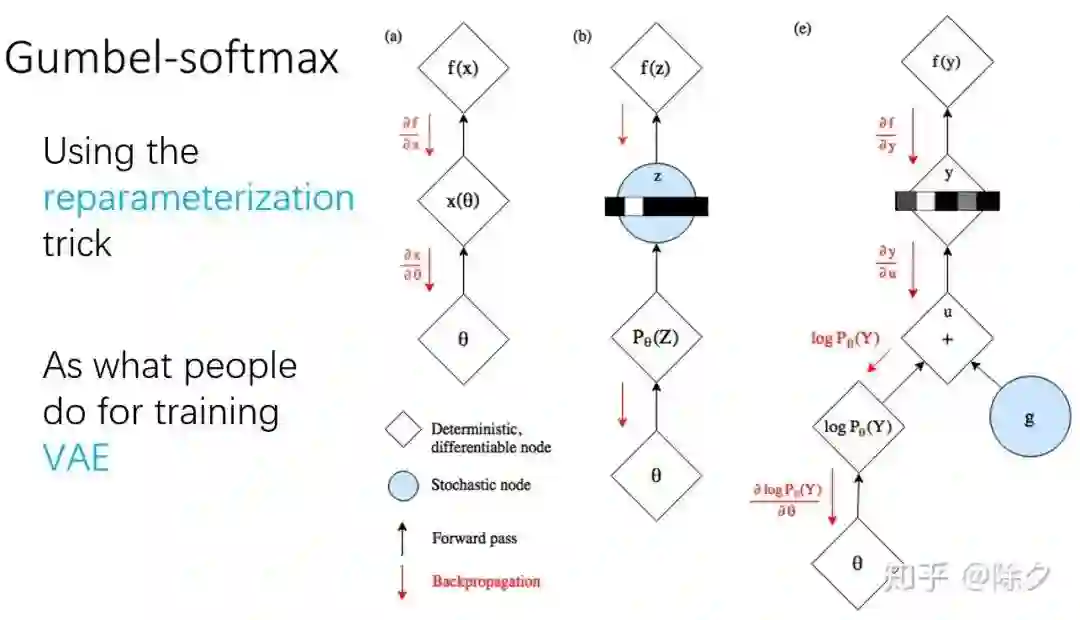
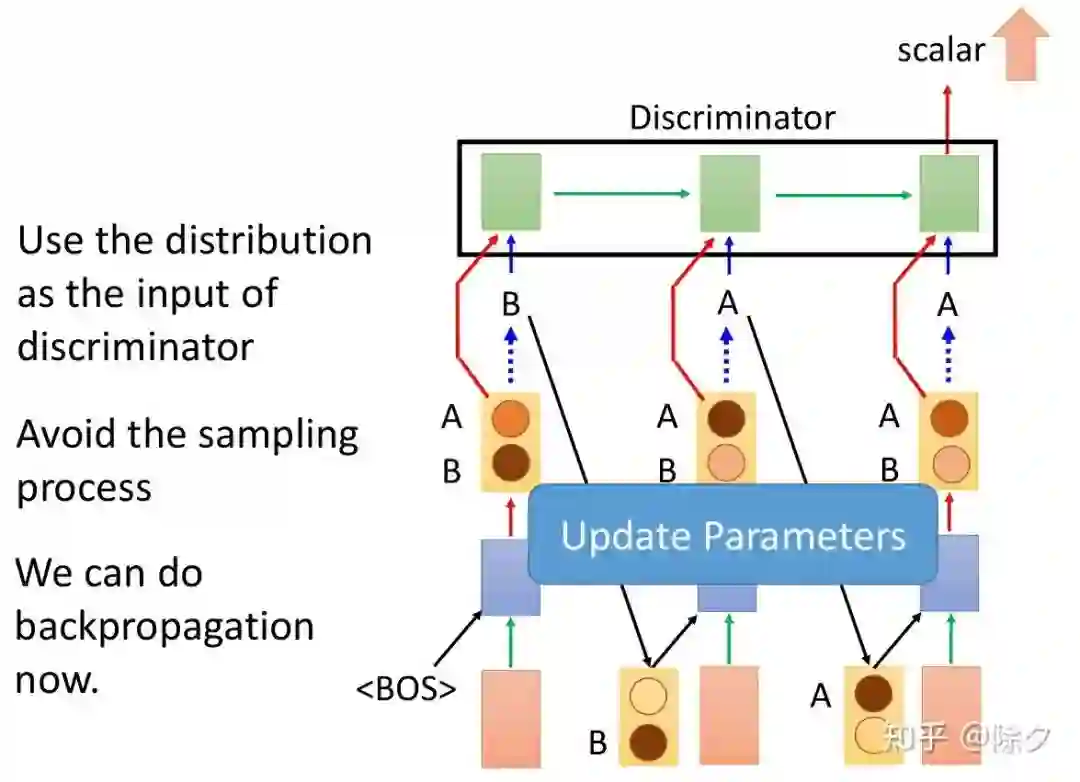

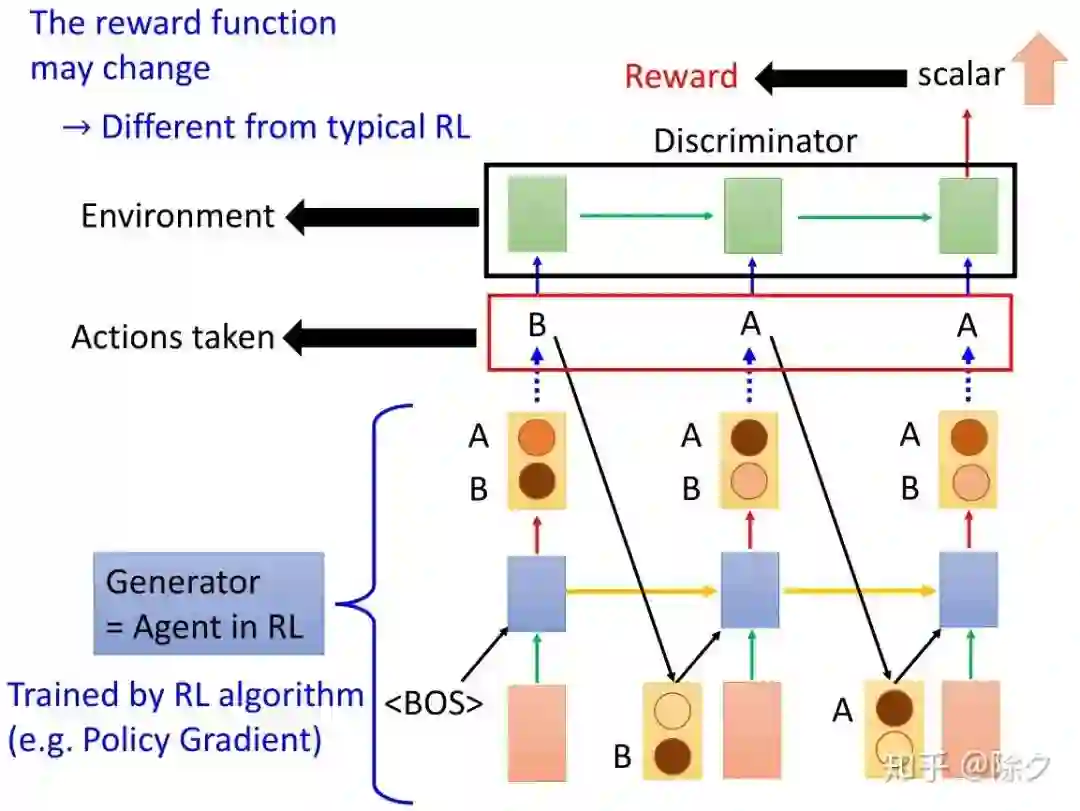

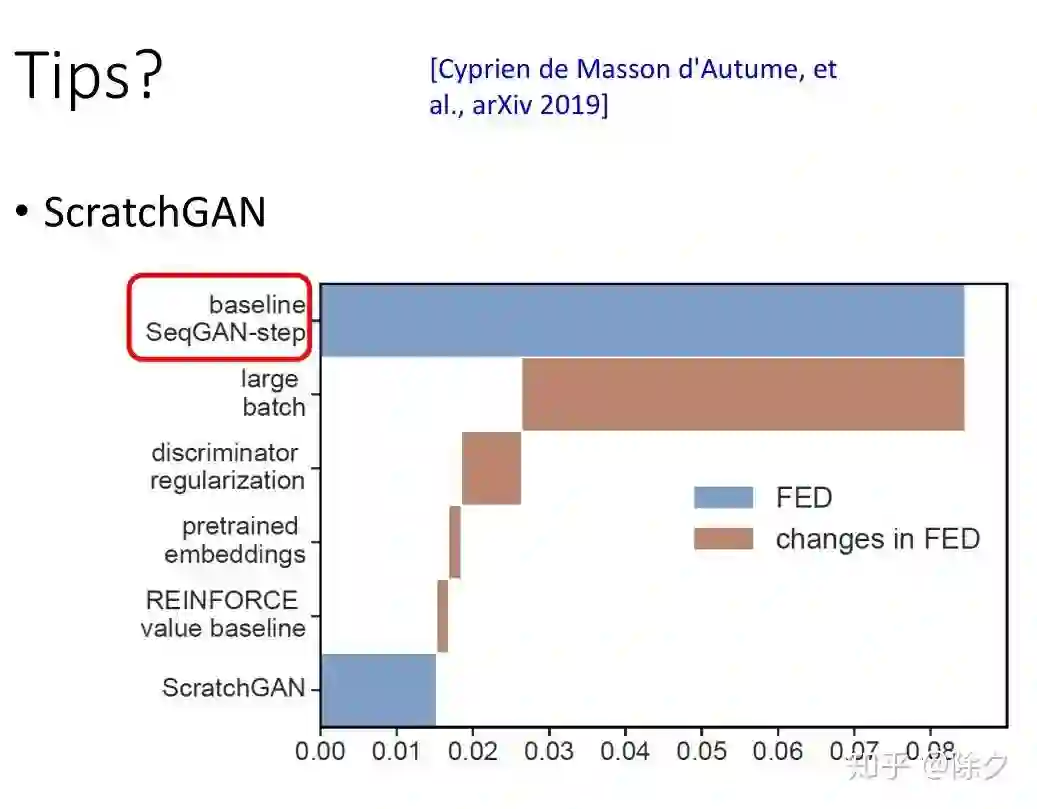
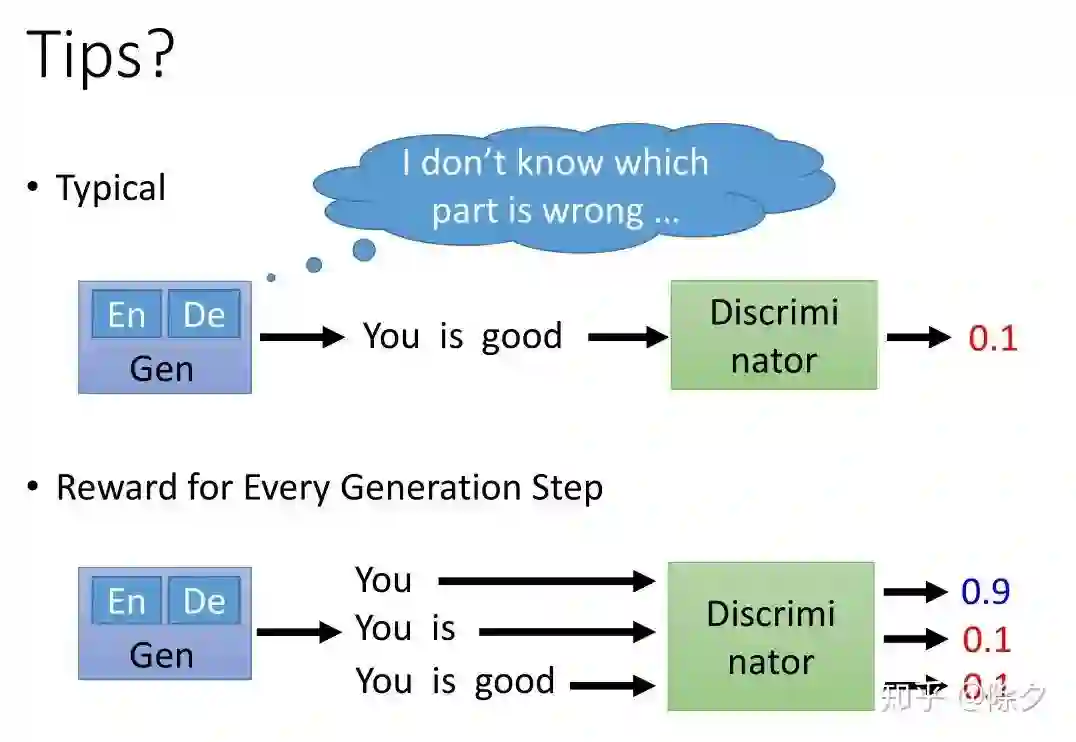

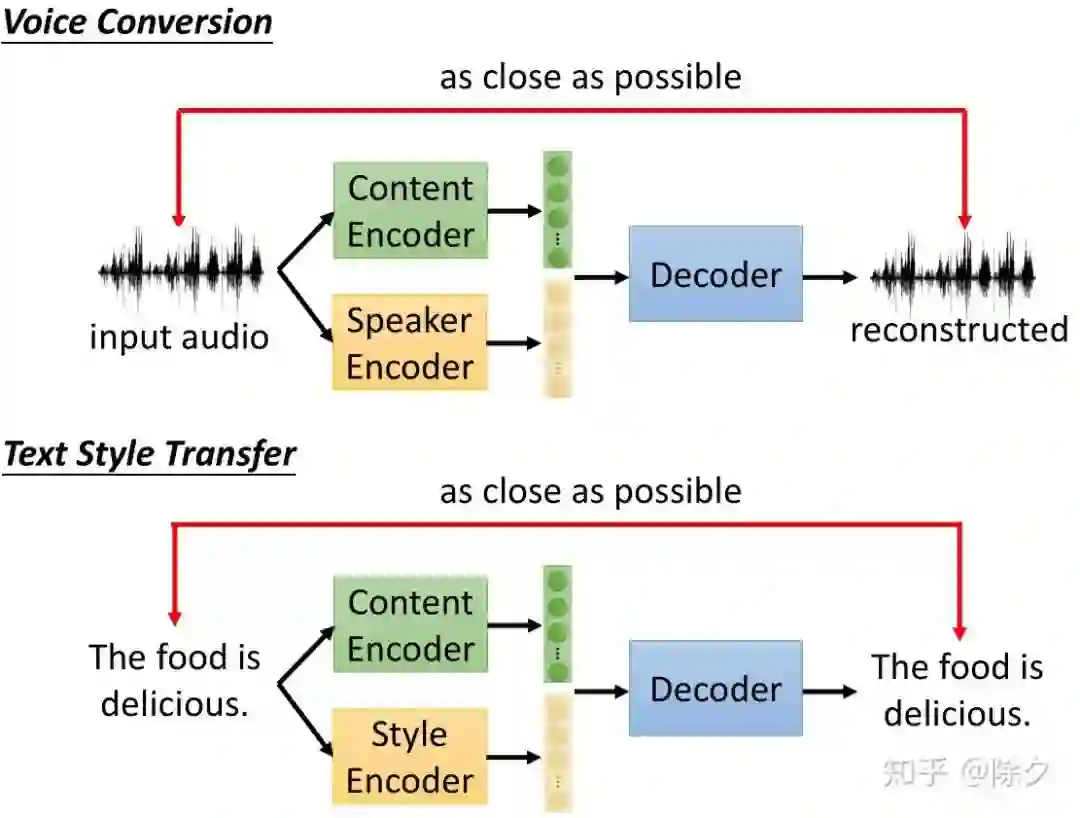
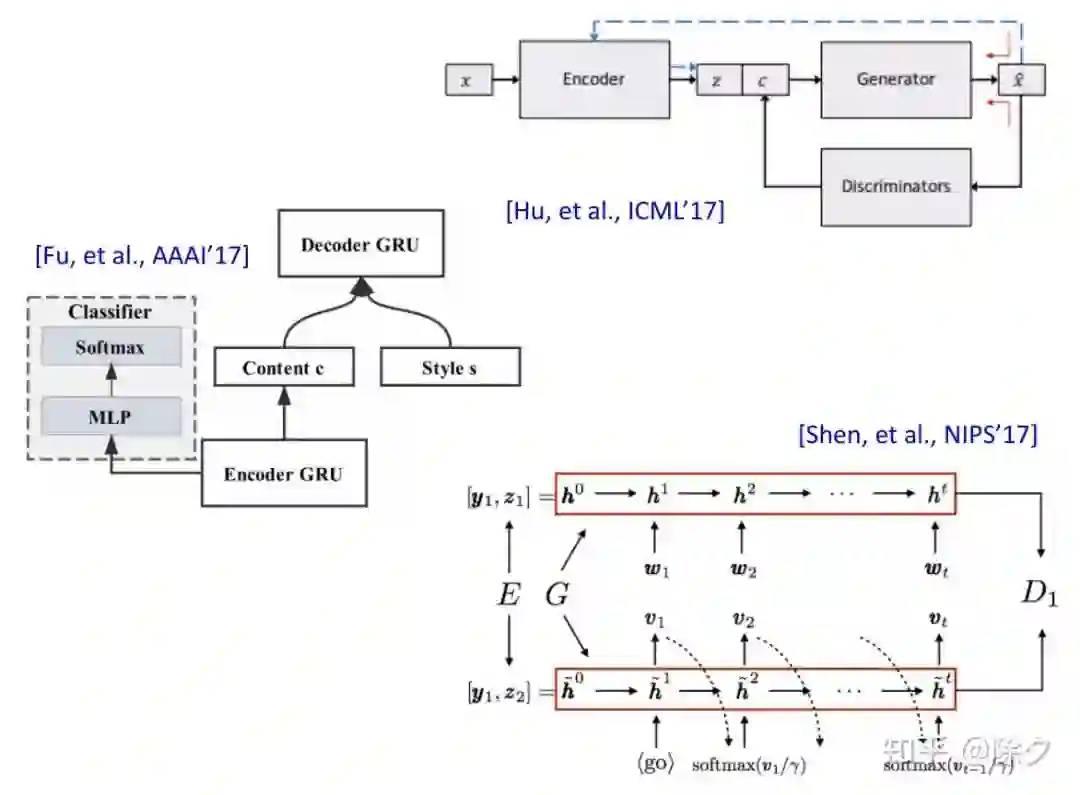
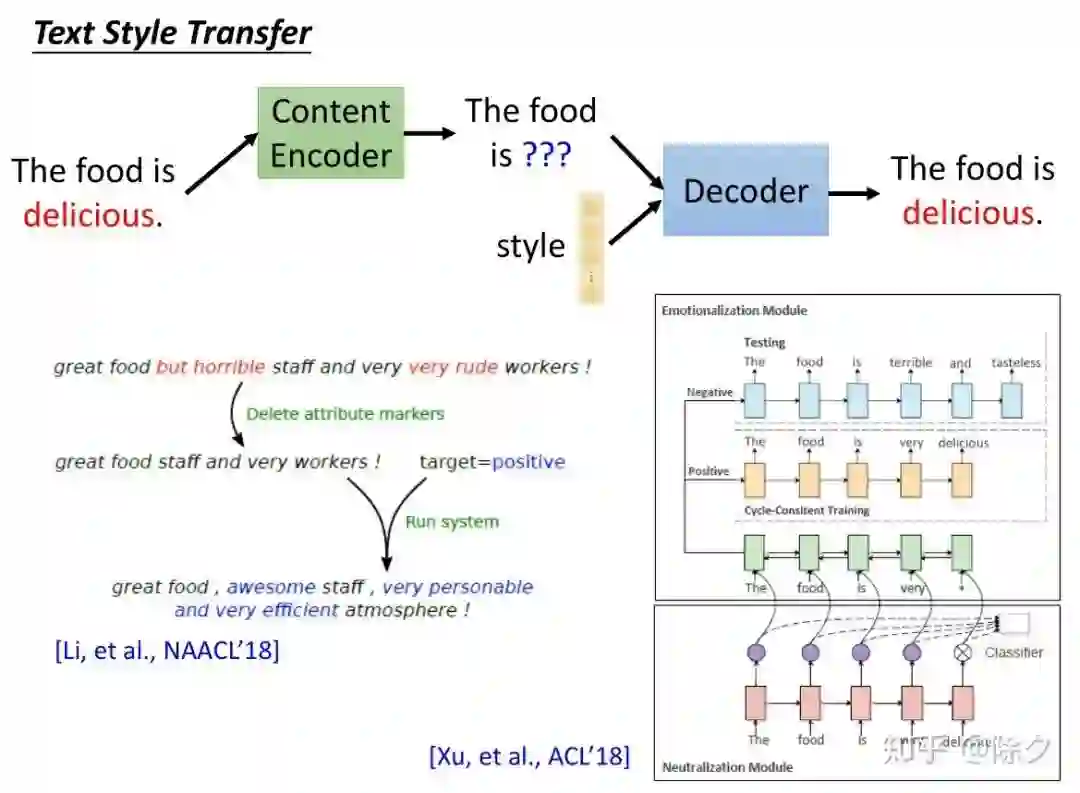
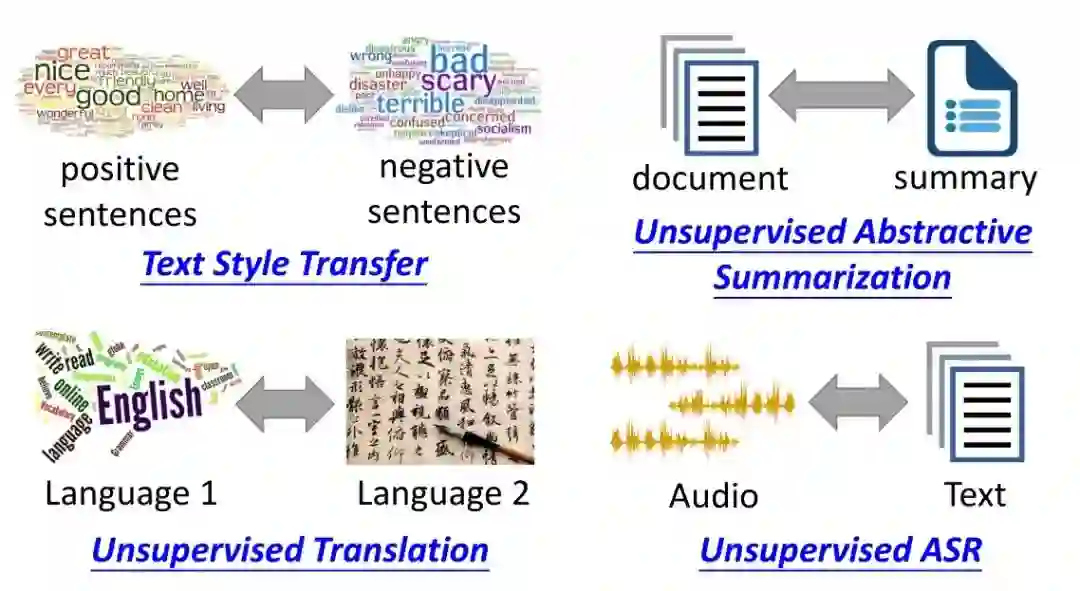

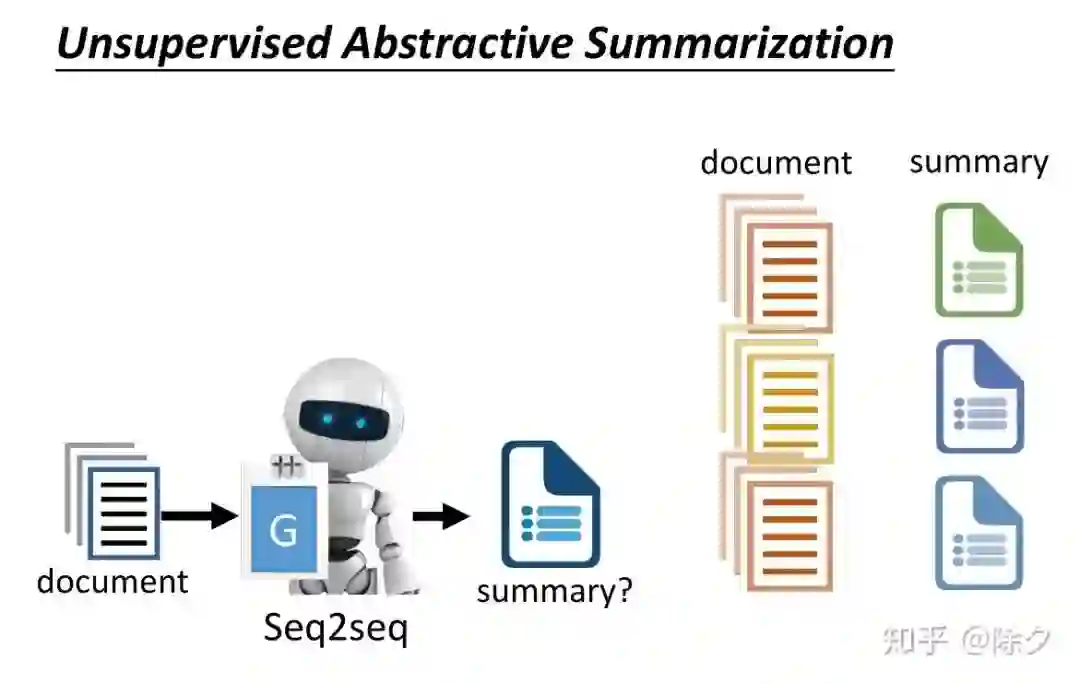
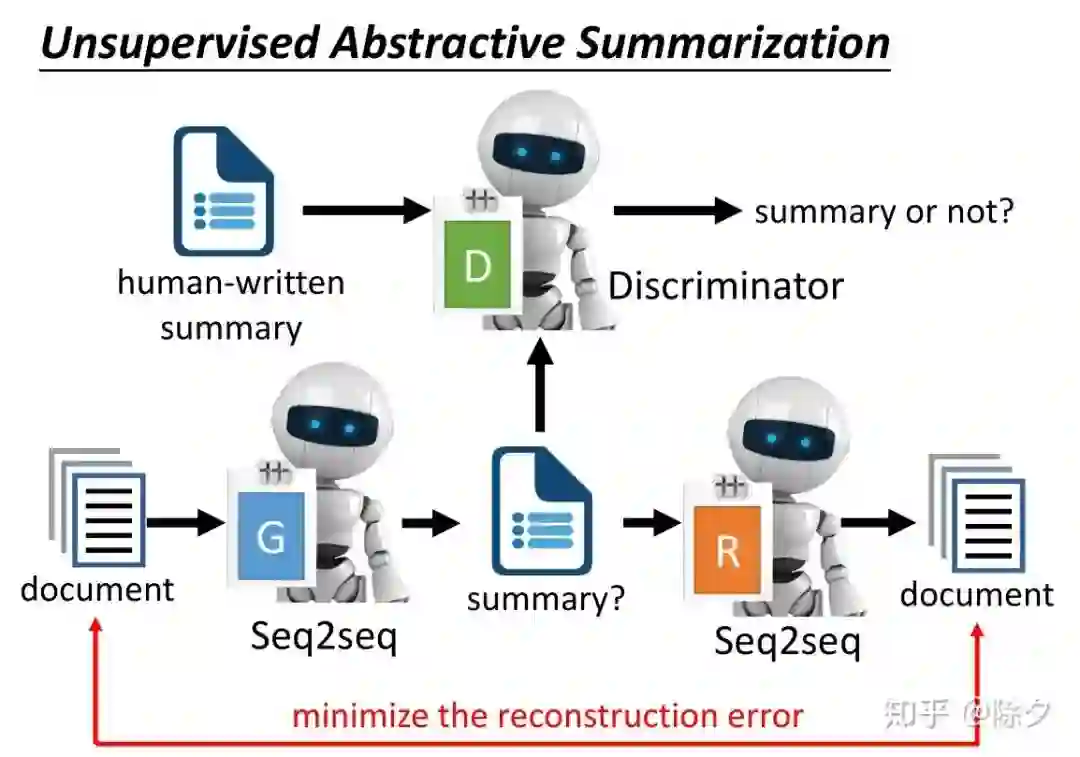
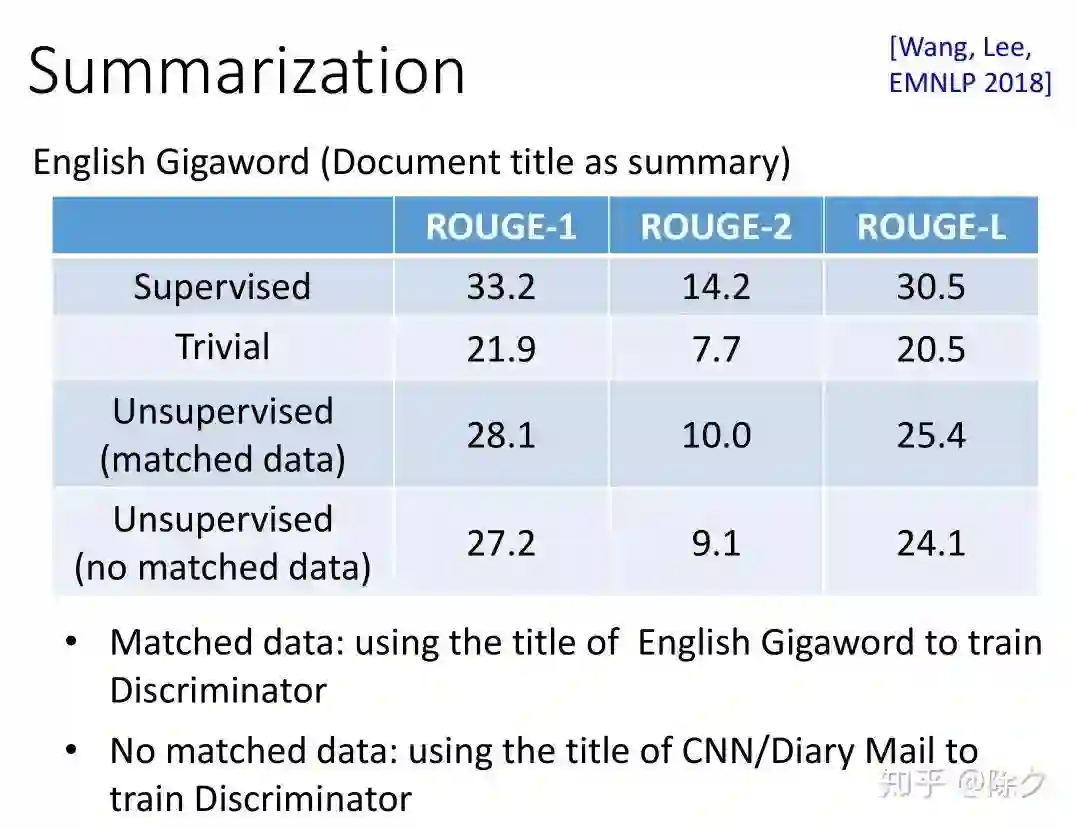
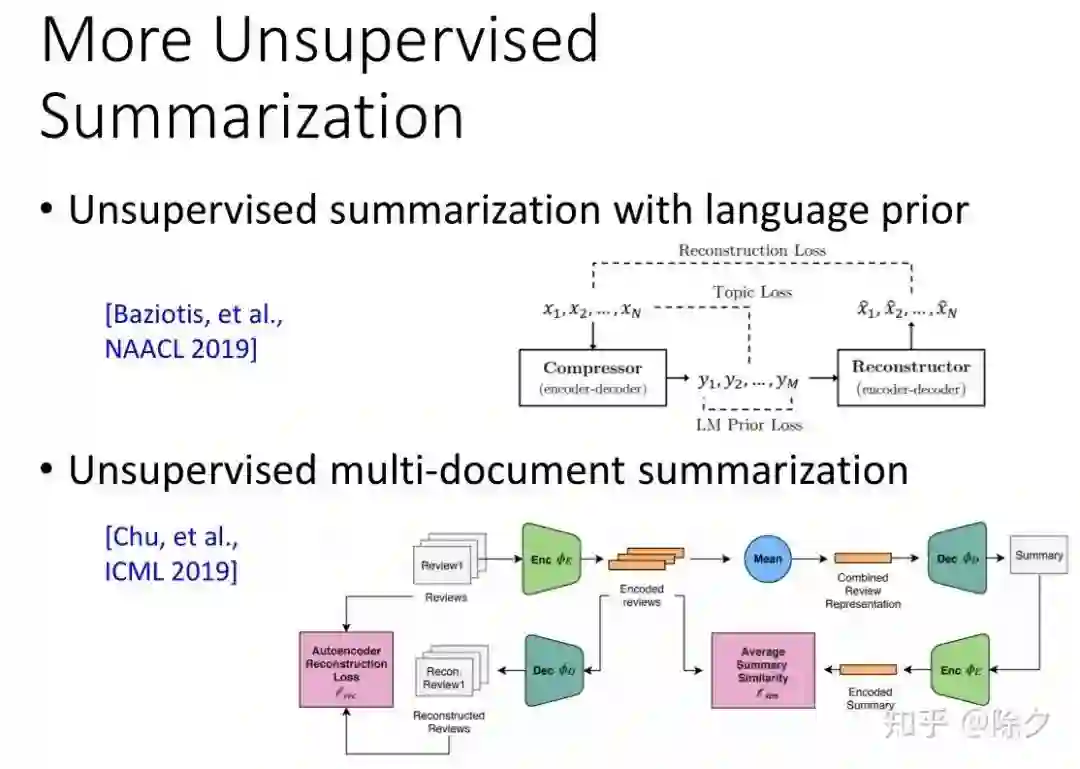

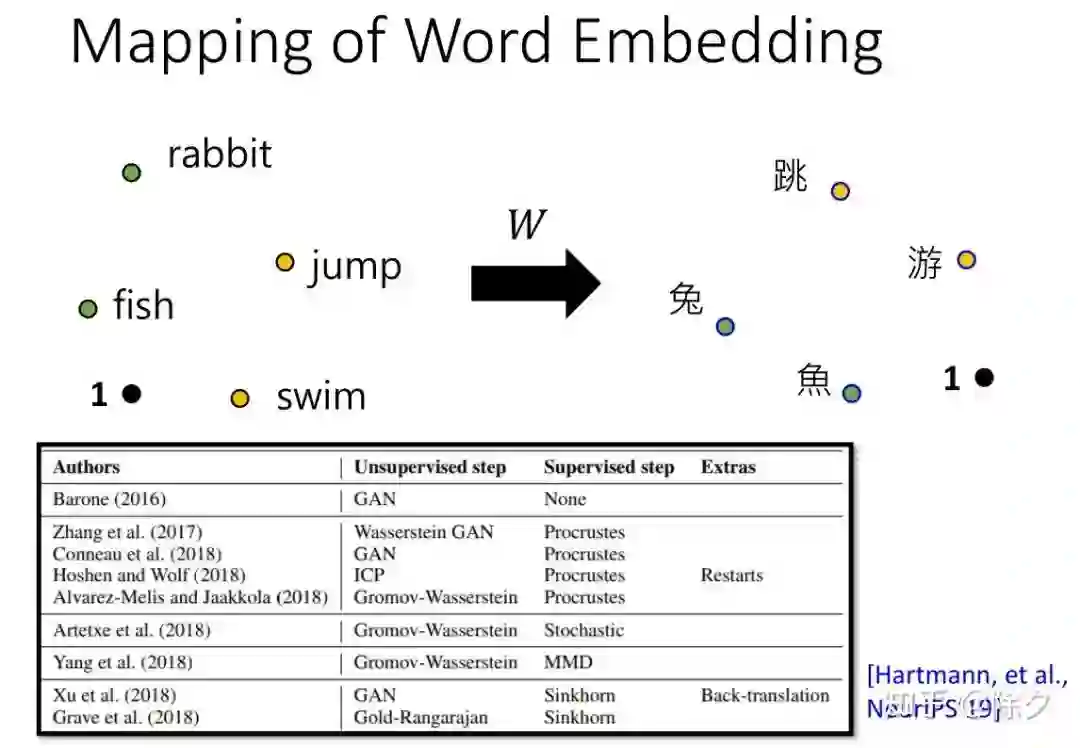
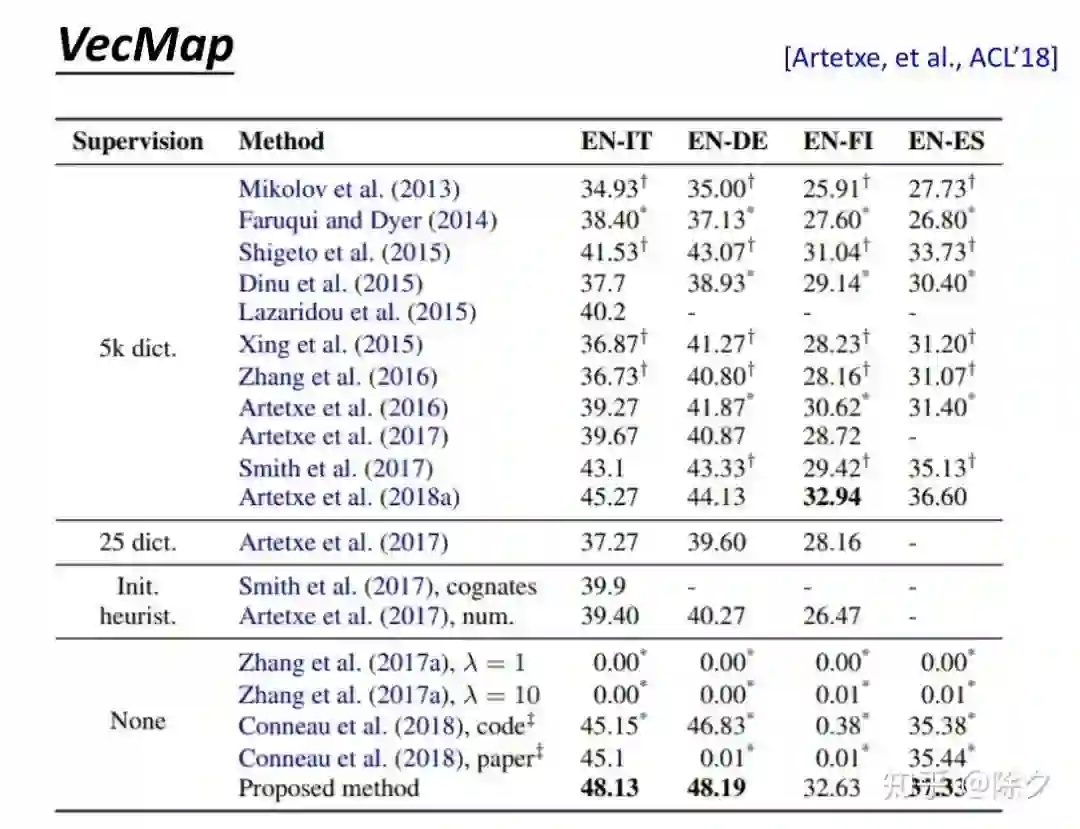
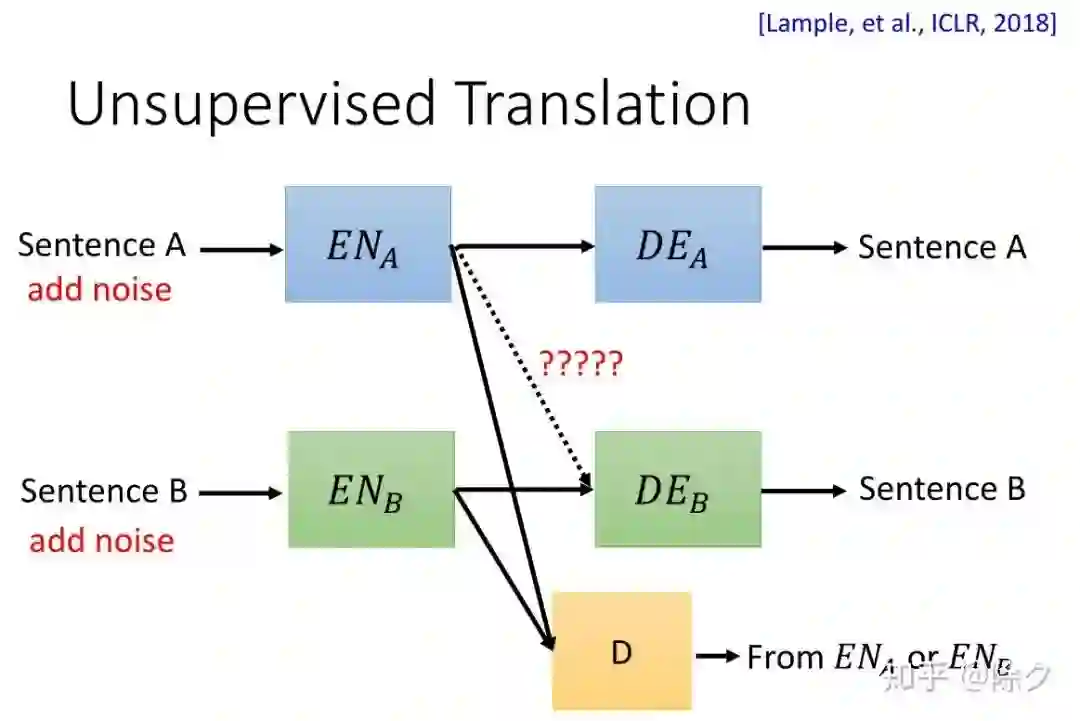
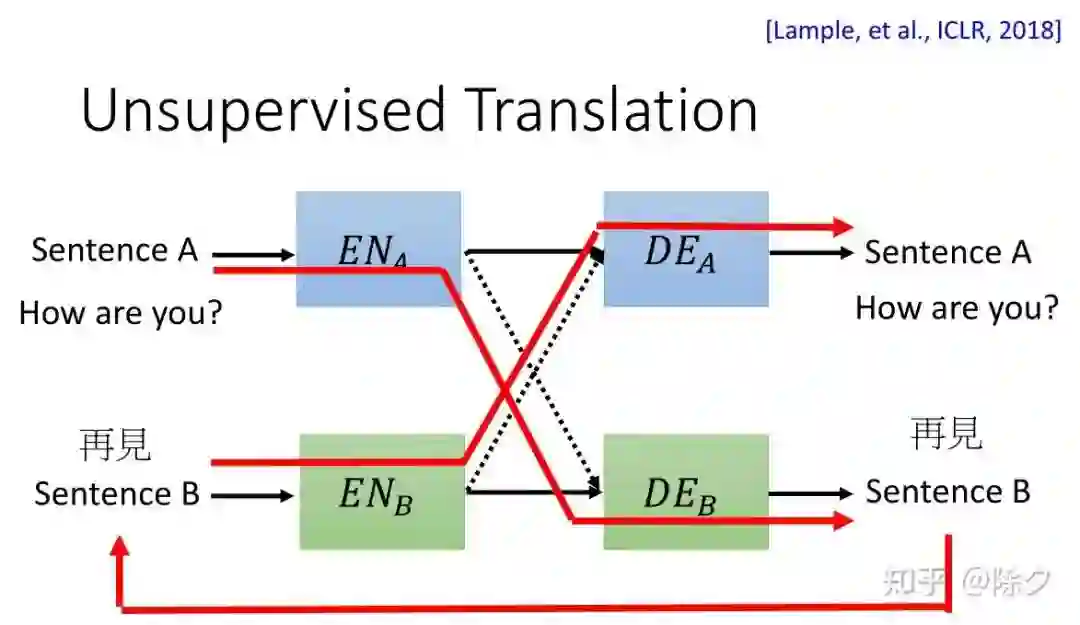
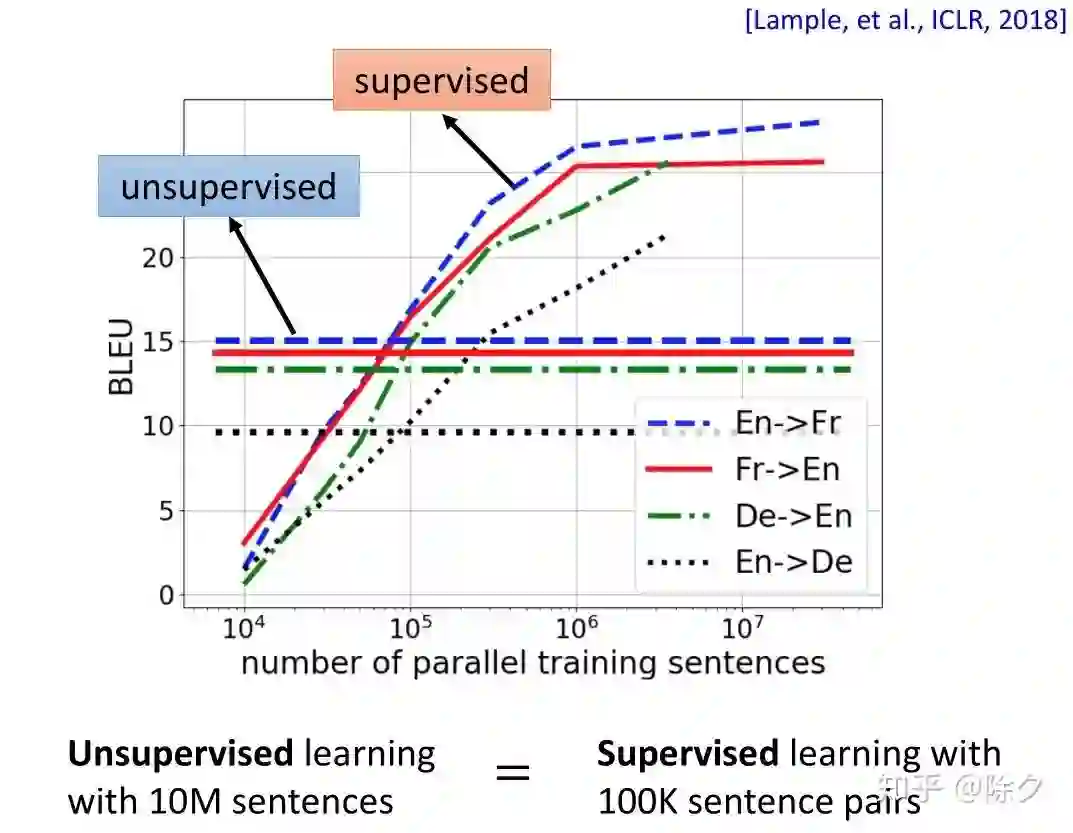
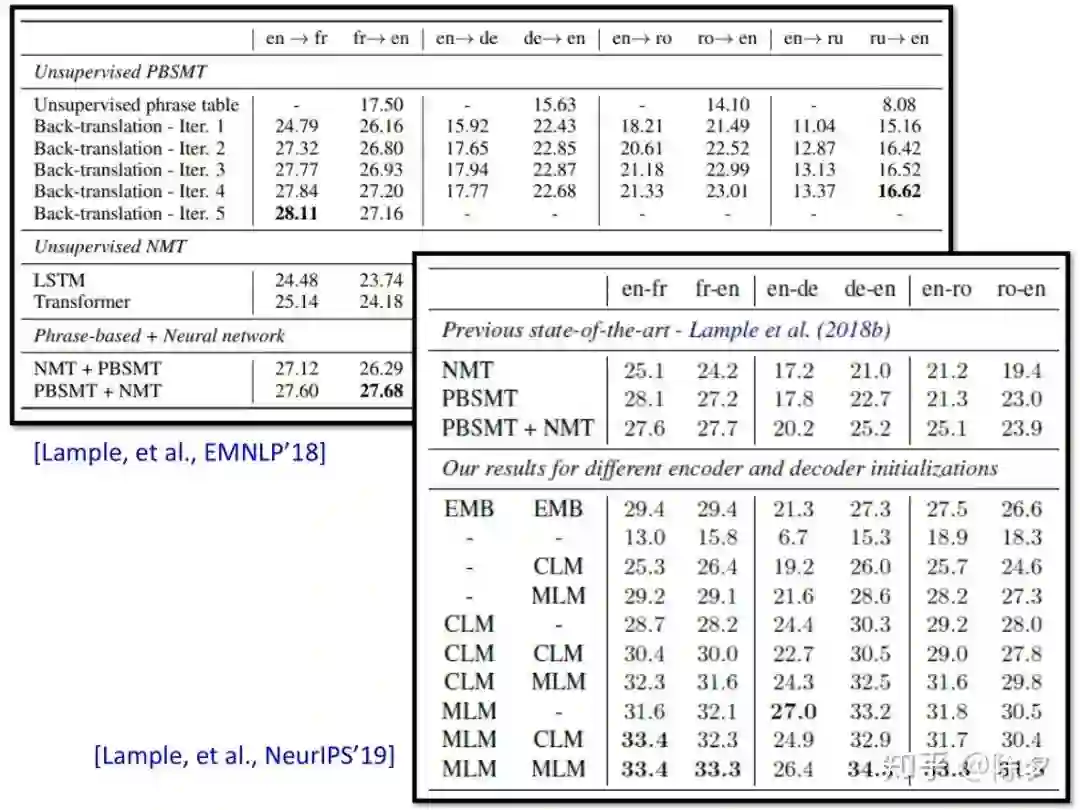
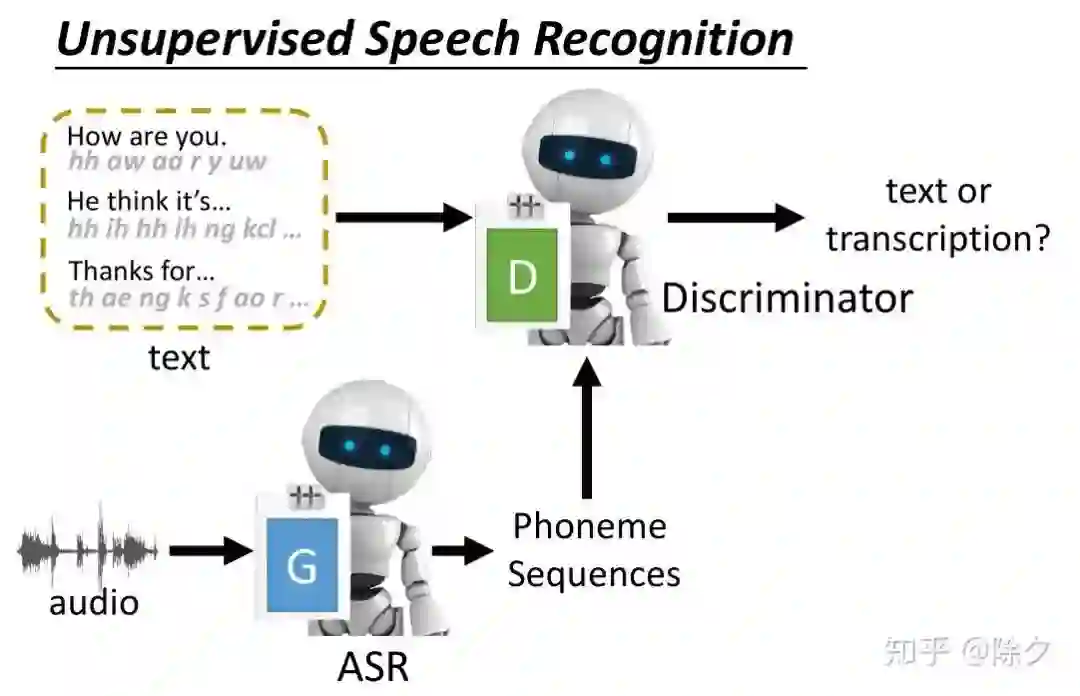
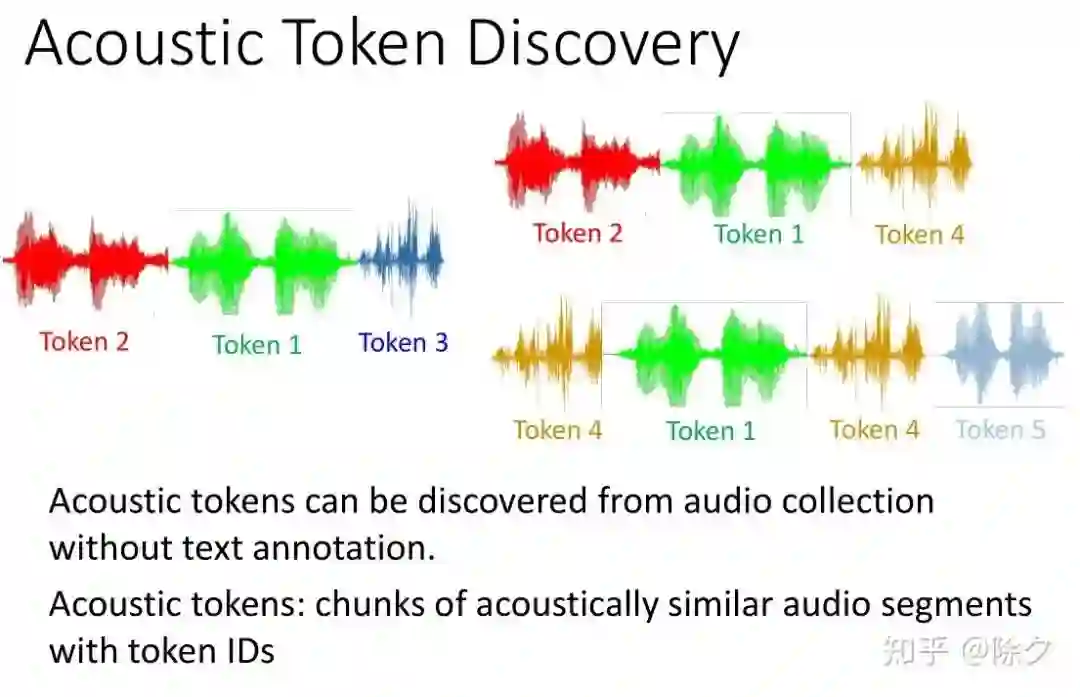
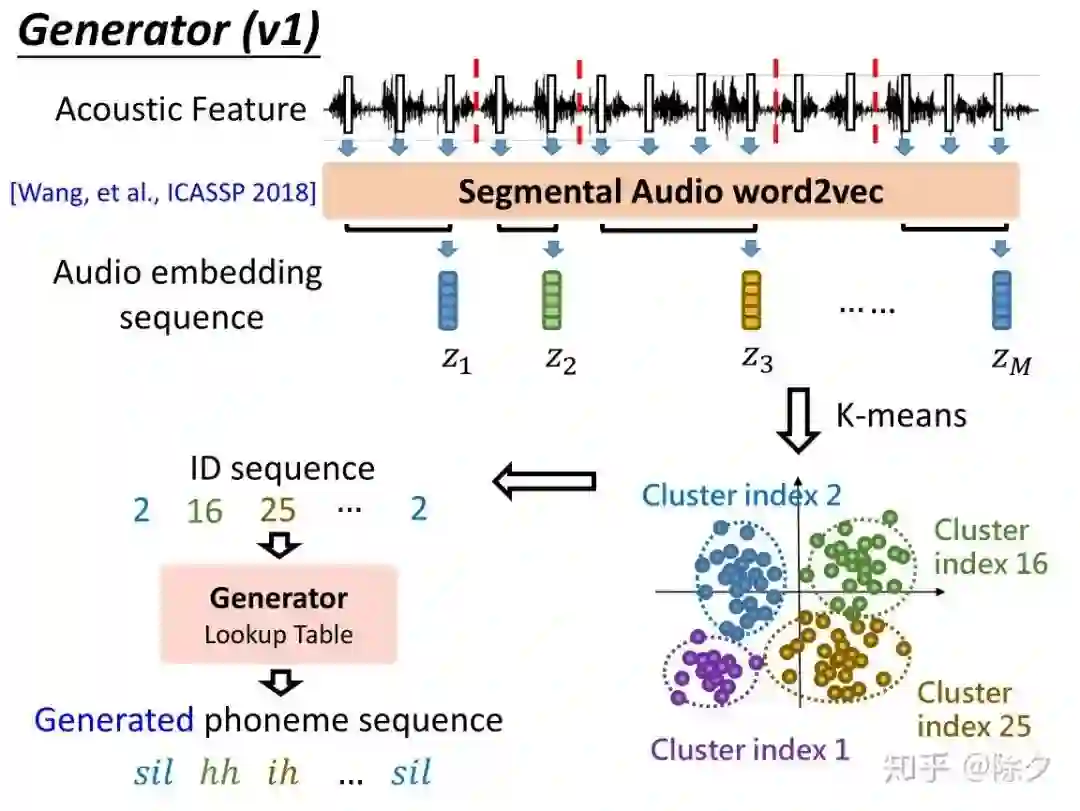
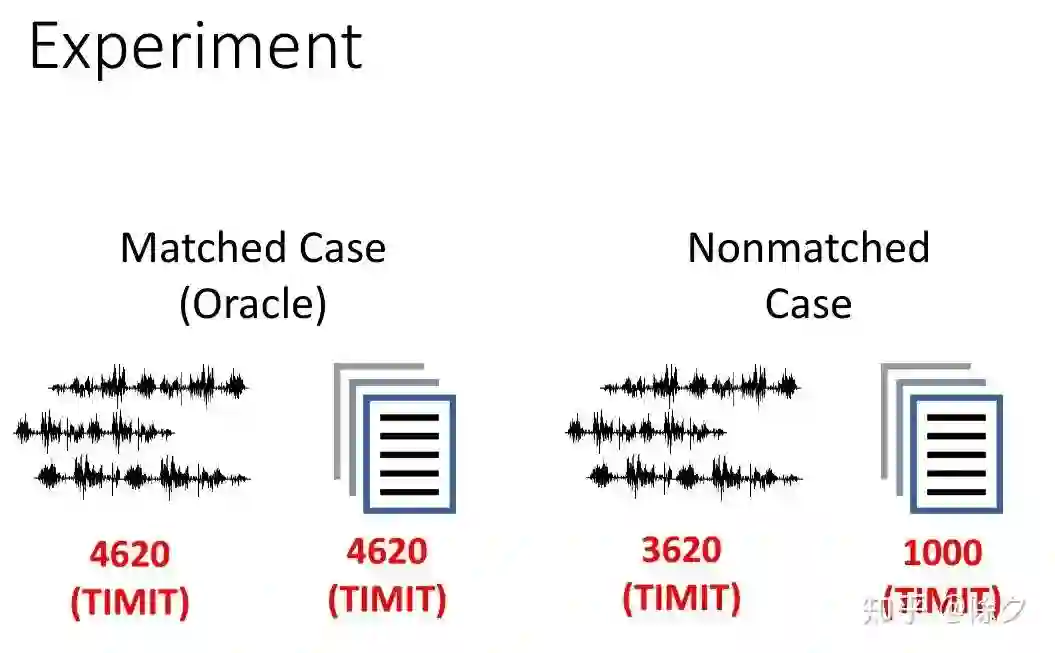
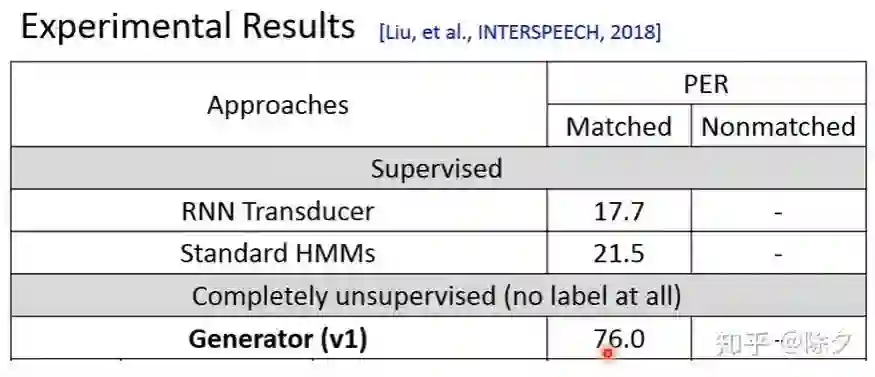
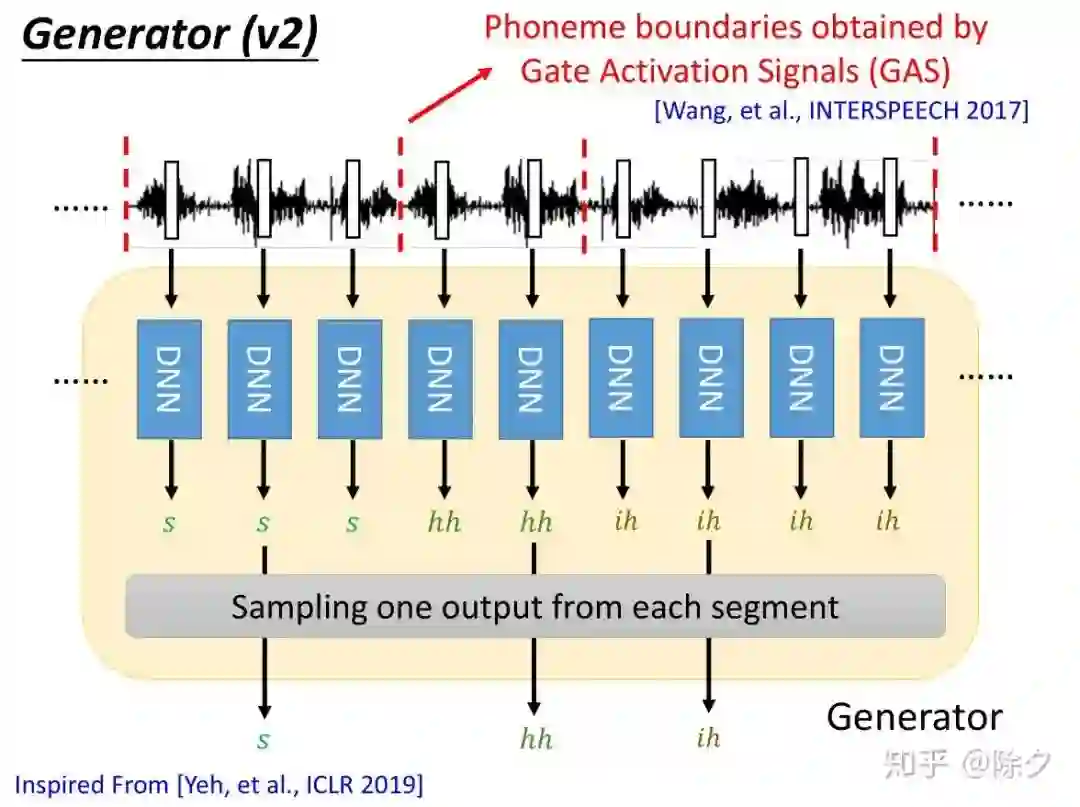
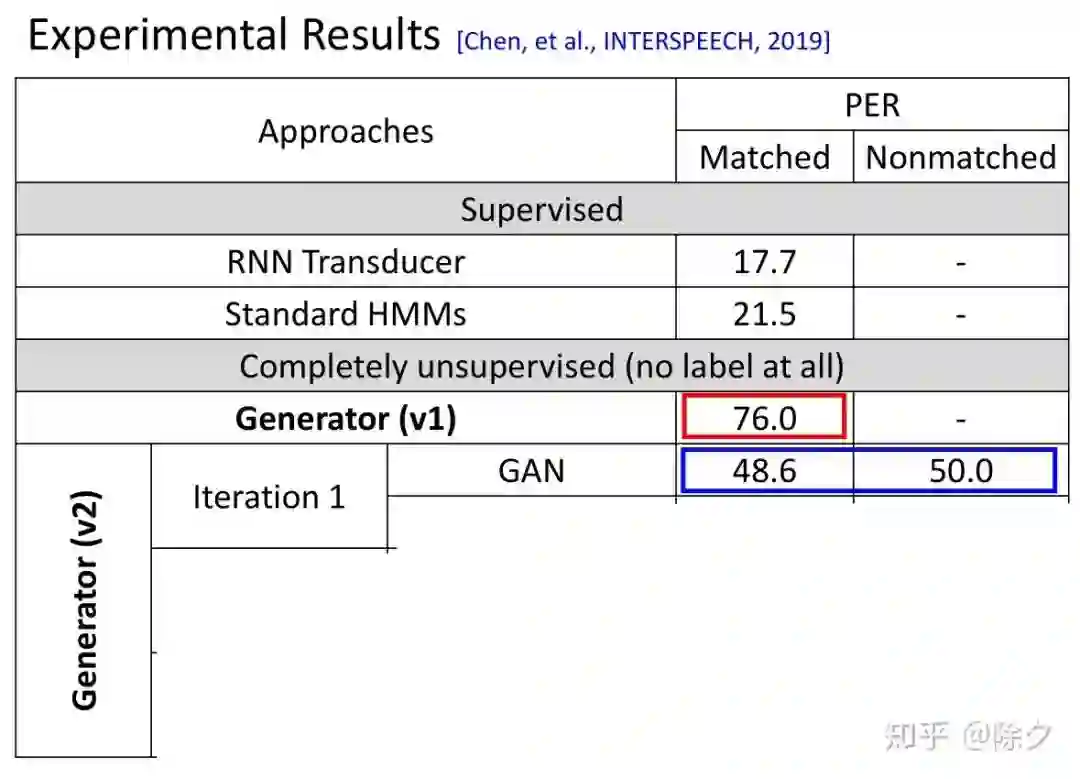
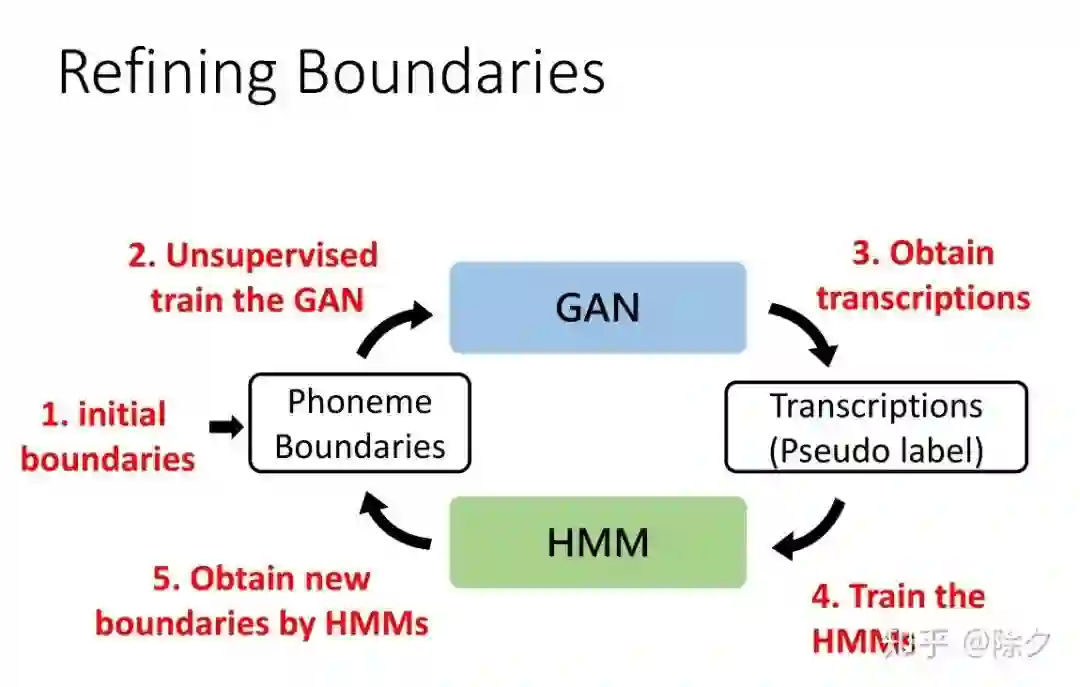
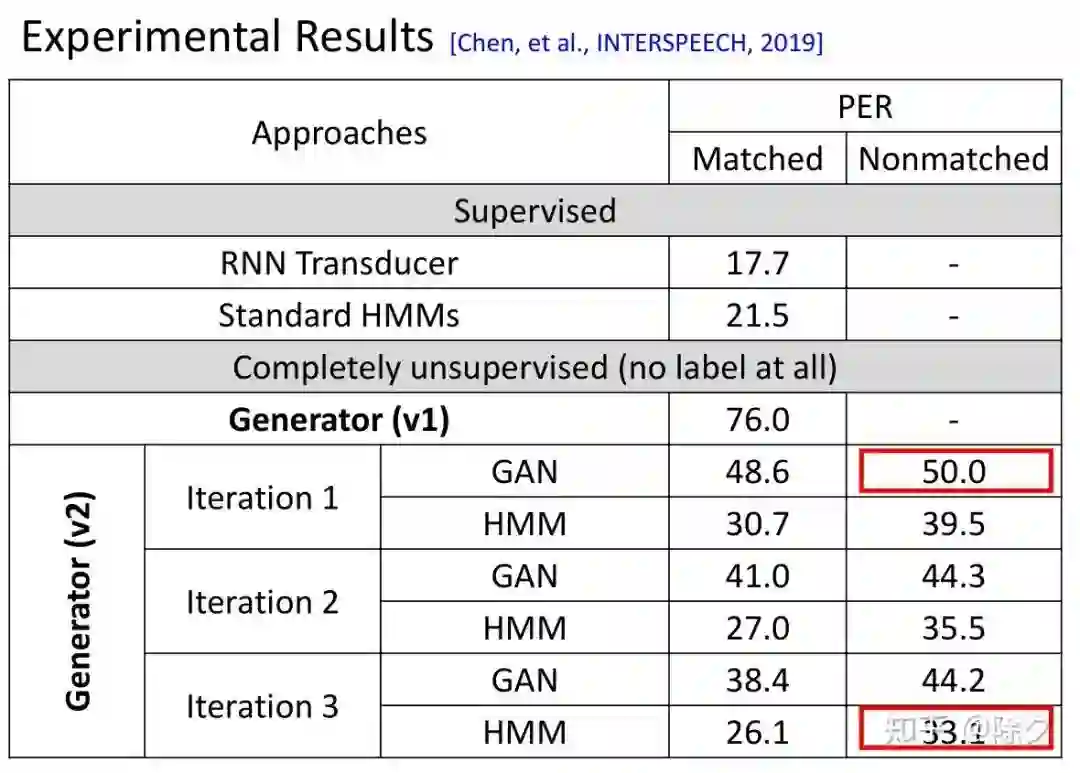

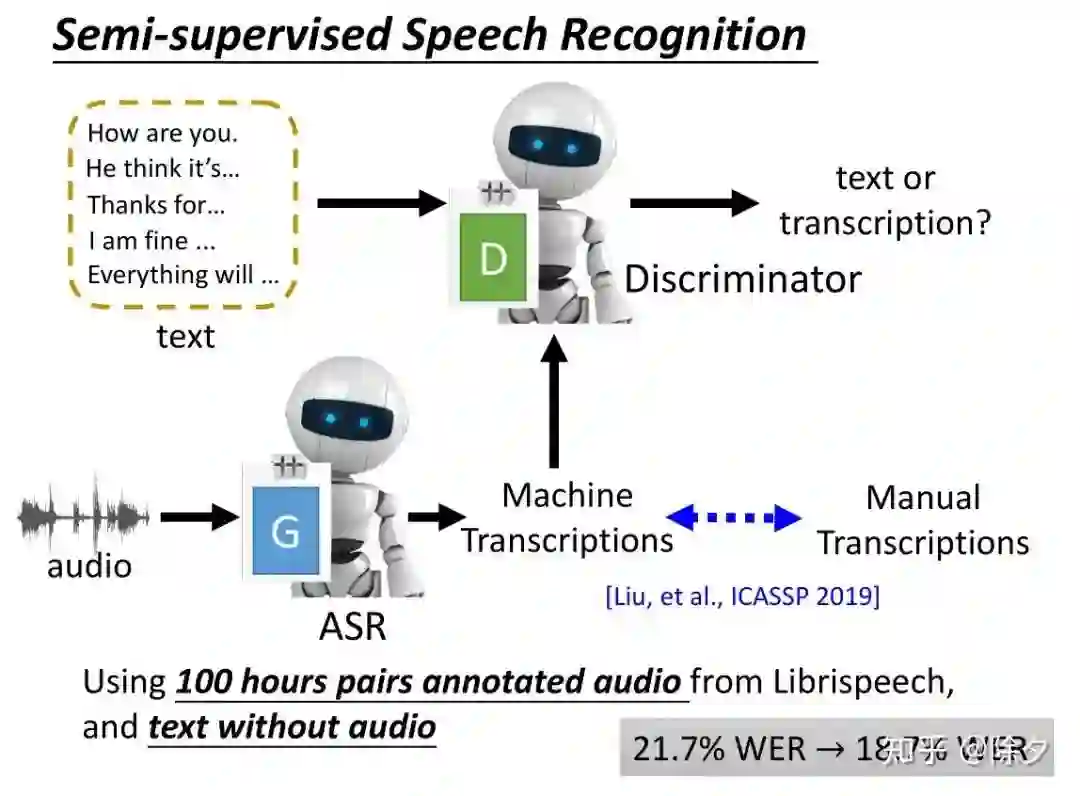


登录查看更多
相关内容




相关VIP内容
相关资讯
相关论文