ResNet被全面超越了!是那个Transformer干的,依图科技开源“可大可小”T2T-ViT,轻量版优于MobileNet
点击上方“CVer”,选择加"星标"置顶
重磅干货,第一时间送达

极市导读
又一篇Transformer来了!本文在ViT方面进行了一次突破性探索,提出了首次全面超越ResNet,甚至轻量化版本优于MobileNet系列的T2T-ViT。
Tokens-to-Token ViT: Training Vision Transformers from Scratch on ImageNet

代码链接:https://github.com/yitu-opensource/T2T-ViT
论文:https://arxiv.org/abs/2101.11986
本文是依图科技在ViT方面的一次突破性的探索。与之前ViT、Detr、Deit等不同之处在于:本文针对ViT的特征多样性、结构化设计等进行了更深入的思考,提出了一种新颖的Tokens-to-Token机制,用于同时建模图像的局部结构信息与全局相关性,同时还借鉴了CNN架构设计思想引导ViT的骨干设计。最终,仅仅依赖于ImageNet数据,而无需JFT-300M预训练,所提方案即可取得全面超越ResNet的性能,且参数量与计算量显著降低;与此同时,在轻量化方面,所提方法只需简单减少深度与隐含层维度即可取得优于精心设计的MobileNet系列方案的性能。强烈推荐各位同学研究一下该文。
前言
语言模型中主流的Transformer已经开始对CV任务开始了降维打击,比如目标检测中NETR,low-level任务中的IPT,图像分类任务中的ViT与DeiT等等。ViT方案首先将输入图像拆分为定长的tokens序列,然后采用多个Transformer层对其进行全局相关性建模并用于图像分类。但ViT背靠比ImageNet更大的训练取得了优于纯CNN的性能,但如果仅采用ImageNet的话,其性能反而不如CNN方案。
作者通过分析发现:(1) 输入图像的简单token化难以很好的建模近邻像素间的重要局部结构(比如边缘、线条等),这就导致了少量样本时的低效性;(2) 在固定计算负载与有限训练样本约束下,ViT中的冗余注意力骨干设计限制了特征的丰富性。可参考下图:

ResNet50可以逐步捕获到期望的局部结构(比如边缘、线条、纹理等),然而ViT的结构建模信息较差,反而全局相关性被更好的获取。与此同时,可以看到:ViT的特征中存在零值,这导致其不如ResNet高效,限制了其特征丰富性。
为克服上述局限性,作者提出了一种新的Tokens-to-Token Vision Transformer,T2T-ViT,它引入了(1) 层级Tokens-to-Token变换通过递归的集成近邻Tokens为Token将渐进的将图像结构化为tokens,因此局部结构可以更好的建模且tokens长度可以进一步降低;(2) 受CNN架构设计启发,设计一种高效的deep-narrow的骨干结构用于ViT。
相比标准ViT,所提T2T-ViT的参数量与MACs可以减低200%,并取得2.5%的性能提升(注仅用ImageNet从头开始训练);所提T2T-ViT同样取得了优于ResNet的性能,比如,在ImageNet数据集上,T2T-ViT-ResNet50取得了80.7%的Top1精度。可参考下图。
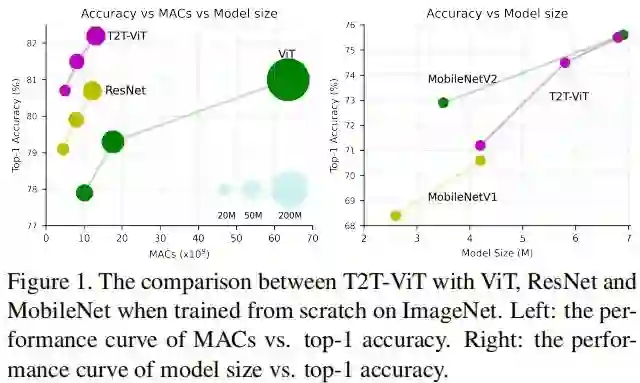
总而言之,本文的主要贡献包含以下几个方面:
-
首次通过精心设计Transformer结构在标准ImageNet数据集上取得了全面超越CNN的性能,而无需在JFT-300M数据进行预训练; -
提出一种新颖的渐进式Token化机制用于ViT,并证实了其优越性,所提T2T模块可以更好的协助每个token建模局部重要结构信息; -
CNN的架构设计思想有助于ViT的骨干结构设计并提升其特征丰富性、减少信息冗余。通过实验发现: deep-narrow结构设计非常适合于ViT。
T2TViT方法简介
前面对ViT存在的问题以及本文的主要改进思路进行了简单的介绍,接下来我们将着重针对本文所提的T2T、deep-narrow骨干设计进行重点介绍与分析。
Tokens-to-Token
Tokens-to-Token(T2T)模块旨在克服ViT中简单Token化机制的局限性,它采用渐进式方式将图像结构化为token并建模局部结构信息;而Tokens的长度可以通过渐进式迭代降低,每个T2T过程包含两个步骤:Restructurization与SoftSplit,见下图。
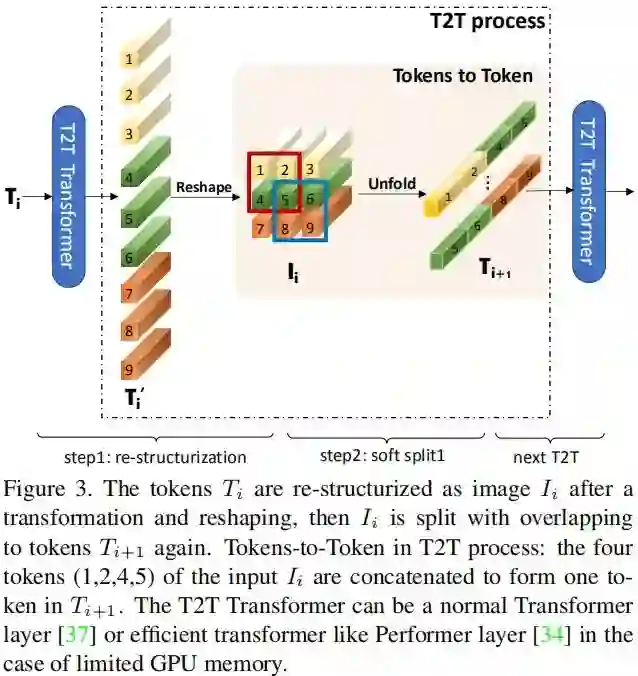
Re-structurization
如上图所示,给定Tokens序列T,将通过自注意力模块对齐进行变换处理,可以描述为:
注:MSA表示多头自注意力模块,MLP表示多层感知器。经过上述变换后,Tokens将在空间维度上reshape为图像形式,描述如下:
注:Reshape表示将 转换为 。
Soft Split
正如上图所示,在得到重结构化图像I后,作者对其进行软拆分操作以建模局部结构信息,降低Tokens长度。为避免图像到tokens过程中的信息损失,将图像拆分为重叠块,也就是说:每个块将与近邻块之间构建相关性。每个拆分块内的Token将通过Concat方式变换为一个Token(即Tokens-to-Token),因此可以更好的建模局部信息。作者假设每个块大小为 ,重叠尺寸为s,padding为p,对于重建图像 ,其对应的输出Token 可以表示为如下尺寸:
注:每个拆分块尺寸为 。最后将所有块在空域维度上flatten为Token 。这里所得到的输出Token将被送入到下一个T2T处理过程。
T2T module
通过交替执行上述Re-structurization与Soft Split操作,T2T模块可以逐渐的减少Token的长度、变换图像的空间结构。T2T模块可以表示为如下形式:
对于输入图像 ,作者采用SoftSplit操作将其拆分为Token: 。在完成最后的迭代后,输出Token 具有固定IG长度,因此T2T-ViT可以在 上建模全局相关性。
另外,由于T2T模块中的Token长度要比常规形式的更大,故而MAC与内存占用会非常大。为克服该局限性,在T2T模块中,作者设置通道维度为32(或者64)以降低MACs。
T2T-ViT Backbone
由于ViT骨干中的不少通道是无效的,故而作者计划设计一种高效骨干以降低冗余提升特征丰富性。T2T-ViT将CNN架构设计思想引入到ViT骨干设计以提升骨干的高效性、增强所学习特征的丰富性。由于每个Transformer具有类似ResNet的跳过连接,一个最直接的想法是采用类似DenseNet的稠密连接提升特征丰富性;或者采用Wide-ResNet、ResNeXt结构改变通道维度。本文从以下五个角度进行了系统性的比较:
-
Dense Connection,类似于DenseNet; -
Deep-narrow vs shallow-wide结构,类似于Wide-ResNet一文的讨论; -
Channel Attention,类似SENet; -
More Split Head,类似ResNeXt; -
Ghost操作,类似GhostNet。
结合上述五种结构设计,作者通过实验发现:(1) Deep-Narrow结构可以在通道层面通过减少通道维度减少冗余,可以通过提升深度提升特征丰富性,可以减少模型大小与MACs并提升性能;(2) 通道注意力可以提升ViT的性能,但不如Deep-Narrow结构高效。
基于上述结构上的探索与发现,作者为T2T-ViT设计了Deep-Narrow形式的骨干结构,也就是说:更少的通道数、更深的层数。对于定长Token
,将类Token预期Concat融合并添加正弦位置嵌入(Sinusoidal Position Embedding, SPE),类似于ViT进行最后的分类:
T2T-ViT Architecture
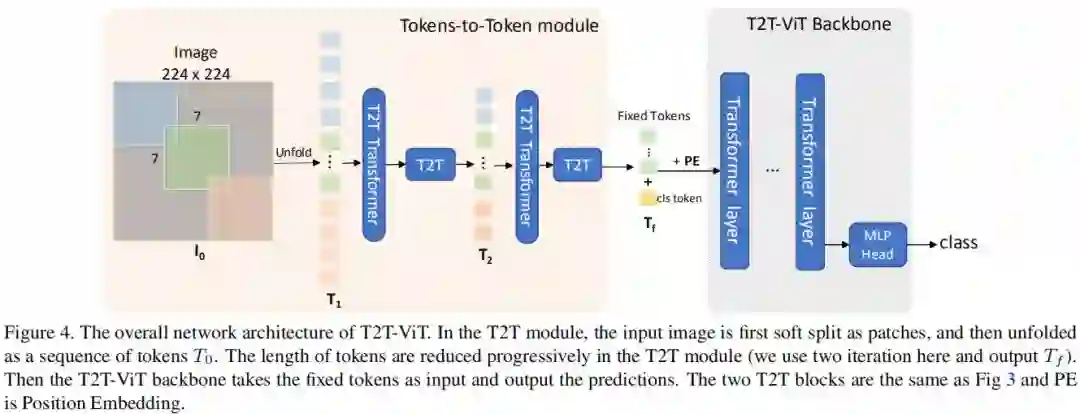
上图给出了T2T-ViT的网络结构示意图,它包含T2T模块与T2T骨干两部分。上图给出了n=2的结构示意图(即n+1=3个soft split,n个Re-structurization)。每个Soft Split的块大小分别为[7,3,3],重叠为[3,1,1]。
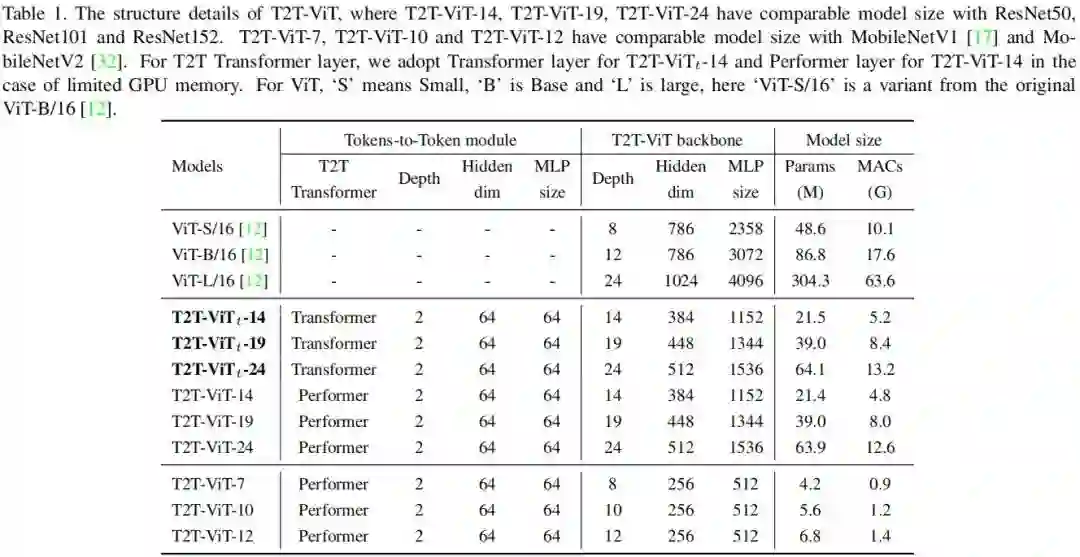
为更好的与常见手动设计CNN进行对比,作者设计了不同复杂度的T2T-ViT模型,见上表。比如对标ResNet50的T2T-ViT-14,对标ResNet101的T2T-ViT-19,对标ResNet152的T2T-ViT-24,对标MobileNetV1、MoblieNetV2的T2T-ViT-7,T2T-ViT-10,T2T-ViT-12。
实验
为更好说明所提方案的有效性,将其与ViT进行了对比,结果见下表。从表中数据可以看到:相比ViT,所提方案具有更少的参数量、MAC,但取得了更高的性能。
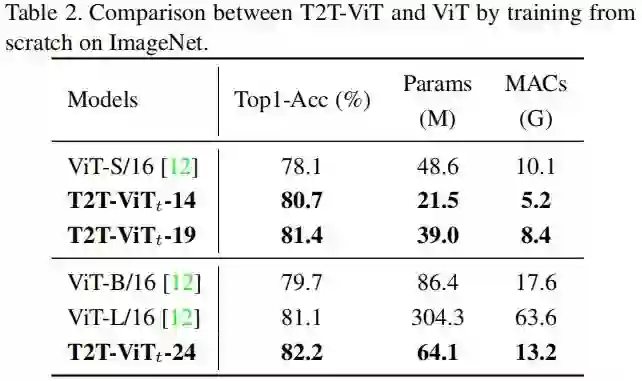
下表给出了所提方案与ResNet的对比。从中可以看到:在相同模型大小与MACs约束下,所提方案能够以1%-2.5%的性能优势超过ResNet。
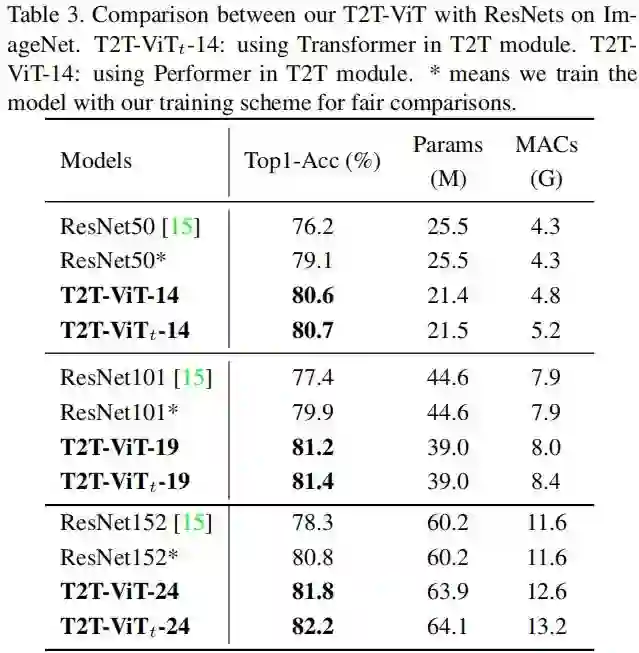
与此同时,本文还给出了所提方案与轻量化网络MobileNet系列的对比,见下表。可以看到:在轻量化网络层面,所提方案可以取得比MobileNet系列更好的性能。注:由于MobileNet系列采用了高效卷积(Depthwise)操作导致其计算量要比T2T-ViT稍低,而T2T-ViT的设计则更为简单,只需要调整深度、隐含层维度即可得到不同计算量的模型。
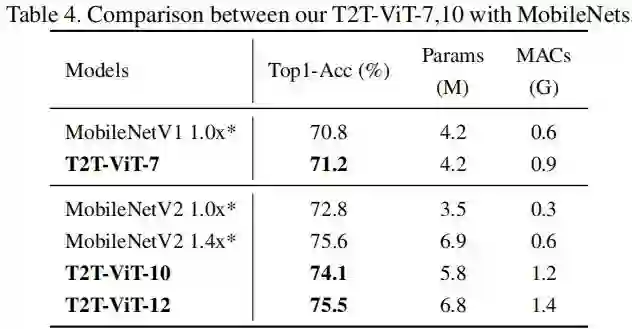
最后还给出了不同CNN结构设计思想在T2T-ViT的性能对比,见下表。
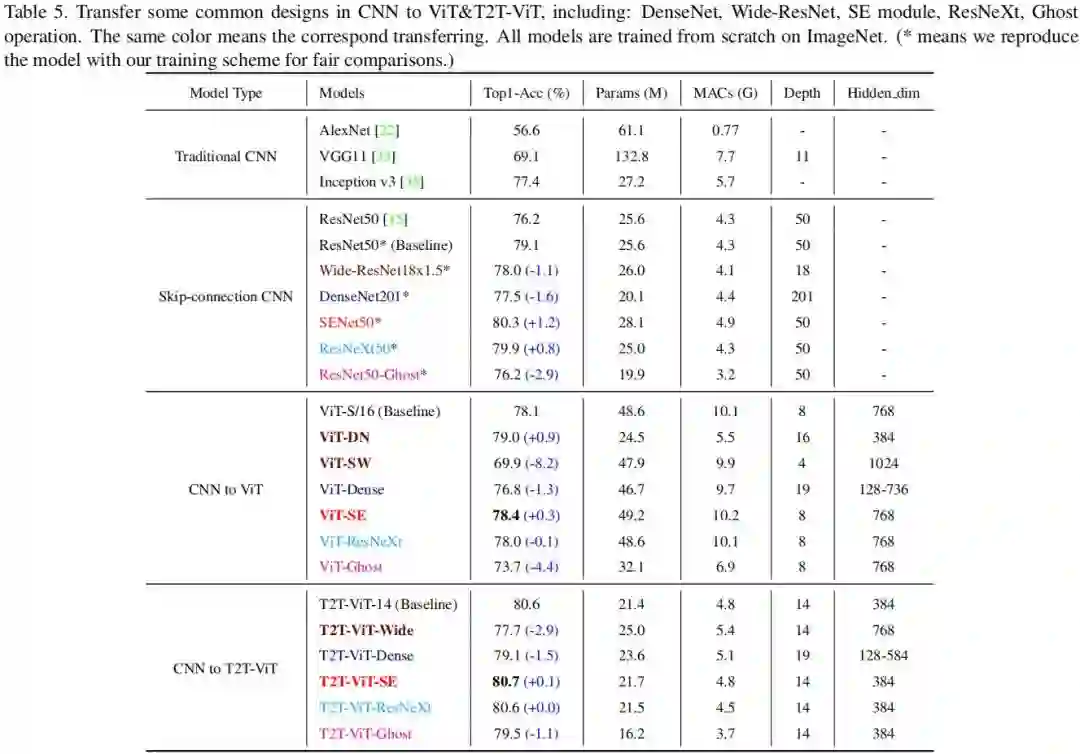
从上表可以看到:
-
无论是SE还是Deep-Narrow结构有益于T2T-ViT,但Deep-Narrow结构设计更为有效; -
稠密连接会损害ViT和T2T-ViT的性能; -
SE有助于提升ViT与T2T-ViT的性能; -
ResNeXt结构与ViT与T2T-ViT的影响非常小,几乎可以忽略; -
Ghost可以进一步压缩T2T-ViT的模型大小、降低MACs,但会造成性能的下降。
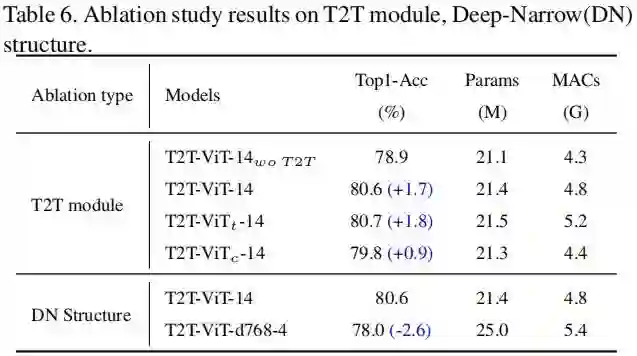
最后的最后,本文还对所提T2T模块与Deep-Narrow结构设计进行了消融分析,结果见上表。从中可以看到:(1) T2T模块比卷积更优,这是因为它可以同时建模全局相关性与结构信息;(2) 相比Shallow-Wide结构,Deep-Narrow结构可以带来2.9%的性能提升。
全文到此结束,更多消融实验分析建议好看原文,笔者强烈建议对Transformer感兴趣的同学研究一下该文,文中不少思想值得各位思考与借鉴。
代码
开源的才是好工作,在paper放出来之前先开源的更是好工作。就在昨天,依图科技就将T2T-ViT相关code与预训练模型在github上进行了开源。
在CVer公众号后台回复:T2TViT,即可获得上述论文、code以及预训练模型下载链接。
CV资源下载
后台回复:Transformer综述,即可下载两个最新的视觉Transformer综述PDF,肝起来!
重磅!CVer-Transformer交流群成立
扫码添加CVer助手,可申请加入CVer-Transformer方向 微信交流群,也可申请加入CVer大群,细分方向已涵盖:目标检测、图像分割、目标跟踪、人脸检测&识别、OCR、姿态估计、超分辨率、SLAM、医疗影像、Re-ID、GAN、NAS、深度估计、自动驾驶、强化学习、车道线检测、模型剪枝&压缩、去噪、去雾、去雨、风格迁移、遥感图像、行为识别、视频理解、图像融合、图像检索、论文投稿&交流、Transformer、PyTorch和TensorFlow等群。
一定要备注:研究方向+地点+学校/公司+昵称(如Transformer+上海+上交+卡卡),根据格式备注,才能通过且邀请进群

▲长按加微信群

▲长按关注CVer公众号
整理不易,请给CVer点赞和在看!



