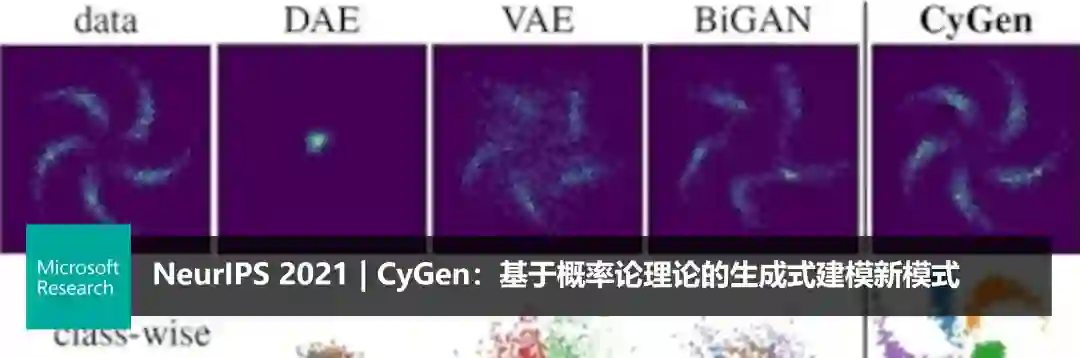
NeurIPS 2021 | 从残差编码到条件编码,构建基于上下文的视频压缩框架DCVC

(本文阅读时间:10分钟)
编者按:传统视频压缩方法多采用残差编码框架,虽简单有效但却并不是最优解,其熵往往大于或等于条件编码的熵。通过从残差编码到条件编码的转换,微软亚洲研究院多媒体计算组的研究员们构建了一种基于上下文的视频压缩框架(DCVC),为基于深度学习的视频压缩提供了新思路和新方法。实验表明,该视频压缩框架比常用的残差编码框架有更低的信息熵下界,且能够自适应学习帧内编码和帧间编码,适用于对高频细节的恢复。作为一种可拓展性非常强的框架,DCVC 也将在未来继续发挥其强大的压缩性能。相关论文已被 NeurIPS 2021 接收。
视频压缩的目标是以最小的码率代价来获得最好的重建质量。大多数已有视频压缩方法都采用残差编码框架。就压缩比而言,这是一种次优的解决方案,通过用简单的减法来去除帧间冗余,其熵大于或等于条件编码的熵。因此,微软亚洲研究院的研究员们提出了一种基于上下文的视频压缩框架(Deep Contextual Video Compression, DCVC)来实现从残差编码到条件编码的范式转换。相关论文“Deep Contextual Video Compression”已被 NeurIPS 2021 收录。

论文链接:
https://arxiv.org/abs/2109.15047
对基于深度学习的视频压缩,研究员们定义和设计了一种高效的条件编码框架,将时域上下文特征作为条件输入去帮助编解码器对当前帧的编码,从而充分挖掘条件编码的潜力。而这种设计也便于充分利用高维特征来帮助视频高频细节获得更好的重建质量。实验表明,研究员们所提出的 DCVC 相比 x265 (veryslow) 获得了26.0%的码率节省(PSNR 为指标)。与此同时,DCVC 是一个拓展性非常强的框架,其里面的上下文特征可以灵活设计。在 DCVC 下,最新的方法相比 H.265-HM 有14.4%的码率节省(PSNR 为质量评价指标)。如果以 MS-SSIM 为质量评价指标,相比 H.266-VTM 则有21.1%的码率节省。
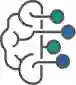
从1988年的 H.261 到2020年发布的 H.266,近30年来所有传统的视频编码标准都是基于残差编码的框架。在残差编码中,预测帧先会从之前已经解码的帧中生成出来,然后再计算当前帧与预测帧的残差。该残差会被编码变成码流,解码器将码流解码并获得重建后的残差,最后和预测帧相加获得解码帧。残差编码是一种简单高效的方式,但它的熵大于或等于条件编码的熵,并不是最优的方式。
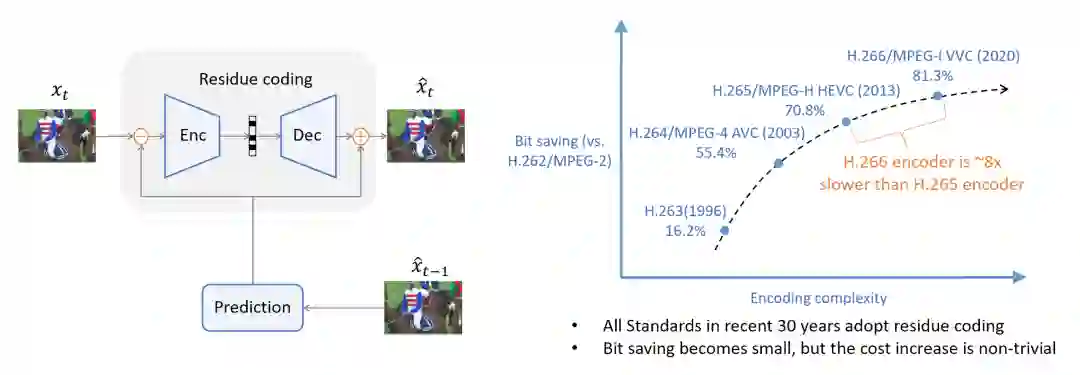
图1: 残差编码框架图和各代传统视频编码标准压缩效率对比
另外从理论上讲,当前待编码的像素与之前所有已经重建的像素都可能有相关性。对于传统编码器,由于搜索空间巨大,使用人为制定的规则去显示地挖掘这些像素之间的相关性是一件非常困难的事情。因此残差编码假设当前像素只和预测帧对应位置的像素具有强相关性, 这是条件编码的一个特例。考虑到残差编码的简单性,最近的基于深度学习的视频压缩方法也大多采用残差编码,使用神经网络去替换传统编码器中的各个模块。而研究者们认为,与其将视野局限在残差编码,更应该充分利用深度学习的优势去挖掘这些像素之间的相关性来设计条件编码。所以微软亚洲研究院的研究员们设计了一种基于条件编码的视频压缩方法,方法对比如图2所示。
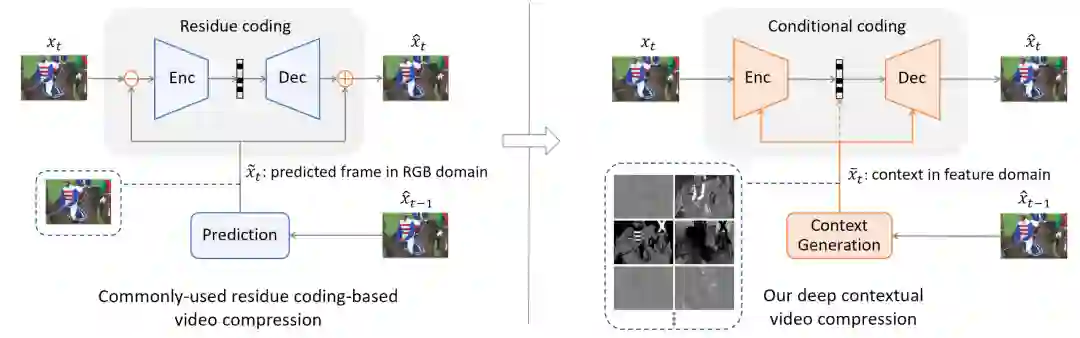
图2: 残差编码到条件编码的范式转换
通常,在设计一个基于深度学习的条件编码框架时会遇到以下问题:什么是条件?如何利用条件?如何学习条件?
准确来讲, 条件可以是任何能帮助当前帧编码的信息。一种简单直接的方法是把预测帧作为条件,这是可实行的。但预测帧只包含 RGB 三个通道的像素信息,这会限制条件编码的潜力。那么,既然已经采纳条件编码,为什么不可以让网络自动学习它所需要的条件?在 DCVC 里,网络在时域上学习生成上下文特征,该下文特征作为条件输入去帮助当前帧的编码和解码。
DCVC 实现框架如图3所示。至于如何学习上下文特征,研究员们首先设计了一个特征提取器将之前解码帧从像素域转换到特征域,同时利用运动估计去学习运动向量。该运动向量在经过编码和解码之后会指导网络从哪里提取特征。考虑到运动补偿引发的空间不连续性,研究员们又设计了一个上下文改进模块去生成最终的上下文特征。该上下文特征通过并以并联的方式作为编码器和解码器的条件输入。
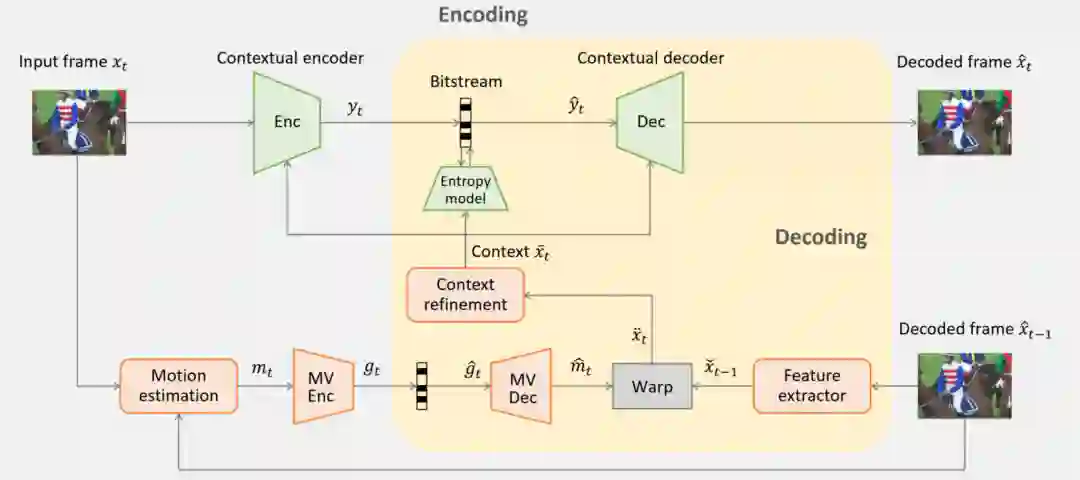
图3: 基于上下文的视频压缩 DCVC框架
在 DCVC 框架中, 时域高维上下文特征为编码条件。相比传统的像素域的预测帧,高维特征可以提供更丰富的时域信息,不同的通道也可以有很大的自由度去提取不同类型的信息,从而帮助当前帧高频细节获得更好的重建。图4展示了在像素域的残差编码和在特征域的条件编码的误差对比。可以发现,研究员们的方法在背景和前景中的高频内容可以获得明显的重建误差减小,这主要得益于使用更丰富的高维特征。
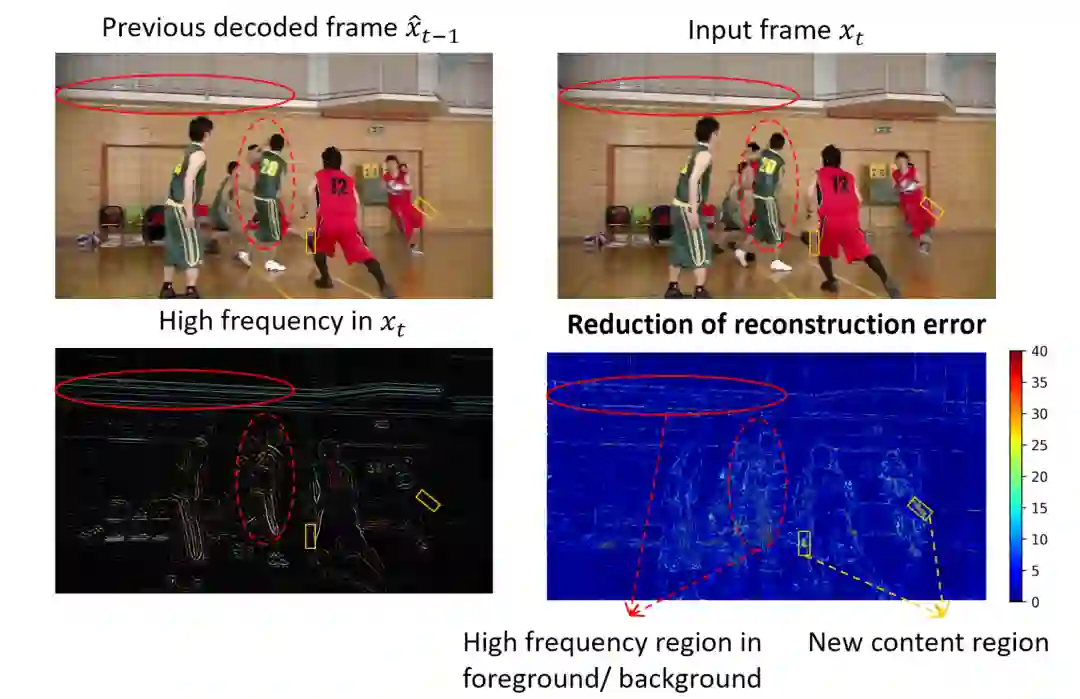
图4: 重建误差分析
另外,研究员们让编码器去自动挖掘当前帧和上下文特征相关性并去除其中的冗余,而不是使用固定的减法去除冗余。这种设计使框架可以在帧内编码和帧间编码获得自适应转换。对于视频中运动较大的区域或者新内容出现的区域,帧间相关性通常较低,其残差能量较大,因此残差编码对这种区域的压缩效率是非常低的。相比之下,研究员们的条件编码对这种区域可以自适应地去挖掘空间相关性来编码。上图也验证了此方法对新内容的区域可以显著地减小重建误差。
在条件编码框架 DCVC 中,上下文特征除了作为编码器和解码器的输入,也同时被用作熵模型的输入。如图5的左图所示,除了超先验,研究员们还同时利用了空域和时域先验。空域先验由自回归模型学习,而时域先验则由时域先验编码器从上下文特征中学习,从而保证熵模型可以获得更准确的概率估计,减小算术编码器所花费的比特代价。需要指出的是,自回归模型是一种比较“昂贵”的模型,虽然它可以进一步去除空间上的冗余,但是它的概率估计和编码是交织在一起的,从而引入了空间依赖并难以并行化。因此,虽然自回归模型可以提升压缩效率,但也会显著降低编解码速度。相比之下,时域先验的相关操作没有这种依赖性,完全可以并行化去处理。研究员们在图5的右图中也提供了只利用超先验和时域先验的熵模型。得益于高维上下文特征作为输入,这种熵模型可以用较小的压缩效率代价去获得显著的编解码加速。
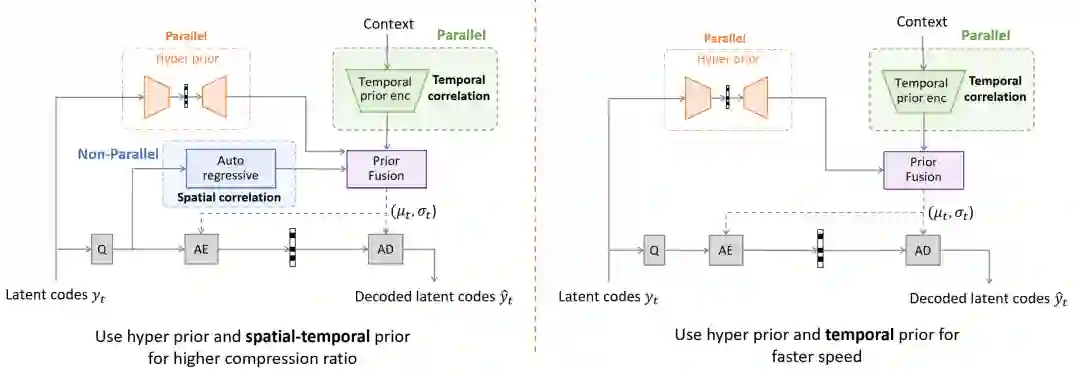
图5: 熵模型
实验表明,研究员们提出的 DCVC 相比传统编码器 x265 (veryslow) 在三个1080p 视频数据集分别获得23.9%, 25.3%, 26.0%的码率节省。另外,通过和最近的基于深度学习的压缩方法 DVC 和 DVCPro 相比。DVC 和 DVCPro 采用和传统编码器一样的残差编码框架。如图6所示,相比 DVC 和 DVCPro,此基于条件编码的方法获得了非常显著的码率节省。
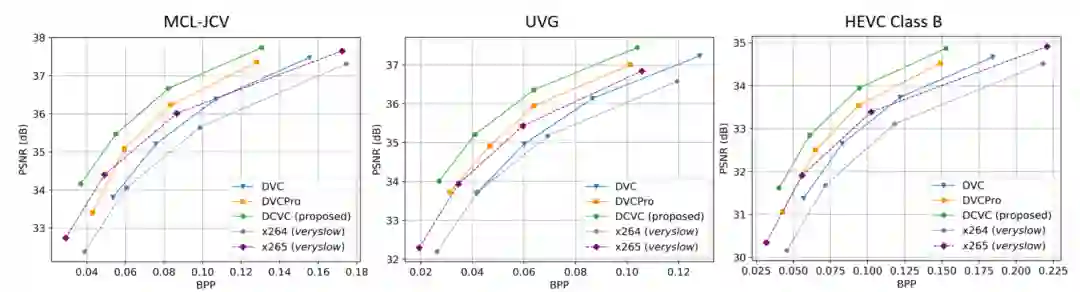
图6:码率-PSNR 曲线对比
正如上文所述,DCVC 具有很强的可拓展性,其高维上下文特征可以灵活设计,例如设计更好的学习或者利用方式。基于 DCVC 的条件编码框架,研究员们最新的方法在性能上有了进一步的提升,相关论文也将在之后公开。图7展示了最新方法的性能对比。值得注意的是,H.265-HM 和 H.266-VTM 都是使用性能最强的低延迟编码配置,并且 intra period 不是目前主流的10或者12,而是更为实用的32。如表1所示,如果以 PSNR 为质量评价指标,基于 DCVC 提升的方法相比 H.265-HM 可以获得高达14.4%的码率节省。相比之下,其它基于深度学习的视频压缩方法离 H.265-HM 的压缩性能还相差甚远。
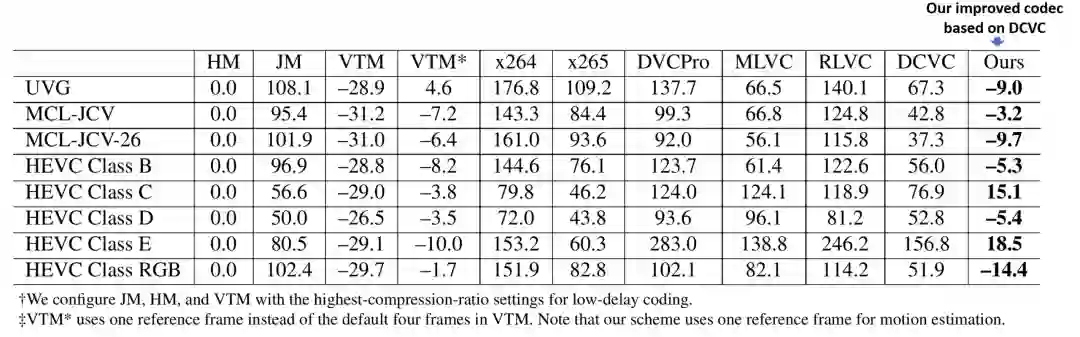
表1:压缩效率对比(PSNR 为质量评价指标,intra period 为32),H.265-HM 为基准
如果以 MS-SSIM 为质量评价指标,DCVC 方法甚至比 H.266-VTM 有高达21.1%的码率节省。与此同时,基于时域先验的熵模型也使该方法的编码速度在所有方法中是最快的,有着数量级的提升,解码速度和 H.265-HM/H.266-VTM 接近。
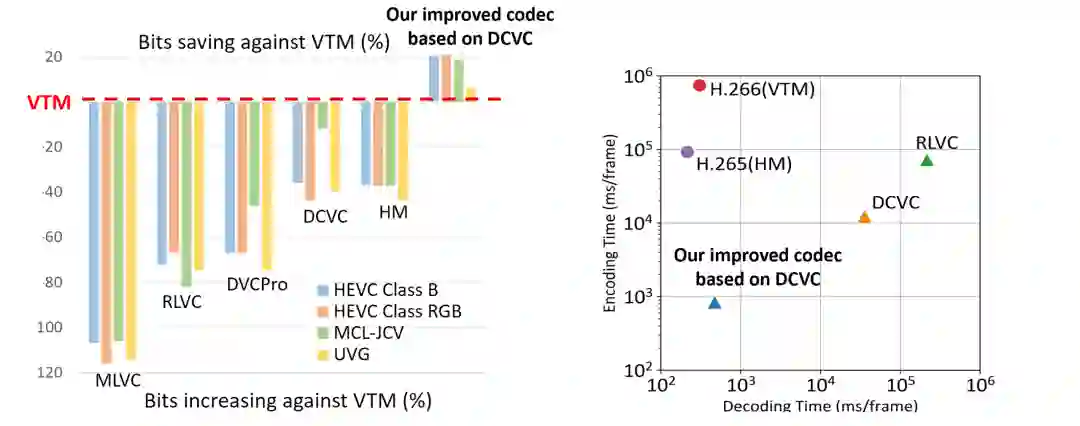
图7:压缩效率对比(MS-SSIM为质量评价指标,intra period 为32)和编解码复杂度对比 (测试视频为1080p)
在本篇论文中,研究员们致力于设计一种基于条件编码的视频压缩框架 DCVC,该框架比常用的残差编码框架具有更低的信息熵下界。另外,对于运动复杂区域或者新内容区域而言,残差编码所假设的帧间预测总是最有效的并不正确。相比之下,研究员们提出的 DCVC 可以自适应地学习帧内编码和帧间编码。在 DCVC 里,其条件被定义为上下文特征。相比传统 RGB 三通道像素,具有更高维度的上下文特征,并可以携带更丰富的时域信息来帮助编码,特别是对高频细节的恢复。在未来,高分辨率视频将会更受欢迎和普及,而针对高分辨率视频中的更多高频细节内容,DCVC 的优势也将更为明显。
DCVC 是一种可拓展性非常强的框架,其潜力巨大,值得进一步研究。研究者们可以通过更好地学习和使用上下文特征去设计更有效的解决方案,并获得更好的压缩性能。如果对以上或相关研究内容感兴趣,欢迎各位读者发邮件与研究员们交流,也非常欢迎各位小伙伴能够加入研究团队。