ACL 2019开源论文 | 基于图匹配神经网络的跨语言知识图对齐

作者丨王文博
学校丨哈尔滨工程大学硕士生
研究方向丨知识图谱、表示学习


动机
引入主题实体图,即指实体的局部子图,用来表示实体与其对应的上下文信息。
将知识图谱中实体对齐问题转化为图匹配问题。进一步提出了一种基于图注意的解决方案,该方案首先匹配两个主题实体图中的所有实体,然后对局部匹配信息进行联合建模,得到图级匹配向量。
主题实体图
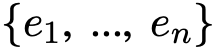 表示。
然后从这个集合中任意选取两个实体对
表示。
然后从这个集合中任意选取两个实体对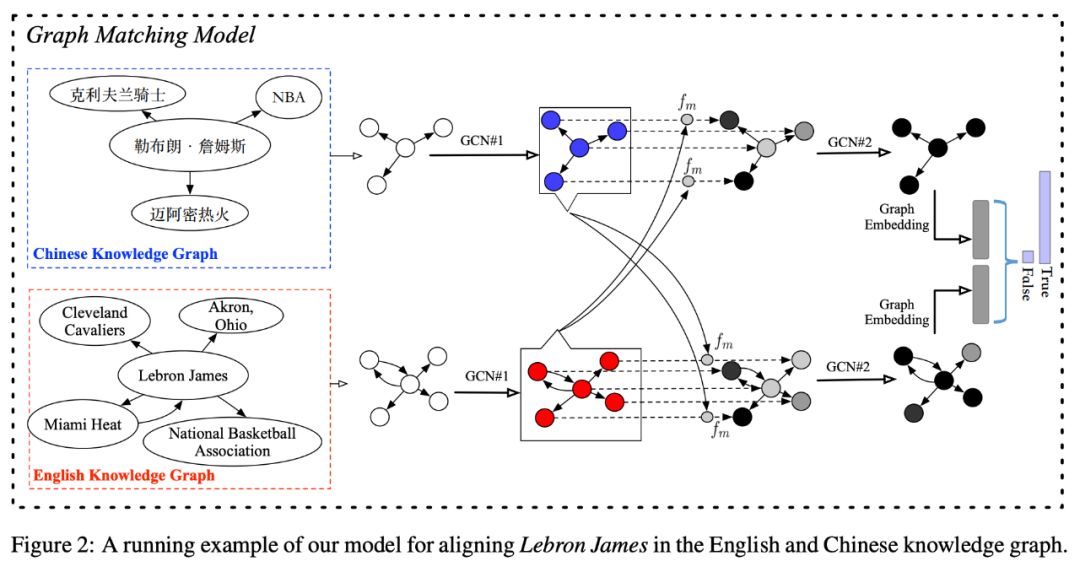
图匹配模型
1. 首先用一个基于单词的 LSTM 将图中所有实体从名字转化成向量,进行初始化。并用符号表示实体 v 的初始化嵌入向量。
2. 对实体 v 的邻居实体进行分类,若该邻居实体通过指向实体 v 的边与 v 相连,则该实体属于集合,若该实体通过指向自己的边与实体 v 相连,则该实体属于集合
。
3. 通过运用一个聚合器,将指向实体 v 的所有邻居节点的表示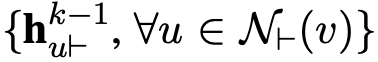
,其中 k 是迭代值。该聚合器将与节点 v 直接相邻的所有节点的向量表示,作为一个全连接层神经网络的输入,并运用一个均值池化操作来捕捉邻居集合中的不同方面特征,得到向量
。
4. 将 k-1 轮得到的指向实体 v 的邻居集合的表示与新产生的
进行连接,并将连接后的向量放入全连接网络去更新指向实体 v 的邻居集合的表示,得到
。
5. 用与步骤(3)步骤(4)相同的方法在由实体 v 指出的邻居集合中更新由实体 v 指出的邻居集合的表示。
6. 重复步骤(3)-步骤(5)K 次,将最终的指向实体 v 的邻居集合的表示与由实体 v 指出的邻居集合的表示进行连接,作为单个实体的嵌入向量。最终得到两组实体的嵌入向量的集合分别为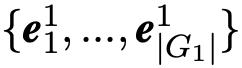
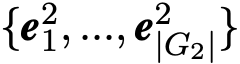
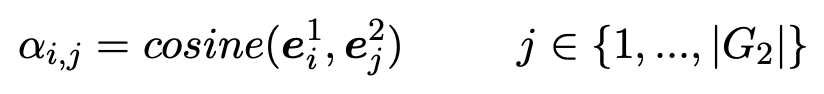
然后,我们用这些相似点作为权重并通过对 G2 中所有实体嵌入向量加权求和的方式来计算整个图的关注向量。
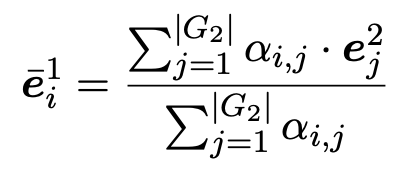
通过对每一步匹配运用多角度 cosine 匹配函数计算 G1 与 G2 中所有实体的匹配向量。
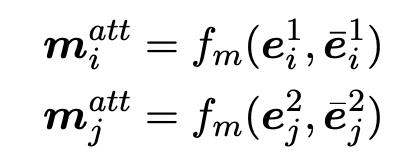
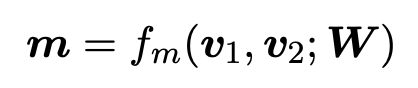
其中,v1 与 v2 表示两个维度为 d 的向量,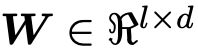
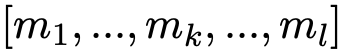
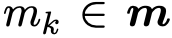
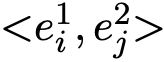 随机构建 20 个错误案例。也就是说首先通过对每个实体表面形式中预先训练的词的嵌入向量加和粗略生成 G1 和 G2 的实体嵌入向量。然后再粗略的在其嵌入空间中选取 10 个与实体
随机构建 20 个错误案例。也就是说首先通过对每个实体表面形式中预先训练的词的嵌入向量加和粗略生成 G1 和 G2 的实体嵌入向量。然后再粗略的在其嵌入空间中选取 10 个与实体实验
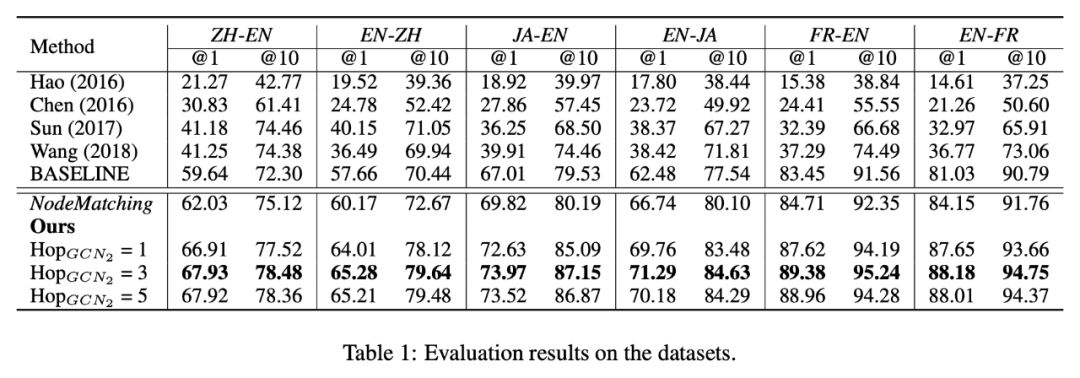
在数据集 DBP15K 上对模型进行评估。这些数据集是通过将汉语、日语以及法语版本的 DBpedia 中的实体与英语版本的 DBpedia 中的实体进行连接得到的。每个数据集包含 1500 个内部语言连接,即在两种不同语言的知识图谱中对等实体的连接。
本实验中采用 Adam 优化器更新参数,最小批尺寸设置为 32。学习率设置为 0.001。GCN1 与 GCN2 最大跳数 K 分别设置为 2 和 3。非线性函数 σ 设置为 ReLU。聚合器的参数是通过随机初始化得到的。由于用不同的语言来表征指示图谱,本文首先用 fastText 嵌入方法对单一语言的知识图谱进行嵌入处理,并运用交叉语言词汇嵌入方法将这些嵌入向量在同一个向量空间进行对齐。用这些对齐后的向量作为 GCN1 第一层输入的初始化单词表示向量。
关系标签在数据集中被表示为抽象符号,这提供了关于关系的相当有限的知识,使得模型很难在两个知识图谱中学习它们的对齐。
合并关系标签可能会显著增加主题实体图的尺寸,这需要更大的跳数和运行时间。
总结
本文通过引入图卷积神经网络,极大地提高了跨语言知识图谱中实体对齐的准确性。本文的亮点之处主要体现在以下三点:
本文提出了主题实体图的构建,实现了相邻实体间的信息传递,使得由此方法得到的每个节点向量包含了其多跳邻居的信息,最大可能地保留了知识图谱的结构化信息。并成功地将实体对齐问题转化为图匹配问题。
本文运用图卷积神经网络构建图匹配模型,在图匹配层运用多角度余弦匹配函数计算相似性,并通过实验论证了图匹配层在本文模型中的重要性,也说明了不仅上下文的局部信息对实体对齐效果有巨大影响,全局信息对实体对齐任务同样十分重要。
本文验证了对知识图谱中关系信息的处理仅保留其方向而忽略其标签具体内容有助于提高模型的效率与准确性的结论。

点击以下标题查看更多往期内容:
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 下载论文 & 源码


