逆向而行,中文轻量级预训练模型的探索之路
作者:Junyi Li(CLUE Benchmark 成员)
Overview
自Bert诞生以来,预训练模型在NLP领域掀起来一股新的浪潮。无数相关的工作被大家所创造。无论是XLNet还是ERNIE,亦或者是去年沸沸扬扬的Roberta,模型大多是朝着“越来越大”这样的一条路上一去不复返。
然而在“越来越大”这股裹挟着大量模型的道路上,依然有着一小撮人选择逆向而行——限制模型大小以得到更小,更快,但是性能却并不减弱的模型。已经有相当多的人在这个方向上加以探索,我们将在第二章一起看一下小模型近年来的发展。
同时,我们也意识到,可能对于很多人来说,对如何构造一个轻量级模型还有些没有头绪,所以我们会在第三章的时候和大家讨论一下实现轻量级模型的思路和现有方法工具。
最后,一方面是基于轻量级模型在学术界日益重要的地位,另一方面也是苦于网络上目前缺乏面向中文的轻量级模型资源,我们在NLPCC2020会议上举办了面向中文的小模型大赛(shared task 1),会在第四章对这个比赛的信息给大家做一个介绍,同时也欢迎大家来参加这个比赛。比赛报名链接:
https://www.cluebenchmarks.com/NLPCC.html
小模型近期的发展
尽管在学术界,我们经常会在理论上追求更大更多更强的预训练模型,特别是Roberta的经验告诉我们,似乎只要资源跟上了,效果自然就水涨船高。但是一旦落到实际的训练或者使用中,会出现内存不够,训练/推理速度缓慢,训练资源耗费巨大这样的问题。
一味追求无实际应用意义的改进,大型模型的存储和计算成本不断提高,在工业界的落地使用问题颇多。
因此针对这样的问题,很多人研究如何才能训练出更好更实用的模型。除了重构网络模型,量化、剪枝与蒸馏都是有效的手段。
Albert
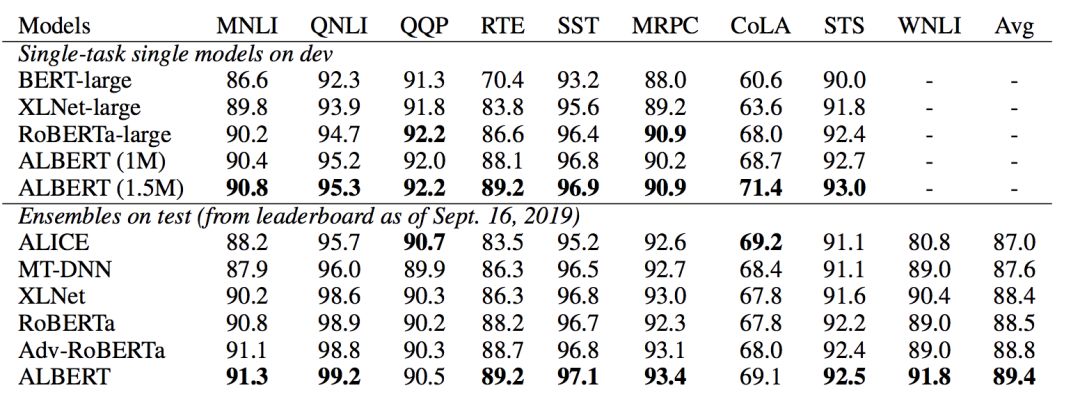
Google在2019年年底提出Albert,主要是通过矩阵分解和跨层参数共享来做到对参数量的减少,除此以外也是用SOP(Sentence Order Prediction)替换了NSP(Next Sentence Prediction),并且停用了Dropout,最后 GLUE上一举达到了SOTA的效果。下图是Albert的实验结果。
知识蒸馏
除了从模型结构的思路上做优化,知识蒸馏是一种很有效的策略来获得小的模型。一般认为其来源于Hitton在2014年的NIPS上的一篇论文《Distilling the Knowledge in a Neural Network》。这篇论文提出了一个思路:通过蒸馏来将一个大型的,知识丰富的teacher模型的“知识”转移到一个小型的student模型上来,使得student模型可以具备和teacher模型类似的效果,但是模型规模会下降很多。由于这个方法对teacher模型和student模型的网络结构并不做强制要求,且我们可以将多个teacher模型的“知识”转移到student模型上去,使单个网络模型(student)的效果达到集成学习类似的效果。故而模型蒸馏正在成为一个构建轻量级模型的重要方法。
DistilBERT
去年年底,HuggingFace提出的DistilBERT,利用KL 散度作为损失函数,使用的是 Bert 的英语 bert-base-uncased 版本进行蒸馏,将 BERT-base 从 12 层蒸馏到 6 层 BERT 模型,虽然效果比bert降低了5%,但是其参数量下降到了66M。
Tinybert(目前CLUE小模型榜单第一名)
由华为云提出的Tinybert提出了一个用于Transformer模型的知识蒸馏方法,并且还提出了一个两阶段的学习框架:通用知识蒸馏阶段和基于特定任务的蒸馏阶段。除此以外,tinybert里用了数据增强做半监督的训练,这个也是他能够取得很好的结果的重要原因之一。(为了满足大家对训练数据的需求,本次举办的比赛也提供了一个14G的中文语料供大家选择性使用。)
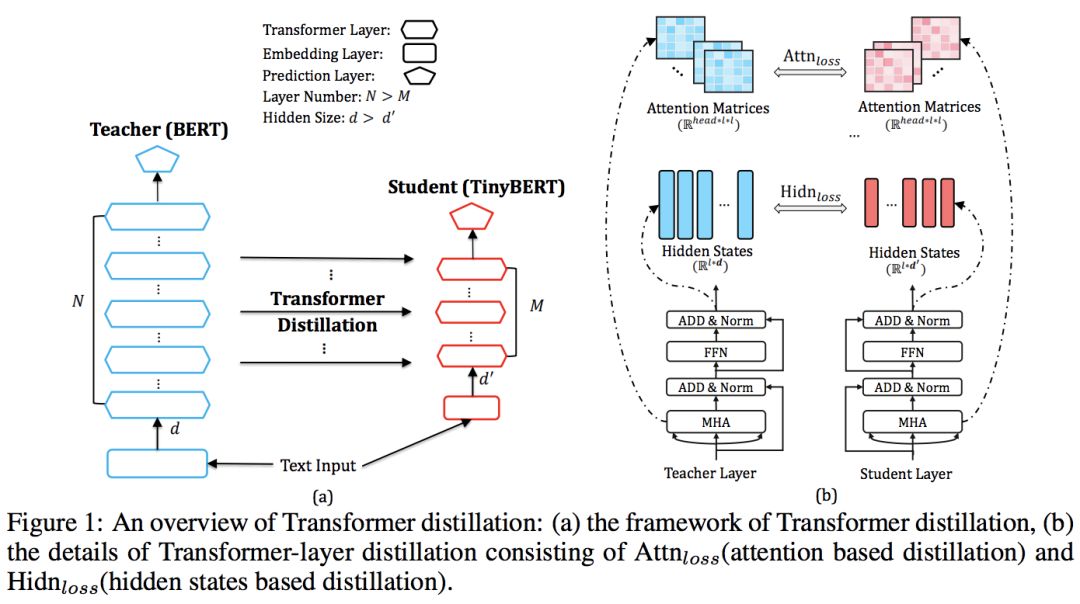
下图展示了Transformer蒸馏的一个过程,通过将Bert模型作为Teacher,TinyBert模型作为Student,作者得到了更好的效果。
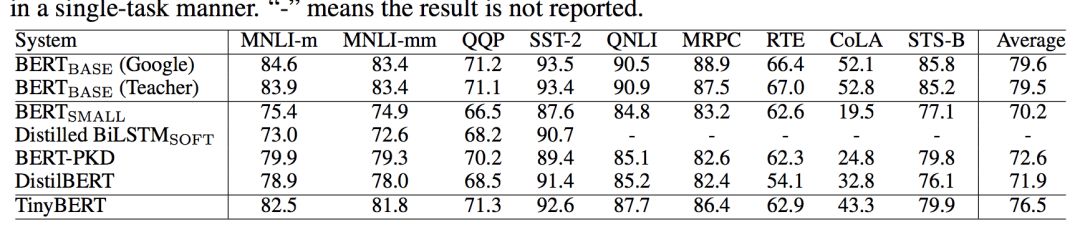
在效果上,从下图我们可以看出,虽然比起大型模型来说有所不足,但是和同等量级的模型相比,有时还是十分明显的。如果我们单独看NMLI,MRPC任务的话,可以说TinyBert已经十分逼近自己的老师(Bert)了。
而从这张图上看就更加直观了,模型的大小以及推理速度都有了极大的改进。

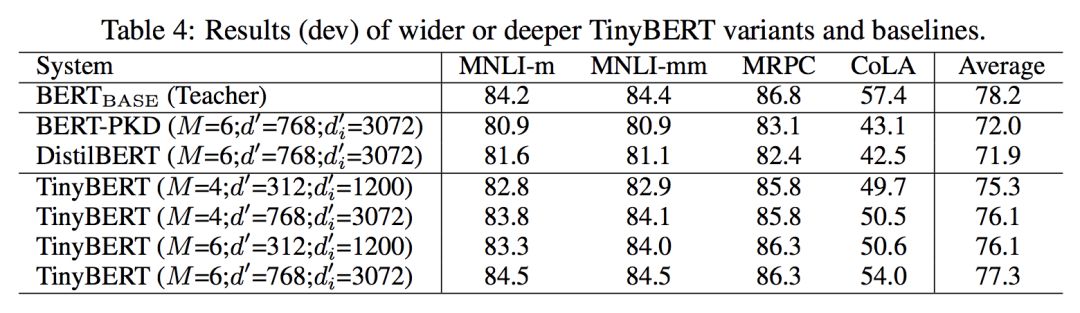
从下面的表格上可以看到Tinybert目前的效果,和bert在总分上目前只差0.9。
Electra
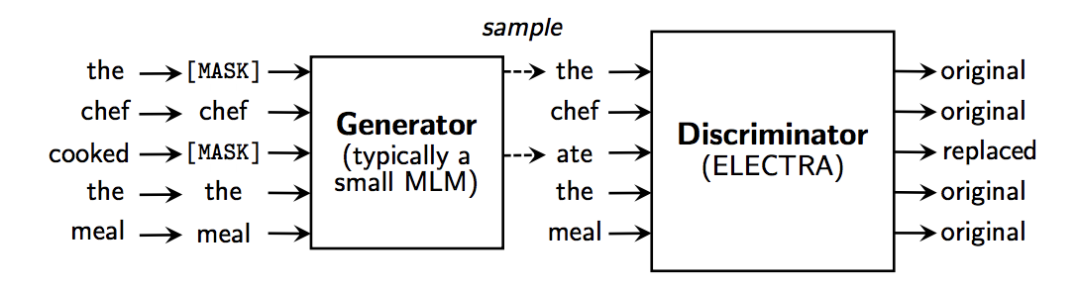
来自斯坦福大学,这个模型将GAN应用到了NLP领域。我们知道因为语言是离散型的变量,所以生成器不能像在图像中一样在语言中发挥很好的效果。但是这篇论文创新性地使用生成器来生成用来作为[MASK]的token,帮助分类器学习更好的分类。最后在论文的实验中证明了这个模型在参数量比较小,训练次数比较少的的时候可以获得比bert更好的效果。从下图中我们可以看到,模型并非直接将[mask]处理后的句子送入判别器中进行训练,而是通过生成器生成数据,然后让判别器判断是否是原来的单词进行训练。
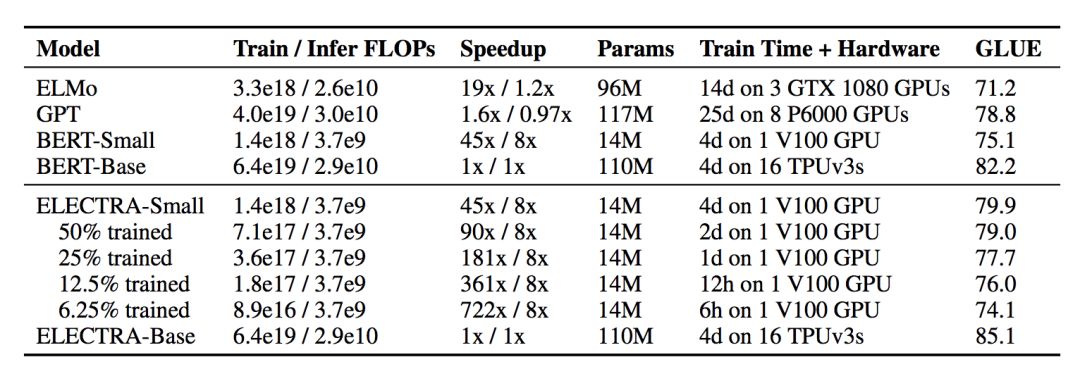
同时作者在论文中也给出了模型参数较少时可以得到的效果,与现在流行的几个模型相比毫不逊色:
Reformer
谷歌和伯克利研究者共同ICLR上发表了一篇新的论文,对transformer做了改进。这篇论文中对transformer的点乘注意力做了分析,发现attention 的计算和时间复杂度是 O(N2),因为需要对同一个序列计算Q和K的点乘,很明显算法复杂度很高。最后研究者使用局部敏感哈希的点乘注意力将复杂度从 O(N^2 ) 变为 O(N log N),将算法复杂度降低,得到了更高的效率。此外,研究者使用了reversible 残差代替普通的残差,可以使得存储只激活一次,而不是有几层便激活几次。实验表明,改良的reformer和原版的transformer在性能上表现非常接近,且随着序列长度(N)的长度变大,存储效率和速度优势就会更明显。

前些日子,google通过知识蒸馏的方法发布了24个仅限英文且不区分大小写的小型BERT模型,试图为小模型提供baseline。这也进一步佐证了模型实用性的重要程度。
上面介绍的工作,Tinybert和Electra都有相应的中文工作。我们可以分别从cluebenchmark小模型榜单上通过他们提交的模型找到相应的链接地址。Electra的中文模型地址:
https://github.com/CLUEbenchmark/ELECTRA
同时,刚才我们提到了,google近来放出了小模型,但是却没有相应的中文模型。不免让中文研究者觉得遗憾。不过,cluebenchmark的成员,通过重新修正中文训练词汇表,以及采用全新中文数据集的方式,重新训练了小型的中文预训练模型并发布在网站上:
https://github.com/CLUEbenchmark/CLUEPretrainedModels
详细情况可以上网站查看。同时,大家现在也可以直接通过依托于Huggingface-Transformers 2.5.1,可轻松调用Pytorch版本的模型。
“””
tokenizer = BertTokenizer.from_pretrained("MODEL_NAME")
model = BertModel.from_pretrained("MODEL_NAME")
“””
模型轻量化的途径与手段
模型的轻量化,我们一般有三种手段,一种直接改设计全新的网络结构,尝试以较少的模型参数学习出一个尽可能好的模型;一种是通过量化和剪枝的方法等手段减少参数量,使得模型变小;另一种就是通过知识蒸馏的方式将一个大模型的知识转移到一个小型模型上。
微软开源了一个工具提供了量化、剪枝以及蒸馏的工具:
https://github.com/microsoft/nni
哈工大讯飞联合实验室开源了一个模型蒸馏的工具:
https://github.com/airaria/TextBrewer
由于篇幅关系,我们本文章就简单的介绍一下模型蒸馏的工具,有机会的话,后续会提供更多的细节给大家。这里我们将基于TextBrewer,以知识蒸馏为主,简单介绍一下知识蒸馏是怎么工作的。下面的内容主要来自TextBrewer官方git文档。
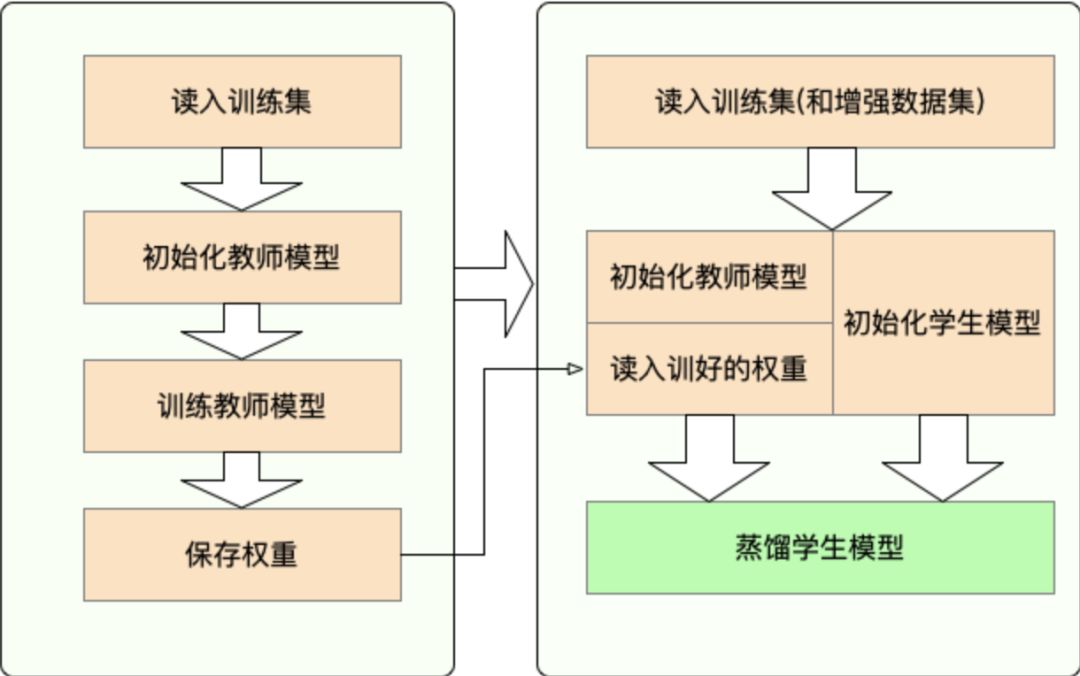
一共有两个步骤:
步骤一: 蒸馏之前的准备工作:
• 训练教师模型
• 定义与初始化学生模型(随机初始化,或载入预训练权重)
• 构造蒸馏用数据集的dataloader,训练学生模型用的optimizer和learning rate scheduler
步骤二: 使用TextBrewer蒸馏:
• 构造训练配置(TrainingConfig)和蒸馏配置(DistillationConfig),初始化distiller
• 定义adaptor 和 callback ,分别用于适配模型输入输出和训练过程中的回调
• 调用distiller的train方法开始蒸馏
由于工具已经封装好了内部的很多函数,所以我们作为使用者需要做的就是准备好teacher模型和student模型,合理的配置和初始化,将其送入模型即可得到自己想要的结果。也是非常方便的。
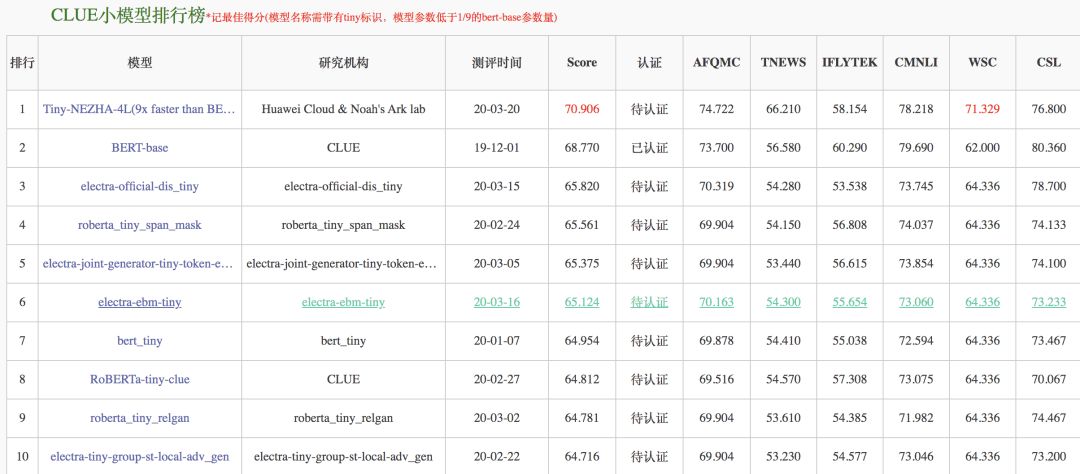
为了促进中文小模型的发展,我们设立了小模型排行榜。目前由clue组织的中文小模型排行榜已经吸引了包括华为诺亚方舟实验室,斯坦福大学在内的组织机构或者个人参与评测。目前榜单上的第一名是来自华为诺亚方舟实验室的团队,他们的的工作在排行榜总分上取得了70.906分的好成绩。大厂和名校的工作,足以显示这方面工作的重要程度以及对我们工作的认可。
榜单请查看:
https://www.cluebenchmarks.com/small_model_classification.html
本次比赛的介绍以及相关链接
本次任务的主要目的是在限定参数数量的情况下,尽可能的训练一个性能足够好的模型,能够在我们提供的四个类型的任务中都得到比较好的效果。
本次任务覆盖了四种不同的下游任务,包含sentence-pair分类,single-sentence分类,命名实体识别和阅读理解。限于篇幅,具体的数据集介绍,请登陆网站查看介绍以及数据示例。
https://github.com/CLUEbenchmark/LightLM#dataset-description
【中文数据集】:
为了缓解参赛者对中文语言的需求,我们提供了14G的中文语料供大家选用。
https://github.com/CLUEbenchmark/CLUECorpus2020#cluecorpussmall14g
报名链接:
1. 访问www.CLUEbenchmark.com, 右上角点击【注册】并登录。
2. 进入【NLPCC2020】tab页,选中【注册栏】后进行比赛注册,并点击提交。
3. 如果有注册或者各个方面有关比赛的问题,可以通过官方邮箱:CLUEBenchmark@163.com 联系我们。
NLPCC-2020官方网站:
http://tcci.ccf.org.cn/conference/2020/cfpt.php
参考:
[1] https://github.com/CLUEbenchmark/DistilBert
[2] Turc, Iulia, et al. "Well-read students learn better: The impact of student initialization on knowledge distillation." arXiv preprint arXiv:1908.08962 (2019).
[3] Yang, Ziqing, et al. "TextBrewer: An Open-Source Knowledge Distillation Toolkit for Natural Language Processing." arXiv preprint arXiv:2002.12620 (2020).
[4] Lan, Zhenzhong, et al. "Albert: A lite bert for self-supervised learning of language representations." arXiv preprint arXiv:1909.11942 (2019).
[5] Sanh, Victor, et al. "DistilBERT, a distilled version of BERT: smaller, faster, cheaper and lighter." arXiv preprint arXiv:1910.01108 (2019).
[6]Clark, Kevin, et al. "ELECTRA: Pre-training Text Encoders as Discriminators Rather Than Generators." International Conference on Learning Representations. 2019.
[7] Jiao, Xiaoqi, et al. "Tinybert: Distilling bert for natural language understanding." arXiv preprint arXiv:1909.10351 (2019).
[8] Cheng, Yu, et al. "A survey of model compression and acceleration for deep neural networks." arXiv preprint arXiv:1710.09282 (2017).
[9] Kitaev, Nikita, Łukasz Kaiser, and Anselm Levskaya. "Reformer: The Efficient Transformer." arXiv preprint arXiv:2001.04451 (2020).
本次比赛官方主页,点击"阅读原文"直达:
推荐阅读
CLUECorpus2020:可能是史上最大的开源中文语料库以及高质量中文预训练模型集合
CLUEDatasetSearch:搜索所有中文数据集,附常用英文数据集
From Word Embeddings To Document Distances 阅读笔记
模型压缩实践系列之——bert-of-theseus,一个非常亲民的bert压缩方法
关于AINLP
AINLP 是一个有趣有AI的自然语言处理社区,专注于 AI、NLP、机器学习、深度学习、推荐算法等相关技术的分享,主题包括文本摘要、智能问答、聊天机器人、机器翻译、自动生成、知识图谱、预训练模型、推荐系统、计算广告、招聘信息、求职经验分享等,欢迎关注!加技术交流群请添加AINLP君微信(id:AINLP2),备注工作/研究方向+加群目的。




