步态识别新动态 !专家报告 + 大咖观点
点击中国图象图形学报→主页右上角菜单栏→设为星标


2020年9月23日,由《中国图象图形学报》组织的系列直播活动“图图Seminar”为大家带来了“步态识别新动态”的主题报告,并由特邀主持人和嘉宾围绕观众所提问题进行了热烈的专题讨论。
主讲人:于仕琪,南方科技大学
主持人:贲晛烨,山东大学
特邀嘉宾:王亮,中科院自动化研究所
特邀嘉宾:张军平,复旦大学
特邀嘉宾:曹春水,银河水滴公司

今天,图图不仅为大家带来了精彩的视频回放,还有本期直播的报告看点,以及特邀嘉宾的精彩讨论~

点击图片观看直播回放



步态识别作为一种生物特征识别技术,主要目标是根据人的走路方式识别人的身份信息。
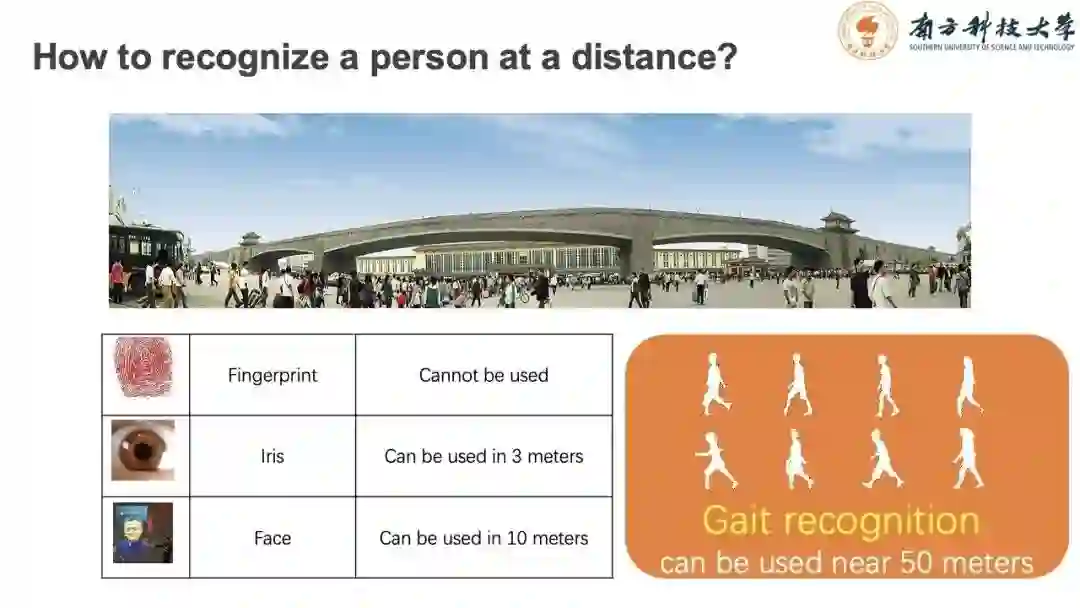
其他特征识别技术,如指纹识别需要接触,虹膜识别与人脸识别有距离限制。步态识别可以在远距离,数十米乃至百米识别出人的身份信息,是其他生物特征技术无法比拟的优势。

在日常监控摄像等应用场景中,人脸识别会遇到如角度,像素等各种参数限制的问题。而步态识别不依赖高清分辨率摄像头,对角度、距离、视频解析度和亮度等参数不敏感。
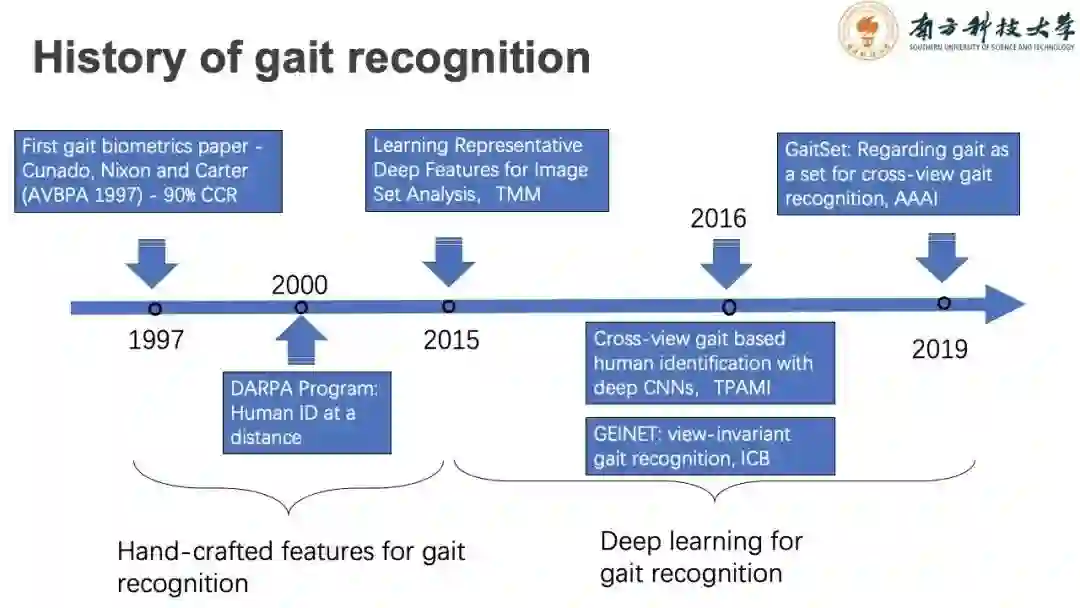
Nixon教授在1997年发表了第一篇现代步态识别论文,识别准确率达到了90%,但是步态库数据量较少,只有几人。但其作为开创性的工作,为后续的工作提供了重要的指导。
2015年之前,相关研究主要通过手工设计特征,得益于深度学习的发展,步态识别领域最近几年获得了明显的提升。随着其他方法的应用,深度学习技术不断刷新识别准确率。GaitSet方法是近几年的关键工作之一,提供了一种全新的思路,许多学者将GaitSet作为性能基准,试图超越。
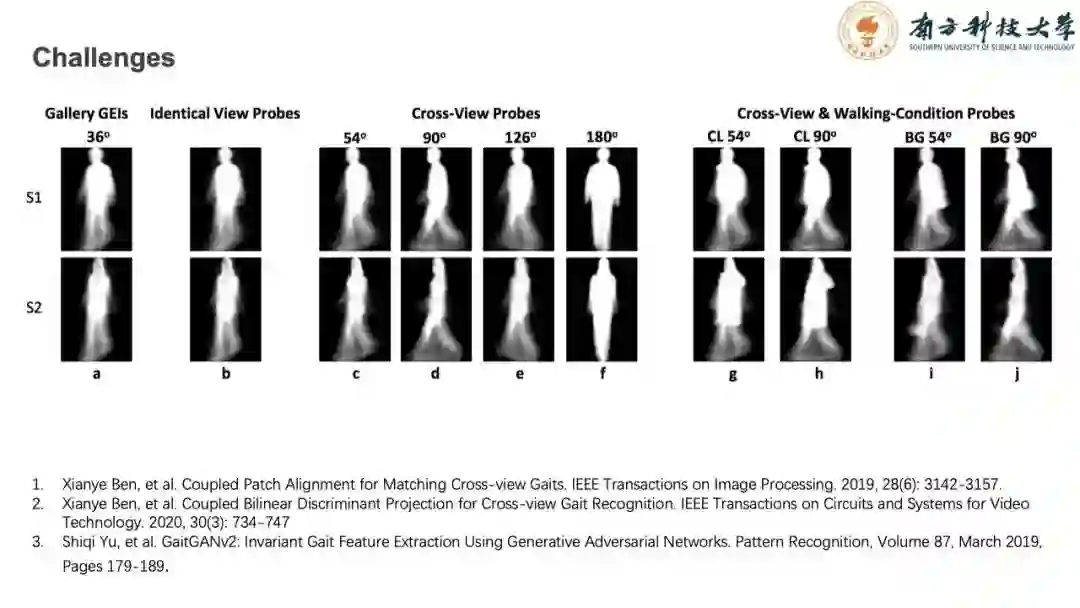
步态识别的难点在于其有角度、衣着、挂件和背包等变化。而这种变化是日常生活场景非常自然,也很常见的。给步态识别带来了许多困难。所以在研究中,我们必须考虑角度等参数的影响。贲晛烨老师在多角度步态识别中做了很多工作。
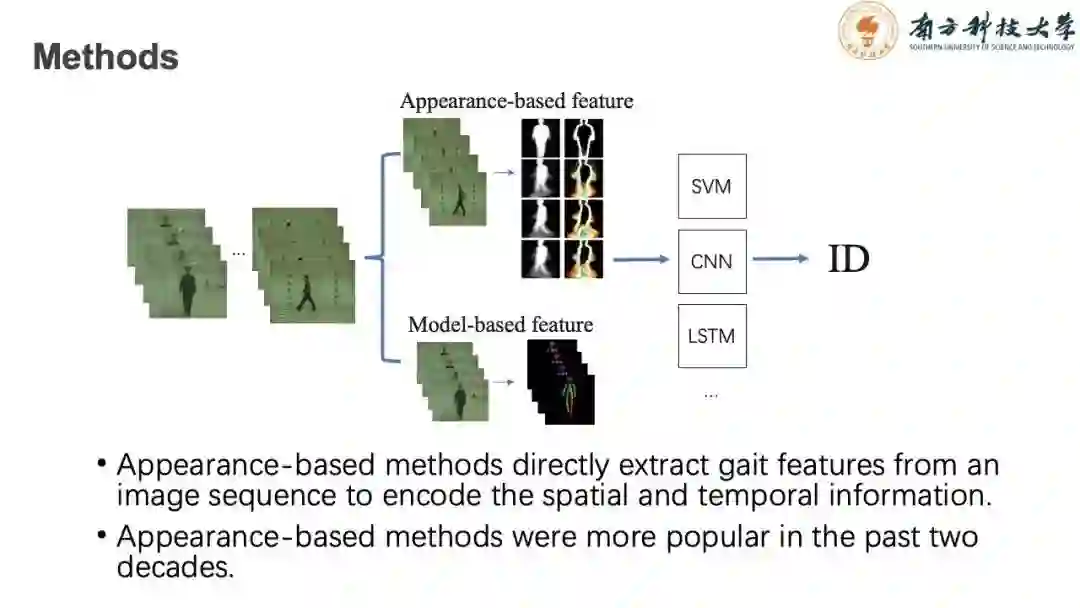
在步态识别领域接近二十年的发展过程中,领域内主要采用两种主流的研究特征:
1)Appearance-base feature,主要采集人体的体态表面特征。常用的方法会在后续介绍。
2)Model-based feature,主要通过对人体建模,如人体骨架和3D建模等方法提取后的特征再送入分类器中,识别出对应的人。

2005年前,model-based方法是步态研究中的主流,图为王亮老师的相关研究工作。国内最早的步态识别库NLPR/CASIA-A由王亮老师创建。在早期,学者们认为要研究人体步态就需要对人体建模,研究模型的属性诸如手臂摆动幅度,各关节的夹角等。但在后续发展中,基于模型的方法不再受到很大的关注,主要原因在于基于模型的方法在建立人体模型时的计算量大,人体建模精度不高造成了最终识别率低。
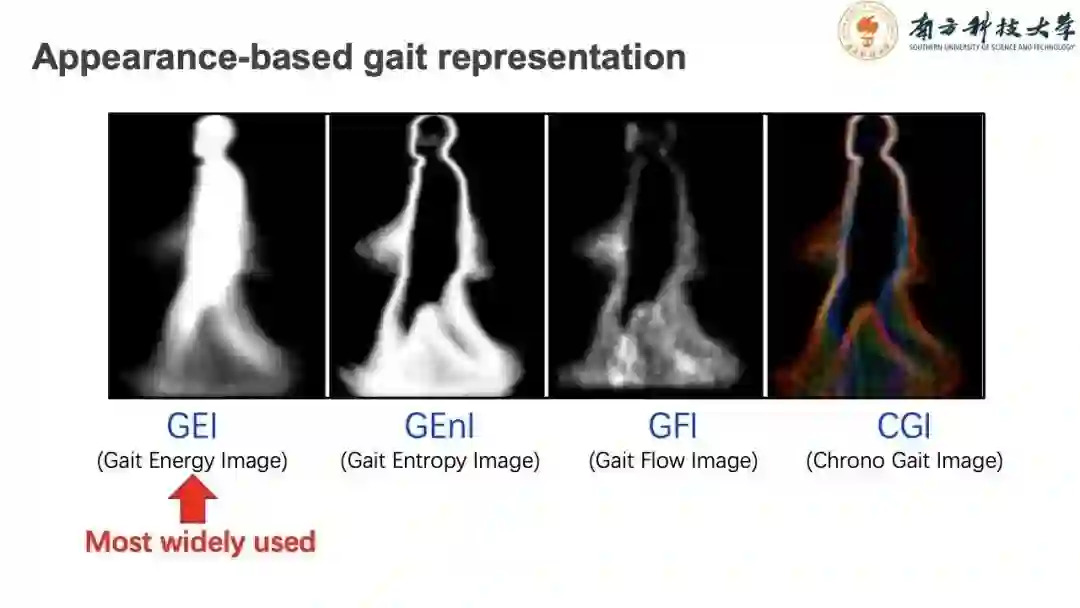
因此,学者们将目光投入到更简洁高效的Appearance-based方法。Appearance-based方法提取人体轮廓信息,如最常用的GEI(Gait Energy Image)在提出时就因其简单高效且准确率超越其他所有方法带来了许多关注。其他类似的变种也是同样提取表面特征但是注重点不同,如注重动态信息的GEnI(Gaut Entropy Image),还有GFI(Gait Flow Image)CGI(Chrono Gait Image)等方法。
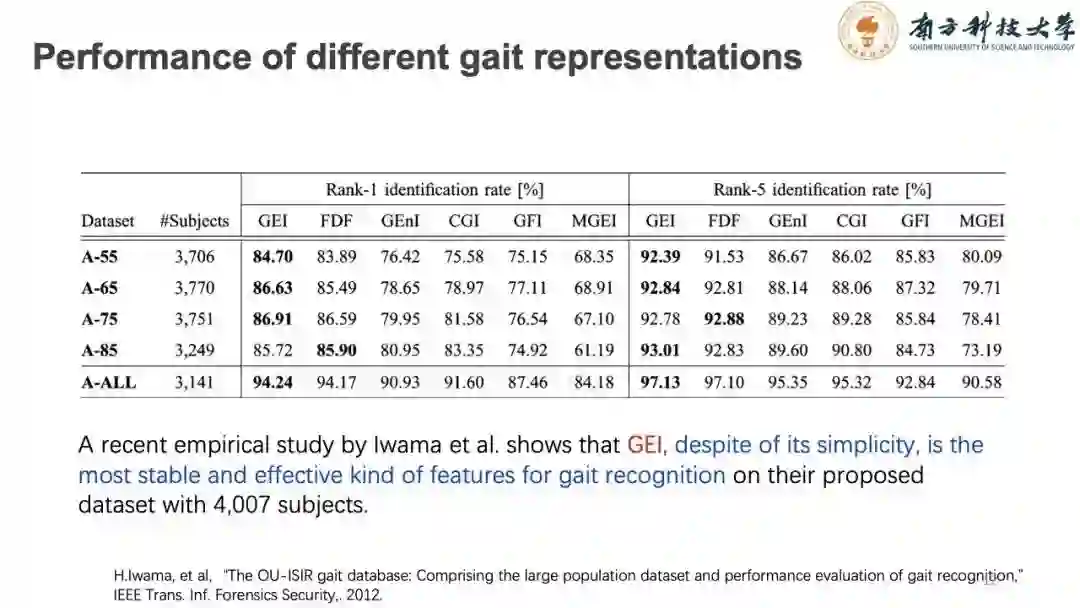
从不同Appearance-based 方法准确率对比中可以发现,GEI作为最简单的提取并平均人体表面体态,其准确率可以达到非常高的水平,这也是appearance-based方法成为主流研究方法的一大原因。
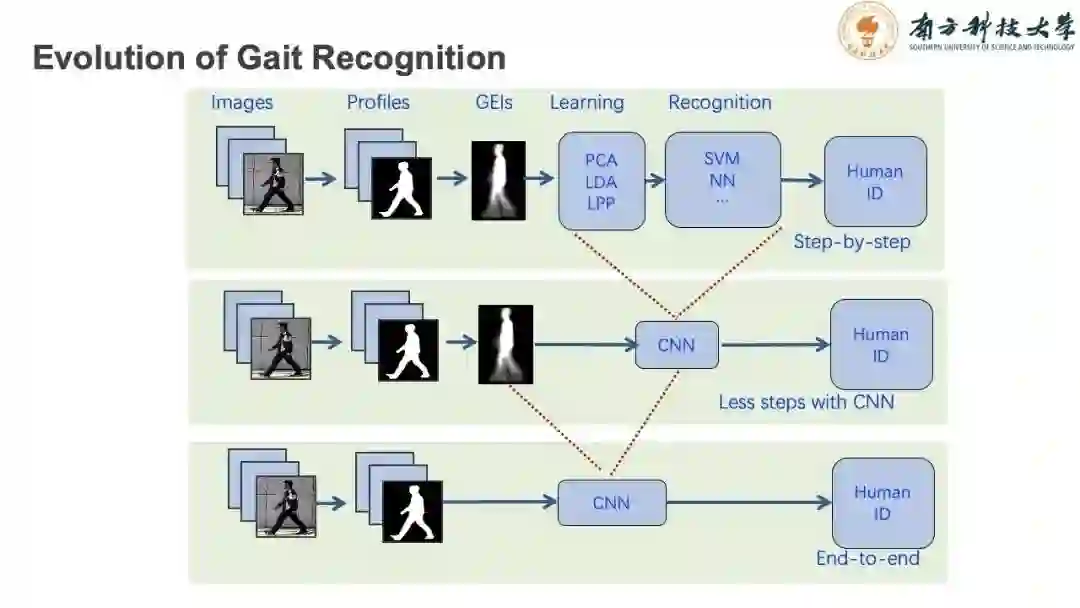
步态识别算法的发展脉络介绍。最早期的步态识别研究流程是:由图像中提取人体的轮廓,采用不同的人体步态表示方法如之前提及的GEI或者GEnI表示轮廓序列;再使用不同的学习方法提取特征信息,通过分类器识别出人的身份。
随着深度学习的出现与发展,卷积神经网络合并了特征提取与分类两个步骤。近五年的步态识别工作都是基于这个思路,深度学习也给步态识别准确率带来了明显的提升。
近几年,学者们发现表观序列用如用GEI表示,是会损失一些特征信息的。得益于卷积神经网络的拟合学习能力,有的工作开始尝试直接将轮廓序列输入神经网络中,略过轮廓平均这一步骤。GaitSet就是采用了这样的研究思路,将准确率再度提升。

在过去的十几年间,步态识别算法以采用表观特征研究方法为主。而人体模型特征的步态研究由于人体建模方法的精度低,计算量大,识别率低等原因受到关注较少。最近的人体建模技术迅速发展,正促进使用模型特征(Model-based feature)的步态识别研究。

得益于深度学习技术的迅速发展,人体姿态估计(pose estimation)得到巨大发展。在2016—2017年间,OpenPose横空出世。从图像中或者视频序列,OpenPose可以准确的估计人体骨架信息。人体建模技术得到明显的提升,姿态估计技术的发展克服了早期步态识别model-based方法的不足与缺陷,而我们认为这就是步态识别未来发展的方向之一。
在最新的CVPR2020论文中,TetraTSDF已经达到可以提取人体三维信息水平。不仅是人体的三维形状被估计,甚至是衣服的纹理。这些成果都可以用于步态识别领域中。
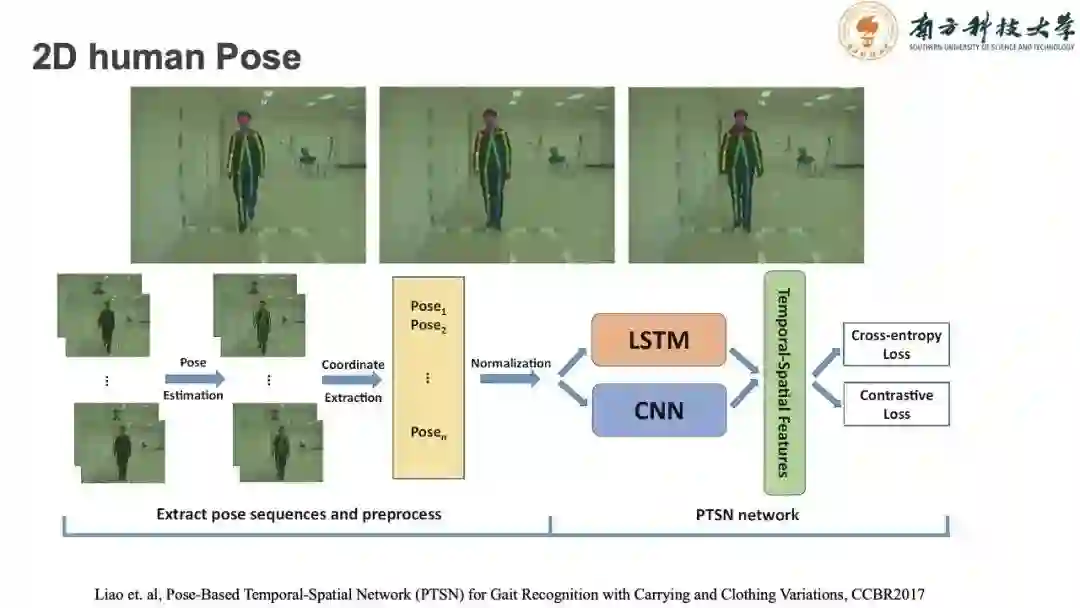
这样的思路下,我们将OpenPose应用到视频序列提取骨架信息,将骨架信息做基于模型特征的步态识别研究。我们发现一些问题:由于图像是二维的,我们的骨架提取也是二维的,在视角变换的情况下,准确率降低严重。
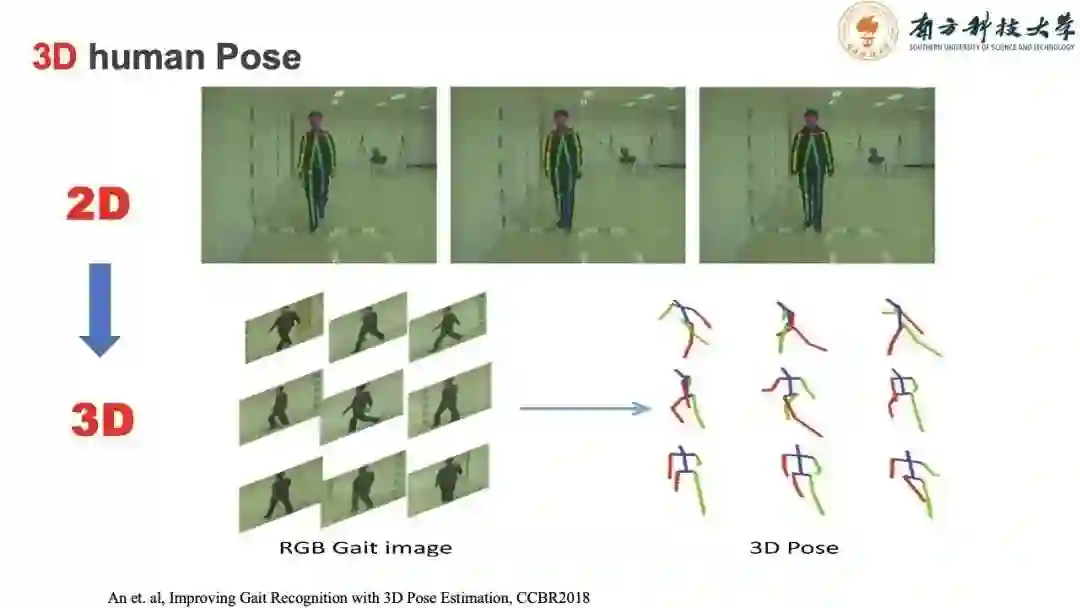
二维图像提取骨架的准确率不高,给予了我们新的思路,如果我们尝试采用三维的人体模型是否能改善结果。因此我们可以从二维人体模型估计出三维人体骨架模型。三维人体骨架模型就可以通过旋转操作克服视角变换的问题。
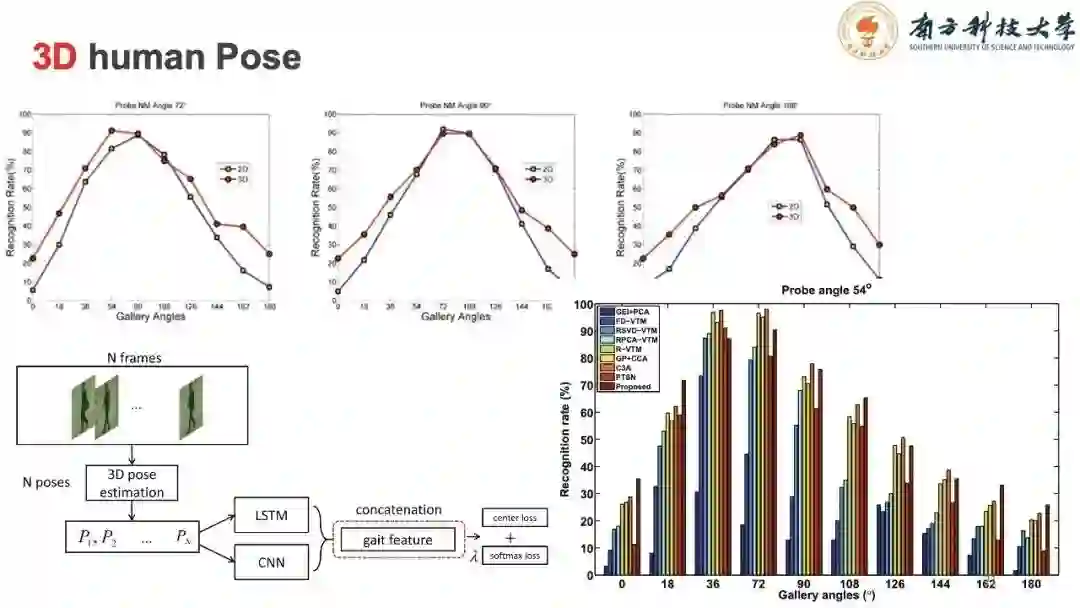
从我们实验的结果可知,准确率有一定的提升,但并不明显。原因有几点:OpenPose提供的骨架信息精度没有达到非常高。图像的解析度比较低。合成的三维骨架基于上述的二维骨架,误差的累积造成准确率的提升并不明显。但是在部分角度如70~100的准确率较好,是超出我们预期的。
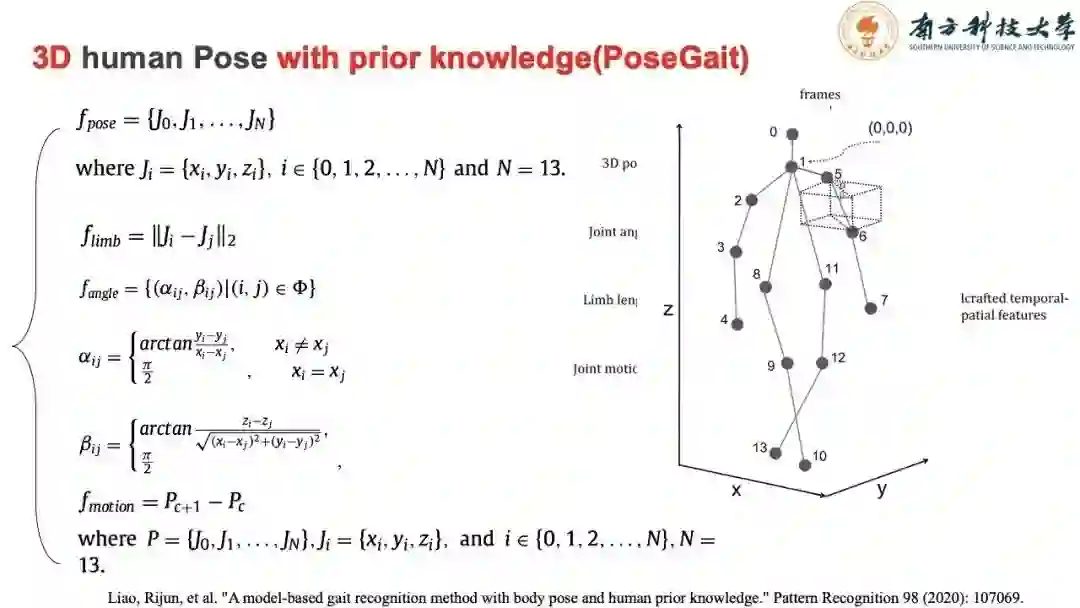
在之前工作的基础上,我们参考了一些行为识别算法,不仅引入了骨架信息,还加入了关键点之间角度的信息,关节长度,运动模式等特征。这样的思路类似于2003年王亮老师工作的思路,温故知新,用经典的思路,结合最新的技术发展。
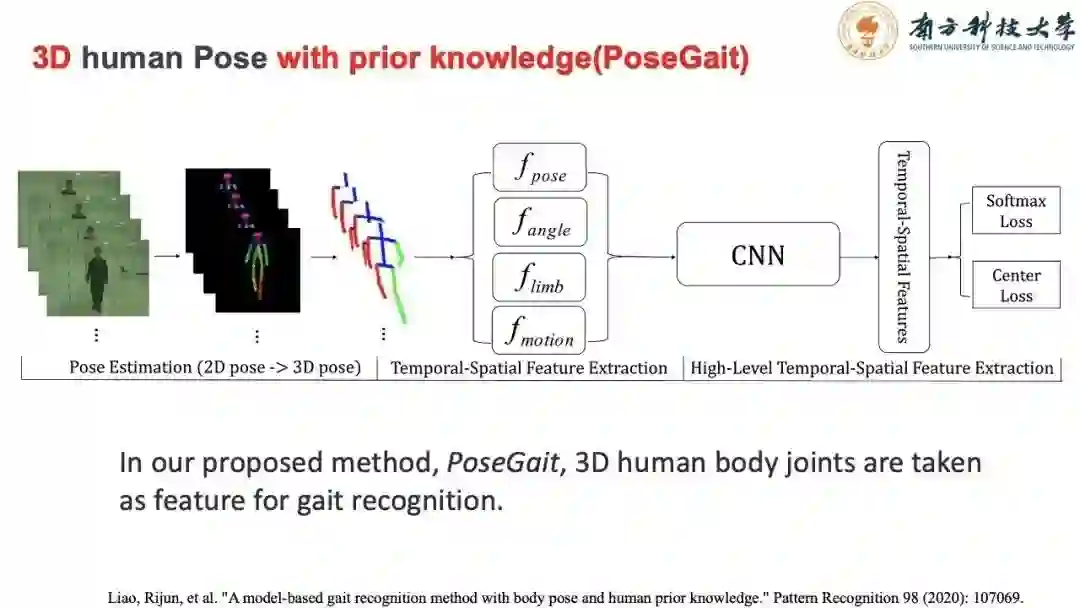
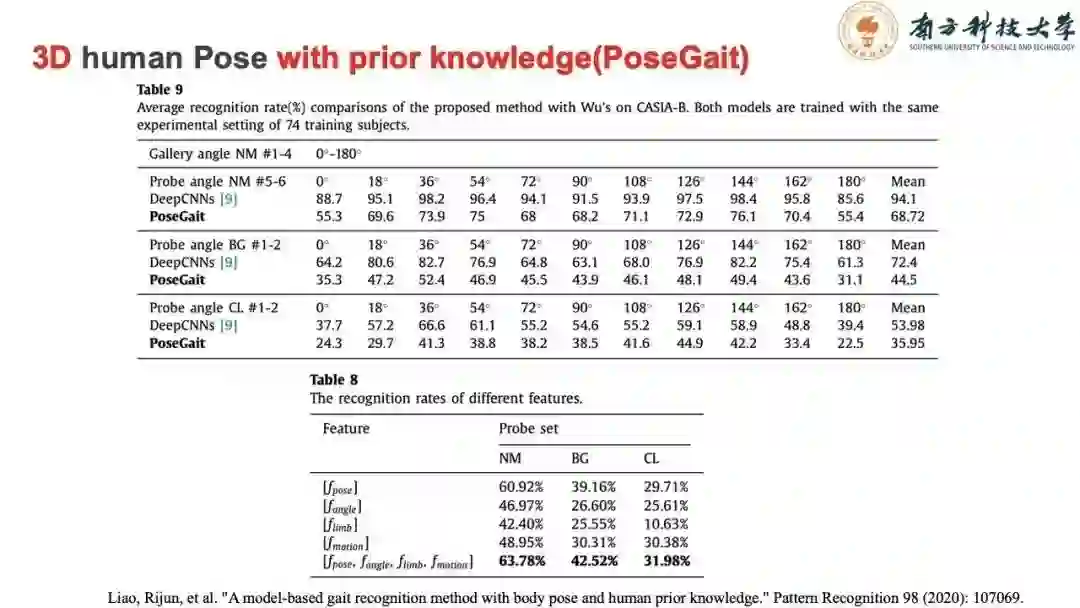
由此发表了我们的工作PoseGait,对比传统基于表观特征的识别方法,PoseGait虽然没有达到SOTA,但是背后的思想与尝试也是非常有意义的。且可以从实验结果中发现,越是复杂的识别场景下,如背包,着装,对比表观特征识别算法,两者识别的准确率差距在缩小。多种信息的融合,包括体型、运动、角度等,可以提升算法的识别率。

目前我们面临的问题是需要高精度的RGB步态识别库,为我们提供高精度的人体模型。同时,在常用的数据集中,多数步态识别数据库的数据量相对较小,规模仅在百人到千人左右。因此,我们需要一个能提供高精度RGB图像同时,有含有多视角的大规模的步态识别数据库。

为此,我们与日本大阪大学合作,共同开发了提供人体姿态数据的大规模步态识别数据库。
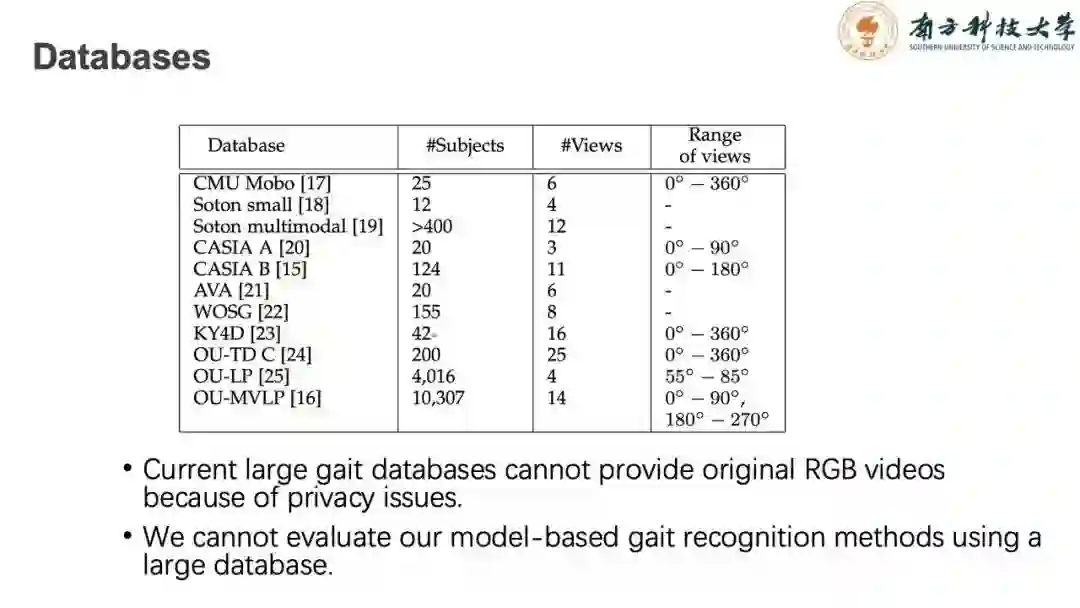
在目前多视角步态识别数据库中,来自日本大阪大学的OUMVLP数据库可以满足大规模数据库的需要,但是由于涉及隐私问题,他们并不提供RGB图像仅提供剪影图。
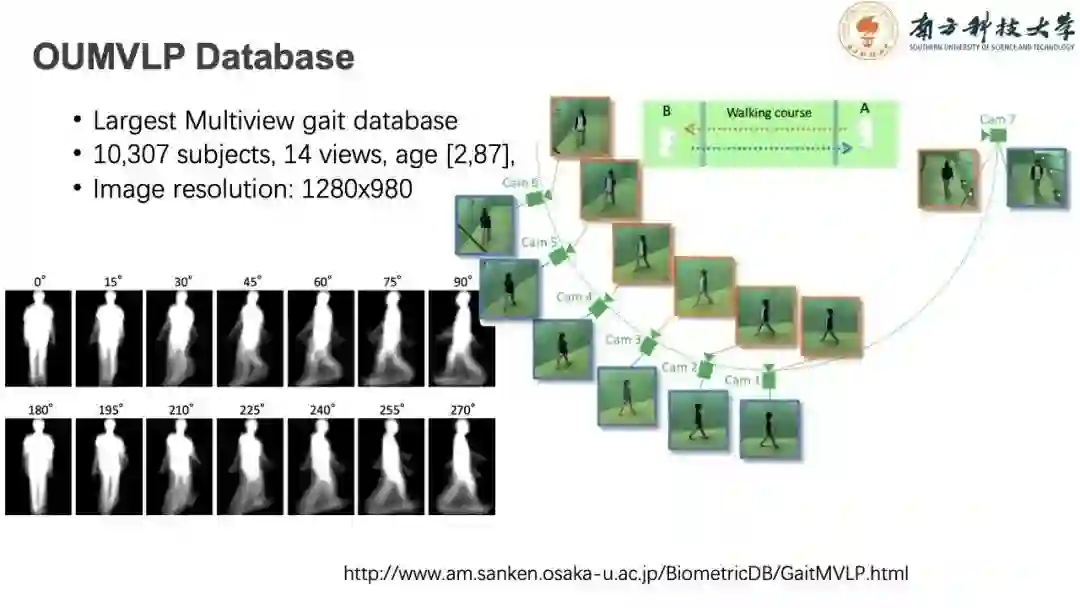
日本大阪大学多视角大规模步态识别数据库是目前最大的多视角步态库,它包含一万多人,14个视角。不仅年龄跨度丰富,图像精度也非常高。

我们选取了当时最前沿的两种姿态估计算法(OpenPose与AlphaPose)帮助我们提取骨架信息。
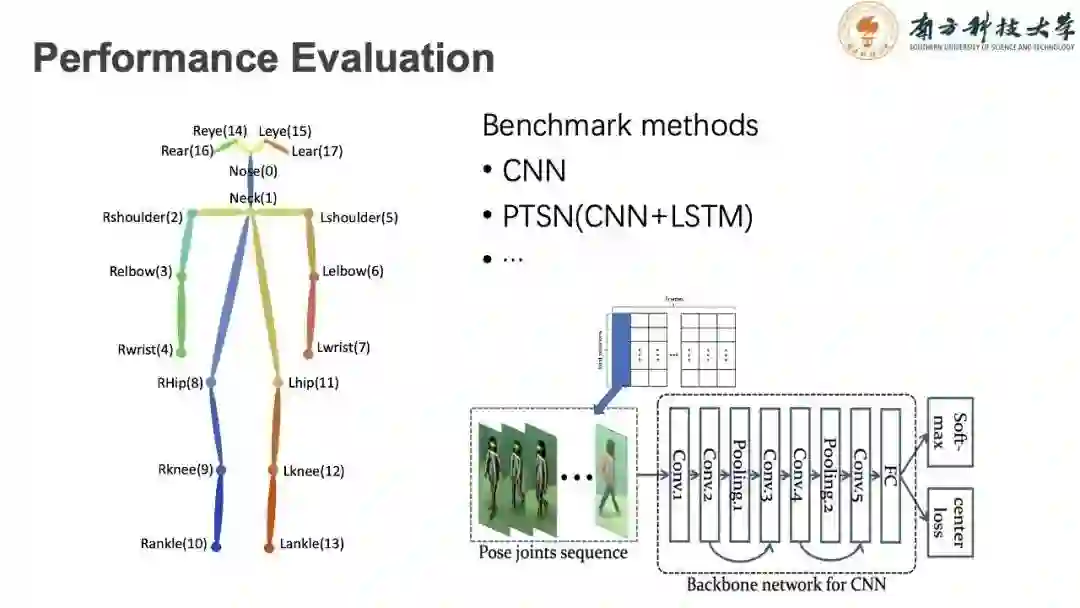
在提取的人体姿态模型中,人体的姿态由18个关键点构成,用以描述人体各个关键部位信息。此项工作的重点并非是深入进行算法的研究,而是数据库的介绍与基于模型步态识别算法评估,以帮助后续学者的加入与研究。

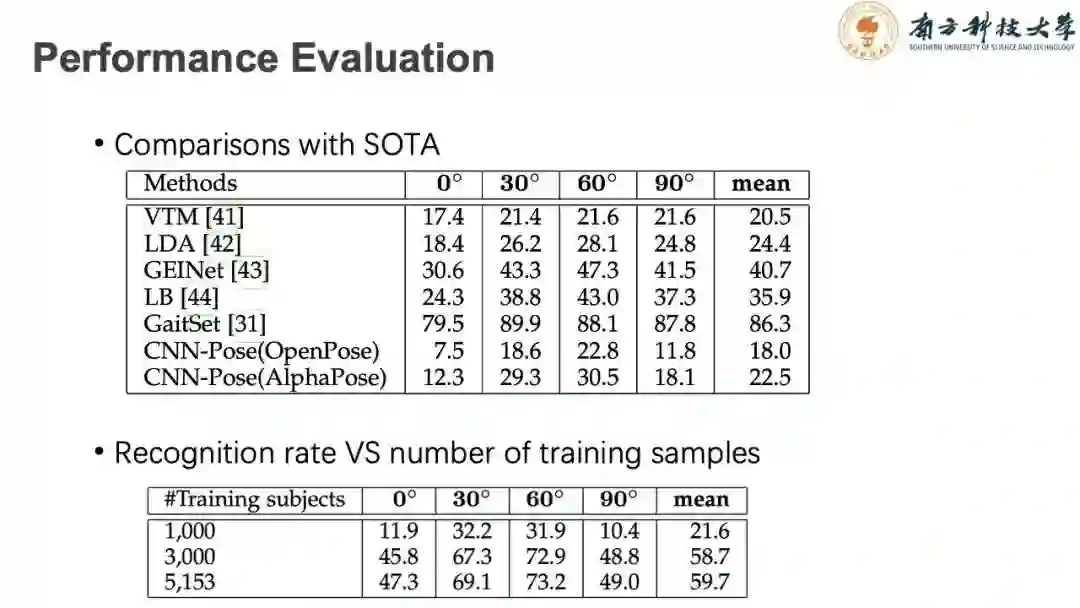
从我们在这个步态数据库上的评测来看,对比主流的表观特征,基于人体模型的识别算法还有一定的差距。但相信在后续需要更多的学者加入,集思广益,基于人体建模的识别算法也能达到可观的识别准确率。

OUMVLP-Pose 步态识别数据库的公开,作为第一个融合人体姿态信息的大规模步态识别库,相信对于领域的发展,部分学者的工作都会有一些积极的影响。

步态识别的发展过程中,许多开创性的算法不断出现,在不同的数据集中都有很好的表现。遗憾的是一直都没有一个大型的竞赛让各路学者同台PK。因此,我们与该领域的许多学者共同举办了这一场竞赛。
本次竞赛和研讨会由IAPR生物特征识别专委会(IAPR TC4)支持举办,全名为TC4 Competition and Workshop on Human Identification at a Distance 2020。研讨会/Workshop将在亚洲计算机视觉会议(ACCV2020)期间线上举办。

竞赛步态数据库CASIA-E由中科院自动化所提供,内含1000余人,是一个大规模的接近实际场景的步态数据库。
获奖的队伍,除了获得由银河水滴公司提供的奖金外,还可以在ACCV2020会议的研讨会上汇报自己的成果。
本次活动由步态识别领域的学术权威:中科院自动化所谭铁牛院士、英国南安普顿大学的Mark Nixon教授,日本大阪大学的八木康史教授担任顾问。

竞赛详情请点击上方图片
活动总结
特邀主持人:贲晛烨
什么是步态识别?步态识别其实是生物特征识别的一种,它具有远距离,无接触,难以模仿等优点。
于老师在报告中首先介绍了步态识别的历史,他觉得真正的突破是由深度学习解决的,张军平老师在2019发表的GaitSet有非常好的效果。推荐初学者可以找来这篇论文学习。
在于老师的报告中我们了解到,步态识别分为基于外观特征的,基于模型特征的步态识别。他觉得在2005年之前基于模型的步态识别是主流,王亮老师也在这个方向有工作,但是由于基于模型特征的步态识别方法更加复杂,且在后来的发展中,外观特征如GEI的步态识别方法达到了很好的效果,因此基于表观的研究开始成为主流。
于老师探讨的第二个问题,基于模型的方法/model-based,这种方法建模是比较难的。在CVPR2017上的OpenPose给于老师带来新的想法,于老师认为基于pose或者model的方法,具有较好的研究潜力,非常值得我们来研究,近期人体三维建模方向上还有一篇比较好的文章TetraTSDF,大家也可以关注一下。
最开始,于老师发现仅把得到的骨架信息用CNN或者LSTM网络中训练,无法解决视角问题。为了解决视角问题,于老师尝试了三维的模型。
第三个工作,于老师在关节的角度,运动模型上做了工作,并提出了PoseGait。但是发现对比轮廓表征的方法效果准确率还是更低一些。于老师提出自己的看法,认为如果要建模的话,需要原始的RGB图像,但这些小的库,比如之前建的CASIA-B这个步态库,在做的这种问题时容易过拟合。
基于这些问题,于老师跟日本大阪大学合作。这个日本大阪大学的步态库是目前世界上最大的公开步态数据库,它包含一万人以上的步态信息,于老师提取了骨架信息,并对比一些方法并列出这些方法在骨架步态库上的准确率作为benchmark,并公开了融合骨架的多视角大规模步态数据库OUMVLP-Pose,这个是一个比较好的开创性的工作,论文是OpenAccess,各位学者都可以免费下载。
同时,于老师还给大家带来了一个步态识别的比赛,欢迎大家关注。最后,图象图形学报上也组织了一个步态识别的专刊,欢迎大家投稿。
获奖名单
微信名或知网昵称
徐速
程佳意
巴顿Z
郭兆骐
YU-ENSTA_Paris-🤖
MQ
IIY
刘宇擎
FDD
请获奖网友联系图图提供邮寄信息

申明:本文发布的网站内容均不代表本号观点,本号旨在提供参考素材以便学习交流。

回放平台:
知网在线教学服务平台:
http://k.cnki.net/Room/Home/Index/181822
B站:
https://space.bilibili.com/27032291
往期目录:
汪荣贵——机器学习基本知识体系与入门方法
陈强——从Cell封面论文谈AI研究中的实验数据问题
石争浩——从先验到深度:低见度图像增强
行知论坛——南理工行知论坛&图图Seminar:智能画质增强专题
孙显——遥感图像智能分析:方法与应用
章国锋——视觉SLAM在AR应用上的关键性问题探讨
林宙辰——机器学习中优化算法前沿简介
白相志,冯朝路——“医学图像与人工智能”主题论坛
李雷达——以人为中心的图像感知评价:从质量到美学
汪荣贵——深度强化学习系列课程第一讲:强化学习与马氏模型
汪荣贵——深度强化学习系列课程第二讲:优化计算的基本方法
汪荣贵——深度强化学习系列课程第三讲:面向价值的深度学习
看完微推意犹未尽?
快加入图图社区,更多资讯等着你

前沿进展 | 多媒体信号处理的数学理论
中国卫星遥感回首与展望
单目深度估计方法:现状与前瞻
目标跟踪40年,什么才是未来?
10篇CV综述速览计算机视觉新进展
算法集锦 | 深度学习在遥感图像处理中的六大应用
封面故事 | 从传统到深度:火灾烟雾识别综述
封面故事 | 光场数据压缩综述
学者观点 | 结合深度学习和半监督学习的遥感影像分类
编辑推荐 | 视频 + 地图!四维信息助力实景中国
深度学习+图像降噪,如何解决“卡脖子”问题?
专家推荐|高维数据表示:由稀疏先验到深度模型
专家报告 | AI与影像“术”——医学影像在新冠肺炎中的应用
专家推荐|真假难辨还是虚幻迷离,参与介质图形绘制让人惊叹!
学者推荐 | 深度学习与高光谱图像分类【内含PPT 福利】
专家报告|深度学习+图像多模态融合
专家报告 | 类脑智能与类脑计算
实战例题!200+PPT带你看懂监督学习
118页PPT!机器学习模型参数与优化那些事儿~
专家开讲 | 机器学习究竟是什么?
羡慕别人中了顶会?做到这些你也可以!
如何阅读一篇文献?
共享 | SAR图像船舶切片数据集
资源分享| 不知道如何获取最新的算法资讯?快来这里看一看
资源分享|热门IT资讯号推荐
《中国图象图形学报》2020年第2期目次
《中国图象图形学报》2020年第1期目次
本文系《中国图象图形学报》独家稿件
内容仅供学习交流
版权属于原作者
欢迎大家关注转发!
编辑:狄 狄
指导:梧桐君
审校:夏薇薇
总编辑:肖 亮
声 明
欢迎转发本号原创内容,任何形式的媒体或机构未经授权,不得转载和摘编。授权请在后台留言“机构名称+文章标题+转载/转发”联系本号。转载需标注原作者和信息来源为《中国图象图形学报》。本号转载信息旨在传播交流,内容为作者观点,不代表本号立场。未经允许,请勿二次转载。如涉及文字、图片等内容、版权和其他问题,请于文章发出20日内联系本号,我们将第一时间处理。《中国图象图形学报》拥有最终解释权。