Dropout可能要换了,Hinton等研究者提出神似剪枝的Targeted Dropout
选自 arXiv
机器之心编译
作者:Aidan N. Gomez、Ivan Zhang、Kevin Swersky、Yarin Gal、Geoffrey E. Hinton
参与:思源
Dropout 已经是很多模型的标配,它随机删除一些神经元或权重以获得不同的「架构」。那么我们在训练中能「随机」删除很弱的连接,或不重要的神经元,因此构建更「重要」的架构吗?Hinton 等研究者表示这是可以的,这种名为 Targeted Dropout 的方法类似于将剪枝嵌入到了学习过程中,因此训练后再做剪枝会有很好性质。
这篇 Targeted Dropout 论文接受为 NIPS/NeurIPS 2018 关于紧凑神经网络的 Workshop,该研讨会关注构建紧凑和高效的神经网络表征。具体而言,其主要会讨论剪枝、量化和低秩近似等神经网络压缩方法;神经网络表示和转换格式;及使用 DNN 压缩视频和媒体的方式。
该 Workshop 的最佳论文是机器之心曾介绍过的 Rethinking the Value of Network Pruning ,这篇论文重新思考了神经网络过参数化的作用,该论文表示剪枝算法的价值可能在于识别高效结构、执行隐性的架构搜索,而不是在过参数化中选择「重要的」权重。
Workshop地址:https://nips.cc/Conferences/2018/Schedule?showEvent=10941
当然,本文还是重点关注这种 Targeted Dropout,它将剪枝隐性地构建到 Dropout 中,难道也是在隐性地搜索高效神经网络架构?
目前有很多研究工作都关注训练一个稀疏化的神经网络,而稀疏化涉及将神经网络的权重或整个神经元的激活值配置为零,并且同时要求预测准确率不能有明显下降。在学习阶段,我们一般能用正则项来迫使神经网络学习稀疏权重,例如 L1 或 L0 正则项等。当然稀疏性也可以通过后期剪枝实现,即在训练过程中使用完整模型,训练完在使用一些策略进行剪枝而实现稀疏化。
理想情况下,给定一些能度量任务表现的方法,剪枝方法会去除对模型最没有益处的权重或神经元。但这一过程非常困难,因为数百万参数的哪个子集对任务最重要是没办法确定的。因此常见的剪枝策略侧重于快速逼近较优子集,例如移除数量较小的参数,或按照任务对权重的敏感性进行排序,并去除不敏感的权重。
研究者新提出来的 Targeted Dropout 基于这样的观察:Dropout 正则化在每次前向传播中只激活局部神经元,因此它本身在训练过程中会增加稀疏性属性。这鼓励神经网络学习一种对稀疏化具有鲁棒性的表示,即随机删除一组神经元。作者假设如果我们准备做一组特定的剪枝稀疏化,那么我们应用 Dropout 到一组特定的神经元会有更好的效果,例如一组数值接近为零的神经元。
作者称这种方式为 Targeted Dropout,其主要思想是根据一些快速逼近权重重要性的度量对权重或神经元进行排序,并将 Dropout 应用于那些重要性较低的元素。与正则化 Dropout 观察结果相似,作者表示该方法能鼓励神经网络学习更重要的权重或神经元。换而言之,神经网络学习到了如何对剪枝策略保持足够的鲁棒性。
相对于其它方法,Targeted Dropout 的优点在于它会令神经网络的收敛对剪枝极其鲁棒。它同时非常容易实现,使用 TensorFlow 或 PyTorch 等主流框架只需要修改两行代码。此外,该网络非常明确,我们所需要的稀疏性程度都可以自行设定。
评审员对该方法总体是肯定的,但对其收敛性,也提出了质疑。由于对神经元(权重)重要性的估计,是基于 Dropout(剪枝)前的情况,而不是实际 Dropout(剪枝之后,这样估值误差有可能在优化迭代过程中累积,最终导致发散的结果。论文作者承诺,在最终版的附录中,会给出更详细的证明。
最后,Hinton 等研究者开源了实验代码,感兴趣的读者可以参考源代码:
项目地址:https://github.com/for-ai/TD/tree/master/models
在项目中,我们会发现对 Dropout 重要的修正主要是如下代码。其中模型会对权重矩阵求绝对值,然后在根据 targ_rate 求出要对多少「不重要」的权重做 Dropout,最后只需要对所有权重的绝对值进行排序,并 Mask 掉前面确定具体数量的「不重要」权重。
norm = tf.abs(w)
idx = tf.to_int32(targ_rate * tf.to_float(tf.shape(w)[0]))
threshold = tf.contrib.framework.sort(norm, axis=0)[idx]
mask = norm < threshold[None, :]
确定哪些权重不重要后,接下来的 Dropout 操作就和和一般的没什么两样了。下面,我们具体看看这篇论文吧。
论文:Targeted Dropout
论文地址:https://openreview.net/pdf?id=HkghWScuoQ
神经网络因为其有大量参数而显得极为灵活,这对于学习过程而言非常有优势,但同时也意味着模型有大量冗余。这些参数冗余令压缩神经网络,且还不会存在大幅度性能损失成为可能。我们介绍了一种 Targeted Dropout,它是一种用于神经网络权重和单元后分析(Post hoc)剪枝的策略,并直接将剪枝机制构建到学习中。
在每一次权重更新中,Targeted Dropout 会使用简单的挑选准则确定一组候选权重,然后再将 Dropout 应用到这个候选集合以进行随机剪枝。最后的神经网络会明确地学习到如何对剪枝变得更加鲁棒,这种方法与更复杂的正则化方案相比非常容易实现,同时也容易调参。
2 Targeted Dropout
2.1 Dropout
我们的研究工作使用了两种最流行的伯努利 Dropout 技术,即 Hinton 等人提出的单元 Dropout [8, 17] 和 Wan 等人提出的权重 Dropout[20]。对于全连接层,若输入张量为 X、权重矩阵为 W、输出张量为 Y、Mask 掩码 M_io 服从于分布 Bernoulli(α),那么我们可以定义这两种方法为:

单元 Dropout 在每一次更新中都会随机删除单元或神经元,因此它能降低单元之间的相互依赖关系,并防止过拟合。

权重 Dropout 在每一次更新中都会随机删除权重矩阵中的权值。直观而言,删除权重表示去除层级间的连接,并强迫神经网络在不同的训练更新步中适应不同的连接关系。
2.2 基于数量级的剪枝
目前比较流行的一类剪枝策略可以称之为基于数量级的剪枝,这些策略将 k 个最大的权重数量级视为最重要的连接。我们一般可以使用 argmax-k 以返回所有元素中最大的 k 个元素(权重或单元)。
单元剪枝 [6],考虑权重矩阵列向量的 L2 范数:
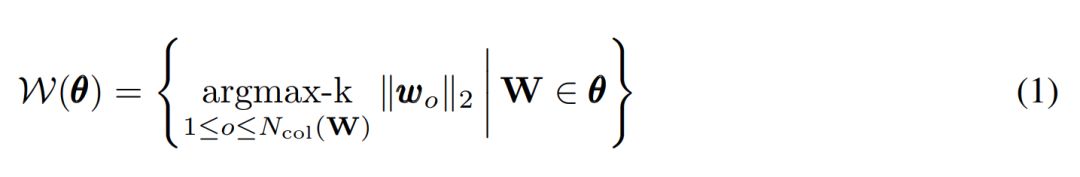
权重剪枝 [10],若 top-k 表示相同卷积核中最大的 k 个权值,考虑权重矩阵中每一个元素的 L1 范数:
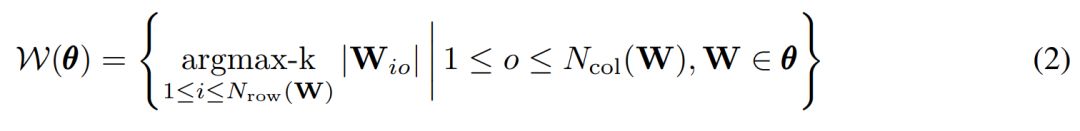
其中权重剪枝一般能保留更多的模型准确度,而单元剪枝能节省更多的计算力。
2.3 方法
若有一个由θ参数化的神经网络,且我们希望按照方程 (1) 和 (2) 定义的方法对 W 进行剪枝。因此我们希望找到最优参数θ*,它能令损失函数ε(W(θ*)) 尽可能小的同时令|W(θ* )| ≤ k,即我们希望保留神经网络中最高数量级的 k 个权重。一个确定性的实现可以选择最小的 |θ| − k 个元素,并删除它们。
但是如果这些较小的值在训练中变得更重要,那么它们的数值应该是增加的。因此,通过利用靶向比例γ和删除概率α,研究者将随机性引入到了这个过程中。其中靶向比例(targeting proportion)表示我们会选择最小的γ|θ|个权重作为 Dropout 的候选权值,并且随后以丢弃率α独立地去除候选集合中的权值。
这意味着在 Targeted Dropout 中每次权重更新所保留的单元数为 (1 − γ · α)|θ|。正如我们在后文所看到的,Targeted Dropout 降低了重要子网络对不重要子网络的依赖性,因此降低了对已训练神经网络进行剪枝的性能损失。
如下表 1 和表 2 所示,研究者的权重剪枝实验表示正则化方案的基线结果要比 Targeted Dropout 差。并且应用了 Targeted Dropout 的模型比不加正则化的模型性能更好,且同时参数量还只有一半。通过在训练过程中逐渐将靶向比例由 0 增加到 99%,研究者表示我们能获得极高的剪枝率。
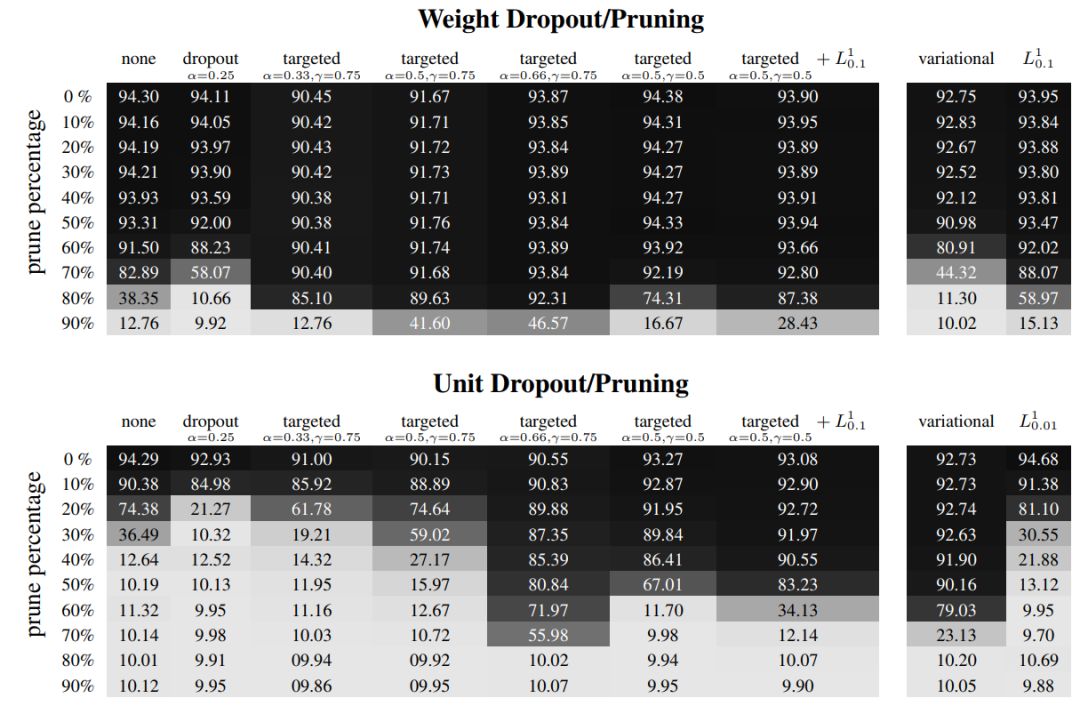
表 1:ResNet-32 在 CIFAR-10 的准确率,它会使用不同的剪枝率和正则化策略。上表展示了权重剪枝策略的结果,下表展示了单元剪枝的结果。
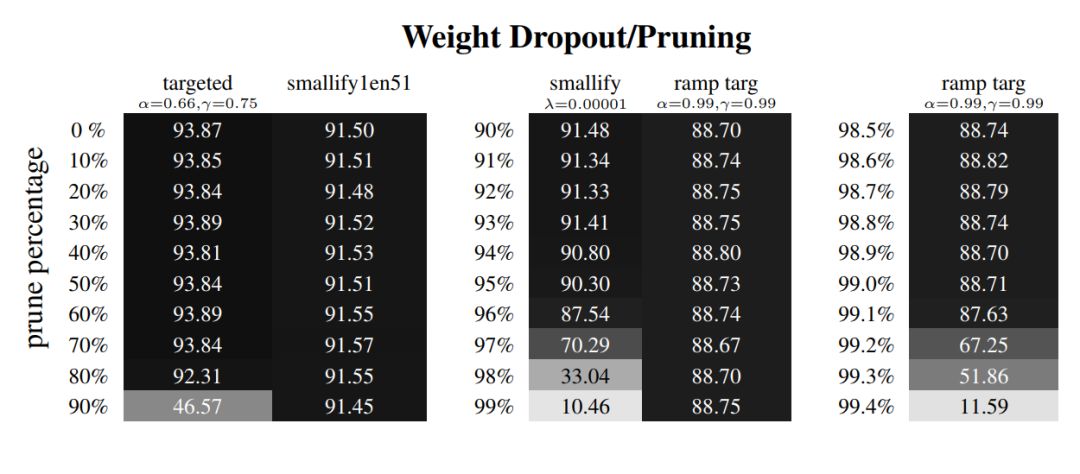
表 2:比较 Targeted Dropout 和 ramping Targeted Dropout 的 Smallify。实验在 CIFAR-10 上使用 ResNet-32 完成。其中左图为三次 targeted 中最好的结果与 6 次 smallify 中最好结果的对比,中间为检测出最高的剪枝率,右图为 ramp targ 检测出的更高剪枝率。
3 结语
我们提出了一种简单和高效的正则化工具 Targeted Dropout,它可以将事后剪枝策略结合到神经网络的训练过程中,且还不会对特定架构的潜在任务性能产生显著影响。最后 Targeted Dropout 主要的优势在于简单和直观的实现,及灵活的超参数设定。

点击「阅读原文」填写报名表单,工作人员在审核后会发送评选申请表格。
申请企业需按照要求填写评选申请表格。
未尽事宜可添加机器之心小助手:syncedai3 进行咨询;添加好友请备注「年度评选」。


