深度协同过滤:用神经网络取代内积建模


在碎片化阅读充斥眼球的时代,越来越少的人会去关注每篇论文背后的探索和思考。
在这个栏目里,你会快速 get 每篇精选论文的亮点和痛点,时刻紧跟 AI 前沿成果。
点击本文底部的「阅读原文」即刻加入社区,查看更多最新论文推荐。
本期推荐的论文笔记来自 PaperWeekly 社区用户 @spider。尽管现在很多工作已经把深度学习运用到了推荐的任务当中,但大多只是利用深度学习给一些辅助信息建模,在表示 user 与item 之间的交互时,仍是使用矩阵分解等用内积来建模。
本文是新加坡国立大学发表于 WWW '17 的工作,作者提出用多层神经网络给 user 和 item 进行交互建模,并提出了一种基于神经网络的协同过滤通用框架 NCF。
如果你对本文工作感兴趣,点击底部阅读原文即可查看原论文。
关于作者:黄若孜,复旦大学软件学院硕士生,研究方向为推荐系统。
■ 论文 | Neural Collaborative Filtering
■ 链接 | https://www.paperweekly.site/papers/635
■ 源码 | http://t.cn/ROuhFZP
论文动机
许多利用深度学习来做推荐的工作 focus 在辅助信息的提取上,而对协同过滤最关键的元素——user 和 item 之间的交互作用,这些工作仍然利用的是矩阵分解模型,利用 latent feature 的内积进行推荐,而内积的描述能力是有限的。
Neural Collaborative Ffiltering(NCF)是一种用神经网络取代这个内积部分的技术,以学到 latent feature 之间任意的函数关系。
模型
MF 利用特征向量 pu、qi 的内积评估 u 对 i 的偏好:
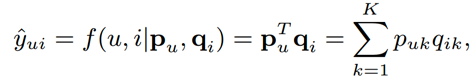
由于将 user 和 item 映射到了同样的特征空间,然后使用内积也就是两个向量的 cosine 来衡量相似性;同样的,我们也可以用内积来衡量两个用户的相似性。
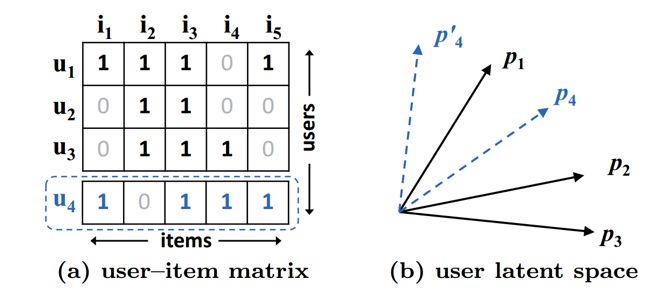
使用 jaccard 系数(集合 A 与 B 的交集与并集的比值作为集合的相似度)来作为用户之间真实的相似程度,那么下面评分矩阵用户 123 之间 S23>S12>S13,在 latent space 中的几何关系如右图所示,加入用户 4 时,S41>S43>S42,于是我们让用户 4 的特征靠近 1,然而无论怎么放,都无法使用户 3 比用户 2 更接近用户 4。
这就是使用内积描述相似度的局限性,我们可以增大 K 来解决这个问题,但是存在过拟合的风险。
下图是 NCF 的框架,user 和 item 的 id 先经过 embedding 层得到一个特征,然后输入到 MLP 中得到打分结果,用 pointwise 的目标函数进行训练:
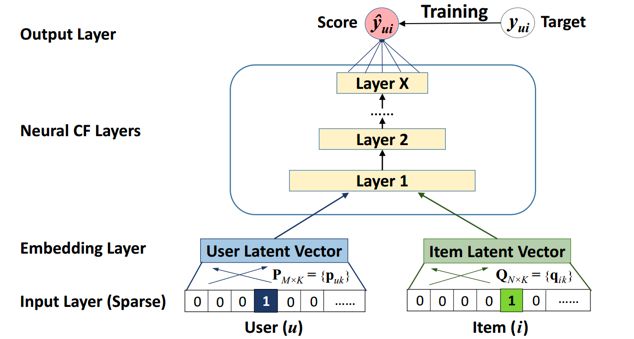
其中 user 和 item 的 embedding 结果可以通过逐元素乘积的形式结合,然后作为 MLP 的输入,称为 GMF 模型。
这种情况下 NCF 可以包含 MF(即使用 identity 的激活函数,同时将隐藏层全部置为 1,可起到内积的效果),如果使用非线性的激活函数,那么比起线性 MF,这个设置使模型具有更强的表达能力。
此外一个常规的思路就是讲两个 vector 拼接起来作为 MLP 的输入,称为 MLP 模型。本文也提出了一个将这两种方法融合起来的模型,称为 NeuMF:
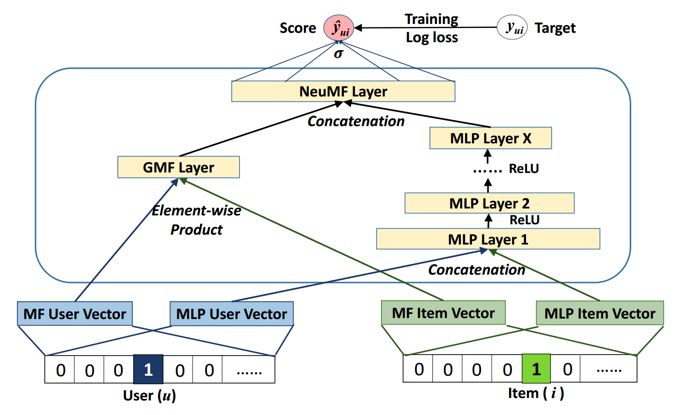
由于本模型使用的是隐式反馈(1/0),如果使用平方误差函数:
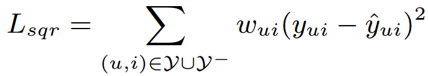
那么实际上相当于认为预测的 yui 是以 f(u,i|θ) 为均值的高斯分布,而这样的假设显然是不适合二值的隐式反馈。所以我们可以将待遇测的值看做是一个分类问题,即用户和项目是否有交互。
使用逻辑回归进行训练,得到一个二元交叉熵损失,其中 Y- 可以是全部或者部分的负样本(也会就是负采样方法):
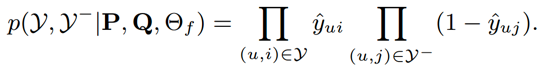
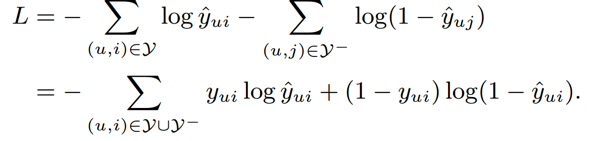
实验
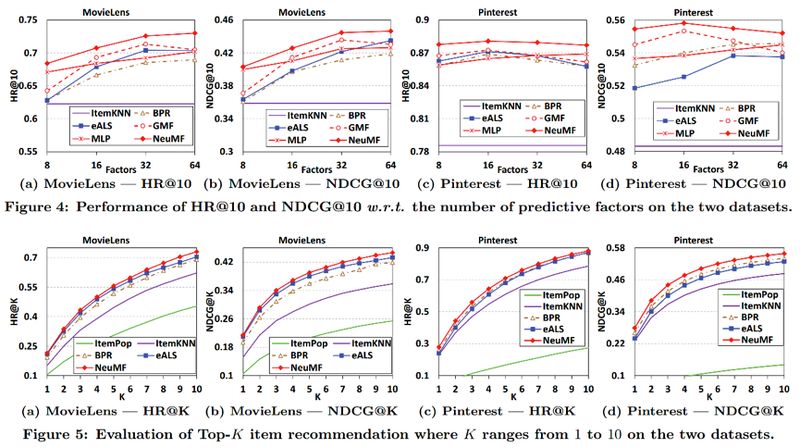
本文在 MovieLens,Pinterest 两个数据集上进行了验证,使用了 HR@10,NDCG@10 作为指标,使用了 itempop,itemknn,bpr,eALS 作为 baseline:
评价
在 MF 出来之后,一大批用各种方法融合属性、上下文的基于 MF 的方法冒了出来,这篇 NCF 的方法提出来之后,在最近比较火的 cross domain 等 task 上,已经出了一批基于 NCF 的方法,可以说在深度学习浪潮下,NCF 是一代新的基础模型(之一)了。
本文由 AI 学术社区 PaperWeekly 精选推荐,社区目前已覆盖自然语言处理、计算机视觉、人工智能、机器学习、数据挖掘和信息检索等研究方向,点击「阅读原文」即刻加入社区!

点击标题查看更多论文解读:

▲ 戳我查看招募详情

关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 查看原论文





