500万照片+20万地标,谷歌更新最大地标数据集
新智元报道
新智元报道
来源:venturebeat
编辑:元子
【新智元导读】谷歌最大的地标数据集更新,开源的Google-Landmarks-v2包含500万张图片和200000个地标。同时举办两项总奖金5万美元(约34万人民币)的比赛,鼓励更多人来为该项目添砖加瓦。
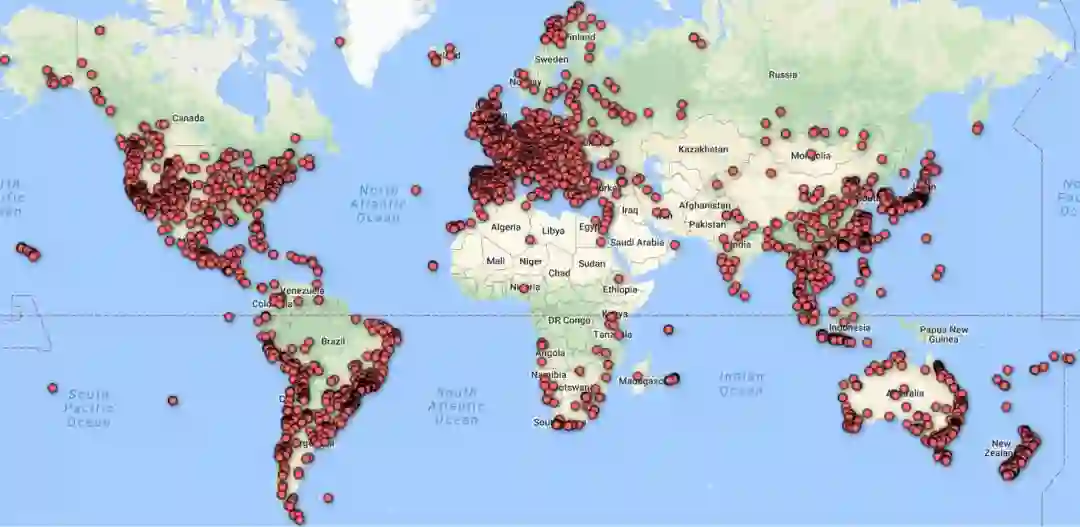
尼亚加拉大瀑布和黄果树大瀑布无论在地理位置还是在照片里的呈现形态都是不同的。Google AI部门希望AI不仅能够区分出两者,同时还应该将各自对应的坐标识别出来,不论照片中的大瀑布是侧面照、正面照还是航拍照。
去年,Google发布了Google-Landmarks,这是当时世界上最大的地标数据集,并举办了两场比赛:Landmark Recognition 2018和Landmark Retrieval 2018,有500多名机器学习研究人员参加。
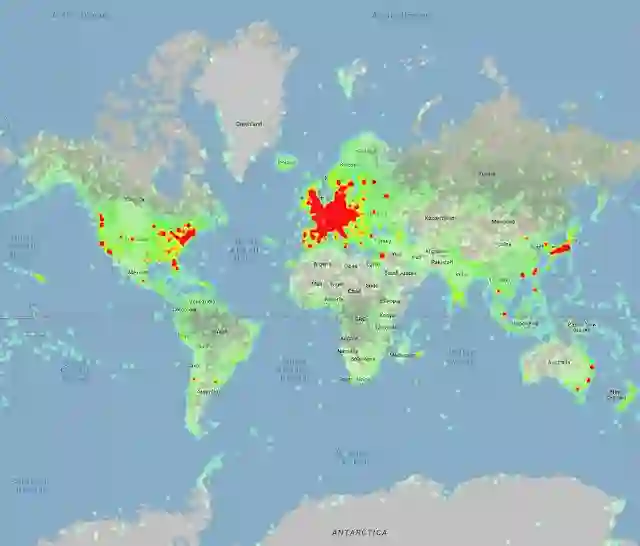
不到一年的时候,Google就开源了它的升级版:Google-Landmarks-v2。这是一个新的、拥有更大地标识别语料的库,包含的照片数量是初代的两倍、地标数据量是初代的七倍。从此,Google朝着更复杂的地标检测计算机视觉模型的目标迈出了重要的一步。下图为Google-Landmarks-v2中地标位置的热图👇
紧接着,Google又在机器学习社区Kaggle上,推出了两项新的挑战:Landmark Recognition 2019和Landmark Retrieval 2019 ,并发布了Detect-to-Retrieve的源代码和模型,这是一个区域图像检索框架。
Landmark Recognition 2019的参赛者需要设计地标检测AI模型,Landmark Retrieval 2019的参赛者需要使用一个AI系统,找出指定地标关联的图像。两项赛事都包括总额为50000美元的现金奖励,获胜团队还将获邀参加CVPR 2019的研讨会。
Google AI软件工程师Bingyi Cao和Tobias Weyand说:“实例识别和图像检索方法都需要更大的数据集,包括图像数量和各种标志,以便训练出更好、更强大的系统。我们希望这个数据集能够帮助推进实例识别和图像检索方面的最新技术。”

根据Bingyi和Weyand的说法,Google-Landmarks-v2包含了超过500万张来自世界各地摄影师收集的20多万个不同地标的图像,然后将照片里的图像进行标注,比如新天鹅堡、金门大桥、清水寺、哈利法塔、狮身人面像、马丘比丘和其他着名景点,最后Google的研究人员用来自Wikimedia的免费资源,例如图像、音频及其他类型的媒体文件,来补充历史和鲜为人知的图像。
那么Detect-to-Retrieve框架又是用来干什么的呢?Bingyi和Weyand表示,已发布的、由原始地标数据集中的80000个子集进行训练的模型,利用来自物体检测模型的边界框,来为包含感目标项目的图像区域提供“额外的权重”,从而可以显著的提高准确性。

目前这个数据集只有训练集开放下载。测试集等会随着挑战赛的进行而逐渐开放。
数据集:
https://github.com/cvdfoundation/google-landmark
挑战赛:
https://www.kaggle.com/c/landmark-recognition-2019
新智元春季招聘开启,一起弄潮 AI 之巅!
岗位详情请戳:
.png")
【加入社群】
新智元 AI 技术 + 产业社群招募中,欢迎对 AI 技术 + 产业落地感兴趣的同学,加小助手微信号:aiera2015_2 入群;通过审核后我们将邀请进群,加入社群后务必修改群备注(姓名 - 公司 - 职位;专业群审核较严,敬请谅解)。






