教科书上的LDA为什么长这样?

作者丨DeAlVe
学校丨某211硕士生
研究方向丨模式识别与机器学习
线性判别分析(Linear Discriminant Analysis, LDA)是一种有监督降维方法,有关机器学习的书上一定少不了对 PCA 和 LDA 这两个算法的介绍。LDA 的标准建模形式是这样的(这里以两类版本为例,文章会在几个关键点上讨论多类情况):
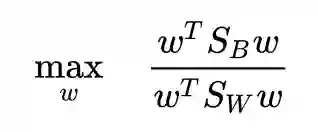
其中,是类间散布矩阵,
是类内散布矩阵, w 是投影直线:
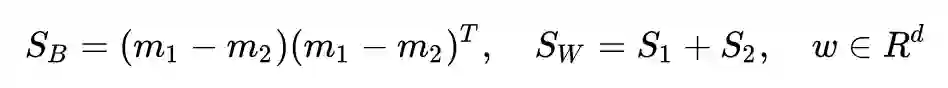
怎么样,一定非常熟悉吧,经典的 LDA 就是长这个样子的。这个式子的目标也十分直观:将两类样本投影到一条直线上,使得投影后的类间散布矩阵与类内散布矩阵的比值最大。
三个加粗的词隐含着三个问题:
1. 为什么是类间散布矩阵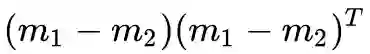
2. 为什么是投影到直线,而不是投影到超平面?PCA 是把 d 维样本投影到 c 维 (c<d),LDA 为什么不能也投影到 c 维,而是直接投影到 1 维呢?同样地,在 K 类 LDA 中,为什么书上写的都是投影到 K-1 维,再高一点不行吗?这是必然吗?
3. 为什么是类间散布与类内散布的比值呢?差值不行吗?
这篇文章就围绕这三个问题展开。我们先回顾一下经典 LDA 的求解,然后顺次讲解分析这三个问题。
回顾经典LDA
原问题等价于这个形式:
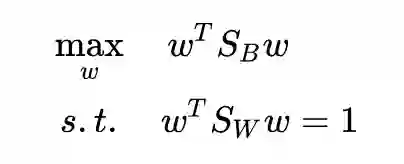
然后就可以用拉格朗日乘子法了:
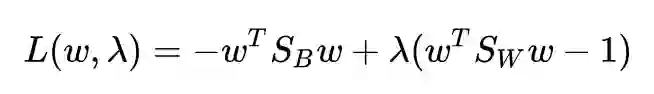
求导并令其为 0:
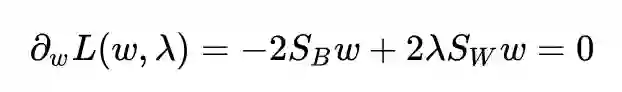
得到解:
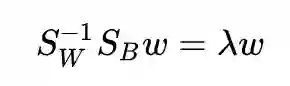
对矩阵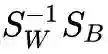
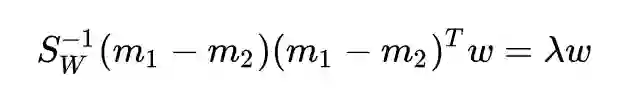
而其中

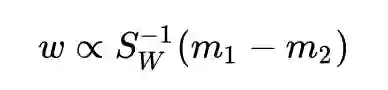
求解完毕。非常优雅,不愧是教科书级别的经典算法,整个求解一气呵成,标准的拉格朗日乘子法。但是求解中还是用到了一个小技巧:
那么,我们能不能再贪心一点,找到一种连这个小技巧都不需要的求解方法呢?答案是可以,上面的问题在下一节中就能得到解决。
类间散布 & 均值之差
我们不用类内散布矩阵

还是用拉格朗日乘子法:
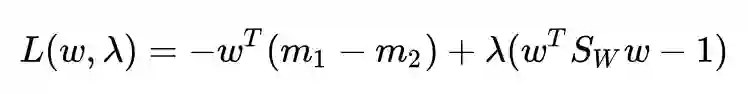
求导并令其为 0:
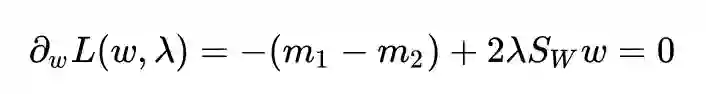
得到解:
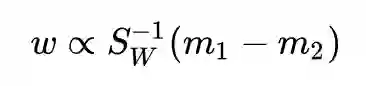
怎么样,是不是求解更简单了呢?不需要任何技巧,一步一步下来就好了。
为什么说均值之差更符合直觉呢?大家想啊,LDA 的目的是让投影后的两类之间离得更远,类内离得更近。说到类内离得更近能想到的最直接的方法就是让类内方差最小,这正是类内散布矩阵;说到类间离得更远能想到的最直接的方法肯定是让均值之差最大,而不是均值之差与自己的克罗内克积这个奇怪的东西最大。
那么经典 LDA 为什么会用类间散布矩阵呢?我个人认为是这样的表达式看起来更加优雅:分子分母是齐次的,并且这个东西恰好就是广义瑞利商:
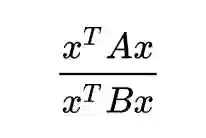
虽然经典 LDA 求解没有上面这个方法直接,但是问题表述更加规范,所用到的技巧也非常简单,不会给是使用者带来困扰,所以 LDA 最终采用的就是类间散布矩阵了吧。
直线 & 超平面
上面那个问题只算是小打小闹,没有太大的意义,但是这个问题就很有意义了:LDA 为什么直接投影到直线(一维),而不能像 PCA 一样投影到超平面(多维)呢? 我们试试不就完了。
假设将样本投影到
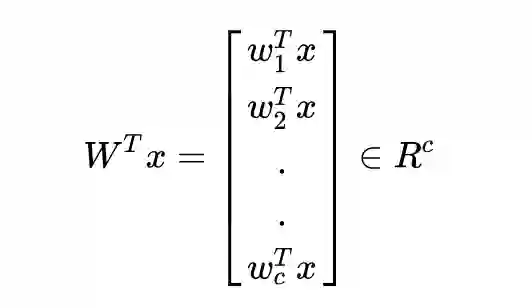
所以样本的投影过程就是:
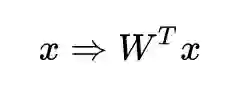
那么,均值的投影过程也是这样:
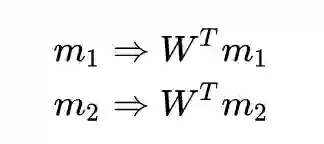
投影后的均值之差的二范数:
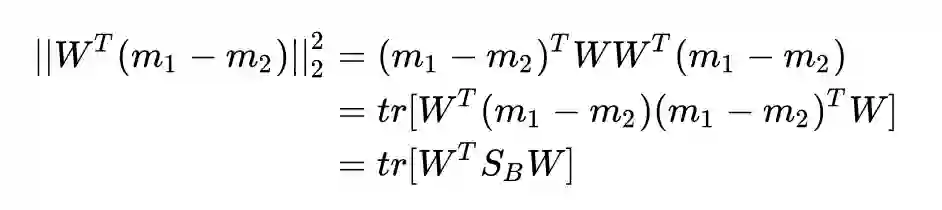
为什么不用第一行的向量内积而偏要用第二行的迹运算呢?因为这样可以拼凑出类间散布
回顾一下经典 LDA 的形式:
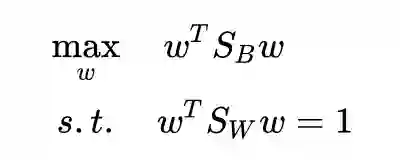
现在我们有了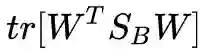
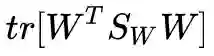
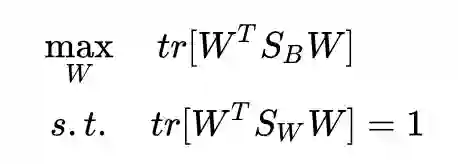
实际上,约束也可以选择成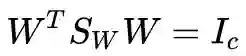
回想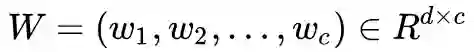
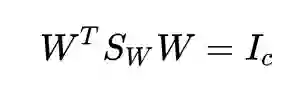
右边是秩为 c 的单位矩阵,因为矩阵乘积的秩不大于每一个矩阵的秩,所以左边这三个矩阵的秩都要不小于 c,因此我们得到了 rank(W) = c。也就是说,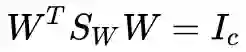
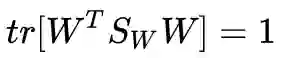
我对矩阵的理解还不够深入,不知道
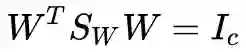
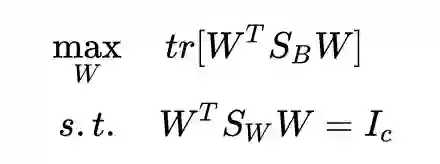
下面来求解这个问题。还是拉格朗日乘子法:
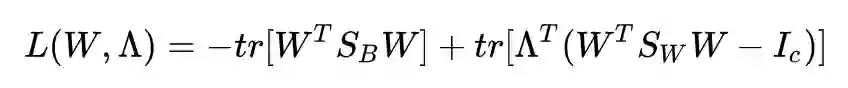
求导并令其为 0:
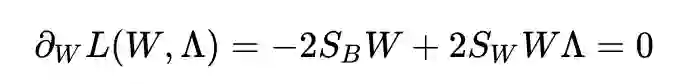
得到了:
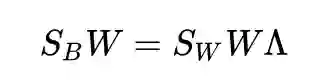
在大部分情况下,一些协方差矩阵的和是可逆的。即使不可逆,上面这个也可以用广义特征值问题的方法来求解,但是这里方便起见我们认为
可逆:
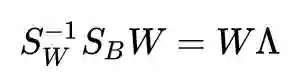
我们只要对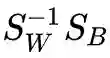
真的是这样吗?
不是这样的。诚然,我们可以选出 c 个特征向量,但是其中只有 1 个特征向量真正是我们想要的,另外 c-1 个没有意义。
观察:
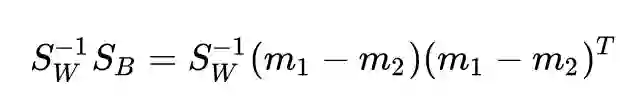
发现了吗?等式右边的 (m1-m2) 是一个向量,换句话说,是一个秩为 1 的矩阵。那么,这个乘积的秩也不能大于 1,并且它不是 0 矩阵,所以:
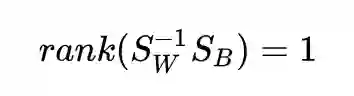
秩为 1 的矩阵只有 1 个非零特征值,也只有 1 个非零特征值对应的特征向量 w。
可能有人会问了,那不是还有零特征值对应的特征向量吗,用它们不行吗?
不行。来看一下目标函数:
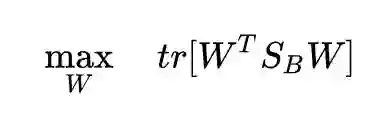
我们刚才得到的最优性条件:

所以目标函数为:
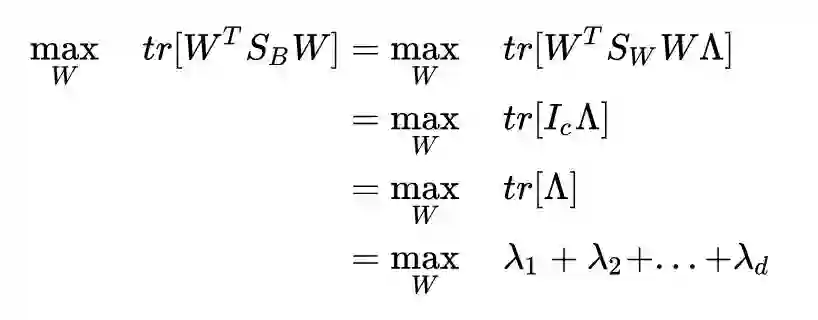
而我们的 W 只能保证 λ1, λ2, ..., λd 中的一个非零,无论我们怎么选取剩下的 c-1 个 w,目标函数也不会再增大了,因为唯一一个非零特征值对应的特征向量已经被选走了。
所以,两类 LDA 只能向一条直线投影。
这里顺便解释一下 K 类 LDA 为什么只能投影到 K-1 维,其实道理是一样的。K 类 LDA 的类间散布矩阵是:
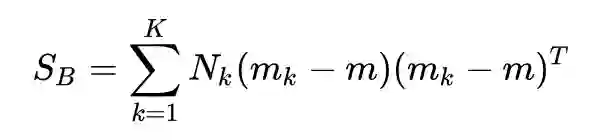
可以看出,是 K 个秩一矩阵
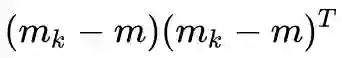
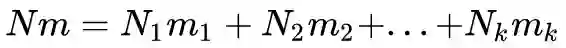
的秩最大为 K-1。也即:
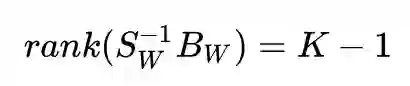
只有 K-1 个非零特征值。所以,K 类 LDA 最高只能投影到 K-1 维。
咦?刚才第三个问题怎么提的来着,可不可以不用比值用差值,用差值的话会不会解决这个投影维数的限制呢?
比值 & 差值
经典 LDA 的目标函数是投影后的类间散布与类内散布的比值,我们很自然地就会想,为什么非得用比值呢,差值有什么不妥吗? 再试试不就完了。
注意,这一节我们不用向量 w,而使用矩阵 W 来讨论,这也就意味着我们实际上在同时讨论二类 LDA 和多类 LDA,只要把和
换成对应的就好了。
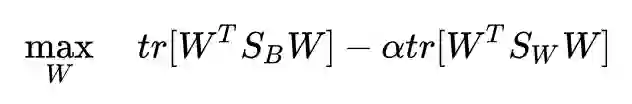
注意到可以通过放缩 W 来得到任意大的目标函数,所以我们要对 W 的规模进行限制,同时也进行秩限制:
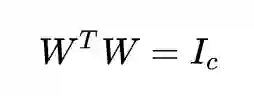
也就得到了差值版的 LDA:
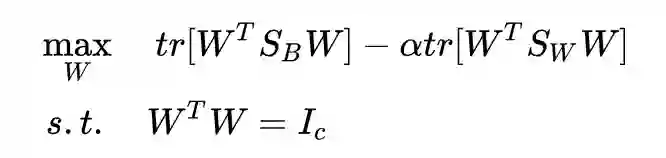
依然拉格朗日乘子法:
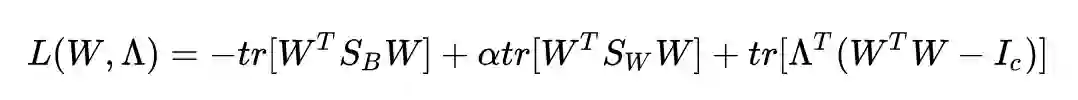
求导并令其为 0:
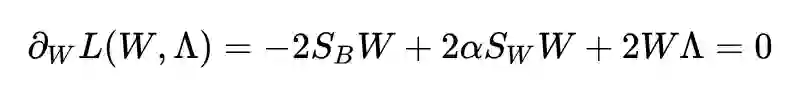
得到了:
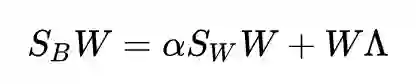
由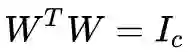
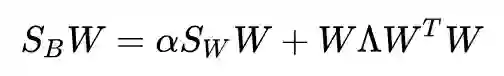
可以得到:
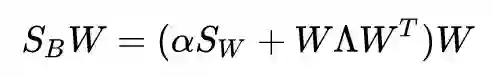
若括号内的东西可逆,则上式可以写为:
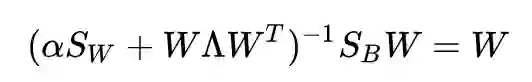
注意到, 的秩不大于 K-1,说明等号左边的秩不大于 K-1,那么等号右边的秩也不大于 K-1,即:
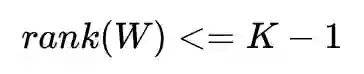
所以我们还是会遇到秩不足,无法求出 K-1 个以上的非零特征值和对应的特征向量。这样还不够,我们还需要证明的一点是,新的目标函数在零特征值对应的特征向量下依然不会增加。
目标函数(稍加变形)为:
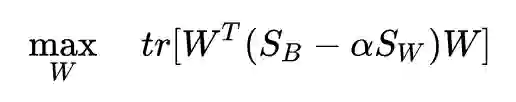
再利用刚才我们得到的最优性条件(稍加变形):
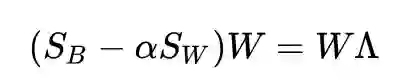
所以目标函数为:
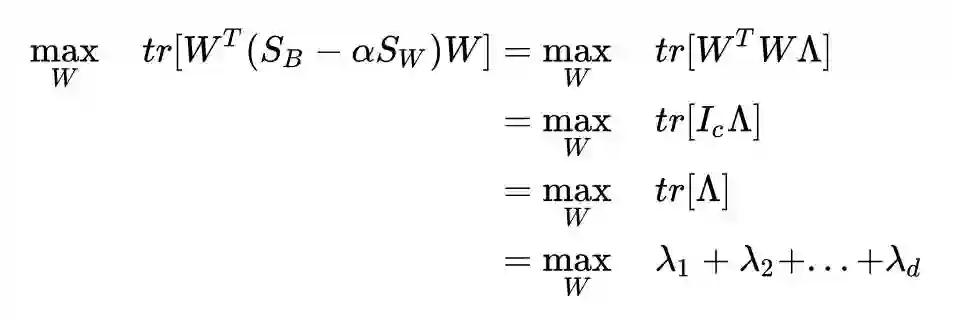
结论没有变化,新的目标函数依然无法在零特征值的特征向量下增大。
综合新矩阵依然秩不足和零特征值依然对新目标函数无贡献这两点,我们可以得到一个结论:用差值代替比值也是可以求解的,但是我们不会因此受益。
既然比值和差值算出来的解性质都一样,那么为什么经典 LDA 采用的是比值而不是差值呢?
我个人认为,这可能是因为比值算出来的解还有别的直觉解释,而差值的可能没有,所以显得更优雅一些。什么直觉解释呢?
在二分类问题下,经典 LDA 是最小平方误差准则的一个特例。若让第一类的样本的输出值等于 N/N1 ,第二类样本的输出值等于 -N/N2 , N 代表相应类样本的数量,然后用最小平方误差准则求解这个模型,得到的解恰好是(用比值的)LDA 的解。这个部分 PRML 上有讲解。
总结
这篇文章针对教科书上 LDA 的目标函数抛出了三个问题,并做了相应解答,在这个过程中一步一步深入理解 LDA。
第一个问题:可不可以用均值之差而不是类间散布?
答案:可以,这样做更符合直觉,并且更容易求解。但是采用类间散布的话可以把 LDA 的目标函数表达成广义瑞利商,并且上下齐次更加合理。可能是因为这些原因,经典 LDA 最终选择了类间散布。
第二个问题:可不可以把 K 类 LDA 投影到大于 K-1 维的子空间中?
答案:不可以,因为类间散布矩阵的秩不足。K 类 LDA 只能找到 K-1 个使目标函数增大的特征值对应的特征向量,即使选择了其他特征向量,我们也无法因此受益。
第三个问题:可不可以用类间散布与类内散布的差值,而不是比值?
答案:可以,在新准则下可以得到新的最优解,但是我们无法因此受益,K 类 LDA 还是只能投影到 K-1 维空间中。差值版 LDA 与比值版 LDA 相比还缺少了一个直觉解释,可能是因为这些原因,经典 LDA 最终选择了比值。
所以,教科书版 LDA 如此经典是有原因的,它在各个方面符合了人们的直觉,本文针对它提出的三个问题都没有充分的理由驳倒它,经典果然是经典。

点击以下标题查看其他相关文章:

让你的论文被更多人看到
如何才能让更多的优质内容以更短路径到达读者群体,缩短读者寻找优质内容的成本呢? 答案就是:你不认识的人。
总有一些你不认识的人,知道你想知道的东西。PaperWeekly 或许可以成为一座桥梁,促使不同背景、不同方向的学者和学术灵感相互碰撞,迸发出更多的可能性。
PaperWeekly 鼓励高校实验室或个人,在我们的平台上分享各类优质内容,可以是最新论文解读,也可以是学习心得或技术干货。我们的目的只有一个,让知识真正流动起来。
📝 来稿标准:
• 稿件确系个人原创作品,来稿需注明作者个人信息(姓名+学校/工作单位+学历/职位+研究方向)
• 如果文章并非首发,请在投稿时提醒并附上所有已发布链接
• PaperWeekly 默认每篇文章都是首发,均会添加“原创”标志
📬 投稿邮箱:
• 投稿邮箱:hr@paperweekly.site
• 所有文章配图,请单独在附件中发送
• 请留下即时联系方式(微信或手机),以便我们在编辑发布时和作者沟通
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。

▽ 点击 | 阅读原文 | 获取最新论文推荐





