小心深度学习这个“坑”(入门误区详细版)

定位:深层学习在哪
1、深层学习需要什么?
数学
线性代数:是有关任意维度空间下事物状态和状态变化的规则。
概 率:是用来衡量我们对事物在跨时间后不同状态的确信度。
编程
操作矩阵
实现数学想法
学习的难点
其实就是学习寻找关联函数f的过程。
难点:需要在未见过的任务上表现良好
有一种极端情况:
记忆:记住所有的训练样本和对应标签。
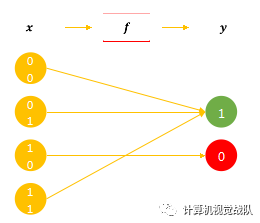

实际:无法被穷尽,各式各样的变体。


关于函数f的寻找
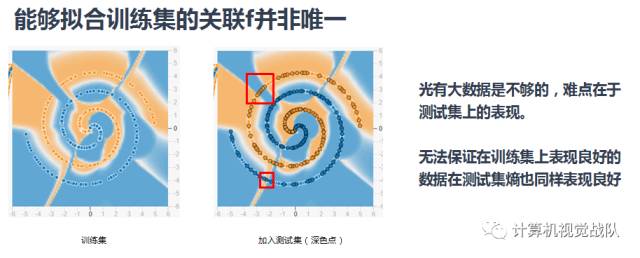
维度的问题:
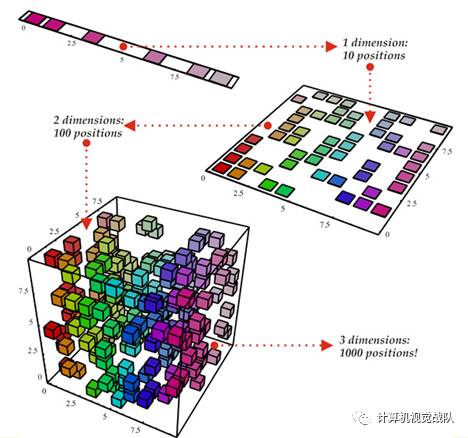
维度越大,我们越无法获得所有的情况。
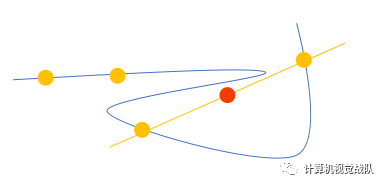
面临没见过的情况,一般是将左右的情况平均一下。但是这种方法在高维数据下并不适用。
分布式表达:
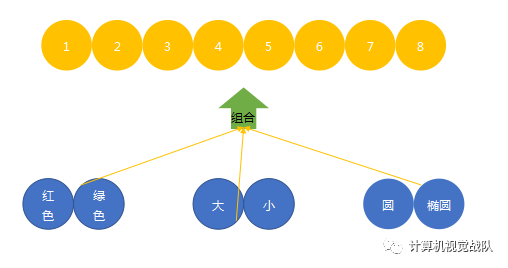
原本需要8个不同情况,现在只需要6个。因为8个变体是又3种因素组合而成的。
数字表示法:解决变化的因素。
椭圆这个factor实际上也是有变体的,可以以相同的思路继续拆分,继续降低训练所需数据量。
No Free Lunch Theorem

任何两个优化算法是等价的,当它们的性能是在所有可能的问题的平均值。
深层VS浅层
分布式表达是将变体拆分成因素。但是如果用无限节点的浅层网络,所拆分的变体并不会在不同样本之间形成共享。
而深层神经网络,由于拆分的变体可以在不同样本间共享,在浅层网络中只负责学习自己的关联,而在深层网络中,那些共用相同因素的样本也会被间接的训练到。换句话说,深层的优势在于节省了训练所需的数据量。
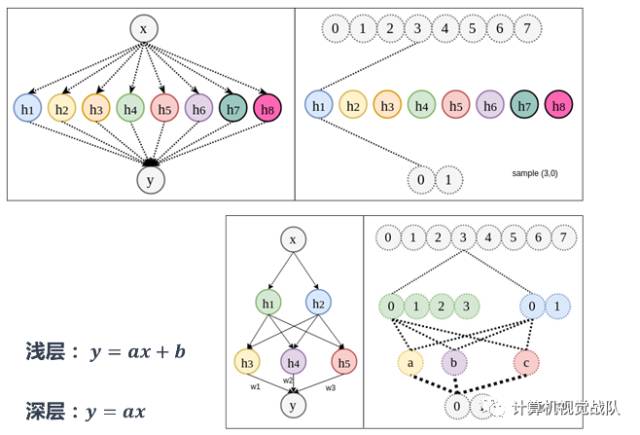
关键:因素的共享
深层神经网络
学习的过程是因素间的关系的拆分,关系的拆分是信息的回卷,信息的回卷是变体的消除,变体的消除是不确定性的缩减。
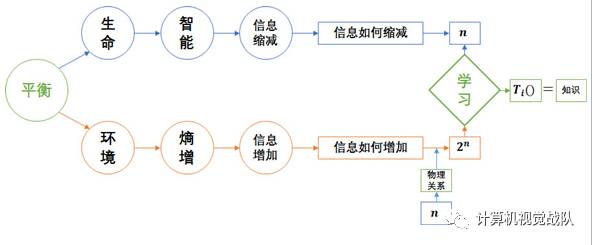
自然界两个固有的先验知识:
并行:新状态是由若干旧状态并行组合形成。
迭代:新状态由已形成的状态再次迭代形成。
应用:如何设计网络
拆分因素:将变体拆分成因素,降低训练所需数据量。
因素共享:使所拆分的因素在不同的样本之间形成共享,可以用等量的数据训练出更好的模型。
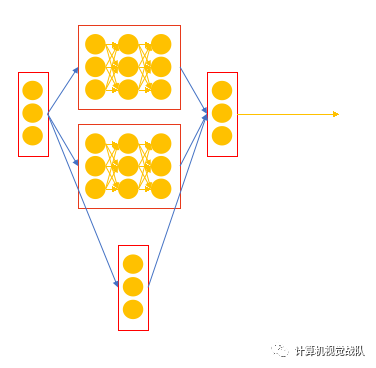
每一层表示事物的一种状态,设计神经网络时,要以“层”为单元。
误区1:深层学习并非万能,应用先验知识的前提是数据可以以先验知识的方式生成
误区2:深层学习没有固定形式,可以依据上两个要点设计出各式各样的网络。
神经网络变体
循环层:时间共享
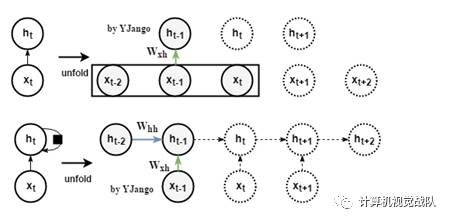
如果用前馈层,每个圆圈表示100个节点,那么前馈层处理时序相关性时就需要学习300个权重。
但如果知道不同权重在时间下是共享的,那么就只需要学习200个权重。
卷积层:空间共享

如果用前馈层,那么需要学习81个权重,但如果知道这些权重在空间下是共享的,那么可能只需要学习9个权重。原本一张图片在前馈层中只能用于学习一次权重,在卷基层中却可以学习很多次。
设计自己的神经网络
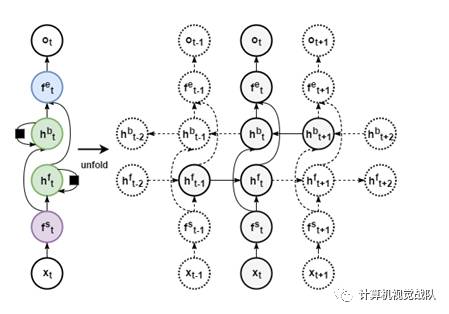
两个方向相加的 双向循环层一般比相并的效果好
神经网络其实并不黑箱,真正黑箱的是你的Task。
设计神经网络就是寻找在你手头的Task上利用因素拆分和因素共享的合理方式
可以先经过前馈层再经过双向循环层再经过前馈层最终得到你的结果。
例子
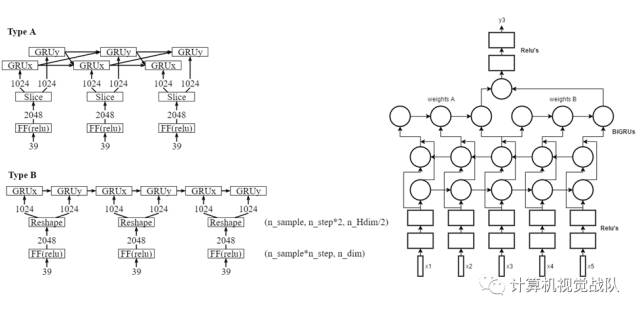
一些技术
多任务学习muti-task learning,利用的是因素共享,多个任务共享相同的知识,这样就会更容易确定我们真正想要的关联f,而排除掉那些只符合训练数据集,而不符合测试数据集的关联。
joint learning,end-to-end learning,是因素共享+因素拆分的联合应用。通过缩减人工预处理和后续处理,尽可能使模型从原始输入到最终输出,给模型更多可以根据数据自动调节的空间,增加模型的整体契合度。
人工智能对我们的影响

若有兴趣,请去“计算机视觉战队”公众平台慢慢去欣赏


(向左滑动,有惊喜)
如果想加入我们“计算机视觉战队”,请扫二维码加入学习群,我们一起学习进步,探索领域中更深奥更有趣的知识!