微软开源深度学习优化库 DeepSpeed 连登 GitHub 趋势榜!

【编者按】近期,深度学习社区发生了一件大事:微软研究院发布了图灵自然语言生成模型T-NLG,据称这是史上最大的自然语言处理模型。T-NLG拥有170亿个参数,性能远胜于其他大型深度学习语言模型,例如BERT和GPT-2。很难想象训练如此大规模的模型需要多少计算量。微软在宣布这一消息的同时,还开源了训练T-NLG背后的技术:DeepSpeed,该库中包括新型并行优化器ZeRO。
而从本周四开始,DeepSpeed就登上了GitHub Trending榜,至今仍保持在Top 5的位置,目前已获得1500多star,并有不断上涨的趋势。

作者 | Jesus Rodriguez
译者 | 弯月
整理 &责编 | 夕颜
出品 | CSDN(CSDNnews)
通过提高规模、速度、可用性并降低成本,DeepSpeed可以在当前一代的GPU集群上训练具有超过1000亿个参数的深度学习模型,极大促进大型模型的训练。同时,与最新技术相比,其系统性能可以提高5倍以上。
根据微软的介绍,DeepSpeed库中有一个名为 ZeRO (零冗余优化器,Zero Redundancy Optimizer)的组件,这是一种新的并行优化器,它可以大大减少模型和数据并行所需的资源,同时可以大量增加可训练的参数数量。研究人员利用这些突破创建了截至目前最大的公开语言模型——图灵自然语言生成模型(Turing-NLG),它的参数可达170亿,CSDN早前也对此有过详细报道。
T-NLG背后的技术DeepSpeed究竟是怎样一个深度学习库?这个库中包含的新型并行优化器ZeRO又有何特别指出?为何一经推出便广受关注?我们通过这个项目的细节来深入了解一下。
首先放出DeepSpeed GitHub开源地址:https://github.com/microsoft/DeepSpeed
以下为译文:

T-NLG:史上最大规模语言模型
在自然语言模型方面,肯定是模型越大越好。T-NLG(Turing Natural Language Generation)是基于Transformer的生成式语言模型,因此它可以生成单词完成开放式的文本任务。除了能够补齐未完成的句子外,它还可以针对问题直接生成答案,也可以给出输入文档的摘要。在自然语言任务中,模型越大,预训练数据的多样化和全面性越好,在一般化至多种下游任务时的表现也会更好,即使下游任务的训练实例较少的情况下亦是如此。构建大型的多任务模型语言要比为某个语言任务训练新模型更容易。
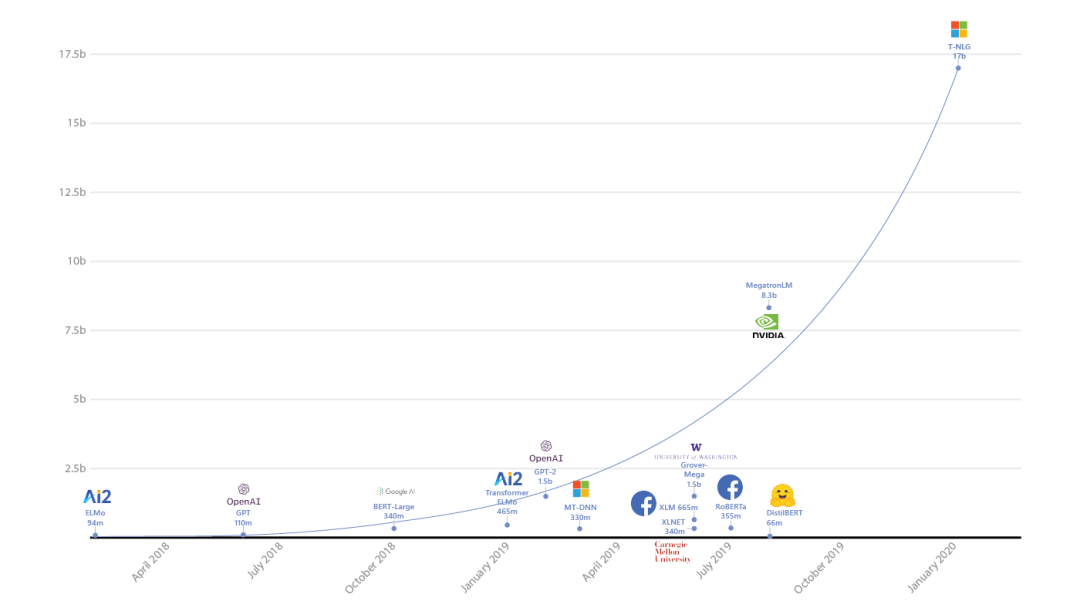
T-NLG到底有多大?除了170亿个参数外,T-NLG模型还有78个Transformer层,包括4256个隐藏层以及 28 个注意力头。该架构代表了大型自然语言模型的一次巨大的飞跃,如下图所示:
T-NLG的强大不仅在于规模和性能,而且其训练过程也让人叹为观止。虽然利用如今的技术构建大型的NPL模型也没问题,但是训练如此大规模的模型所耗费的巨额成本会让大多数组织望而却步。扩展训练的过程基于两个基本的并行化:数据并行和模型并行。数据并行的重点是在单个节点/设备上扩展训练,而模型并行则寻求将训练分布到多个节点上。然而,这两种技术都面临各自的难题:
数据并行无法减少每个设备的内存占用量:对于拥有超过10亿个参数的模型来说,即使是拥有32GB内存的GPU也会面临内存告急的问题。
由于训练需要细粒度的计算和昂贵的通信,模型并行很难扩展到单个节点之外。模型并行框架常常需要根据实际的模型架构修改大量代码。
为了克服这些难题,微软研究院开发出了自己的优化器,并实现了大型深度学习模型训练的并行化。

ZeRO:兼顾数据并行和模型并行优点,克服局限性
ZeRO(Zero Redundacy Optimizer,零冗余优化器)是一个优化模块,可以最大化内存和扩展效率。在发布T-NLG的同时,微软还发布了一篇研究论文,其中概述了ZeRO背后的细节。从概念上看,这个优化器旨在兼顾数据并行和模型并行优点的同时,努力克服二者的局限性。ZeRO使用一种名叫“ZeRO支持的数据并行”方法,将OGP模型的状态分区(而不是复制)到多个数据并行进程上,消除了数据并行进程之间的内存冗余;并在训练的过程中使用动态通信计划,保证了数据并行的计算粒度和通信量,从而保证了计算/通信的效率。随着数据并行度的增加,这种方法可以线性地减少模型中每个设备占用的内存,同时还可以保持通信量接近正常的数据并行下的通信量。此外,ZeRO支持的数据可以与传统的模型并行方法结合使用,以进一步优化性能。
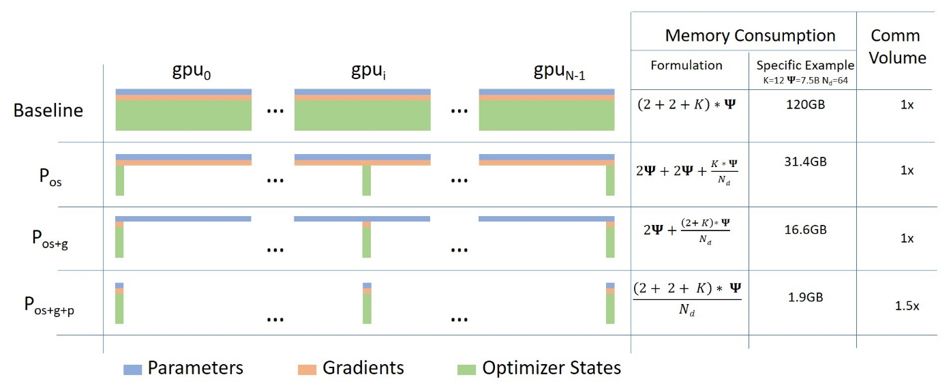
从算法的角度来看,ZeRO分三个主要阶段,分别对应于优化器状态的分区、梯度的分区和参数的分区。
1. 优化器状态的分区(Optimizer State Partitioning,Pos):在进行数据并行时,内存使用量减少4倍,通信量保持不变。
2. 增加梯度(Gradient)分区(Pos + g):在进行数据并行时,内存使用量减少8倍,通信量保持不变。
3. 增加参数(Parameter)分区(Pos + g + p):内存使用量减少与数据并行度(Nd)呈线性关系。例如,拆分到64个GPU上(Nd = 64)将减少64倍的内存。通信量会增加50%,尚可接受。
分布式训练的开源库中已经包含了ZeRO的第一个实现。

DeepSpeed:模型训练性能提高10倍
微软的DeepSpeed是一个新的开源框架,致力于优化大型深度学习模型的训练。当前版本包括ZeRO的第一个实现以及其他优化方法。从编程的角度来看,DeepSpeed建立在PyTorch之上,并提供了一个简单的API,工程师只需几行代码即可利用训练并行化的技术。DeepSpeed抽象了大规模训练的所有难点,例如并行化、混合精度、梯度累积和检查点等,因此开发人员只需专注于模型的构建。
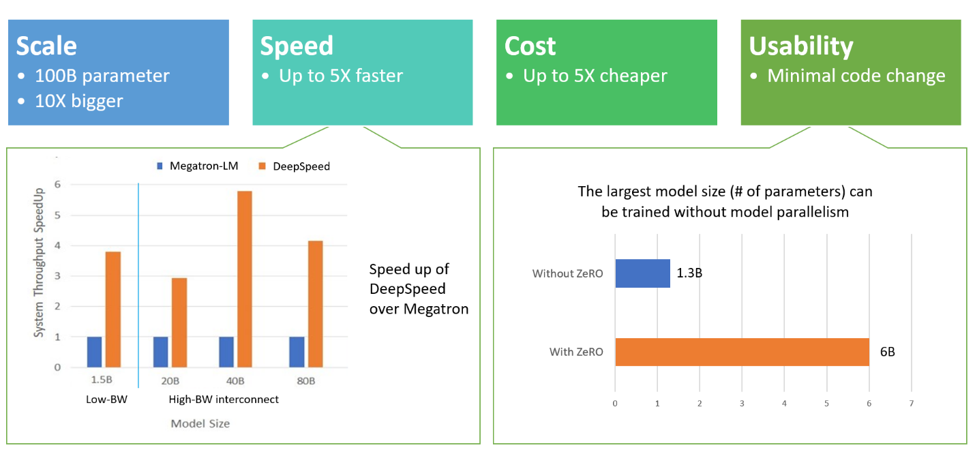
从功能的角度来看,DeepScale在以下四个方面都有出色的表现:
规模:DeepSpeed提供的系统支持可以运行多达1000亿个参数的模型,与其他训练优化框架相比,提升了10倍。
速度:在最初的测试中,DeepSpeed表现出的吞吐量是其他库的4-5倍。
成本:使用DeepSpeed训练模型的成本比其他方法低三倍。
易用性:DeepSpeed不需要重构PyTorch模型,仅需几行代码即可使用。
对于深度学习社区而言,Turing-NLG是一个重大的里程碑。微软通过开源DeepSpeed和ZeRO的第一个实现,降低了大型深度学习模型训练的门槛,而且还可以帮助我们实现更完整的对话应用程序。



