从易到难,针对复杂问题的无监督式问题分解方法

论文标题:
Unsupervised Question Decomposition for Question Answering
论文作者:
Ethan Perez (FAIR,NYU), Patrick Lewis (FAIR,UCL), Wen-tau Yih (FAIR), Kyunghyun Cho (FAIR,NYU), Douwe Kiela (FAIR)
论文链接:
https://arxiv.org/abs/2002.09758
代码链接:
https://github.com/facebookresearch/UnsupervisedDecomposition
问答(QA)任务常常包含了很多难以直接回答的复杂问题,而这些问题一般需要搜寻多段文本才能找出答案。
本文提出一种无监督的问题分解方法:把复杂问题分解成若干简单问题,然后把这些简单问题的答案作为上下文提供给复杂问题,从而帮助模型回答复杂问题。
使用这种策略,我们能够在多跳问答数据集HotPotQA上实现显著效果,尤其对于领域外的问题十分奏效。
问答中的复杂问题
针对问答系统的研究已经有了多年历史,在近些年,各类数据集的出现对问答系统的要求越来越高。
如数据集HotPotQA就要求系统能够在多段不连续的文本中寻找线索,并且按照逻辑顺序把这些线索组织起来形成答案。
这种需要多次答案“跳跃”的问答形式就称为“多跳问答”(Multi-Hop QA),或者简单地称为复杂问题。
模型直接回答这些问题往往不现实,但一个简单的想法是,可以把这个复杂问题分解成若干模型能够回答的简单的子问题,然后再把这些子问题及其答案作为上下文提供给模型,再去回答复杂问题,这样就可以大大降低直接回答复杂问题的难度。
比如下图是一个例子,要回答复杂问题,我们先从中拆分出两个简单问题(或“单跳问答”),回答之后再回答复杂问题本身,就容易得多。
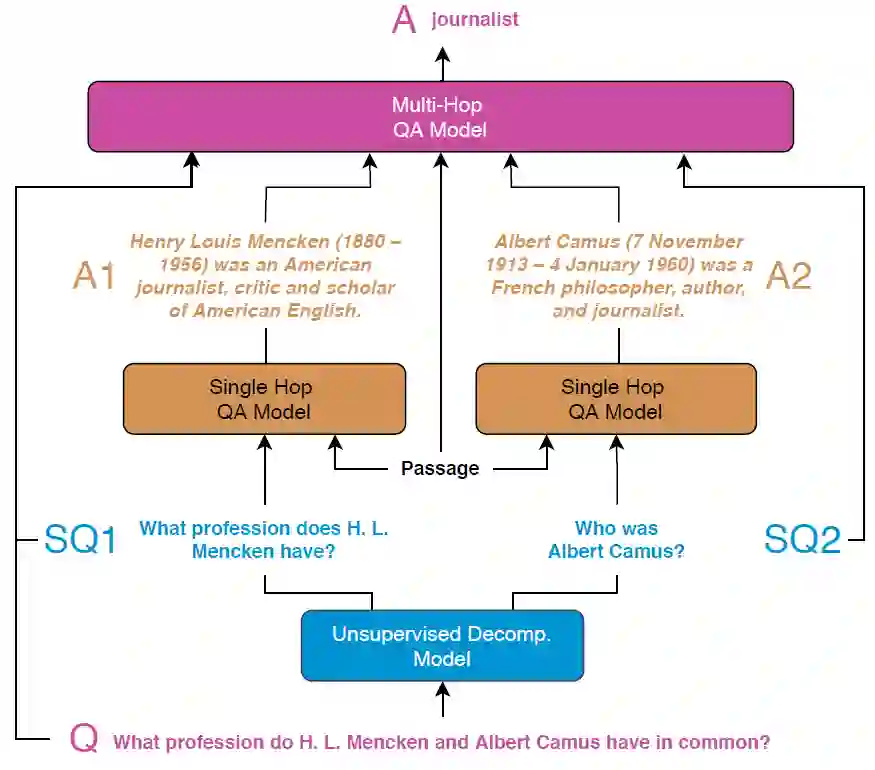
那么,现在的问题是,怎么得到简单的子问题。本文采用了一种无监督的问题分解方式:(1)首先以抽取的方式构建一个“伪分解”数据集,(2)利用构建的“伪分解”数据集和原来的复杂问题数据集训练一个序列到序列模型,(3)使用序列到序列模型生成子问题。以上问题分解步骤完全是无监督的,因而避免了大量的人工标注。
最后,本文在HotPotQA上测试了该方法的效果,并取得了显著效果。总的来说,本文贡献如下:
提出一种完全无监督的问题分解方法,可以有效地把复杂问题分解为若干简单的子问题;
在HotPotQA的实验上表明,这种方法已经非常接近强监督的方法;
本方法尤其能够在各种类型的复杂问题都取得很好的结果,表明此方法的通用性较强。
无监督问题分解
问答任务是,给定问题




而问题分解就是,找到和



所谓问题分解,指的就是复杂问题到子问题集的一个映射:

Step1: 伪分解构造
假设我们现在有两个数据集:复杂问题数据集

为了进一步扩大这两个数据集的大小,我们从Common Crawl中挖掘更多的问题补充
另一方面,因为我们没有标注好的


具体来说,我们对每个复杂问题

下面给出两种抽取子问题的策略(本文设
相似度抽取:使用余弦值改写上述公式为(其中
为单位句向量,用fastText得到)
;
随机抽取:随机中
中抽取
个简单问题作为
。

 ;
;
在抽取了若干子问题后,由于其中包含了很多噪声,所以我们还把其中没在
Step2: 问题分解映射学习
在上述得到伪分解对

不学习(No Learning),直接使用抽取得到的
作为复杂问题
的子问题;
序列到序列(Seq2Seq),把所有的
拼接起来作为目标文本
,学习一个
的序列到序列模型
;
无监督序列到序列(USeq2Seq),不直接从
中学习,而是用各种无监督学习手段去学习。




对Seq2Seq和USeq2Seq,我们首先在
对Seq2Seq,直接用






Step3: 如何使用
在学习了映射
具体地,我们使用RoBERTa(Large)和BERT(Base)作为简单问答模型,并且也使用了模型集成。类似地,对回答复杂问题我们也用同样的模型。
实验
我们在数据集HotPotQA上实验,测评指标有F1和EM,其他实验设置详见原文。
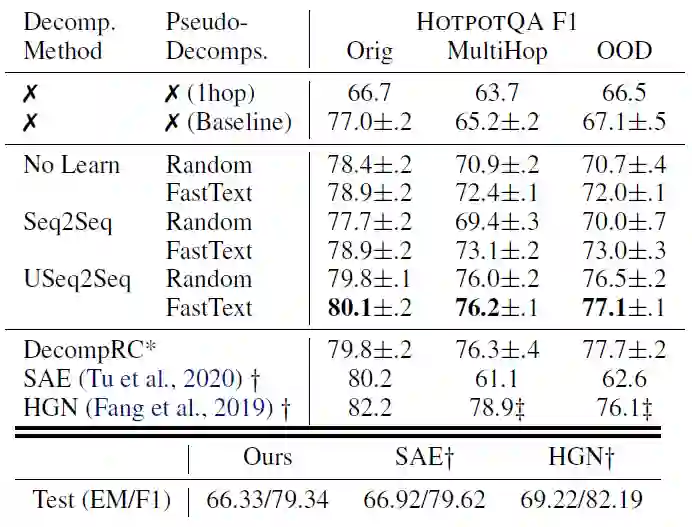
下表是实验结果,第一列是分解学习方法,第二列是分解构造方法。可以看到,和基线模型比较,在原始版本(Orig)上得到3F1的提升,在多跳(MultiHop)和领域外(OOD)版本上,得到10F1的提升,并且还能实现强监督模型DecompRC的效果。
在测试集上,本方法能接近当前最佳的强监督(额外的监督信号,知道哪些句子能回答问题)模型SAE和HGN。在后面的实验中,我们使用Useq2seq+fastText的方法。
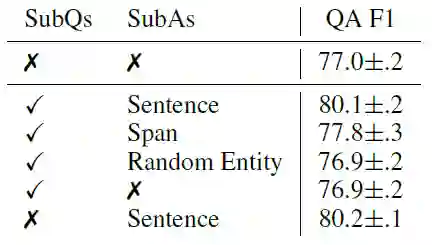
下面我们想要知道提供怎样的上下文信息可以使模型更好。我们有几种选择:(1)简单的答案段(span);(2)答案所在的一整句话(sentence);(3)随机实体。
下表是实验结果,可以看到,相比提供子问题,子答案的选择更为关键。其中,提供一整句话而非仅仅是答案本身可以大幅提高效果,这说明,充足的额外的上下文对模型至关重要。
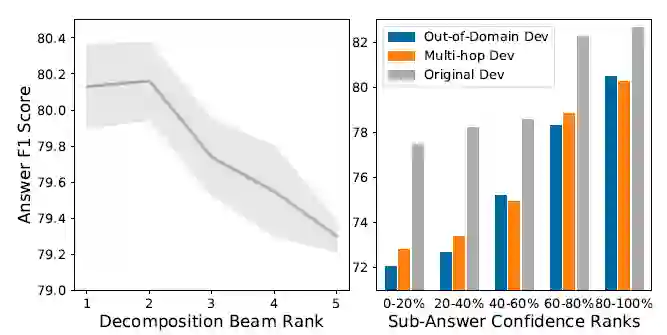
接下来我们探究子问题和子答案对最终结果的影响。如下图所示,左图是使用beam search生成的子问题的置信度对最终结果的影响,右图是子答案置信度对最终结果的影响。可以看到,置信度越大的子问题或子答案能最大化提升最终的结果。
最后来看看具体分解的子问题及其得到的答案的例子,如下表所示。可以看到,尽管有些子问题语法不通,但这并不妨碍简单模型找到相关答案,并为复杂模型提供有效的信息。

小结
本文提出了一种无监督式的“问题分解-分解学习-分解应用”的将复杂问题分解为简单问题从而提供丰富上下文信息的问答范式,在HotPotQA上能够接近当前最佳的强监督模型,并通过一系列分析实验验证了此方法的有效性。
这种方法的本质是为模型提供更多的上下文信息,非常类似我们推出的一系列工作——将各种任务归纳到阅读理解框架下。
实际上这种想法也是很直观的:人类也无法只从一句话中推出很多信息,总是需要各种各样的背景信息作为支撑。从这个观点看,未来拓展模型能够处理的文本长度也许会是一种趋势。
🔍
现在,在「知乎」也能找到我们了
进入知乎首页搜索「PaperWeekly」
点击「关注」订阅我们的专栏吧
关于PaperWeekly
PaperWeekly 是一个推荐、解读、讨论、报道人工智能前沿论文成果的学术平台。如果你研究或从事 AI 领域,欢迎在公众号后台点击「交流群」,小助手将把你带入 PaperWeekly 的交流群里。





