我们可以从Alexa语音助手的错误中学到什么:用户对话界面的设计性挑战

大数据文摘作品
编译:杨捷、Bill、Aileen
交谈是人与人之间互动的关键,追根溯源它可以是远古穴居人篝火旁的围坐,或者政坛上冗长的辩论,又甚至于你与牙医之间尴尬的小对话。我们常常可以通过交流很快速地判断出对方是否有兴趣、我们是否愿意与之约会或形成雇佣关系。如果我们希望完成某件事,那就交谈吧,这是我们传递信息并且与他人交流的途径。
所以这表明我们也将在交谈中实现与服务和商品的互动,不是吗?
确实如此。但事实证明创建智能的对话对象仍具有一定的挑战性,特别是当它能获取你的财政状况或向老板发送信息的时候。这些长期以来在人与人的交谈中已被解决的问题对于对话界面仍然是个挑战。
对话是我们都熟知的交互界面,因此,站在服务的角度理解,对于交互界面设计师来说,想要用户为了与一项服务互动而必须重新学习对话是不合理的。不论用户选择用何种自然的方式与系统对话,服务方都必须试图去理解。
以下是亚马逊Alexa语音助手的最近大热而引起人们注意的一些有关交互界面的挑战:
认证鉴定
“谁正在讲话?”

在一个当地新闻节目中,新闻主播模仿了一个偶然通过与Alexa语音助手对话买到了玩偶的小女孩。捕获到的声音信号被Alexa处理为一则命令,随即许多观众也通过Alexa接口尝试订购了一个玩偶。
认证在交易和交流服务中都是至关重要的:我们期待合理的保障措施,尤其面对需要支付和登陆的时候。当处理资金与个人信息时,我们需要更谨慎。对话界面在此有了一个新的挑战,比如偶然的噪声干扰。这样的意外绝不可能发生在物理触屏上。
在人与人的交流中,我们有很多我们甚至不会意识到的形式的认证方式:
面对面:我们通过长相得知我们在与谁交谈,毕竟我们知道朋友的长相。
声音:我们通过声音辨认交谈的对象,包括语气、词汇等。有时有人错误地接起了电话,你立刻就能觉察。
位置/直觉:我们对一个新环境中可能遇到某人的概率做了逻辑性的假设。正在外地度假时你突然发现一个人看起来好熟悉?好吧,应该不可能……
但是对话机器人是如何核实客户身份的?
一个折衷的办法是利用传统的验证方法,比如密码验证,虽然显得有些拙劣但是效果很好。然而理想的办法是收集足够多有关客户声音和外貌(取决于介质)的信息,使得对话界面可以不再依赖这种看起来比较笨拙的输入方式,它就好像你的朋友,必须确认你真的是你,才肯借钱给你。
语境
“你在说什么?”
语境同样与上则买娃娃的新闻故事息息相关,如果Alexa已经辨认出其正处于电视节目的环境中(主持人假装想要娃娃的小女孩时使用的是过去时态),那么Alexa就不会采取行动。
这是我们在人际交往中认为理所应当的事情,比如对方可以记住我们在哪里、正在做什么包括我们刚刚谈到的所有一切。毕竟,你可能不会花太多的时间与一个不记得你最近给他说过什么的朋友交往。
从Alexa的故事中我们明白,对于情境的理解需要深入,从什么时候该保持安静到得知某一问题可能会涉及到曾经发生的事情(就像在正常对话中一样)或者用户所说的同音异义语表达的究竟是什么意思——比如你正在感受饥饿(hungry)或者你正要前往匈牙利(Hungary)。
真正的挑战在于这几乎是一个零和游戏,要么提供丰富的语境信息来定义对话代理的行为,要么干脆几乎什么都不提供,因为但凡一个微小的不准确都会使的机器变得不可靠(错误的理解)或者反应迟钝(根据它的理解做出了错误的回应)。当然,随着类似于Alexa的这些平台学习能力的增强,他们变得越来越聪明有用。
用户意识
“我正在和谁讲话?”
在这个视频中一个小孩要求亚马逊Alexa为他播放他最喜爱的歌,然而Alexa误解了他的意思并且做出了完全不同的回应
对话界面更有可能在人与人之间共享,就像Alexa被设计为一种家庭内部的存在(亦或一个家庭数字成员),所以它需要理解并且适应不同的用户。它需要明白用户的喜好,年龄,和如何给予他们反馈。如果用户是一个孩子,它们则应提供一种适合孩子的反应方式。
就像通常人们根据聊天的对象和关系程度来调整对话的内容,会话代理同样需要根据听众来调整他们的语调和语言。这也可以归结于语境,如果用户确实很匆忙,那么语音服务也要调整成快速准确的语调。所以语音助手需要了解它的听众。
智力水平
Alexa:“对不起,您可以重复一遍吗?”用户:“算了……”

一个充满抱怨的爸爸正在努力使用亚马逊“Trevor” 啊不,是Alexa
我们每天都在进行着对话,与其他交流方式不同的是,人们在交谈时往往有明确的期待。主要表现为对被理解的期待和以及因为需要不断重复表达或者不断被误解而产生的失望。
对话界面令人兴奋并且感到新奇的原因是它可以完全达到免提和隐形的效果。然而这意味着它必须顺利地工作,因为它未设置连击缓冲键或其它选项供用户选择。
与图形用户界面所达到的即时性和反馈不同,对话界面需要时间接受所有的语音信号并且知道在作出回复之前输入语音已经结束,然后用户须收听整个回应来判断界面回应的准确性。
需要强调的是,触摸屏的输入是实时的,包括用户触摸到了那里和怎样触摸:
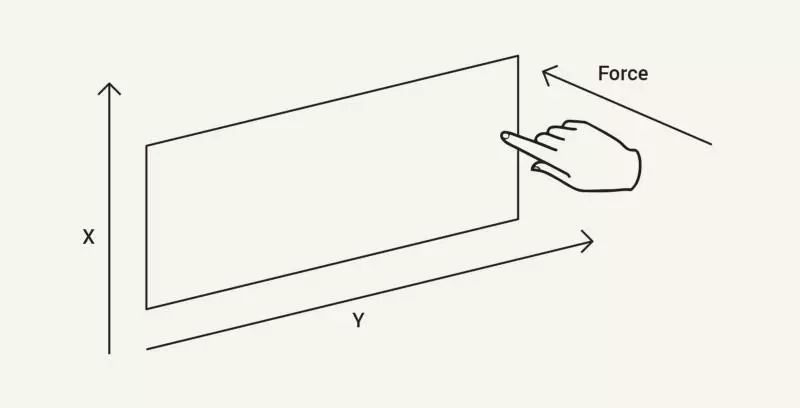
触摸屏界面通过获取触摸位置和触摸类型(例如按压力度、长度)来工作,这种类型的输入非常迅速
但是语音界面主要输入的是随着时间变化的声波,如下所示:
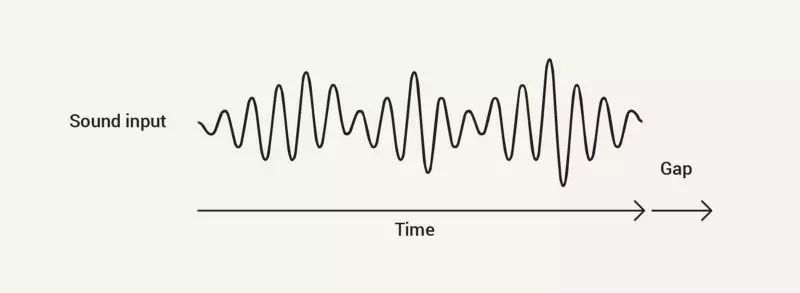
对话界面需要时间听到完整的输入并且确认输入完成
这些额外需花的时间应该被作为一个考量因素列入到专门为对话服务的新型交互方式的设计中,仅仅将现有的交互方式适配到新型的平台中是不够的。
接下来,我们应该向哪里努力?
我们需要学习如何创建自然对话方式,替代现有的图形界面。对话本身是没有改变的,我们必须向人类已创造的人际交流直觉机制致敬,毕竟我们无需要求他们重新学习这项技能。
我们该如何做呢?
使其更简单,容易上手: 通过智能地使用数据(包括语境、用户行为和用户属性)将所有的事物都拟人化,给用户提供一种和谐并感到舒适的沟通对象。此外,人们总是在思考的半途中就改变了主意或者不总是能清楚地表达自己的想法,所以对话界面需要能够从这些噪音信号中,尽可能对本意做出最佳的猜测。
使其更令人信赖: 为了使用户信任地将他们的财产或信誉交给看不见的隐形私人助手,用户需要清楚私人助手采取的行动和背后的原因。同时,当私人助手无法满足用户要求时,应该清楚地向用户传达系统的限制,透明化有助于用户避免碰壁或有其他不好的经历。
最后,很重要的一点是:会话只是提供了另一种交互的方法,但是不能完全地取代视觉或者其他交流方式。一幅图胜过千言万语,文字并不一定是实现目标最有效的方法,我们需要考虑并且欣然接受这个事实。一个理想的交互世界可能看起来更加变化多端:能无缝对接各种最合适类型的交互界面来达成给定的任务。
原文链接:
https://uxdesign.cc/what-we-can-learn-from-alexas-mistakes-a4670a9e6c3e#.rz8y92jbk
【今日机器学习概念】
Have a Great Definition

志愿者介绍
回复“志愿者”加入我们








