Redis 主从复制演进历程与百度实践

你好,我叫王源,来自百度数据库技术部,主要负责百度智能云 Redis 内核研发和磁盘 KV 存储服务 PegaDB 的研发工作,今天我与你分享的主题是 Redis 主从复制演进历程与百度实践。
我会从以下几个方面为你讲解:
Redis 主从复制的基本原理
Redis 主从复制的演进历程
百度智能云在 Redis PSYNC-AOF 方案
Redis 主从复制的展望
在讲解 Redis 主从复制之前,我们宏观看一下主从复制。它是通过网络连接的多台机器上保留相同的数据副本,从而实现高可用和冗余备份。这里需要注意的几个地方,首先是通过网络连接的多台机器,我们在分布式领域要实现高可用跨机的这种复制是必备的,这样才能实现高可用;再一个就是相同的数据副本,只有数据相同了,我们的备份和高可用才是有意义的。
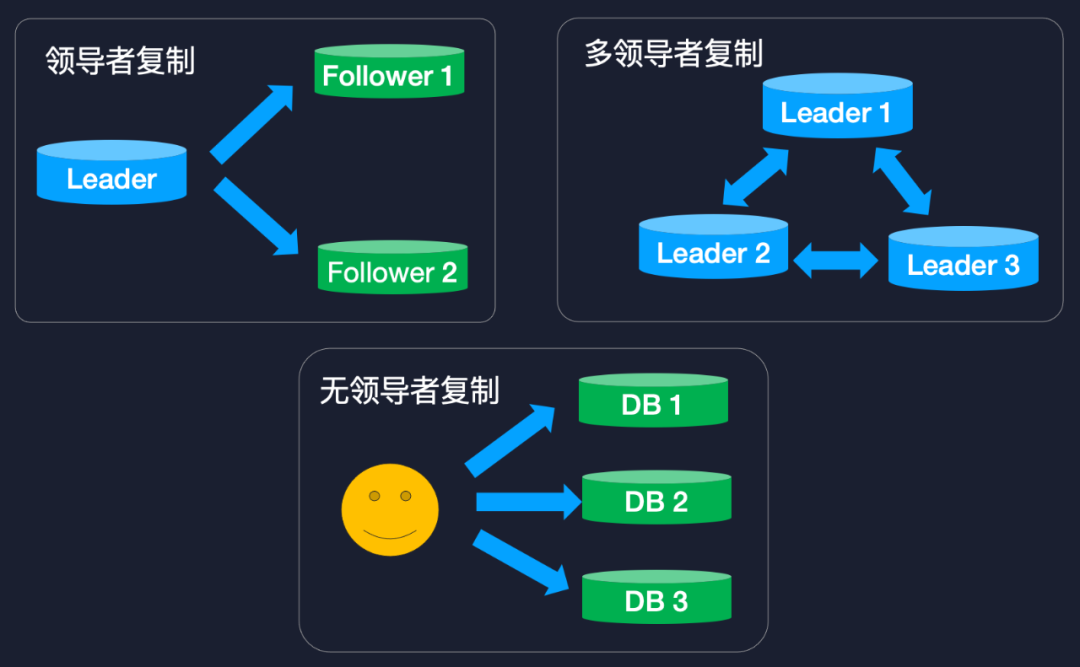
我们看一下主从复制的一些常用方式。第一个是基于领导者的复制,如上图所示,Leader 会将自己的数据变更发送给他的追随者,这种基于领导者的复制也分为同步复制和异步复制,像 Redis 其实就是异步复制的,它将用户写入的数据逐步异步地写给这些追随者,而像 MySQL 提供的是半同步机制,比如说只有当 Leader 将自己的数据同步到执行的从库之后,用户才能使用成功。再一个就是多领导者复制,每个 Leader 的数据可以相互地循环复制,这常见于我们异地多活中有多个 Region 的主库相互将数据进行传播。
还有一种方式是基于无领导者的复制,就是数据节点之间不会进行同步,而是由用户来写入的,用户的写入一般会基于 Quorum 的原则,比如说用户会写入超过一半的节点,读取的时候也会读超过一半的节点。
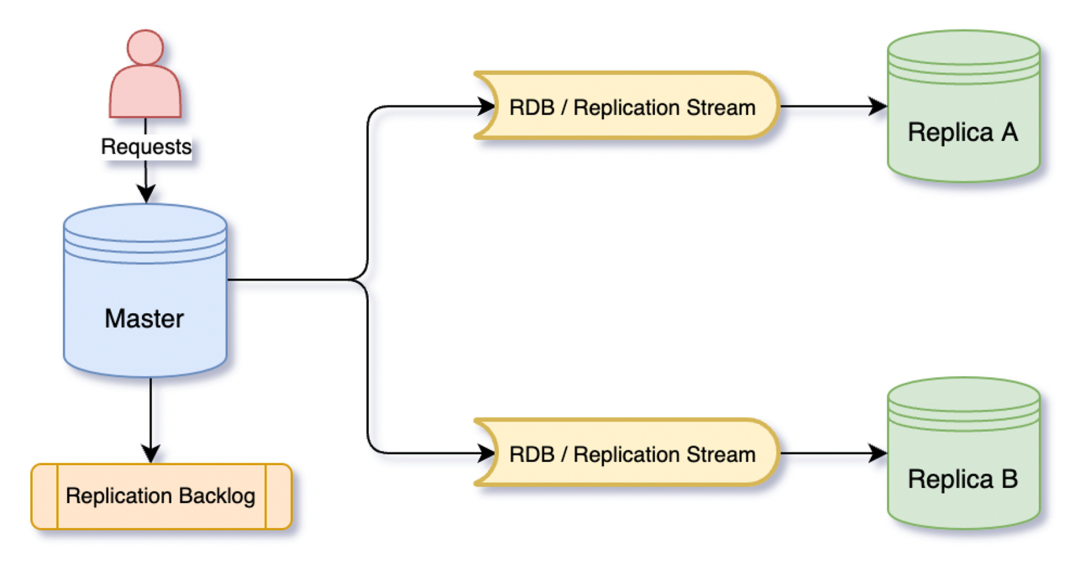
下面我们来看一下 Redis 主从复制的原理。Redis 主从复制主要分为两部分:第一部分是全量同步,它实现数据的基准校验;第二部分是命令传播,在基准数据之后进行命令的传播。我们看一下全量同步的步骤,它主要是分为产生快照、传输快照以及从库的加载快照,而命令传播也是当客户端写入数据之后,它会将写入的数据形成复制流发给从库,同时它也会保存到自己的一个 ReplicationBacklog 的一个缓冲区中。
我们下面重点来讲解一下 Redis 主从复制的演进历程。
首先我们看一下 Redis 在 2.8 之前的 SYNC 方案,Redis 从第一个 commit 开始就有复制,到 2.8 之前,它的复制方案基本上没有变化,都是 SYNC 的。SYNC 其实就是一个全量同步,我们看一下它的流程。
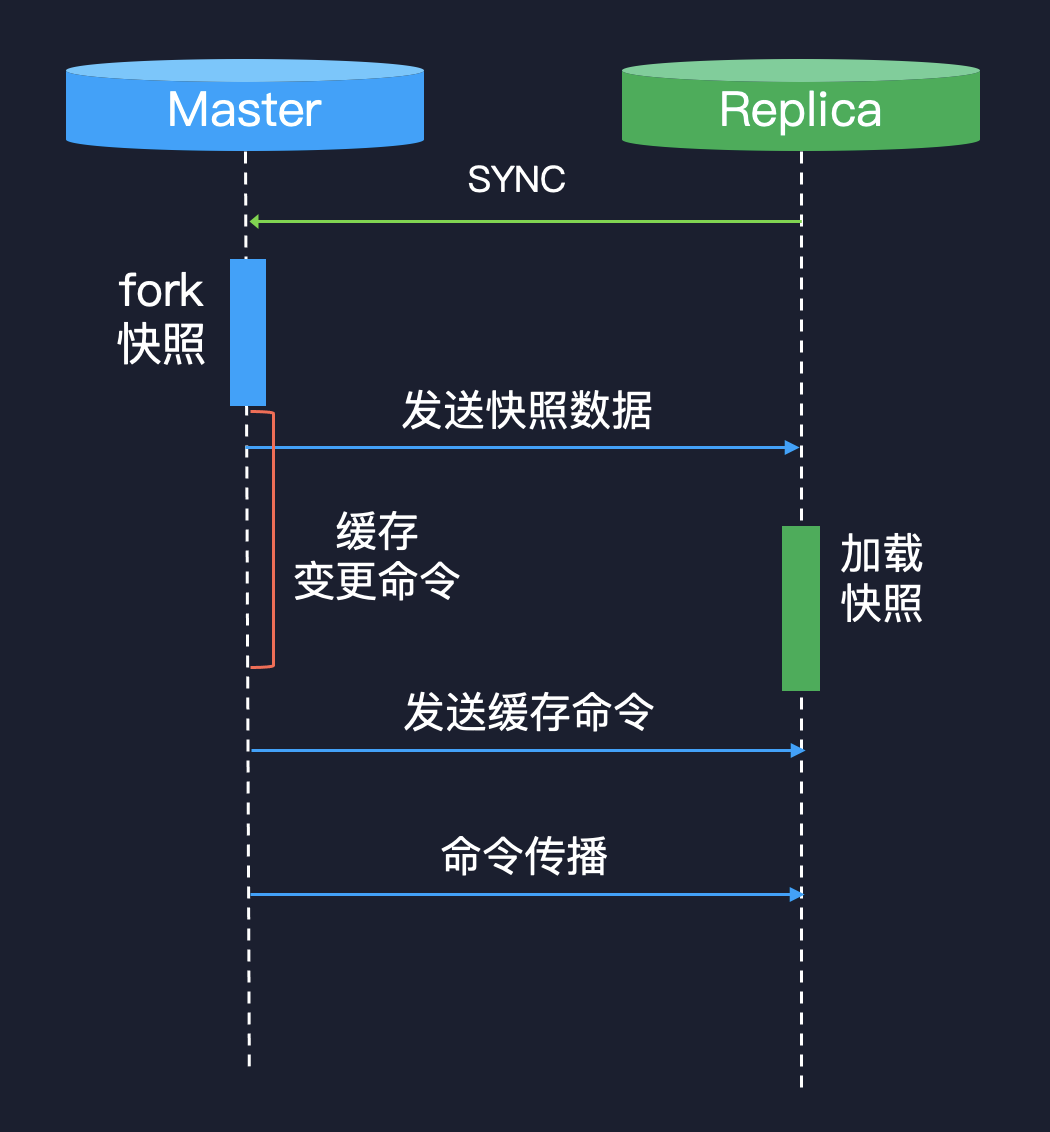
从库发送一个 SYNC 请求给主库,主库就会 fork 一个进程,产生数据快照,当这个数据快照产生完成之后发送给从库,注意这里是数据快照,产生完之后再发给从库,从库也是接收完这个快照之后再加载快照。因为在这个期间主库肯定又会积累很多命令,所以它会将缓存的命令再次发送给从库,之后就进入了一个命令的传播阶段。
这里我们可以发现这个方案的缺点,第一个是 fork 产生快照,fork 的这个系统调用在进程的内存非常大的时候,是非常慢的,因为它要有大量的列表拷贝,可能是毫秒、百毫秒级别。再一个 是 fork 之后,如果主库仍然有数据写入,那就会有大量的 copy on write,消耗很多的内存。另外一个是在从库上,从库加载 RDB 是不能对外访问的,这样缺少了一些访问的能力。这也是方案的一个最基础却没有解决的问题,也是最迫切需要解决的问题。从库和主库断开连接之后,从库就要进行一次全量同步,这是非常伤的。我们其实非常想解决这个问题,也就是从库如何断开连接之后再跟主库进行一个部分同步,所以 2.8 就是来解决这个问题。
它提出了一个 PSYNC 方案,有部分重同步,当从库跟主库再次进行连接的时候,它们不需要进行全量同步,而只需要同步部分数据就可以了。我们想一下这个方案如何去支持,从库上肯定要记录一些信息,然后它下次再连主库的时候,告诉它复制到哪儿。主库上也肯定要缓存一部分命令,然后当主库的数据在自己缓冲区里,就可以发送给从库了。
2.8 的 PSYNC 的方案,它首先提出了几个新的概念:一个是 Runid,在实际运行的时候,它有一个唯一的 ID。再一个是复制 offset,刚刚我们提到的从库在写入数据之后,它的 offset 会增加,主库也是同样的,在写入数据的时候 offset 也会增加;还有在主库上记录了一个环形的数据积压区 replication_backlog。
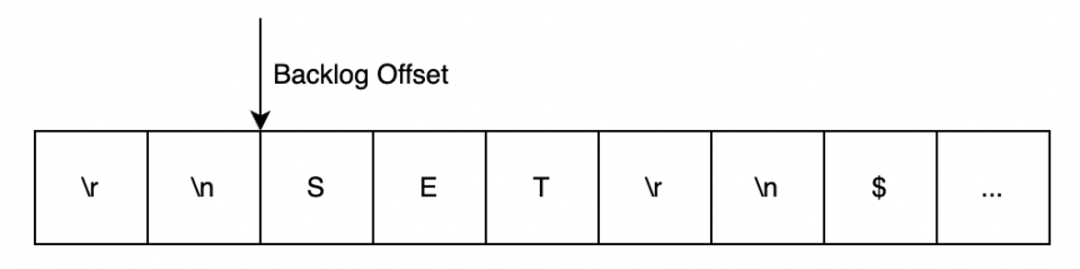
如图所示它有一个积压区,并且它积压区中记录了复制的一个起点,一个 backlog 的 offset,因为它是一个环形的,我们肯定要知道起点。再一个我们在从库上记录了它缓存的主库信息,当从库断开与主库的连接之后要记录信息,再次跟主库连接的时候,它会把信息发送给主库,主库校验,我们来看看它整体的流程是怎样的。
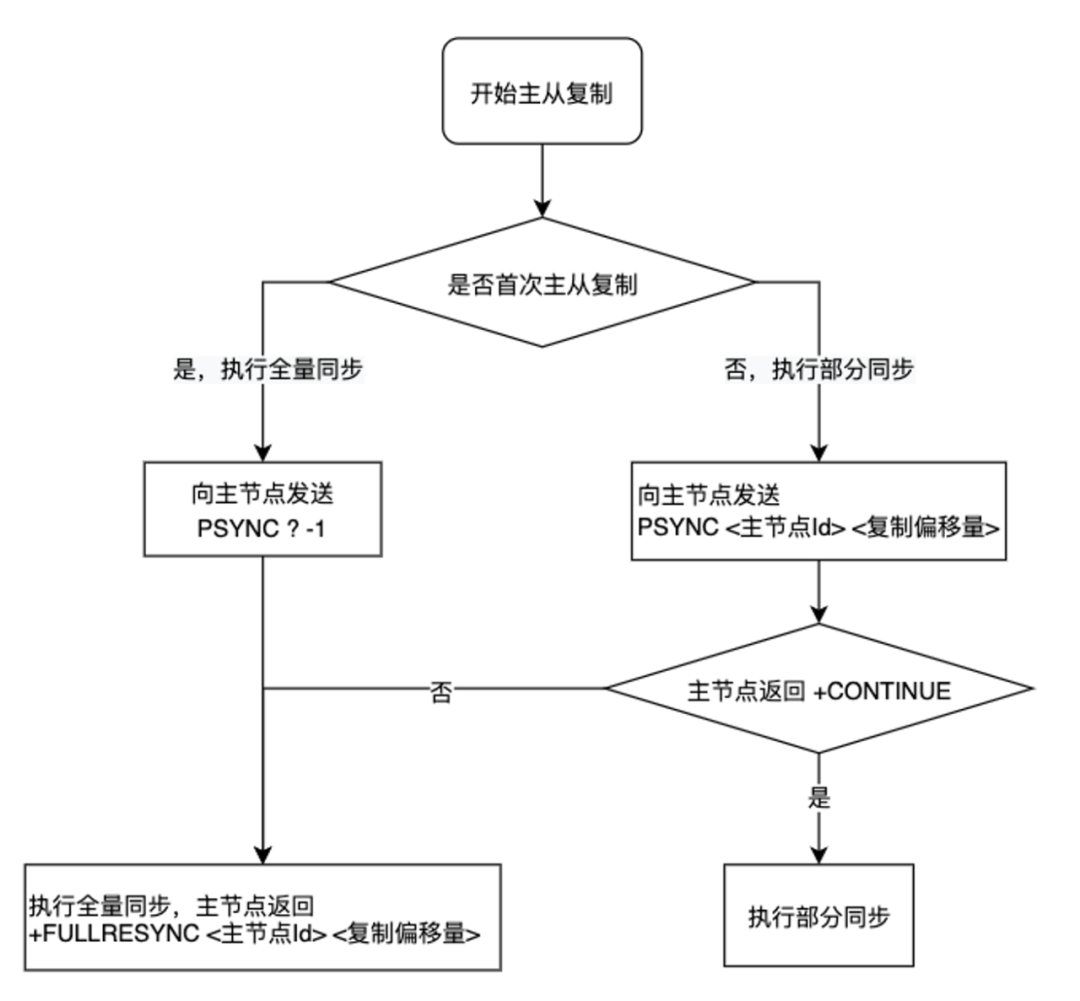
看一下这张流程图,首先从库也会尝试跟主库建立同步,它会判断自己是不是第一次跟主库进行同步,如果是的话肯定没有这种 Cached Master 记录的信息。PSYNC 发送的时候,也就带上一个问号和 -1,这会儿主库必然跟它进行全量同步;如果它有一个 Cached Master,假使之前跟主库复制过了,它会发送什么呢?它会发送之前主库的 Runid 和一个它复制的 offset,主库拿到 Runid 跟自己的 Runid 比较,如果是一样的,并且这个 offset 在自己的 backlog 中能够找到,那就可以进行部分重同步,主库就可以把这些 backlog 的内容发送给从库,从而实现部分重同步。这是 2.8 最重要的一个优化,它解决了闪断导致的全量同步问题,现在只需要一个轻量的增量同步即可。
我们看看这个方案就完善了吗?其实它还是有很多缺点的。首先是从库在重启之后,它记录的主库的 runid、offset 都丢失了,它肯定需要进行全量同步;再一个主库如果发生了故障,我们新选出来的主库,它的 runid 和 offset 都发生了变化,所有的从库都要跟主库进行全量同步,这是不是也非常伤,这在我们实际的运行过程中是不可以接受的,后面的方案其实就是着重去解决这些问题。作者之前也在 GitHub 上公开讨论过这个 idea,大家感兴趣的话可以去看看。
Idea issue:
https://github.com/redis/redis/issues/189
我们 4.0 就是解决刚刚提出的这种故障切换之后,新选出来的主库和之前的从库,仍然进行部分重同步,而不进行那么重量级的全量同步。
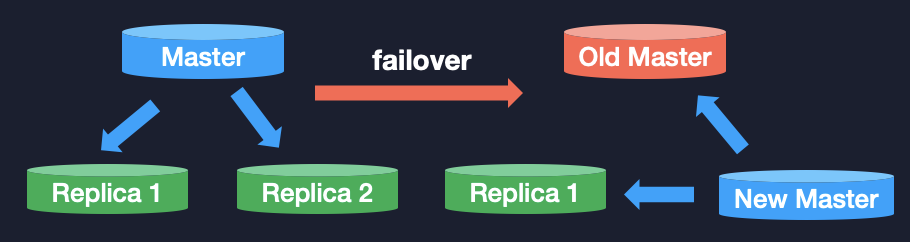
比如说现在有一主两从的一个分片,当主库挂掉了,我们将从库 2 选为主库,它是不是能够跟从库 1 进行一个部分同步?在 PSYNC 中,它是不可以的,因为主库和从库的数据都是不一样的,它的 runid 也都不一样,所以不能进行这种部分同步。
那么我们应该如何去实现呢?其实我们发现从库 1 和从库 2,它们之前是复制了同一份数据,其实它们的复制上下文是一样的,所以如果新的 Master —— New Master 也记录了自己的复制上下文,从库 1 是不是就可以跟 New Master 来进行增量同步?其实这也就是 4.0 的方案在 PSYNC2 中提出的几个概念。首先是一个 Replid,就是自己的复制 ID;Replid2 是自己上一次复制的主库的一个 Replid,同时它也记录了上一次复制的 offset,Replid2 和 Second_replid_offset 是一对儿,那有了这些信息,我们看一下它是如何实现的这种增量同步呢?
在 PSYNC1 中它又是只是校验,offset 是不是在 Backlog 里,它现在多了一个校验,其实主要是判断它的复制历史是否一样的。如果它的 Replid 是一致的,比如说之前的 Runid 是一样的,自然可以来进行部分重同步的尝试。如果没有,接下来也是 PSYNC 中最重要的一个改变,它就会看一下是否和自己上一次的 Replid 一样,也就是说与 Replid2 一样。如果一样的话,再看一下这个 offset 是不是在上一次的 second_replid_offset 中,如果在这之中,也可以进行增量同步。这里说一下为什么要看上一次的 Replid_offset,这也是大家非常容易出错的地方。
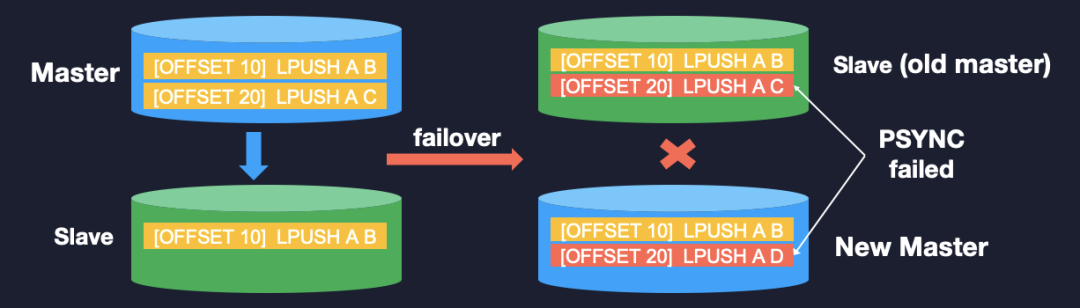
还是看一下这个例子:现在有一主一从,你在主库上写了两条数据,LPUSH A、C,但是由于同步的延迟,在从库上只有一条,就是 LPUSH A、B,当 failover 后从库成为新主,它肯定会接收新的业务请求,比如它写入了一条 LPUSH A、D,此时我们想让旧主跟新主建立主从复制,这样是可以进行增量同步的吗?
其实是不可以的。尽管它们的 offset 一样,但是它的 offset 和新主的 second_replid_offset 是不一样的,它的 second_replid_offset 的值是上一条的。我们为什么要这样判断,这里当从库切为主库之后,它的复制上下文已经变了,我们不能用新的复制上下文和老的去比较,只能用之前的复制上下文和老的去比较,这样才能实现对应。
我们这个方案它主要就解决了这种切主之后,新主库体需要跟从库进行全量同步的问题。由于 RDB 中也持久化了这种复制信息,其实它也解决了从库在重启之后需要跟主库全量同步的问题,因为从库在重启加载 RDB 后都有主库的这些信息,它可以跟主库进行一个部分重同步。但是这个方案仍然还是存在缺点的:多个从库的时候,这个 buffer 非常大。因为 Redis 中每个从库的 buffer 都是独立的,所以多从库的时候复制 buffer 就会非常大;再一个是 backlog 的容量是有限的,所以主从断开的时间容忍也是有限的,如果断开时间长还需要进行全量同步。这个设计方案 Redis 作者也公开地讨论了,大家可以点开链接看看。
设计:
https://gist.github.com/antirez/ae068f95c0d084891305
刚刚几个内存相关的问题我们先放一下,来看一下磁盘上的优化,Redis 做了很多磁盘上的优化,以至于在 6.0 的时候实现了一个完全无盘复制的方案,其实 Redis 从 4.0 的时候就开始做无盘的方案了。
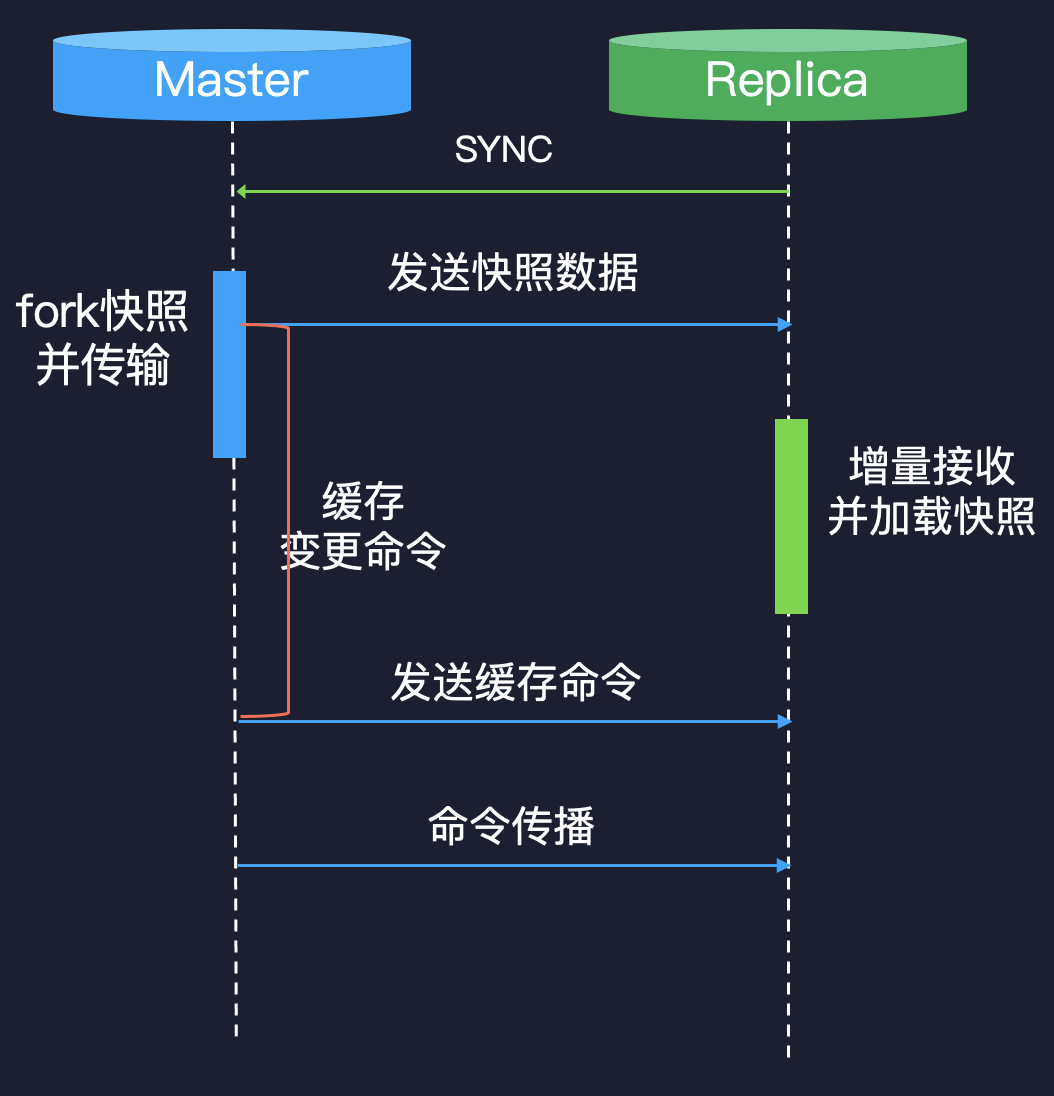
无盘复制其实这里我主要分为两部分:第一个是无盘的传输、第二是无盘的加载。无盘的传输是从 4.0 就开始做的,我们看一下这张图,主库在收到一个全量同步的请求时,它会产生快照并传输,这里它是怎么做的呢?在 6.0 之前它会 fork 一个进程,比如子进程一边 dump 数据,一边通过网络发送给从库,到 6.0 之后这个就变了,它也是 fork 一个子进程,子进程 dump 数据,但是它通过管道回写给主库,主库再将数据发送给从库,这样的过程就是无盘的传输。
再来看看加载的过程,加载其实在 6.0 也变成了一个无盘的加载。比如说光主库,它的数据不需要落盘,从库接收的这些数据也不需要落盘。在之前的方案中,从库需要完全地接收完数据之后才可以加载,在无盘的加载过程中则不需要这样。从库在跟主库间连接后,全量同步的时候,它也会创建一个 socket,就不再打开一个本地文件写,而是直接从 socket 中读取数据并加载,边读边加载,实现了对磁盘的解耦,避免了保存磁盘文件的时间。而且 Redis 为了解决这些数据翻倍的问题,从库如果仍然保留之前的数据再加载一份新的数据,内存肯定是翻倍的,所以它提出了一些方案,供大家去权衡选择。
第一个就是在加载的时候有一个 empty-db 的选项,比如说加载之前把之前的数据全部清掉再加载,从而减少了内存的消耗;再一个就是 swap 的选项,它是将之前的数据先保存到另外一份临时的 db 中,然后加载数据到新的 db,但这样就实现内存的翻倍,但是数据更可靠,因为即使当主库的数据挂掉之后从库仍然有自己的数据,而 empty 的方案,从库上就没有数据了,这是非常危险的。
7.0 的时候还做了一个优化,这个数据保存临时 db 的时候,它不是将原来的数据临时保存到一个 db 中,它是这个数据仍然对外访问,而将加载的数据临时放在一个 db 中,加载完成之后交换,所以它在加载的过程中也可以对外访问,这是非常漂亮的,也是 SWAPDB 的一个优点。缺点就是内存翻倍,刚刚我们也提到了 Redis 的主从复制,一个问题是内存的消耗极其严重,原因就是多个从库,复制 buffer 是独立的,也就是说有几个从库,它有几份复制 buffer。如果我们这里有 10 个从库,每 1 个从库占用 1GB 的复制 buffer,它就要占用 10GB 的内存,是非常可怕的。
详细描述:
https://mp.weixin.qq.com/s/UlHksrqFq0yfKh1uMFvYNg
另外这个 buffer 非常大,它的拷贝和释放都可能会存在阻塞的问题,这里可能会是百毫秒级,甚至秒级的阻塞。所以在 7.0 的时候,我们将百度智能云的一个共享复制缓冲区的方案提给了社区,社区也采纳了,并且成为了 7.0 中重要的一个功能。在今年的 RedisDay 上也提及了这个功能,我们看一下共享复制缓冲区的方案是怎样做的。
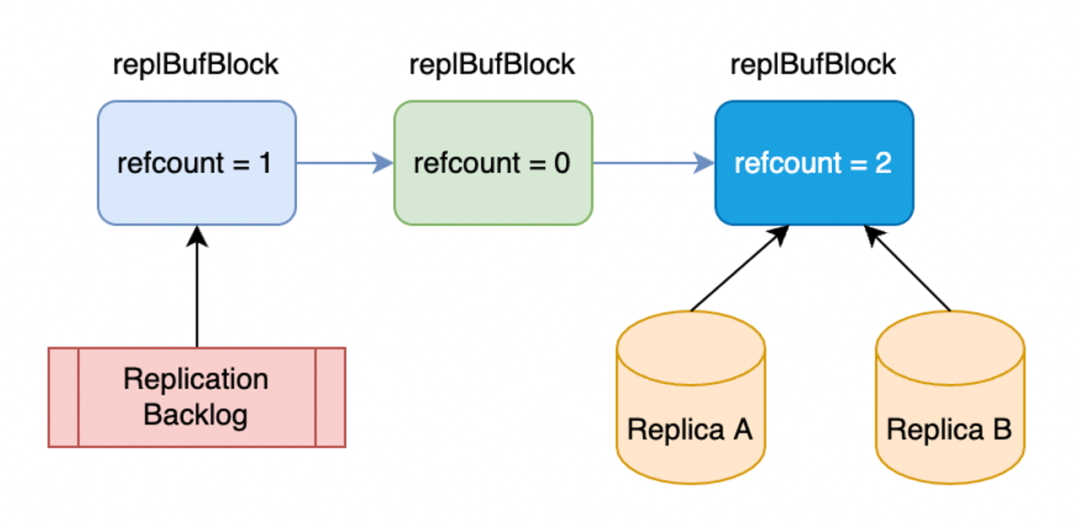
其实这个方案的思想非常朴素,就是所有的从库我共同访问一份 buffer 就行了。首先看一下这个 buffer 如何表示,其实我们是通过一个 buffer 的 block 链表来实现的,这个链表有多个数据块,数据块就是主从复制的数据,我们同时给数据块增加了一个特殊的字段叫 refcount,它会记录这个 refcount,也就是 block 的一个引用的个数,每当有从库对它引用的时候,它个数就会加一,当减少引用的时候它就减一。

Replication Buffer:replBufBlock 的链表
如图所示,Backlog 它引用了第一个 block,它的 count 就是 1,然后从库 A 和 B 它们都引用了第三个 block,它的 count 就是 2。这样我们就在一条链表上,不同的从库引用不同的节点,就实现了一个共享复制缓冲区的方案。
但是这个方案仍然有几个问题需要解决,我们知道部分重同步的时候,在 Backlog 中要找到对应的数据内容,现在 Backlog 只是引用复制缓冲区,那共享的复制缓冲区,我们如何实现查找呢?这个链表上的节点非常多,可能是几万个,甚至是几十万个,我们如何高效地查找呢?
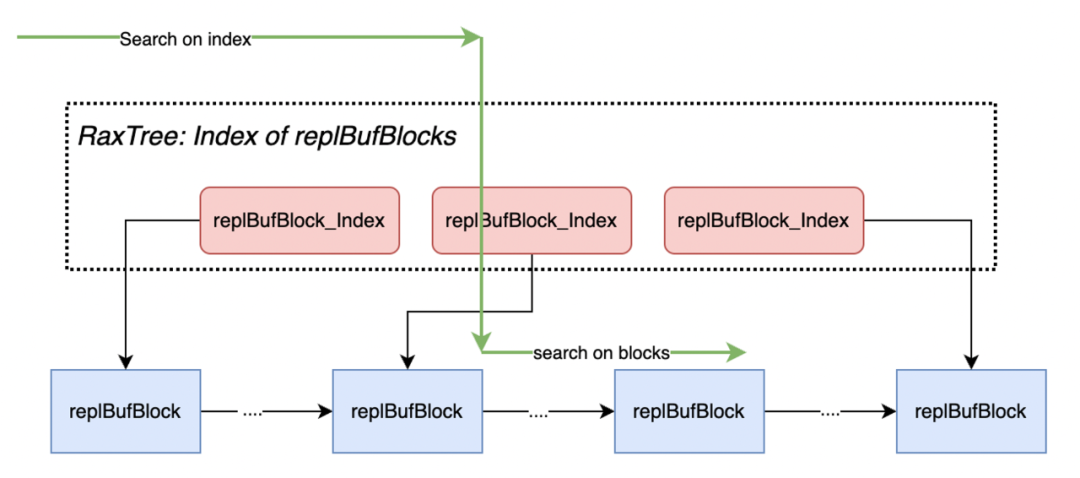
这里我们通过一个 Rax 数记录了这些 block,通过每 64 个间隔记录一个 Block,实现了它的一个固定区间的缩影。当我们查找的时候,先查 Rax 树,然后让它聚焦在一个范围内,就是 64 的这种格,然后我们再沿着这 64 个节点遍历一遍就可以找到对应的节点,整个查找的过程中也不会超过 100 次,时间也会在一毫秒之内,这样基本上就可以做到业务无感地去查找,这是我们复制 buffer 的方案,但是这个 buffer 我们不可能无限增长,我们如何裁剪它呢?
我们裁剪的一个朴素的 idea 就是 buffer block 的引用计数变为 0,就释放,我们从头来遍历;如果它是 0 就释放,如果它不是 0 我们就停止,其实现在的问题是如何减少引用计数让它引用计数减为 0,那什么情况减 1 呢?
当 block 读写完成了之后,我们访问下一个的时候,会将当前的 refcount 减 1,再一个如果从库断开了之后,在当前引用 block 的 refcount 也会减 1,因为它释放了,对它不引用了。再者就是 Backlog,它会有一个大小限制,如果超过大小限制,那么它就会前移,之前 Block 的引用计数也会减 1,通过这种不断地剪辑操作,前面的一些最开始的 block 的引用计数就会变为 0,我们就释放掉。
这个方案是我们可以很好地减少了这种主从复制内存的开销,我们也贡献给开源社区了,具体的 PR 是在这个链接上,大家也可以详细看一下具体的实现。
百度智能云 Redis 团队贡献的 PR:
https://github.com/redis/redis/pull/9166
我们上面主要讲解的是开源社区的主从复制的演进。然后再分享一下我们百度智能云的一个实践 —— PSYNC-AOF 的方案。我们现在看一下 Redis 主从复制遇到的问题,首先就是内存,Redis 一切都在内存中,Backlog 在内存中;Backlog 是有限的,它在 Backlog 里头找数据,因为它的容量有限,所以它肯定是找数据有限,所以它只能应对网络短时间的闪断,而不是长时间的断开。
还有就是 OutputBuffer,客户端缓存也是有限的,它超过之后从库也会断开;另外一个非常严重的问题,在业务流量高峰的时候,如果发生全量同步,这时候就会出现一个非常严重的问题,因为全量同步期间,数据会缓存到这个客户端的缓存中,洪峰流量会导致业务的 QPS 非常高,写入的数据也会非常大,客户端的 OutputBuffer 会超限断开,然后又会全量同步,这样就会循环失败,直到业务的流量过去之后,才逐渐地恢复同步。
这个问题非常严重,在当洪峰流量的时候,Redis 主从同步的承载能力是非常有限的,我们据此做了 PSYNC-AOF 的方案,其实这个方案的 idea 也是非常朴素的,它就是将 AOF 的内容和 Backlog 的内容保持一致,当在 Backlog 里找不到内容后,可以尝试从 AOF 里头找。我们的 AOF 不仅仅和 Backlog 中的一样,并且还记录了 AOF 对应的这种复制的 offset,因为这样我们才能去拿到从库请求,再去找这边的 AOF 文件。
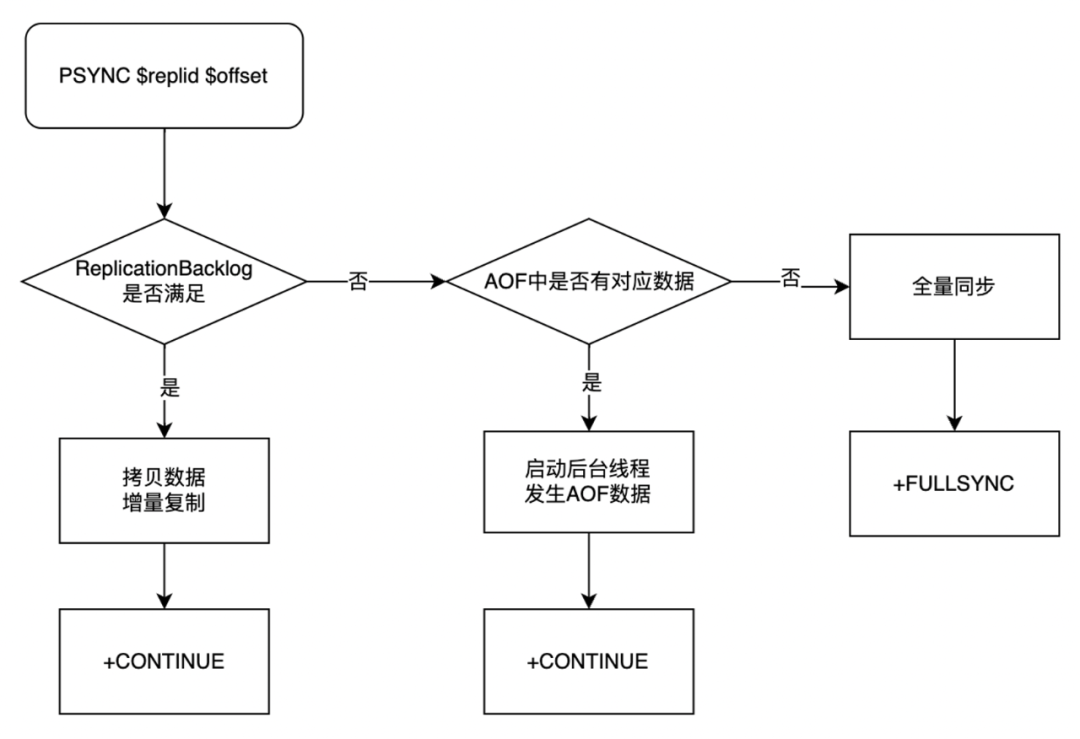
通过一个 RDB 作为基准,AOF 作为增量,而且还有多个这种 AOF 的文件,我们就可以实现一个更大的复制积压区,可以应对更长的网络延迟以及网络断开。再来看一下我们现在的主从复制的流程是怎样的,首先也从构建连接发送一个 PSYNC 请求,如果它请求的 offset 在 Backlog 中,就能找到它走之前的逻辑;如果找不到,按照之前的方案就会全量同步,但现在我们加了 AOF 的去尝试寻找的过程,它会基于 offset 到 AOF 文件去查找,AOF 文件找到之后,它又把 AOF 文件的内容发送给从库,然后把之后的 AOF 文件也发送给从库,从而实现了增量同步,避免全量同步。当然 AOF 文件大小也是有限制的,如果找不到,它最后也会进行全量同步,这是无法避免的。
再说一下我们 AOF 文件的发送,AOF 文件是通过子线程发送的,也就说发送 AOF 文件不会阻塞子线程的服务请求,它仍然是可以对外服务的,而且通过 send_file 来提升发送的效率,通过这样的方式避免了主库的阻塞。另外从库在接收这些 AOF 的时候,它也是对外可以服务的,只是它的数据相对主库差异的有点多,有些老数据而已,如果业务可以忍受这个方案就可以极大地避免了洪峰流量导致的问题。当然我们一直还有一个问题没有提到,就是 Redis fork 的问题,这个 fork 也非常严重,在存量同步的时候,我们也提出了一个 forkless 的方案,在本专题的另外一个 Topic 中,有相应的分享,大家可以去看一下。
最后我们来一起展望一下 Redis 主从复制还有哪些思路。
首先就是 PSYNC3,也就是 PSYNC-AOF,这个其实和百度智能云的基于 AOF 的复制是非常类似的,作者在很早之前也提出了这个 issue,和大家一起讨论过,但是并没有落地去实现它。我在一个 AOF 注释的 PR 的讨论中也提到了,我们如何进行注释可以更好地记录 AOF 对应的 offset,从而为基于 AOF 的复制提供一些基础能力。
再一个是 SYNC-less replication 的方案,就是无全量同步复制的方案,因为前面我们提到全量同步很伤,那么我们有没有一个方案,就是不需要全量同步直接进行增量同步而解决问题?对于 cache 的场景这似乎是可以忍耐的,我们没有基准,慢慢地增量同步一段时间之后,其实数据又一样了。作者之前也提出过这个方案,我这里也抛出一个 discussion 进行讨论,大家可以一起参与一下。
但这个方案最大的问题就是,对一些复杂的数据类型是极其不友好的,因为没有基准数据,从库上面的执行可能非常出意外,在主库上执行没问题,从库上可能就执行失败。从库可能需要大量地应对这些问题,可能有些业务能接受,有些业务是不可以接受的,所以大家也是可以根据自己的需要,看看是否采纳。
最后一个是 Redis Core Team 成员 Oran 提出的一个解决方案 —— 多路复用的传输。之前我们提到的这种全量复制期间 RDB 的传输,这种复制流的传输都是串行的,他提出一个思路就是多路复用的传输,让 RDB、PING、复制的 buffer/stream 一起发送,大家可以在下面的链接上看到他的想法。
PSYNC3(PSYNC-AOF) 基于 AOF 实现复制
https://github.com/redis/redis/issues/4357
https://github.com/redis/redis/discussions/9282
SYNC-less replication 无全量同步的复制
https://github.com/redis/redis/discussions/9278
Multiplex replication 多路复用复制
RDB-bulk, PING, Replication-stream 多路复用传输
https://github.com/redis/redis/pull/8440#issuecomment-771623319
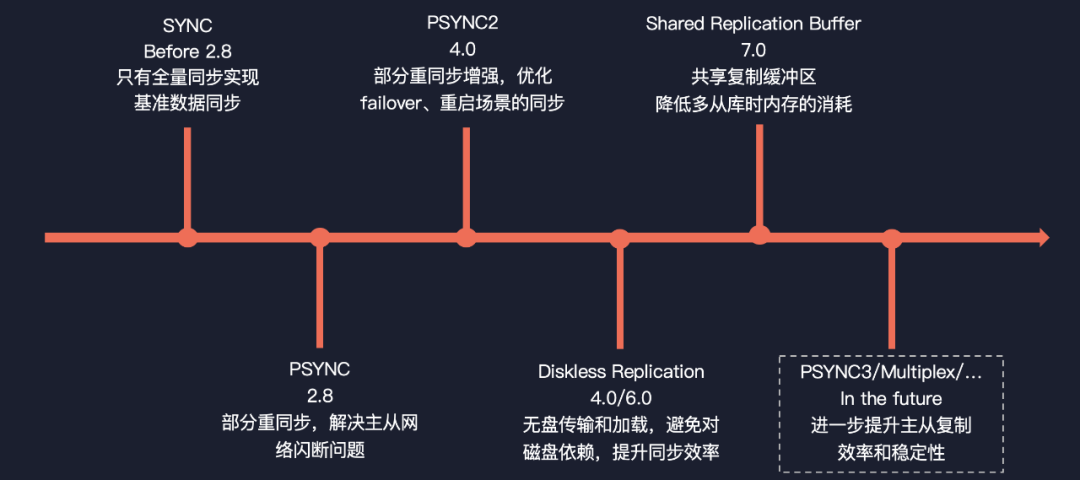
最后我们来总结一下,Redis 主从复制演进的历程,首先是在 2.8 之前的一个全量同步,主要就是解决基准数据同步,到了 2.8 提出了一个 PSYNC 的方案部分重同步,它解决了主从网络闪断的问题,在 4.0 提出了 PSYNC2,部分重同步的一个增强,它优化了 failover 后,故障重启之后的场景,从而实现一个部分同步,而避免了全量同步的问题。
主从复制演进历程
在 4.0 和 6.0 共同去解决了一个 Diskless Replication 的方案,无盘的传输和加载,避免了对磁盘的依赖,提升了主从同步的效率。在 7.0 中我们百度智能云提出了共享复制缓冲区的一个概念,降低了多从库内存的消耗。刚刚我们也展望了一下未来,在主从复制上面的一些优化,PSYNC3 多路复用的传输,它将会进一步提升主从复制的效率和稳定性,一起期待一下吧。
最后我有一句话和你分享:独立思考、不断探索。我们发现 Redis 主从复制的历程,也是发现问题去解决问题。我们遇到了很多问题,但是通过深挖找到解决的思路,然后去探索,最后将这个问题不断地优化得以解决,也让我们应对的场景越来越多。
王源 百度数据库技术部 资深研发工程师
多年来一直负责百度分布式 Redis 和磁盘 KV 存储服务 PegaDB 的内核研发工作。专注于分布式 KV 数据库、存储引擎和 NoSQL 等方向的研究。Redis 官方社区的 Member,Redis 6.2 和 7.0 的重要贡献者,同时也是开源磁盘 KV 存储服务 Kvrocks CoreTeam 成员之一。
传美的被勒索千万美元,连夜天价聘请安全专家;软银抵押一半阿里股票,孙正义:“为过去贪图暴利感到羞愧”;谷歌数据中心爆炸 |Q 资讯
QCon+ 案例研习社(又名:大厂案例)是极客时间平台推出的视频案例课。内容由领域内技术专家出品审核、数百位不同大厂 / 独角兽公司的一线开发工程师、项目经理、产品经理、咨询师和 Tech Lead 亲身分享,所有实践案例都经过至少三个月打磨。QCon+ 专注于提供最接地气、最可靠的技术解决方案,目前已更新 90+ 专题、300+ 实战案例。专题每周一持续更新中,敬请期待!

👇 点击“阅读原文”领取 7 天试用会员 ~



