微软亚洲研究院发布高性能MoE库Tutel,为大规模DNN模型开发提速!


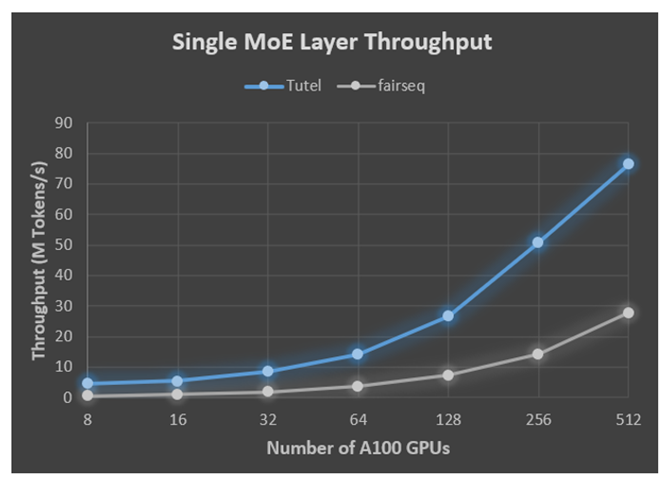
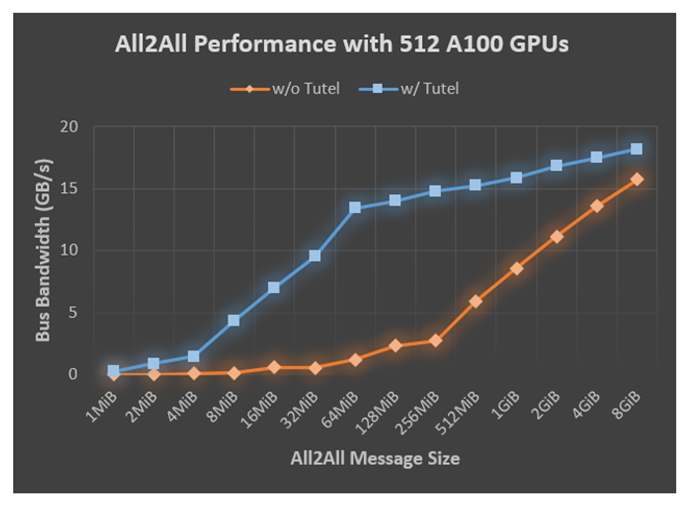
-
为 Top-K gating 算法设置任意K值(大多数实现方法仅支持 Top-1 和 Top-2 )。 -
不同的探索策略,包括批量优先路由、输入信息丢失、输入抖动。 -
不同的精度级别,包括半精度(FP16)、全精度(FP32)、混合精度等(下一个版本中将支持 BF16)。 -
不同的设备类型,包括 NVIDIA CUDA 和 AMD ROCm 设备等。
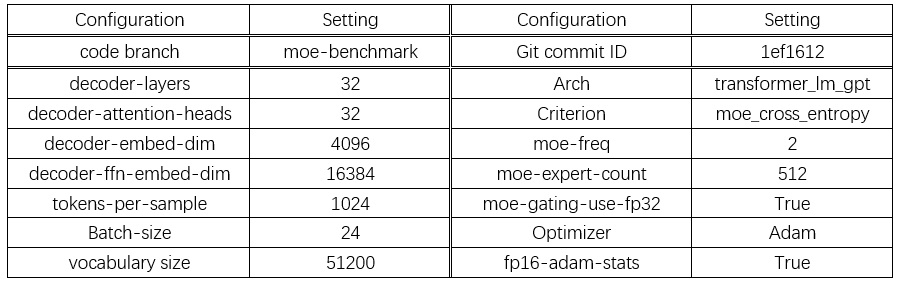
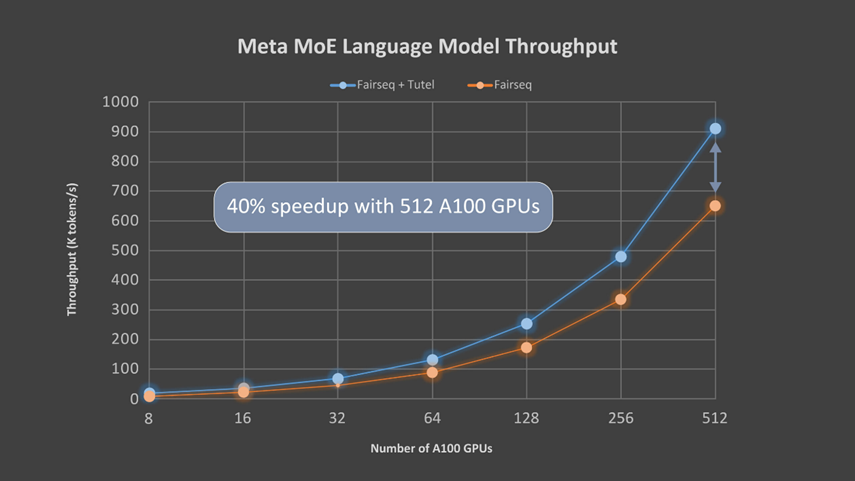




登录查看更多
相关内容
Arxiv
14+阅读 · 2019年8月8日




相关VIP内容
相关资讯