深度学习训练tricks总结(均有实验支撑)

极市导读
本文作者模拟复现了自己在深度学习训练过程中可能遇到的多种情况,并尝试解决这些问题,文章围绕学习率、动量、学习率调整策略、L2正则、优化器展开。>>加入极市CV技术交流群,走在计算机视觉的最前沿
深度模型是黑盒,而且本次并没有尝试超深和超宽的网络,所以结论只能提供一个先验,并不是标准答案!同时不同的任务也可能导致不同,比如分割,所以必须具体问题具体分析!
Abstract;Key-words;Motivation
前阵子参加了几个CV的比赛,发现了这样的问题:虽然了解的理论知识不算特别少,跑了的实验和paper代码也还可以,但是实际搞起来总会出现一些奇怪的问题,然后解决起来也是有点难受,于是就打算尽可能地把遇到的情况模拟复现出现,尝试解决并解释(但是解释原因只能自圆其说,毕竟黑盒实验),以免之后遇到类似的情况没有解决的思路。
这个黄金周,乖乖地在研究所做了几天实验,主要围绕着这下几个关键字:
学习率;动量;学习率调整策略;L2正则;优化器
(所有的结论都有实验支撑,但是有一部分实验数据给我搞没了....555)
Thinking
在这些实验以及一些资料(主要是吴恩达的《Machine Learning Yearning》),总结了以下几条基本准则:
-
模型性能的影响因素:
-
模型的表达能力(深度和宽度) -
学习率 -
优化器 -
学习率调整策略
2. 模型过拟合的影响因素:
-
数据量(数据增强可以增加数据量) -
正则化
稍微解释一下:模型的表达能力对模型是否过拟合的确有起到一定的影响,但是选择合适的正则化强度可以有效的减缓这个影响!所以我没有把模型的表达能力列入为过拟合的影响因素。而且吴恩达的书中(《Machine Learning Yearning》)也表达了类似的想法(很开心,和大佬有一样的想法)。
实验环境
Resnet-18
Cifar-10
Details
-
学习率 和 动量
学习率和动量我会放在一起说,因为我发现这两个东西就是天生的couple。了解深度学习的小伙伴应该知道,学习率过大和过小都会存在问题:
学习率过大会导致模型无法进入局部最优甚至导致模型爆炸(不能收敛)
学习率过小会导致模型训练慢,进而浪费时间
那有没有办法让模型训练得又快又能收敛呢?有!
我经过四个实验得出以下结论:
使用较大的学习率+大的动量可以加快模型的训练且快速收敛
实验设计如下(我忘记保存实验图了,对不起!):
实验一:
小学习率+小动量
结果:模型训练速度慢,虽然收敛但是收敛速度很慢,验证集上性能很稳定
实验二:
小学习率+大动量
结果:模型训练速度慢,虽然收敛但是收敛速度很慢,验证集上性能很稳定
实验三:
大学习率+小动量
结果:模型训练速度快,虽然很难收敛而且验证集上性能波动很大,说明了模型很不稳定
实验四:
大学习率+大动量
结果:模型训练速度快,同时收敛得也很快,而且验证集上性能很稳定
我觉得这个原因,可以从两个角度来解释,一个是向量加法的特殊性;另一个是从集成模型的角度来解释。第一个角度我这里就不说了,因为我不想画图。。,我从第二个角度来说:
大的学习率意味着不稳定,但是因为这个学习率也是可以让模型往正确的优化方向上走,所以你可以理解大的学习率为一个弱的机器学习模型;当你采用大的动量的时候,意味着本次学习率对最终模型优化起的作用要小,也就是说采用大动量 -> 单次损失函数的占比低,那就相当于我这个模型的优化是由本次+过去很多次学习率(弱机器学习模型)计算出来的综合结果,那是不是就是一个集成模型呢~so,效果就比较好了。
随便提一嘴,当模型很不稳定的时候,如果某个瞬间出现较好的结果,比如准确率98%,那也不能说明这个模型在这个瞬间是好模型,因为这个时候你的模型很有可能是对验证集过拟合了!不信你可以划分出一个测试集试试(我之前参加脑PET识别比赛的时候就在地方摔过)。
2. 学习率调整策略
以前我是几乎不用学习率调整策略的,因为我觉得很扯,效果不大,但是前阵子和一小哥打华录杯的时候看他用了余弦退火有不错的效果,就决定也试试,结论是:真香!
对不起的是,这里我也忘记保存实验图了,对不起!
我尝试了3种学习率调整策略,分别为:1.ReduceLROnPlateau;2. 余弦退火;3. StepLR
结论:
-
三种策略都很不错的 -
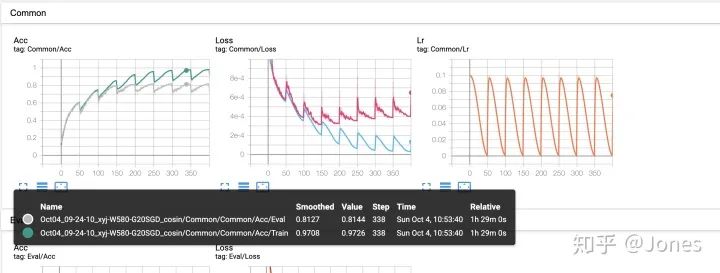
余弦退火使用的时候,最大学习率和最小学习率相差的数量级不要太大(比如1e-1和1e-4),不然会导致在该快的时候太慢,在该慢的时候太快,特别的接近最优解的时候,太大就直接跑偏(图1)【Acc图中,灰色的曲线是验证集上的准确率,这里我L2没调好,所以过拟合了,可以忽略这点】 -
余弦退火我推荐在warm-up的时候可以用,之后可以改一下 -
ReduceLROnPlateau我觉得是三个里面最优的,可以根据训练的情况动态调整(也出现了一些玄妙的情况(mode参数),我后面会说),需要注意的地方是,用这个的时候最好设置一下最小学习率,不然后期会因为学习率衰减得过小导致模型训练不到。 -
StepLR就很传统,也挺好用的,但是灵活度不如ReduceLROnPlateau。
3. L2正则
正则主要分两种,一种是L1,一种是L2,因为pytorch自带L2,所以我就只用了L2(嘻嘻),直接上结论:
-
L2千万不要调太大,不然特别难训练(难训练/训练不到的标记就是验证集上的性能一直在较低的水平波动,不如10% -> 12% ->9%),这就说明我们的模型并没有学到什么东西 -
L2也不能太小,不然过拟合得挺严重的,大概1e-2可以有不错的效果(resnet18) -
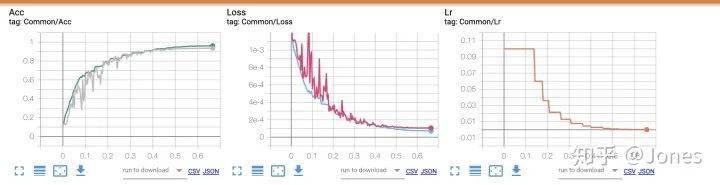
即使正确地使用正则化强度,也会导致验证集前期不稳定甚至呈现训练不到的现象,但是之后就会稳定下来!不要慌!(如图2,Acc中,灰色的曲线是模型在验证集上的准确率)
4. 优化器
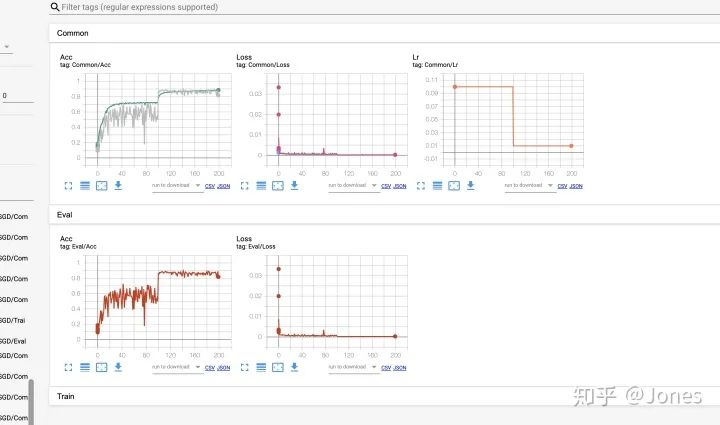
优化器部分我就存图了!
其实这里不单单测试了优化器,应该是优化器+学习率策略+momentum
其实我想做的事情就是找到一个最优解可以作为我的先验知识(害,人话就是:就是我想知道哪种搭配比较好,以后就先试试这种搭配)
我做了几组实验:
-
第一组:
-
SGD(大的初始学习率) + momentum(大动量) +StepLR + L2(每隔70个epoch,学习率衰减为之前的0.1) -
Adam(大的初始学习率) +StepLR + L2(每隔70个epoch,学习率衰减为之前的0.1) -
AdamW(大的初始学习率) +StepLR + L2(每隔70个epoch,学习率衰减为之前的0.1)
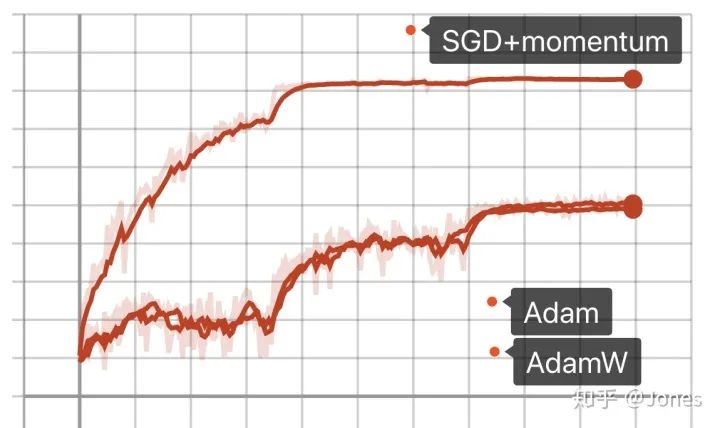
结论(图3):
-
SGD+momentum在大学习率+大动量的时候效果更好; -
不管是SGD还是Adam还是AdamW,学习率的调整都对他们有帮助
第二组:
-
ReduceLROnPlateau(mode='min') + SGD(大学习率) + momentum(大动量) + L2 -
ReduceLROnPlateau(mode='max') + SGD(大学习率) + momentum(大动量) + L2 -
余弦退火 + SGD(大学习率) + momentum(大动量) + L2
先解释一下ReduceLROnPlateau的两种模式:min和max
当模型为min的时候,如果指标A在一段时间内没有减小的话,则学习率衰减。
当模型为max的时候,如果指标A在一段时间内没有增大的话,则学习率衰减。
ReduceLROnPlateau我选择mode为min模式的时候,指标的是acc,很有意思的是,其收敛速度非常快(比mode为max更快),我猜测原因应该是:
当acc有所上升的时候,说明这个优化方向是正确的,这个时候优化的速度应该放缓!但是在这个实验中,其最优解比mode为max模式差(min模式下的最优解为0.916,max为0.935)。原因应该有两个:
1. 是因为lr的衰减速度过快,以至于后面学习率过低,训练不动;(后来我做了实验证明了就是这个原因!)
2. 因为一遇到可优化的地方就减少学习率,所以极有可能使得模型过早进入局部最优点(但是我后来觉得这个原因站不住脚哈哈哈,因为就算使用其他优化器,同样会存在陷入局部最优的问题,所以这个点不重要,但是为了保留从实验到笔记的思考过程,我还是不把这点删掉了。)
对于原因1,我之后做了实验进行验证,实验思路就是减小学习率衰减周期和衰减系数的值/设置最小学习率,保证后期学习率不会过小,最终的解决了最优解的问题。
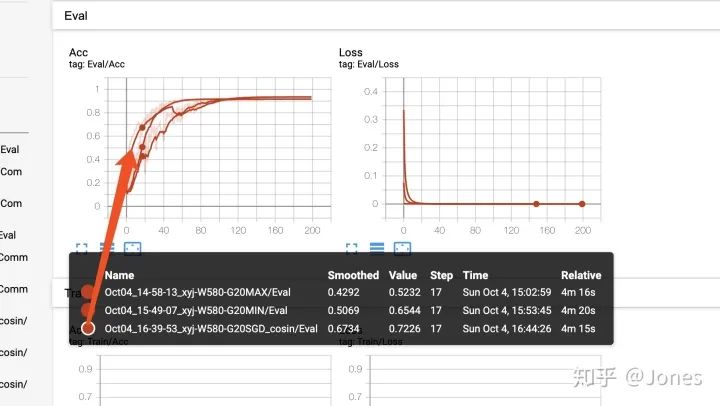
结论(图4):
-
带有momentum的SGD加余弦退火收敛更快且更加稳定(其他两个也不赖!) -
学习率最好设定好下限,不然后期会训练不动
第三组:
-
StepLR+ SGD(大学习率) + momentum(大动量) + L2(图5) -
Adam + L2(图6)
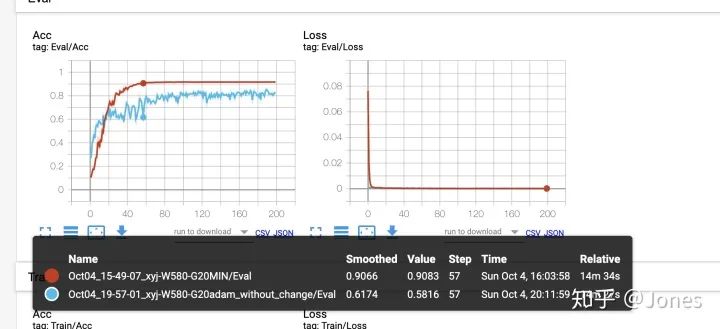
结论:
-
SGD+momentum的话,这东西对学习率还是很敏感的,所以平时最好还是别单纯只用它,最好加上一些其他的策略(余弦/ReduceLROnPlateau)。 -
纯Adam非常垃圾,- -我给它的初值是1e-3,然而和之前的结果相比不管从稳定性还是收敛速度来讲都很差劲。
顺便提一下:我也有尝试模拟退火+Adam,但是因为退火的幅度过大,所以效果更不好(我的锅)。下次再试试正常幅度的退火。
心得:
从上述实验可以看出monument非常非常重要,让有点垃圾的SGD一下子就上天了(怪不得论文里都喜欢用这对couple),这时候再加上一些学习率调整策略(退火/ReduceLROnPlateau)就可以直接上天了,不说了,以后我就先首发这对组合。Adam相对于SGD来讲,的确好上不少,但是相比较于最优组合(SGD+momentum+学习率调整策略),就弱了一点。(在叉烧哥的群里有位高通的大佬和我说可以试试用nadam,因为nadam可以理解为Adam+monument,但是因为pytorch官方没相应的api,我就懒得试了,不过我相信应该很猛!)
推荐阅读
ACCV 2020国际细粒度网络图像识别竞赛正式开赛!






