KDD Cup 2018 冠军「 first floor to eat latiao」:为什么取这个队名?因为大家都爱辣条
提到 KDD Cup,相信数据挖掘领域的同学并不陌生。作为目前数据挖掘领域最有影响力、最高水平的国际顶级赛事,KDD Cup 至今已举办 21 届,每年都会吸引世界数据挖掘界的顶尖专家、学者、工程师、学生等前来参赛,被外界誉为大数据领域的「奥运会」。
今年的 KDD Cup 从空气问题入手,组委会在比赛中提供中国北京和英国伦敦的相关数据,比赛选手需要预测未来 48 小时内 PM2.5, PM10 和 O3 的浓度(伦敦只需要预测 PM2.5 和 PM10)。在 48 小时后,选手提交的结果将通过真实的天气数据评分。
虽然 KDD Cup 2018 在今年 6 月就已经结束,冠军团队也早已揭晓,但对冠军团队的正式颁奖是在刚刚结束的 KDD 2018 上。
本次比赛共吸引了来自全球 4183 支队伍,包括 49 个国家的 3000 多所学校或机构,北京邮电大学韩金栋、张前前、刘娟,中南大学罗宾理、蒋浩然组成的「first floor to eat latiao」团队在该项赛事中取得第一名。作为此次比赛的冠军,「first floor to eat latiao」团队受邀参与此次大会,在会上展示了他们的解决方案,也第一时间对 AI 科技评论进行分享。

看到队名,相信大家便对这一团队充满好奇。在组队的时候,队员张前前提出这个以吃为主题的名字,并得到大家全票通过。「我们都很喜欢吃辣条,辣条是中华民族的传统美食,我们想要得第一,将中华美食传扬出去。」
团员组成如下:
队长韩金栋,北京邮电大学硕士在读,喜欢用数学建模方法去解决实际生活中的问题;
队员张前前,北京邮电大学硕士在读,擅长特征工程和深度学习;
队员刘娟,北京邮电大学硕士在读,对数据分析和数据可视化感兴趣;
队员罗宾理,中南大学本科二年级在读,擅长特征工程和模型融合(骚操作);
队员蒋浩然,中南大学硕士在读,擅长数据分析与时间序列。
以下便是这一团队带来的解决方案:
主要的挑战有三点:
空气质量变化十分迅速,并且有很多突变点;
污染物会向周边扩散,具有复杂的空间依赖关系;
空气质量受很多复杂因素的影响,因此需要很强的专业领域知识。
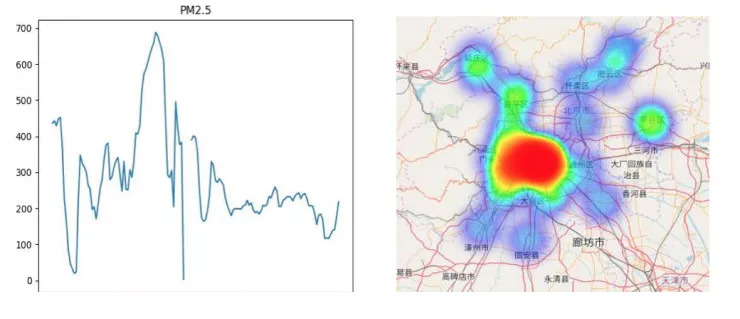
使用到的基本特征:
过去 72 小时的空气质量
预测前最后一小时的天气
未来 48 小时的天气预报
月份、周末、小时、假期、站点 id
除了基本特征,我们还从时域、空域、频域和专业领域知识四个方面分别构建特征群,一共提取了 100 多个特征,这些特征是模型提分的关键。
时域特征
利用预测时间附近天气预报数据的统计(不同的统计方式,可以统计预测时间节点之前的统计信息,也可以以预测时间节点为中心进行统计)防止天气突变。
针对短期预测问题,过去的天气变化可以影响到未来几个小时的空气质量。因此我们设计了不同大小的窗口,用来提取过去天气的统计特征,这些特征提高了模型的短期预测能力。
我们还发现未来 48 小时的天气预报是影响空气质量长期预测和突变预测的一个关键因素,因此我们针对未来的天气预报设计了很多细粒度的特征,具体可以看下图。如果绿色点是我们要预测的时间节点,为了描述预测时间点之前和附近的天气变化,我们使用滑动窗口提取了预测时间点之前的天气预报统计信息以及附近的天气预报统计信息。通过这些特征,提高了长期预测的准确率。
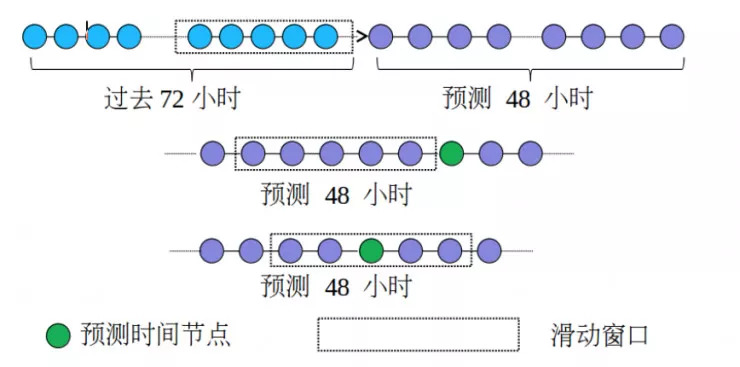
此外,为了区分要预测的是第一天还是第二天,我们使用了一个标志位特征,将预测时间标为 0~47。
频域特征
为了得到时间序列中隐藏的周期信息和波动信息,对空气质量,温度,湿度,气压等时间序列进行傅立叶变换,提取频域特征。
空域特征
未来的空气质量不仅与过去的空气质量有关,而且还受到周边空气质量和天气的影响。为了对空间相关性进行建模,我们针对过去的空气质量、天气以及未来的天气预报分别提取了表征空间相关性的特征。我们尝试使用了所有的空气质量站点和天气监测站点的数据,这样会增大模型的复杂度,导致严重的过拟合。于是我们假设只有部分站点会对我们要预测的站点产生影响,并使用一些技巧去降低空间特征的输入维度。
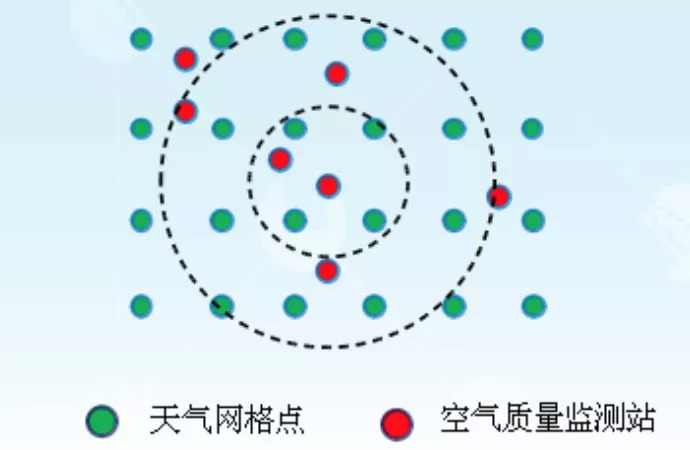
对于过去的空气质量和天气,我们又将其分为两类:
一类是没有方向的特征,包括压强、温度、湿度。为了提取这类特征,我们使用两个半径不同的圆将待预测站点周边划分为两个区域,分别为内圆区域和外部的圆环区域,具体划分方式可以见下图。我们提取了每一个区域的压强、温度和湿度的均值。
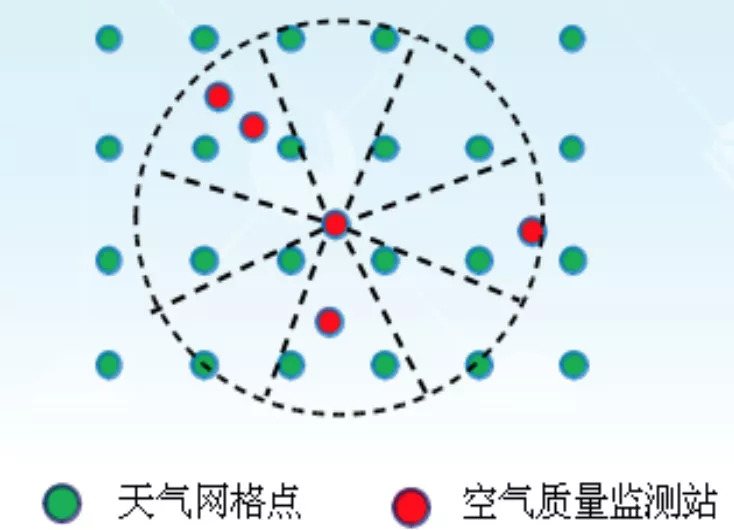
另一类是有方向的特征,污染物浓度和风的扩散都是有方向的。为了建模这一类特征对空气质量的影响,我们将目标站点的方位划分为八个方向,分别考虑八个不同方向区域对目标站点的影响。对于每一个区域,提取其风速和污染物浓度的均值。此外,我们又将风向离散为八个方向,每一个区域的风向由众数决定。如果某一区域污染物浓度缺失,我们使用插值的方法进行补全。
以上两类特征我们均只提取了预测前最后一小时的数据,这些特征对于短期预测起到了良好的效果。
对于未来的天气预报,由于天气网格点和空气质量监测站点的位置不是对应的,因此我们采用了一种 k 近邻的方法去提取空气质量监测站点周边的天气网格点。具体做法是寻找距离空气质量检测站点最近的四个天气网格点,使用这些网格点的特征表征未来天气预报对空气质量的影响,这种方法可以提高长期预测的准确率。
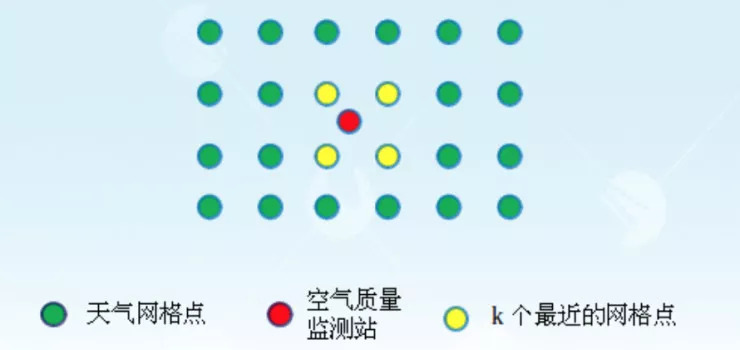
专业领域特征
查阅气象学和空气污染相关论文,通过风向 uv 坐标系,日照时长,不同时刻湿度的差值,污染物之间的相关性等方面提取特征。
模型
因为不同的污染物具有不同的分布,因此需要分别对每一种污染物建模。我们采用微软开源的 LightGBM,具体的建模方式可以参看下面这一张图:
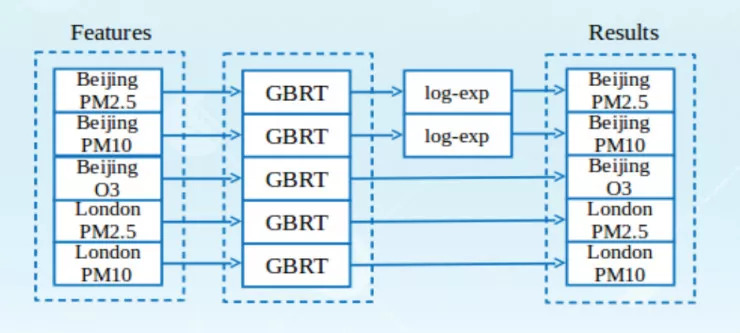
此外,我们还分析了北京和伦敦的每一种污染物的分布,发现北京的 PM2.5 和 PM10 是长尾的分布,存在很多严重污染的情况,这会给模型带来偏差。而北京的 O3 以及伦敦的 PM2.5、PM10 的数值相对来说跨度没有那么大,异常点较少。因此我们在训练模型的时候对北京 PM2.5 和 PM10 的标签做了 log 变换,在预测未来的时候使用指数变换。这个技巧可以给模型带来几个千分位的提升。
以下是关于比赛的更多细节:
团队共有来自北邮和中南大学的五名成员,大家在比赛中的分工如何?
在比赛初期,我们首先对赛题的技术难点进行了分析,总结出空气质量预测问题存在的几点挑战。然后针对每一个挑战,我们都有一个队员去独立探索,去尝试一些应对该挑战的解决方案。最后充分融合各自的方案,集成为一个模型。
此外,我们还有两名队员做了深度学习模型的探索,尝试使用端到端的模型去解决空气质量的预测问题。在比赛后期,我们的模型遇到瓶颈,我们又进行讨论,互相补充了思路,在特征工程上去掉了很多冗余的特征,又提取了不少新的特征,这让我们的模型在最后几天又有了大幅度提升。
比赛的三个难点分别是空气质量突变迅速、污染物复杂的空间依赖关系、需要很强的专业领域知识,对于这三大挑战,分别是如何应对的?
本次 KDD CUP 的比赛有三个挑战,我们主要是从特征工程角度出发,去解决这些挑战。
第一个挑战是空气质量变化十分迅速,并且有很多突变点,我们对空气质量时间序列做了大量的分析工作,了解其影响因素。针对这一挑战,我们从信号处理的角度出发,使用傅立叶变换将时间序列变换到频域,更好地提取时间序列的周期和波动信息。此外,我们还设计了更细粒度的天气统计特征去表征天气变化。
第二个挑战是污染物具有复杂的空间依赖关系,举个例子,如果有强风从污染严重的区域吹向周边区域,那么周边空气质量也会变差。但是如果将所有监测站的数据作为特征,那么将会导致严重过拟合。因此我们假设只有一部分相邻的监测站会影响到我们要预测的监测站,并且针对与方向有关和与方向无关的天气特征,我们使用了一种降维技巧去降低输入的维度,防止过拟合。
比赛遇到的第三个挑战是预测空气质量需要很强的专业领域知识,空气质量受很多复杂因素的影响,需要结合专业知识去建模。在比赛期间,团队成员阅读了大量与空气污染和气象学相关的文献,从而构造了很多与领域知识相关的特征,这些特征给模型带来显著的提升。
你们在比赛中采用 GBRT 模型,此前有尝试过其他模型吗?
我们还尝试了 seq-seq 模型建模时间序列,以及使用图卷积网络建模网络拓扑图的关系,因为数据集的问题,线上效果并不稳定,所以后来线上提交的只是 GBRT 单模型。
你们 PPT 的总结中特别强调了特征,在这次比赛中,特征占据比重有多大?这次比赛有哪些在特征方面的经验可以分享?
特征工程是我们这次比赛获得冠军的关键,这次比赛在训练集构造和数据预处理方面,大家都大同小异。我们在特征工程方面做了一些创新性的工作,提取了一些我们独有的特征,因此在比赛初期就建立了优势。
关于特征工程方面的经验,首先特征要有可解释性,提取的每一簇特征都是有理有据的。
其次特征要分群,不要因为效果的提升或下降随机删减某个特征,将特征分群处理可能会更加有效果。
最后特征要结合领域,一些好的特征是通过和业务领域结合产生的,通过查阅论文或者资料可以提取到和别人不一样的特征。
你们这次去 KDD 的体验如何?参加这次大会有哪些收获?
KDD 是数据挖掘方面的最顶级会议,而 KDD Cup 可以说是数据挖掘竞赛里的皇冠,能摘下桂冠,对我们的意义是非同凡响的。我们团队中也有历史上年龄最小拿到这一冠军的参赛者;而在会议上,认识的小伙伴基本上都是能在 KDD 上发论文的大牛,他们的科研实力都非常强;当然更有头条、阿里、京东、腾讯等大厂在现场,能够与部门主管/VP 直接交流,也是一件非常不错的事情,开阔了我们的眼界与思路。
目前,解决方案 PPT 也已经在 GitHub 上公开。
地址: https://github.com/luoda888/2018-KDD-Cup-Top1-Solutions






